This article was published as a part of the Data Science Blogathon.
Introduction to MLOps
I believe all you’re familiar with the terminology DevOps for these many years, this is the complete culture and process life cycle of CI/CD. Yes! This is the best fit for the traditional software that is managed in the production environment very effectively with a well-defined strategic path by Development and Operational team members, to make sure all issues are fixed keep applications of high quality. That’s a well-known thing across.
Now we’re in AIML fever, all customers are looking for AIML implementation is to improve the business opportunities. So, the industry throwing the new abbreviation called MLOps from an ML implementation perspective. In this article, we’re going to discuss MLOps and their effectiveness.
Based on my personal experience the MLOps is an influential and high demand role in this digital transformation world. I mean when we are handling Machine Learning projects in large scale implementations, irrespective of domains where were deploying the model and getting the benefit out of it. Since data is growing in phenomenon ways.
I am writing this article by keeping in my mind with already you’re familiar with the Machine Learning life cycle and other matters around that. I promise that your reading time would be much more effective and understanding the End-to-end on the proposed topic.
Let’s understand DevOps first quickly, this is well-established culture on CI/CD for developing software applications and moving into production on the streamlined process with a dedicated set of tools its ecosystem is tightly coupled to two different teams.
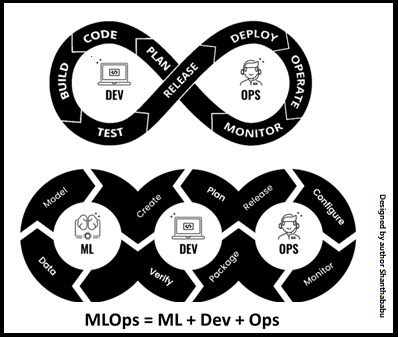
How MLOps is different from DevOps, typical It requires a CI/CD pattern, along with a retraining stage before moving into the production for the trained and tested model. The main reason behind this is to understand the unseen data. Hope you know that the data would keep on changing and growing in different aspects across by the behaviour of business, so ultimately the demand for the product keeps changing in months or years due to many factors around.
What is MLOps?
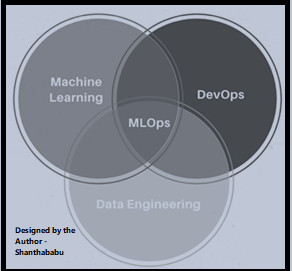
MLOps, short for “Machine Learning Operations,” refers to the practices and techniques employed to streamline and manage the lifecycle of machine learning (ML) models in production environments. It combines principles from machine learning, software engineering, and DevOps to facilitate the development, deployment, monitoring, and maintenance of ML models at scale.
MLOps aims to bridge the gap between data scientists, who build and train ML models, and IT operations teams, responsible for deploying and managing the models in production. It involves establishing robust workflows, automation, and collaboration processes to ensure the efficient and reliable deployment of ML models.
Key components of MLOps include version control for ML models and associated code, continuous integration and deployment (CI/CD) pipelines, infrastructure management, data management, model monitoring and logging, and governance and compliance measures. By implementing MLOps practices, organizations can enhance the reproducibility, scalability, reliability, and governance of their ML deployments, leading to improved model performance, faster iteration cycles, and reduced operational risks.
