This article was published as a part of the Data Science Blogathon
ML + DevOps + Data Engineer = MLOPs
Origins
MLOps originated in 2015, from writing entitled “Hidden Technical Debt in Machine Learning Systems”. Since then, the rise has been particularly strong: considering that the MLOps market is established to succeed in $4 billion by 2025.
Introduction
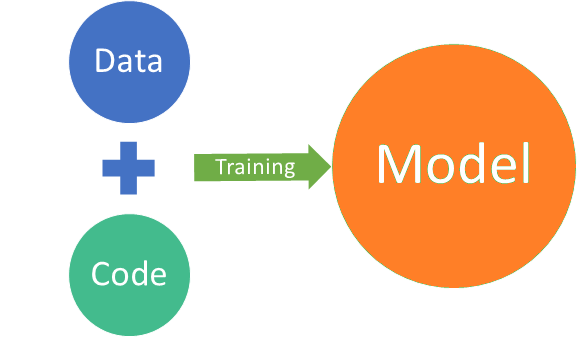
MLOps are intelligence that minimizes the gap uniting data scientists & production teams. It’s deep in nature and focuses on minimizing any wastage of resources and make ML systems more scalable by automating and receiving highly consistent information from ML models.
ML systems can be sub-divided into eight categories: data collection, data pre-processing, functional engineering, data labeling, model design, training and optimization, endpoint implementation & monitoring but need to be connected. It is the minimum number of systems a company has to scale machine learning throughout the organization.
This sector of conventional software program development, a hard and fast of practices called DevOps have made it viable to deliver software program to manufacturing in a tight timeframe and to preserve it walking reliably. DevOps is predicated on tools, automation, and workflows to summary away from the unintended complexity and permit builders’ consciousness at the real issues that need to be cracked. This technique has been so a hit that many corporations are already adept at it, so why can’t we truly preserve doing the identical factor for ML?
Advantages of MLOps
1. Realize rapid modernization through collaboration with ML lifecycle management
2. Modeling and simulation of workflows
3. Easy to use high-fidelity models
4. Efficient management at every stage of the ML life cycle
5. Resource management and control are also Very useful
Most data scientists are not avid programmers. You can build the most effective model of an ML problem, but you do not have the skills to package, test, implement, or maintain the model in a production environment. This requires people who understand databases, REST APIs, and a range of other IT skills. This is where Ml-Ops come in.
Tools for MLOps:
1.Kubeflow
2. Algorithmia
3. Pachyderm
2. MLflow
3. DataRobot
Challenges to MlOps
Although the continuous ML life cycle has been portrayed as a true “cycle”, the success of managing this end-to-end process throughout the organization is limited due to the
Following reasons:
Data scientists are usually not well-trained engineers, so they don’t always follow DevOps best practices
Data engineers, data scientists, and deployment engineers work in silos, creating tensions between teams
A Team
Since we have determined that building an ML requires a set of skills that were previously considered independent, to be successful, we need a hybrid team that collectively covers this area of expertise. Of course, one person can be good enough for everyone. In this case, we can call this person a complete machine learning operation and maintenance engineer. But the most likely situation is that a successful team consists of a data scientist or machine learning engineer, a DevOps engineer, and a data engineer.
The exact composition, organization, and team names may vary, but it is important to understand that data scientists cannot accomplish ML Ops goals alone. Even if an organization has all the necessary skills, it will not succeed if they do not work closely together.
Another important change is that data scientists must master basic software development skills, such as modularization, reuse, testing, and version control; it is not enough to just make the model work well on dirty notebooks. For this reason, many companies hold the title of machine learning engineer, highlighting these skills. In numerous cases, machine learning engineers many of the tasks need for machine learning.
ML Pipeline

One of the core concepts of data engineering is the data pipeline. A data pipeline is a series of modifications that registers the data between its source and target. They’re normally explained as a graph, where every node is a modification, and the edges show dependencies or executive order. There are various specialized tools that can help you create, manage, and run pipelines. The data pipeline can also be called the ETL pipeline (extract, transform, and load).
ML model always requires some form of data conversion, usually through scripts or even units in notebooks, so it is difficult to manage and execute reliably. Switching to the right data pipeline provides many advantages in terms of code reuse, runtime transparency, manageability, and scalability.
