This article was published as a part of the Data Science Blogathon.
Introduction
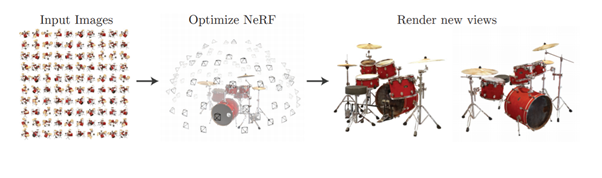
Neural Radiance Field or NeRF is a method for generating novel views of complex scenes. NeRF takes a set of input images of a scene and renders the complete scene by interpolating between the scenes.


The output is a volume whose color and density are dependent on the direction of view and emitted light radiance at that point. For each ray, we get an output volume and all these volumes make up the complex scene.
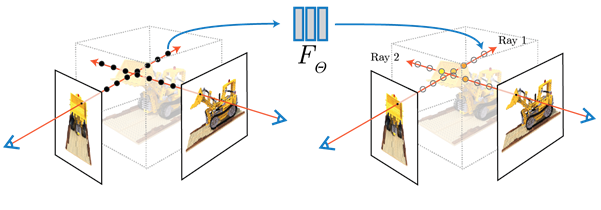
A static scene is represented as a continuous 5D function as defined above. The method uses a fully connected neural network- a multilayered perceptron(MLP) to represent this function by moving backward from a single 5D coordinate (x, y, z, θ, φ) to output a volume density (with RGB color influenced by view)
To render this NeRF, there are 3 steps:
1. march camera rays through the scene to sample 3D points
2. use points from step1 and their corresponding 2D viewing directions(θ, φ) as input to the MLP to produce an output set of colors (c = (r, g, b)) and densities σ,
3. use volume rendering techniques to accumulate those colors and densities into a 2D image [Note: Volume rendering refers to creating a 2D projection from sampled 3D points]
Results
As compared to other methods, this method achieved significantly better results:

The results when you fix the camera viewpoint and change the viewing direction:
Viewing Geometry: NeRF is good with complex geometries and deals with occlusion well.

Some speedup can be obtained on model training by data caching, vectorizing code, proper memory management, and reducing data transfer between CPU and GPU.
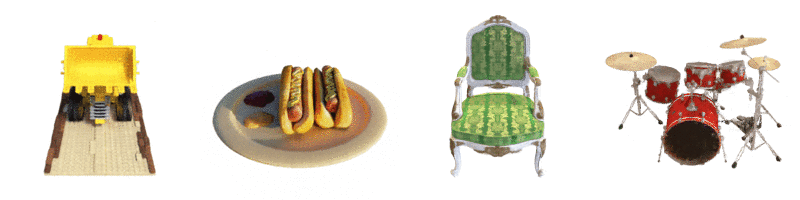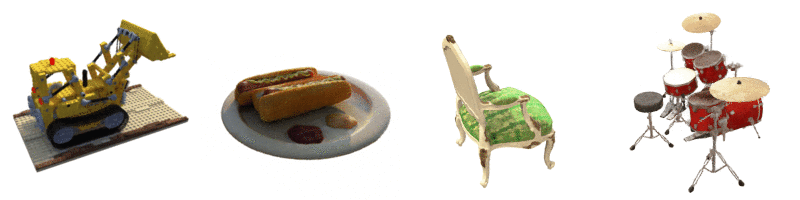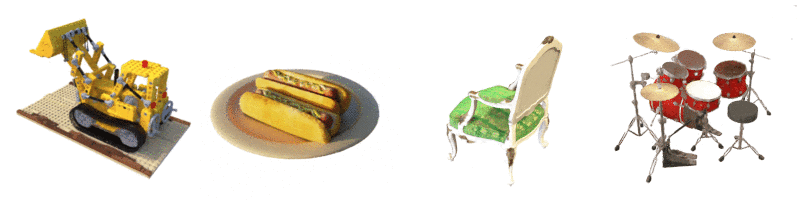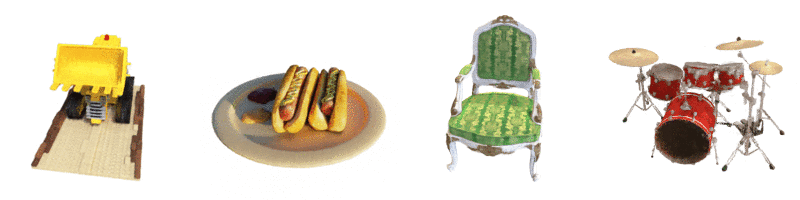
This is a tiny version of the original NeRF architecture and the model used here is lighter compared to the original. The architecture can be seen below:
class VeryTinyNerfModel(torch.nn.Module):“””Define a “very tiny” NeRF model comprising three fully connected layers.”””# this code has been adopted from https://github.com/krrish94/nerf-pytorchdef __init__(self, filter_size=128, num_encoding_functions=6):super(VeryTinyNerfModel, self).__init__()# Input layer (default: 39 -> 128)self.layer1 = torch.nn.Linear(3 + 3 * 2 * num_encoding_functions, filter_size)# Layer 2 (default: 128 -> 128)self.layer2 = torch.nn.Linear(filter_size, filter_size)# Layer 3 (default: 128 -> 4)self.layer3 = torch.nn.Linear(filter_size, 4)# Short hand for torch.nn.functional.reluself.relu = torch.nn.functional.reludef forward(self, x):x = self.relu(self.layer1(x))x = self.relu(self.layer2(x))x = self.layer3(x)return x
Applications
An application of NeRF in tourism: Phototourism
Lots of tourists take lots of photographs. And these photographs can be used to render complex photorealistic scenes:

Recently, NeRF has been extended to NR-NeRF (non-rigid NeRF). While NeRF is used for photorealistic appearance and geometry reconstruction of static scenes, NR-NeRF deals with non-rigid dynamic scenes.

The input is presented on the left, the middle shows the reconstruction by NR-NeRF, the right shows the generated novel view
This example shows the input video on the left and the novel view processed by NR-NeRF:

Sparse Neural Radiance Grid (SNeRG) enables real-time scene rendering. It is based on NeRF whose computational requirements make it unsuitable for real-time applications. This method precomputes and stores a NeRF into a SNeRG data structure. To render SNeRG data structure in real-time, we:
- Use a sparse voxel grid to skip empty space along with rays
- Lookup a diffuse color for each point sampled along a ray in occupied space, and composite these along the ray
- Lookup a feature vector (4-dimensional) for each point, and composite these along the ray
- Decode the composited features into a single specular color per pixel using a tiny (2 layers, 16 channels) MLP
- Add the diffuse and specular color components to compute the final RGB color
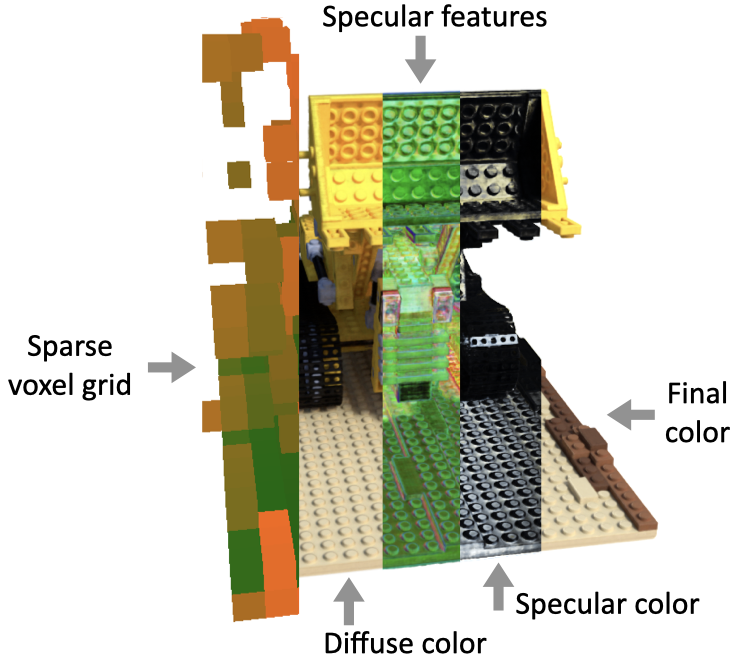
This article has been inspired by the papers: “NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis” (Mildenhall et.al)”, “Baking Neural Radiance Fields for Real-Time View Synthesis” (Hedman et.al), “Non-Rigid Neural Radiance Fields: Reconstruction and Novel View Synthesis of a Dynamic Scene From Monocular Video” (Tretschk et.al)
This article has been written by Ujjayanta. You can find him on LinkedIn (https://www.linkedin.com/in/ujjayanta-bhaumik/) and Twitter (https://twitter.com/I_m_jojo).
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.
PhD Researcher, Virtual Reality | Light & Lighting Laboratory, KU Leuven | Msc Computer Graphics, Vision and Imaging UCL | Interested in Python, Virtual Reality, Augmented Reality, Cryptography | Currently working on the perception of light in real and virtual environments