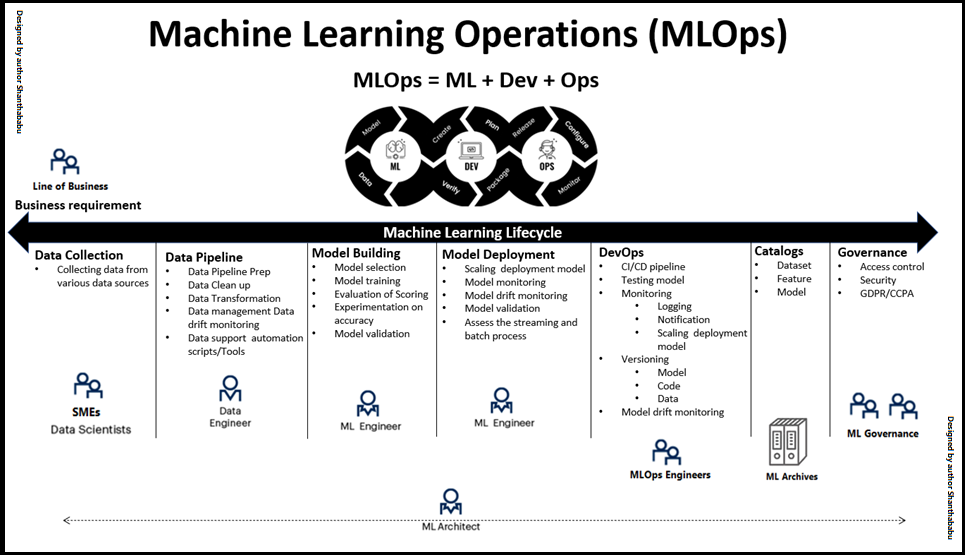
In one step further, MLOps is a new collaboration and set of procedures among the group of people, which includes Business team, SMEs, Statistics, Data Scientists, Data Engineers, Machine Learning Engineers and Architect, DevOps-MLOps experts, and Software Engineers, the size of the team could be different based on the size of an organization.
Apparently, there are a set of best practices to reinforce the quality and improve the management processes, and automate the models are deployment in a medium and large-scale Machine Learning production environment.
The simple representation of MLOPs.
The below image shows the detailed processes involved in MLOps
The Fundamentals truth of MLOps is “Enabler of the quality-outcomes in the production environment(s)”
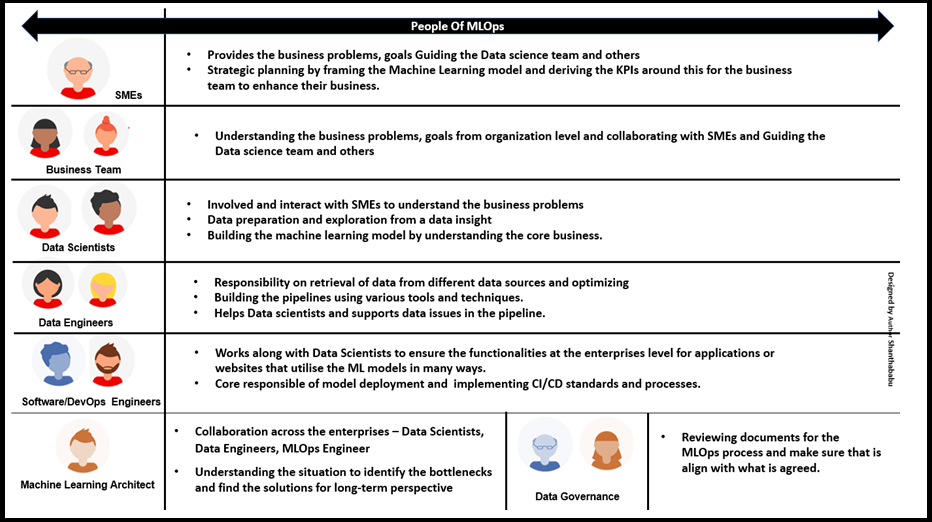
MLOps People
Since the Machine Learning discipline is constantly evolving and bringing multiple new roles and responsibilities to strengthen the discipline to drive with best practices. Let’s understand the People of MLOps, its means that the people who are all playing a key role in the Machine Learning life cycle are working together to implement and execute the greater milestones under the name of MLOps.
SMEs (Subject Matter Exports): SMEs are first and chief role in ML after all others, He/She only provides the business problems, goals and guiding the Data science team and others make to understand the model performance and its strategic planning by framing the Machine Learning model and deriving the KPIs around this for the business team to enrich their business. Same time they never fail to set up a feedback loop on the system to be flagged if any, abnormalities need to be fine-tuned in the model further.