Since ML training can also be considered as a kind of data transformation, it makes sense to include certain ML steps in the data pipeline itself to transform it into an ML pipeline. Most models require 2 versions of the pipeline: one for training and one for maintenance. Because, as a rule, data formats and access paths, especially real-time operating models, often vary greatly. Time query (as opposed to batch prediction run).
Automation
The degree of automation of data pipelines, machine learning models, and code determines the advancement of the machine learning process. As you age, the speed at which you learn new models will increase. The goal of the MLOps group is to automatically implement ML models in the underlying software system or as a service component. It implies that each step of the machine learning process is automatic without human involution.
Automated testing can help you quickly identify problems early so that you can quickly correct mistakes and learn from them.
We have seen three stages of automation implemented by MLOps, from entry-level with training and manual model implementation to the automatic triggering of ML and CI/CD pipelines.
The handheld process is a typical data analysis process performed at the beginning of an ML implementation.
ML automation. The next stage involves automatically starting to train the model. Here we introduce continuous model learning.
CI/CD pipeline automation
As the last step, we introduced the CI/CD system to provide machine learning models quickly and reliably in a production environment. The foremost difference from the earlier step is that we are now automatic creating, testing, and establish data, machine learning. Machine learning pipeline models and components.
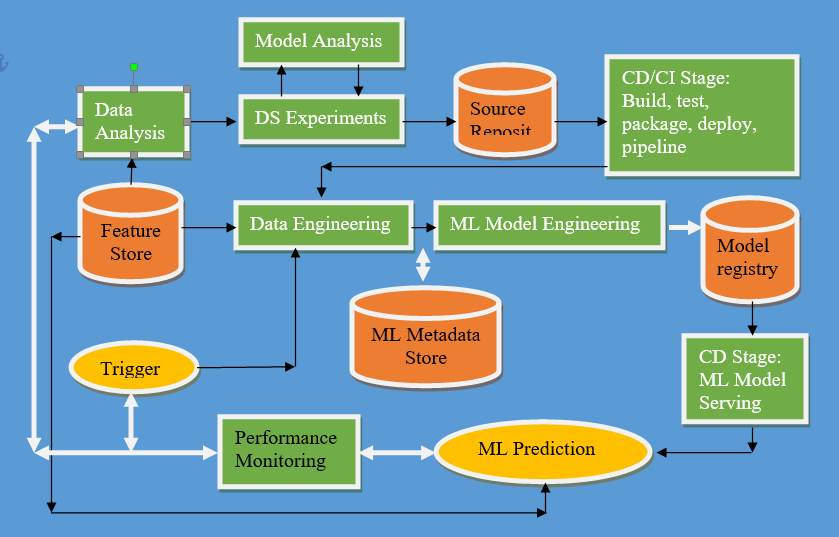
Continuous X
To understand the implementation of the model, we first define “ML assets” as the ML model, its parameters and hyperparameters, training scenarios, training, and test data. We are interested in the identities, components, versions, and dependencies of these machine learning artifacts. The target of machine learning artifacts can be (micro)services or infrastructure components. Provisioning services provide orchestration, logging, monitoring, and reporting to ensure the stability of machine learning models, code, and data artifacts.
It comprises of :
Continuous Integration (CI)
Continuous Delivery (CD)
Continuous Training (CT)
Continuous Monitoring (CM)
Version Control
The aim of version control is to treat ML training scenarios, ML models, and model training data sets as the main citizens in the DevOps process, and use a version control system to track ML models and data sets.
Tracking experiment
The development of machine learning is a highly regressive and research-oriented process. Unlike the conventional software development process, machine learning development allows you to run multiple model training experiments in parallel before deciding which model shall go into production.
Testing
Machine learning test training should include procedures to verify that the algorithm makes decisions that meet business goals, which means the loss rate of machine learning algorithms (MSE, log loss, etc.), user interaction, etc.)
