This article was published as a part of the Data Science Blogathon.
What is OpenCV?
Computer vision is a process by which we can understand how the images and videos are stored and manipulated, also it helps in the process of retrieving data from either images or videos. Computer Vision is part of Artificial Intelligence. Computer-Vision plays a major role in Autonomous cars, Object detections, robotics, object tracking, etc.
OpenCV
OpenCV is an open-source library mainly used for computer vision, image processing, and machine learning. It gives better output for real-time data, with the help of OpenCV, we can process images and videos so that the implemented algorithm can be able to identify objects such as cars, traffic signals, number plates, etc., and faces, or even handwriting of a human. With the help of other data analysis libraries, OpenCV is capable of processing the images and videos according to one’s desire.
More information about OpenCV can be acquired here (https://opencv.org/)
The library which we are going to use along with OpenCV-python is Mediapipe
What is Mediapipe?
Mediapipe is a framework mainly used for building multimodal audio, video, or any time series data. With the help of the MediaPipe framework, an impressive ML pipeline can be built for instance of inference models like TensorFlow, TFLite, and also for media processing functions.
Cutting edge ML models using Mediapipe
- Face Detection
- Multi-hand Tracking
- Hair Segmentation
- Object Detection and Tracking
- Objectron: 3D Object Detection and Tracking
- AutoFlip: Automatic video cropping pipeline
- Pose Estimation
Pose Estimation
Human pose estimation from video or a real-time feed plays a crucial role in various fields such as full-body gesture control, quantifying physical exercise, and sign language recognition. For example, it can be used as the base model for fitness, yoga, and dance applications. It finds its major part in augmented reality.
Media Pipe Pose is a framework for high-fidelity body pose tracking, which takes input from RGB video frames and infers 33 3D landmarks on the whole human. Current state-of-the-art approach methods rely primarily on powerful desktop environments for inferencing, whereas this method outperforms other methods and achieves very good results in real-time.
Pose Landmark Model
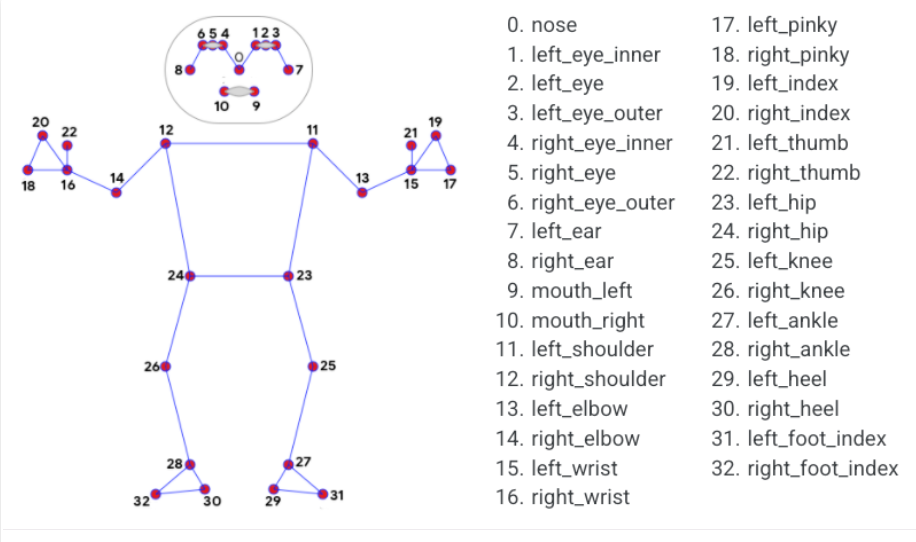
Source: https://google.github.io/mediapipe/solutions/pose.html
Now Let’s Get Started
First, install all the necessary libraries.
– pip install OpenCV-python
– pip install mediapipe
Download any kind of video for example dancing, running, etc. We will make use of that for our pose estimation. I am using the video provided in the link below.