The entire Machine Learning life cycle starts and ends with them.
Data Engineers
Data Engineers has a core responsibility on retrieval of data from different data sources and optimising them and building the pipelines using mixed tools and techniques, all these data to eventually power the Machine Learning models. He/She always closely working with SMEs/Business team to identify the right data, which helps immensely for Data scientists and supports data issues in the pipeline that might cause a model performance.
The Machine Learning life cycle Data Engineers roles are the core reason for quality data pipeline and addressing underlying issues when it comes from the representative areas.
Data Scientists
As we know Data Scientists are the backbone of Machine Leaning projects right from the beginning and they all have to be considered when building MLOps strategies. They are usually involved and interact with SMEs to understand the business problems and build the machine learning model by understanding the core business. These people only dive into and get their hands are dirty right from data preparation and exploration from a data insight perspective. Certainly, they are get handed off to Data Engineers for target data. Even some small/medium scale industries data scientists themselves manage the end-to-end ML life cycle.
In earlier days, Data Scientists had to continuously evaluate the model performance and ensure the business expectations, at the same time they have to work on changes in the production model and validate against the data and deploy back to production. Nowadays these tasks are assigned to the role called Machine Learning Engineers along with a few more responsibilities. This way industries are building the MLOps model very effectively.
Software/DevOps Engineers
Software Engineers are not certainly, building the ML models, Yes! Of Course, we know this clearly, But in the MLOps world. Here Data Scientists and Software Engineers work together to ensure the functionalities at the enterprises level for applications or websites that utilise the ML models in many ways. So MLOps is the way for both of them to collaborate in the same mode to understand how different models are deployed across along with applications to fit into CI/CD standards and processes. These people are might call out as MLOps Engineers. Here some of the quick responsibilities are listed below.
- Basic understanding of the ML specific applications.
- They used to put the model into production, before that they would test it and ensure that it is working fine as expected along with specifically designed UI,
- Make sure that the ML application is scalable and extendable by calling them in API or other modes.
- Have to ensure that the application can handle the entering data.
- On top of that, they should understand the cloud deployment process since most of the models and applications are in the cloud environment.
Machine Learning Architect
ML Architects are playing a critical role MLOps, basically these people are Data Architects, due to the current demand in the AIML world, just knowledge on understanding the overall data needs across the business, how data ins, outs data stored and consumed perception, on top how ML model works with data, algorithm along with data pipelines are built by Data Engineers and providing improvisation in all standpoints in ML implementation in a meticulous way. Actually, speaking below are the high-level responsible
- Collaboration across the enterprises – Data Scientists, Data Engineers, MLOps Engineer
- They should understand the situation to identify the bottlenecks and find the solutions for the long-term perspective.
- Identify the right resource, technology and tools for ML implementations
- Orchestrion of the entire ML life cycle, and make sure the sustainable production model performance.
Designed by the author Shanthababu
If you want to understand MLOps needs to have at least a cursory understanding of the below l. Let’s go deeper into that.
Developing Models | Preparing for Production | Deploying to Production | Monitoring and
Feedback Loop | Model Governance
Developing Models
As we know Model Developing is the key element in the ML life cycle. The ability of this stage is depending on the goals and sizes of the business. It varies from simple, medium and complex. Once the Data Collection is done for a kick-start for model building or development then this stage is predominantly based on the statistical, machine learning algorithms using Python, R, Tensor Flow, Keras and other available tools to achieve the generalised model. The most common target in structured data is predictive & classification based problems and other parts are quite advanced levels of models with a larger group of tools and technology.
The below image represents the components, that is mainly used during developing and evolving the models.