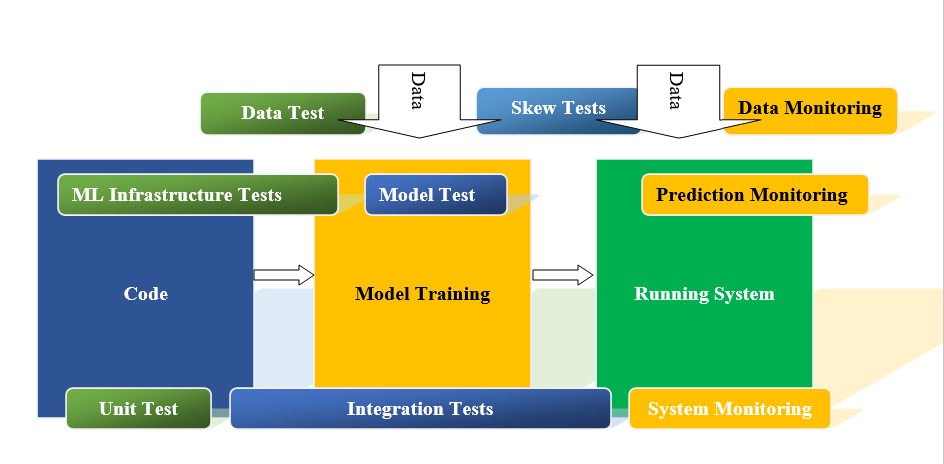
Machine learning test training should include procedures to verify that the algorithm makes decisions that meet business goals, which means the loss rate of machine learning algorithms (MSE, log loss, etc.), user interaction, etc.)
ML infrastructure test-
1) Test ML API usage. Stress testing
2) Test the algorithmic correctness
3) Integration testing
4) Validating the ML model before serving it
5) ML models are canaried before serving
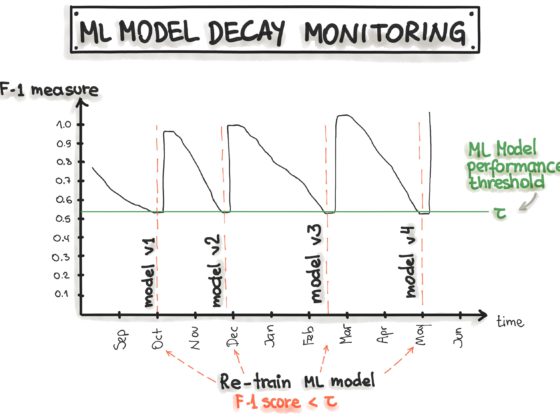
Monitoring
Once the ML model is implemented, it requires supervision to ensure that the ML model works as expected.
The final test score is calculated using the minimum of the aggregate scores of each data test, model test, infrastructure test, and monitoring test.
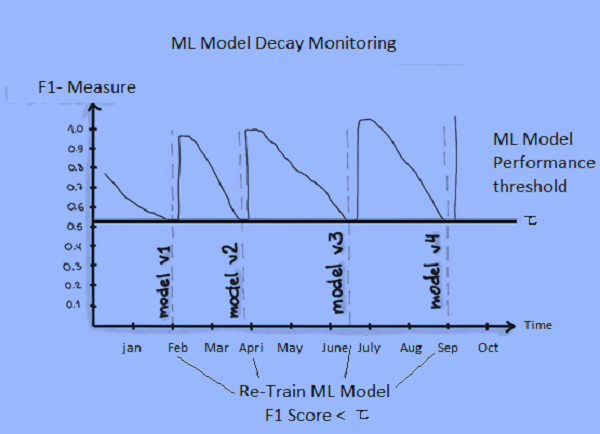
High Demand short supply
MLOps Engineer: Supply is scarce The emerging development of MLOps lacks experienced professionals.
Other shortcomings are:
1) The roles and authority of MLOps engineers at the organizational level lack clarity, especially at the new level.
2) Multiple platforms and training tools.
3) Lack of specific courses for MLOps engineers.
According to a 2020 study by Stanford University, despite the pandemic, private investment in the field of artificial intelligence has surged. According to the report, in the same year, China outperforms the United States in artificial intelligence research.