(https://drive.google.com/file/d/1kFWHaAaeRU4biZ_1wKZlL4KCd0HSoNYd/view?usp=sharing)
To check if mediapipe is working, we will implement a small code using the above-downloaded video.
import cv2 import mediapipe as mp import time
mpPose = mp.solutions.pose
pose = mpPose.Pose()
mpDraw = mp.solutions.drawing_utils
#cap = cv2.VideoCapture(0)
cap = cv2.VideoCapture('a.mp4')
pTime = 0
while True:
success, img = cap.read()
imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
results = pose.process(imgRGB)
print(results.pose_landmarks)
if results.pose_landmarks:
mpDraw.draw_landmarks(img, results.pose_landmarks, mpPose.POSE_CONNECTIONS)
for id, lm in enumerate(results.pose_landmarks.landmark):
h, w,c = img.shape
print(id, lm)
cx, cy = int(lm.x*w), int(lm.y*h)
cv2.circle(img, (cx, cy), 5, (255,0,0), cv2.FILLED)
cTime = time.time()
fps = 1/(cTime-pTime)
pTime = cTime
cv2.putText(img, str(int(fps)), (50,50), cv2.FONT_HERSHEY_SIMPLEX,1,(255,0,0), 3)
cv2.imshow("Image", img)
cv2.waitKey(1)
In the above you can get easily that using OpenCV we are reading the frames from the video named ‘a.mp4’ and that frames are converted from BGR to RGB image and the using mediapipe we will draw the landmarks on the entire processed frames and finally, we will get video output with landmarks as shown below. The variables ‘cTime’, ‘pTime’, and ‘fps’ are used to calculate the reading frames per second. You can see the left corner in the below output for the number of frames.
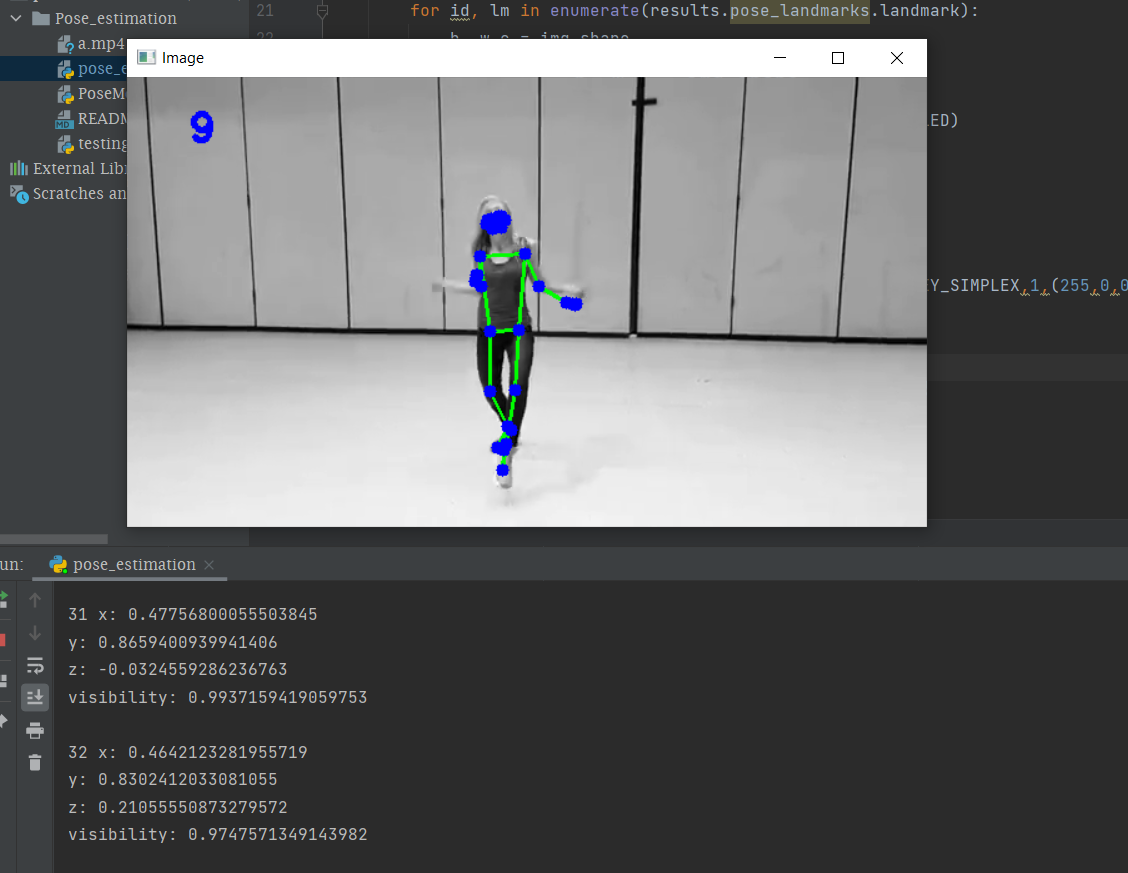
The output in the terminal section is the landmarks detected by mediapipe.