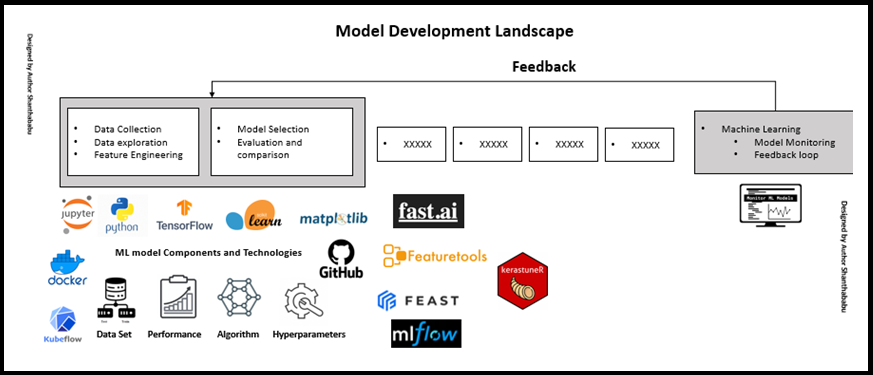
Data Explorations:
This step is very important in ML/MLOps lifecycle to understand the data in closer look and distribution, correlations and summarizing statistics representation of the given data set. At the same time will ensure the cleaning, filling, reshaping, and sampling then will go with the dataset is fine to train a model.

Designed by the author Shanthababu
Feature Engineering
The FEATURE is nothing but the character or a set of characteristics of a given Dataset. Simply saying that the given fields/attributes in the given dataset, when these fields/characteristics are converted into some measurable form. I mean in Numeric values, then they are called features. Mostly Numeric data type is attributes are straight features for the analysis. Sometimes Characters/String/non-numeric types are to be converted into measurable form (Numeric) to analyse the given dataset.
A feature engineering includes a blow list.
- Feature Improvements
- Feature Selection
- Feature Extraction.
- Feature Construction,
- Feature Transformations
- Feature Learning
In the market there are multiple Feature Engineering tools are available.

Does, Feature Selection will impact MLOps Policies, yes! Of course!
Adding more features may produce a more accurate model, apparently, the model becomes more expensive computation power, maintenance, and loss of the stability of the model and leading to some governance issues. With help of Auto-Sklearn and AutoML, open sources would help us to improve the performance and reduce the more human intervention.
Next to Feature Selection, Versioning and Model Reproducibility is the big challenging part during the Model Development and Evolution. Since during this stage there are multiple versions of models would be created with many combinations by Data Scientists, so have to create multiple branches and keep the version for reference for future model reproducibility whenever they need to perform reproducibility workouts. In the Morden digital world, there are many version control tools are available to maintain the version and history. Evidently, this stage is most critical and tangible in all aspects of MLOps life.
Preparation and Deploying into Production
Do you think the models running in the development environment would behave the same in a production environment, don’t think too much, undoubtedly
not, this is the reality. Because the production environment size would be changed from small to complex. The model will be in Kubernetes clusters, in the
form of API Services, TensorFlow Serving and etc., even though the business is having many challenges due to the lack of appropriate tools and processes and
consequence a large impact when they are moving into production. There would be many reasons behind that, quickly I can say example that the model is developed using Python programming language and its own libraries, and then in the production environment in Java-specific, so the migration process expects PMML format input to run the java-based model. But in the market, there are multiple tools are available, So you need not worry.
PMML – Predictive Model Markup Language is an XML- format, which is based on predictive model interchange, which was designed by Dr Robert Lee Grossman Wikipedia
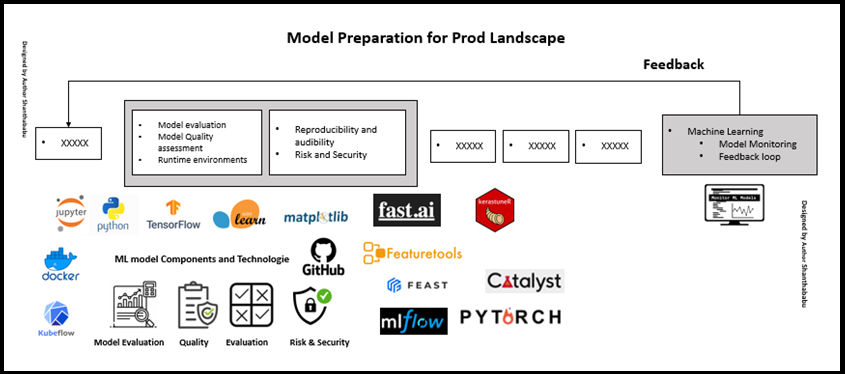
Below are the factors we should be considered when dealing with model preparation and deployment into production.