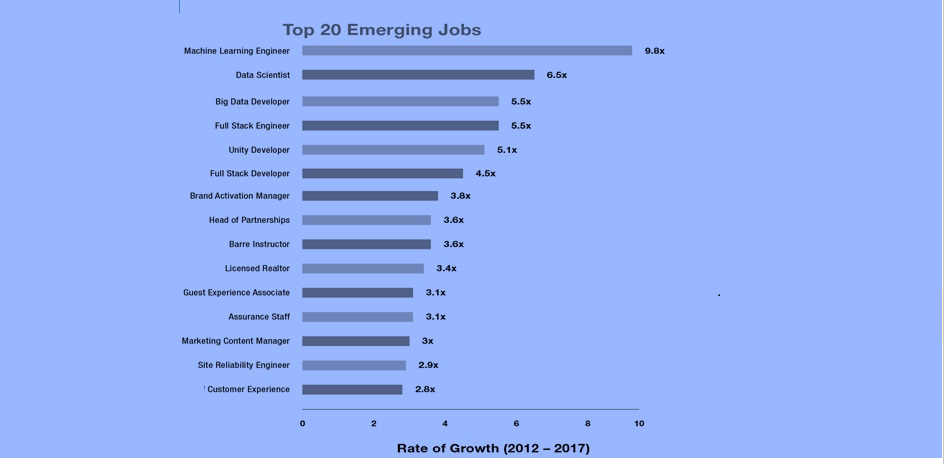
The ultimatum for data scientists and ML engineers has never been top. ML engineers are at the top of LinkedIn’s new job rankings and have grown 9.8 times in five years (2012-2017)
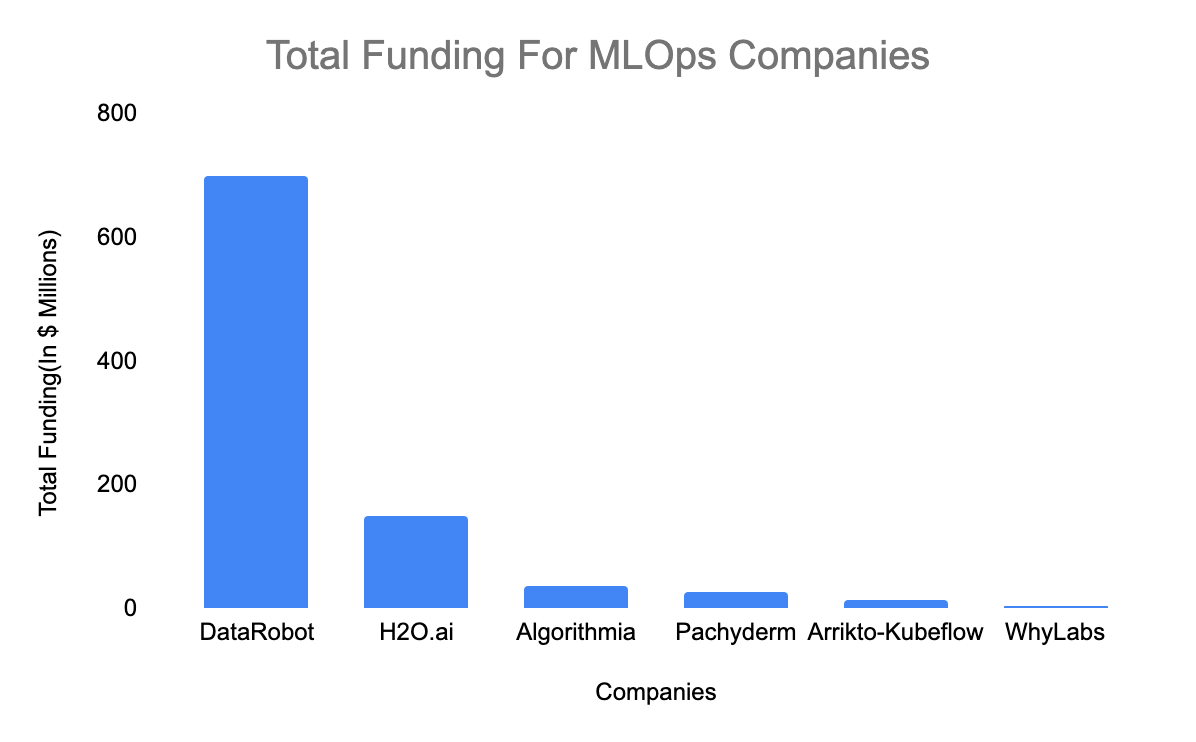
and Here is the funding by the companies on MLPOs
Conclusion
Ml-Ops is a wide field with a mix of ML DS DevOps, Cloud concepts that can’t be mastered by a single individual. Hence there is a need to design specific curriculum & training programs for the MlOps domain to eradicate the gap between demand and supply of highly demanding domains of Artificial Intelligence.







{kind=link}
{kind=link}
{kind=link}