Welcome readers. This is Part 1 of the Comprehensive tutorial on Deep learning. This tutorial or guide is mostly for beginners, and I’ll try to define and emphasize the topics as much as I can. Since Deep learning is a very Huge topic, I would divide the whole tutorial into few parts. Be sure to read the other parts if you find this one useful.
Table of contents
This article was published as a part of the Data Science Blogathon
What is Deep Learning?
It is a subfield of Machine Learning, inspired by the biological neurons of a brain, and translating that to artificial neural networks with representation learning.
Why Deep learning?
When the volume of data increases, Machine learning techniques, no matter how optimized, starts to become inefficient in terms of performance and accuracy, whereas Deep learning performs soo much better in such cases.

What amount of Data is big?
Well one cannot quantify a threshold for data to be called big, but intuitively let’s say a Million sample might be enough to say “It’s Big”( This is where Michael Scott would’ve uttered his famous words “That’s what she said” )
Fields where DL is used
- Image Classification, Speech recognition, NLP(Natural language Processing), recommendation systems, etc.
Difference Between Deep Learning and Machine Learning
- Deep Learning is a subset of Machine Learning.
- In Machine Learning features are provided manually.
- Whereas Deep Learning learns features directly from the data.

We will use the Sign Language Digits Dataset which is available on Kaggle here. Now let us begin.
Importing Necessary Libraries
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt
# Input data files are available in the "../input/" directory.
# import warnings
import warnings
# filter warnings
warnings.filterwarnings('ignore')
from subprocess import check_output
print(check_output(["ls", "../input"]).decode("utf8"))
# Any results you write to the current directory are saved as output.
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt
# Input data files are available in the "../input/" directory.
# import warnings
import warnings
# filter warnings
warnings.filterwarnings('ignore')
from subprocess import check_outputOverview of the Data
- There are 2062 sign language Digit Images in this dataset.
- Since there are 10 digits from 0-9, there are 10 unique sign images.
- In the beginning, we will only use 0 and 1 (To keep it simple for learners)
- In the data, the hand sign for 0 is between indices 204 and 408. There are 205 samples for 0.
- Also, the hand sign for 1 is between indices 822 and 1027. There are 206 samples.
- Thus we shall use 205 samples from each class (Note: in reality 205 samples are very much less for a proper Deep Learning model, but since this is a tutorial, we can ignore that),
Now we will prepare our arrays X and Y, where X is our Image array(Features) and Y is our label array (0 and 1).
# load data set
x_l = np.load('../input/Sign-language-digits-dataset/X.npy')
Y_l = np.load('../input/Sign-language-digits-dataset/Y.npy')
img_size = 64
plt.subplot(1, 2, 1)
plt.imshow(x_l[260].reshape(img_size, img_size))
plt.axis('off')
plt.subplot(1, 2, 2)
plt.imshow(x_l[900].reshape(img_size, img_size))
plt.axis('off')
Prepare the Data Arrays
We will concatenate segments of hand sign images for digits 0 and 1 into the array X and create the labels for Y:
# Join a sequence of arrays along an row axis.
# from 0 to 204 is zero sign and from 205 to 410 is one sign
X = np.concatenate((x_l[204:409], x_l[822:1027] ), axis=0)
z = np.zeros(205)
o = np.ones(205)
Y = np.concatenate((z, o), axis=0).reshape(X.shape[0],1)
print("X shape: " , X.shape)
print("Y shape: " , Y.shape)
To create our X array, we first slice and concatenate our segments of 0’s and 1’s hand sign images from the dataset to the array X. Next we do something similar with Y, but use the labels instead.
1) So we see that the shape of our X array is (410, 64, 64)
- The 410 means 205 images of 0, 205 images of 1.
- the 64 means that the size of our images is 64 x 64 pixels.
2) The shape of Y is (410,1) thus 410 1’s and 0’s.
3) Now we split X and Y into train and test sets.
- train = 75%, train = 15%
- random_state = Uses a particular seed while randomizing, thus if the cell runs multiple times, the random number generated does not change every time. The same test and train distribution are created every time.
# Then lets create x_train, y_train, x_test, y_test arrays
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.15, random_state=42)
number_of_train = X_train.shape[0]
number_of_test = X_test.shape[0]We have a 3 Dimensional input array, so we have to flatten it to 2D to feed into our first Deep Learning model. Since y is already 2D, we leave it just as it is.
X_train_flatten = X_train.reshape(number_of_train,X_train.shape[1]*X_train.shape[2])
X_test_flatten = X_test .reshape(number_of_test,X_test.shape[1]*X_test.shape[2])
print("X train flatten",X_train_flatten.shape)
print("X test flatten",X_test_flatten.shape)
Now we have a total of 348 images, each with 4096 pixels in the training array X. And 62 images of the same pixel density 4096 in the test array. Now we transpose the arrays. This is just a personal choice and you will see in the upcoming codes why I dis this.
x_train = X_train_flatten.T
x_test = X_test_flatten.T
y_train = Y_train.T
y_test = Y_test.T
print("x train: ",x_train.shape)
print("x test: ",x_test.shape)
print("y train: ",y_train.shape)
print("y test: ",y_test.shape)
So now we are done with preparing our required data. This is how it looks:

Now we will get familiar with one of the basic models of Dl, called Logistic Regression.
Logistic Regression
When talking about binary classification, the first model that comes to mind is Logistic regression. But one might wonder what is the use of logistic regression in Deep learning? The answer is simple since logistic regression is a simple neural network. The terms neural network and Deep learning go hand in hand. To understand Logistic regression, first, we have to learn about Computational graphs.
Computation Graph
Computational graphs can be considered as a pictorial way of representing mathematical expressions. Let us understand that with an example. Suppose we have a simple mathematical expression like:
c = ( a2 + b2 ) 1/2
Its computational graph will be:

Image Source: Author
Now let us view a computational graph of Logistic regression:

Image Source: Kaggle Dataset
- The weights and bias are called parameters of the model.
- The weights depict the coefficients of each pixel.
- Bias is the intercept of the curve formed by plotting parameters against labels.
- Z = (px1*wx1) + (px2*wx2) + …. + (px4096*wx4096)
- y_head = sigmoid_funtion(Z)
- What the sigmoid function does is essentially scale the value of Z between 0 and 1, so it becomes a probability.
Why use the Sigmoid Function?
- It gives us a probabilistic result.
- Since it’s a derivative, we can use it in the gradient descent algorithm.
Now we will examine each of the components of the above computational graph in detail.
Initializing Parameters

Image source: Microsoft Docs
Each pixel has its own weight. But the question is what will be their initial weights? There are several techniques to do that which I shall cover in part 2 of this article but for now, we can initialize them using any random value, let’s say 0.01.
The shape of the weights array will be (4096, 1), since there are in total 4096 pixels per image, and let the initial bias be 0.
# lets initialize parameters
# So what we need is dimension 4096 that is number of pixels as a parameter for our initialize method(def)
def initialize_weights_and_bias(dimension):
w = np.full((dimension,1),0.01)
b = 0.0
return w, bw,b = initialize_weights_and_bias(4096)
Forward Propagation
All the steps from pixels to cost function is called forward propagation.
To calculate Z we use the formula: Z = (w.T)x + b. where x is the pixel array, w weights, and b is bias. After calculating Z we feed it into the sigmoid function which returns y_head(probability). After that, we calculate the loss(error) function.
The cost function is the summation of all the losses and penalizes the model for the wrong predictions. This is how our model learns the parameters.
# calculation of z
#z = np.dot(w.T,x_train)+b
def sigmoid(z):
y_head = 1/(1+np.exp(-z))
return y_heady_head = sigmoid(0)
y_head
> 0.5The mathematical expression for loss function(log) is :
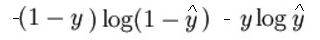
Like I said previously, what the loss function essentially does is penalize for wrong predictions. here is the code for the forward propagation:
# Forward propagation steps:
# find z = w.T*x+b
# y_head = sigmoid(z)
# loss(error) = loss(y,y_head)
# cost = sum(loss)
def forward_propagation(w,b,x_train,y_train):
z = np.dot(w.T,x_train) + b
y_head = sigmoid(z) # probabilistic 0-1
loss = -y_train*np.log(y_head)-(1-y_train)*np.log(1-y_head)
cost = (np.sum(loss))/x_train.shape[1] # x_train.shape[1] is for scaling
return costOptimizing with Gradient Descent

Image Source: Coursera
We aim to find the values for our parameters for which, the loss function is the minimum. The equation for gradient descent is:

Where w is the weight or the parameter. greek letter alpha is something called stepsize. What it signifies is the size of the iterations we’ll take while going down the slope to find local minima. And rest is the derivative of the loss function, also known as the gradient. The algorithm for gradient descent is simple:
- First, we take a random datapoint in our graph and find its slope.
- Then we find the direction in which the value loss function decreases.
- Update the weights using the above formula. (This method is also called backpropagation)
- Select the next point by taking a stepsize of α.
- Repeat.
# In backward propagation we will use y_head that found in forward progation
# Therefore instead of writing backward propagation method, lets combine forward propagation and backward propagation
def forward_backward_propagation(w,b,x_train,y_train):
# forward propagation
z = np.dot(w.T,x_train) + b
y_head = sigmoid(z)
loss = -y_train*np.log(y_head)-(1-y_train)*np.log(1-y_head)
cost = (np.sum(loss))/x_train.shape[1] # x_train.shape[1] is for scaling
# backward propagation
derivative_weight = (np.dot(x_train,((y_head-y_train).T)))/x_train.shape[1] # x_train.shape[1] is for scaling
derivative_bias = np.sum(y_head-y_train)/x_train.shape[1] # x_train.shape[1] is for scaling
gradients = {"derivative_weight": derivative_weight,"derivative_bias": derivative_bias}
return cost,gradientsNow we update the learning parameters:
# Updating(learning) parameters
def update(w, b, x_train, y_train, learning_rate,number_of_iterarion):
cost_list = []
cost_list2 = []
index = []
# updating(learning) parameters is number_of_iterarion times
for i in range(number_of_iterarion):
# make forward and backward propagation and find cost and gradients
cost,gradients = forward_backward_propagation(w,b,x_train,y_train)
cost_list.append(cost)
# lets update
w = w - learning_rate * gradients["derivative_weight"]
b = b - learning_rate * gradients["derivative_bias"]
if i % 10 == 0:
cost_list2.append(cost)
index.append(i)
print ("Cost after iteration %i: %f" %(i, cost))
# we update(learn) parameters weights and bias
parameters = {"weight": w,"bias": b}
plt.plot(index,cost_list2)
plt.xticks(index,rotation='vertical')
plt.xlabel("Number of Iterarion")
plt.ylabel("Cost")
plt.show()
return parameters, gradients, cost_list
parameters, gradients, cost_list = update(w, b, x_train, y_train, learning_rate = 0.009,number_of_iterarion = 200)Till this point, we learned our parameters. It means we are fitting the data. In the prediction step, we have x_test as input and using it, we make forward predictions.
# prediction
def predict(w,b,x_test):
# x_test is a input for forward propagation
z = sigmoid(np.dot(w.T,x_test)+b)
Y_prediction = np.zeros((1,x_test.shape[1]))
# if z is bigger than 0.5, our prediction is sign one (y_head=1),
# if z is smaller than 0.5, our prediction is sign zero (y_head=0),
for i in range(z.shape[1]):
if z[0,i]<= 0.5:
Y_prediction[0,i] = 0
else:
Y_prediction[0,i] = 1
return Y_predictionpredict(parameters["weight"],parameters["bias"],x_test)
Now we make our predictions. Let us put it all together:
def logistic_regression(x_train, y_train, x_test, y_test, learning_rate , num_iterations):
# initialize
dimension = x_train.shape[0] # that is 4096
w,b = initialize_weights_and_bias(dimension)
# do not change learning rate
parameters, gradients, cost_list = update(w, b, x_train, y_train, learning_rate,num_iterations)
y_prediction_test = predict(parameters["weight"],parameters["bias"],x_test)
y_prediction_train = predict(parameters["weight"],parameters["bias"],x_train)
# Print train/test Errors
print("train accuracy: {} %".format(100 - np.mean(np.abs(y_prediction_train - y_train)) * 100))
print("test accuracy: {} %".format(100 - np.mean(np.abs(y_prediction_test - y_test)) * 100))
logistic_regression(x_train, y_train, x_test, y_test,learning_rate = 0.01, num_iterations = 150)


So as you can see, even the most fundamental model of Deep learning is quite tough. It is not easy for you to learn, and beginners sometimes might feel overwhelmed while studying all of this in the one go. But the thing is we haven’t even touched deep learning yet, this is like the surface of it. There’s soo much more which I’ll add to in part 2 of this article.
Since we have learned the logic behind Logistic regression, we can use a library called SKlearn which already has many of the models and algorithms built in it, so you don’t have to start everything from scratch.
Logistic regression using Sklearn

I am not going to explain much in this section since you know almost all the logic and intuition behind Logistic regression. If you are interested in reading about the Sklearn library, you can read the official documentation here. Here is the code, and I’m sure you will be flabbergasted to see how little effort it takes:
from sklearn import linear_model
logreg = linear_model.LogisticRegression(random_state = 42,max_iter= 150)
print("test accuracy: {} ".format(logreg.fit(x_train.T, y_train.T).score(x_test.T, y_test.T)))
print("train accuracy: {} ".format(logreg.fit(x_train.T, y_train.T).score(x_train.T, y_train.T)))
Yes! this is all it took, just 1 line of code!
Conclusion
We’ve learned a lot today. But this is just the beginning. Be sure to check out part 2 of this article. You can find it at the below link. If you like what you read, you can read some of the other interesting articles that I’ve written.
I hope you had a good time reading my article. Cheers!!
The author uses the media shown in this article on Top Machine Learning Libraries in Julia at their discretion, and Analytics Vidhya does not own it.



Very good article would help people entering this field and wants to be a professional in this line.