- Considerations of tools, already we have discussed in the above.
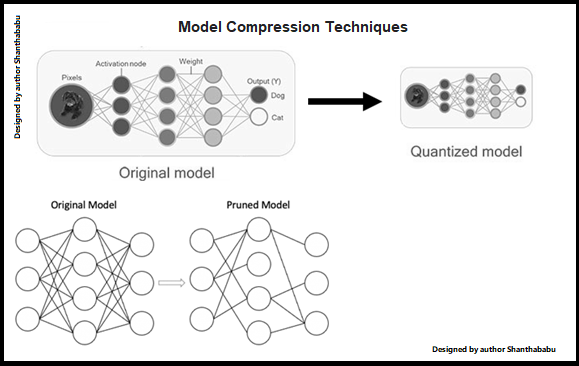
- Performance of the model: To bring a better model performance, there
must be compression optimisation techniques in place – like quantization,
pruning and distillation, so that the model size allows inference speed up and
saves compute energy without major accuracy losses.
Designed by the author Shanthababu
Let’s discuss a few facets of Model Risk and Security.
With respect to Model Risk, the below factors are the root cause for the model getting into the risk.
- Poor quality of Training data during the training period
- The huge gap between real/production data and training data
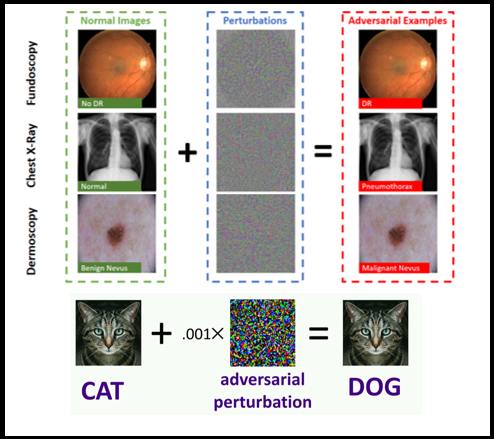
- Adversarial attacks
- Model incompatibility at runtime
- Unethical usage of machine learning and misinterpretation of model inputs
- Etc.,
Machine Learning Auditability
MLOps practise are giving the guidelines to align with goals by creating the appropriate documentation and capturing all the data sources, model(s) and purpose of the ML implementation and overall QA in authoritative formats for auditing assessment. This practice would help continuous improvements and tracks of actions during different phases of the ML journey.
Machine Learning Security
When we’re concerned the Q&A and Auditing, we shouldn’t forget the security aspects, Since the attackers introduce the sickening and shocking data that causes our models to behave in unforeseen ways and given irrelevant accuracy and radically change the predictions & classifications values and bringing down the model score. Especially when dealing with deep learning techniques the influence of adversarial attacks are massive and the predictions are drastically hit the final predictions. Same time ML model itself gives way to leak the personal data like name, sex, dob, address and etc., all these factors have to be addressed in Model governance practises and on top of the supplementary data security system should be in place for organization-specific and based on their nature of the business.