Pose Landmarks
You can see a list of pose landmarks in the terminal section of the above image. Each landmark consists of the following:
· x and y: These landmark coordinates normalized to [0.0, 1.0] by the image width and height respectively.
· z: This represents the landmark depth by keeping the depth at the midpoint of hips as the origin, and the smaller the value of z, the closer the landmark is to the camera. The magnitude of z uses almost the same scale as x.
· visibility: A value in [0.0, 1.0] indicating the probability of the landmark being visible in the image.
MediaPipe is running well and well.
Let us create a Module to estimate the pose and also that the module can be used for any further project related to posing estimation. Also, you can use it in real-time with the help of your webcam.
Create a python file with the name ‘PoseModule’
import cv2 import mediapipe as mp import time
class PoseDetector:
def __init__(self, mode = False, upBody = False, smooth=True, detectionCon = 0.5, trackCon = 0.5):
self.mode = mode
self.upBody = upBody
self.smooth = smooth
self.detectionCon = detectionCon
self.trackCon = trackCon
self.mpDraw = mp.solutions.drawing_utils
self.mpPose = mp.solutions.pose
self.pose = self.mpPose.Pose(self.mode, self.upBody, self.smooth, self.detectionCon, self.trackCon)
def findPose(self, img, draw=True):
imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
self.results = self.pose.process(imgRGB)
#print(results.pose_landmarks)
if self.results.pose_landmarks:
if draw:
self.mpDraw.draw_landmarks(img, self.results.pose_landmarks, self.mpPose.POSE_CONNECTIONS)
return img
def getPosition(self, img, draw=True):
lmList= []
if self.results.pose_landmarks:
for id, lm in enumerate(self.results.pose_landmarks.landmark):
h, w, c = img.shape
#print(id, lm)
cx, cy = int(lm.x * w), int(lm.y * h)
lmList.append([id, cx, cy])
if draw:
cv2.circle(img, (cx, cy), 5, (255, 0, 0), cv2.FILLED)
return lmList
def main():
cap = cv2.VideoCapture('videos/a.mp4') #make VideoCapture(0) for webcam
pTime = 0
detector = PoseDetector()
while True:
success, img = cap.read()
img = detector.findPose(img)
lmList = detector.getPosition(img)
print(lmList)
cTime = time.time()
fps = 1 / (cTime - pTime)
pTime = cTime
cv2.putText(img, str(int(fps)), (50, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 3)
cv2.imshow("Image", img)
cv2.waitKey(1)
if __name__ == "__main__":
main()
This is the code that you need for pose estimation, In the above, there is a class named ‘PoseDetector’, inside that we created two objects that are ‘findPose’ and ‘getPosition’. Here the object named ‘findPose’ will take the input frames and with help of mediapipe function called mpDraw, it will draw the landmarks across the body and the object ‘getPosition’ will get the coordinates of the detected region and also we can highlight any coordinate point with the help of this object.
In the main function, we will have a test run, you can take a live feed from the webcam by changing the first line in the main function to “cap = cv2.VideoCapture(0)”.
Since we created a class in the above file, we will make use of it in another file.
Now the final phase
import cv2 import time import PoseModule as pm
cap = cv2.VideoCapture(0)
pTime = 0
detector = pm.PoseDetector()
while True:
success, img = cap.read()
img = detector.findPose(img)
lmList = detector.getPosition(img)
print(lmList)
cTime = time.time()
fps = 1 / (cTime - pTime)
pTime = cTime
cv2.putText(img, str(int(fps)), (50, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 3)
cv2.imshow("Image", img)
cv2.waitKey(1)
Here the code will just invoke the above-created module and run the whole algorithm on the input video or the live feed from the webcam. Here is the output of the test video.

The complete code is available in the below GitHub link.
https://github.com/BakingBrains/Pose_estimation
Link to the Youtube video: https://www.youtube.com/watch?v=brwgBf6VB0I
If you have any queries please make use of the issue option in my GitHub repository.
Thank you
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.
I thrive on the thrill of the challenge, tackling complex problems and crafting innovative AI solutions that make a difference. Whether it's optimizing or building sustainable AI ecosystems, I believe in harnessing the power of AI for the greater good. Let's brainstorm, collaborate, and change the world, one byte at a time.




Hi. Great tutorial. Can you please tell me if I can use these technologies to build a virtual tryon app?
hey, can you people help me on my project. Am working on a project -sequence to sequence recognition and translation of sign language using pose estimation method. Can you direct me the best research papers that i should be citing