Deploying into Production
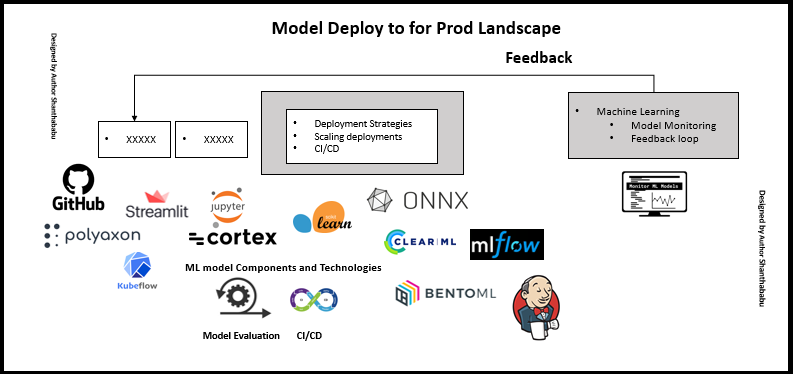
Designed by the author Shanthababu
As we‘re familiar with CI/CD for traditional software development and suitable for the Machine Learning based project too. Here I could like to strongly recommend CI/CD for MLOps because this culture ultimately fulfils the business needs. especially the model deployment into production and support their business values in streamlined. Once Data Science and ML team have developed the working version, they would push the set of artefacts into CI/CD pipeline. While conferring the CI/CD we have to keep it in our mind about versioning, GitHub is the best choice for this to push the code into other environments like testing, production followed by one after another along with appropriate documents. Jenkins is the best choice to orchestrate all these processes.
When we are moving into Deployment, we have to make sure that what categories of our model deployment and followed by this will work on deployment strategies.
The model would be two different categories Batch Scoring and Real-time scoring
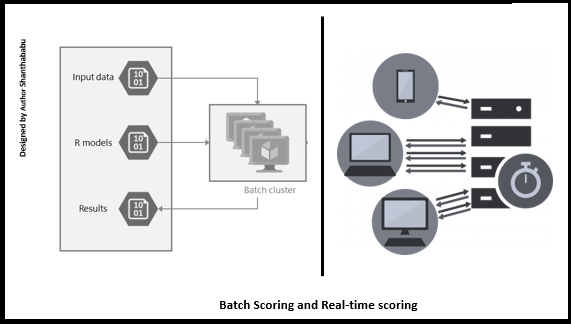
The model would be two different categories Batch Scoring and Real-time scoring
Batch Scoring: This is very familiar in this industry job scheduling make it simple, in which the entire datasets are processed using the model. It would be daily, hourly basis based on the demand.
Real-time Scoring: Feeding the live data into deployed models in the form of web services to make real-time predictions using Kubernetes services to achieve high-scale production deployments.
Deployment Strategies: Coming into Deployment Strategies., in short, we can call out this as the IDDR model.
- I-Integration
- D-Delivery
- D-Deployment
- R-Release
Integration: Process of merging the required files and artefacts – CI
Delivery: Process of building a valid package and ready for deployment into production.
Deployment: Deploying model into target system either manual or automates, the second option is preferred-one by the business, since this could add value to the business.
Release: Moving an updated version of the model into the production environment for many reasons.
Methods for Deploy Machine Learning Models
- As Web services
- On-demand batch
- Embedded models.
As Web services: This is one of the simplest ways to deploy the machine learning model in the form of web-service for prediction-classification based models. the Flask framework is one of the best options for these types of deployments
On-demand batch: Batch prediction models are simply called the respective function along with the target dataset as the input variables for on-demand assessments.
Embedded models: As the name implies it includes the devices like Mobile, Tablets, Gadgets, IoT and IIoT. It has its own benefits of deploying a machine learning model on these devices with lower data bandwidths and low latency.
Model Monitoring and Feedback Loop
So far, we have discussed different stages in MLOps, one Model monitoring and feedback is the major and deciding the success-rate, of our model in production. After we deployed the models into the production and we are expected to monitor, the performance, since we considered the set of hypotheses, on production data will be similar to trained and test data during model building and evolution. 90-95% of all our assumptions do not stand with us. Because of the trends change over the period, as we know people’s interests always vary from season to season. So, the model deployment process is to be considered as a continuous process across and rather than deploying the model once in the production and focusing on another ML implementation project, undoubtedly this is not like a traditional software development how it works.
Once the model has been moved into production, it needs to be monitored carefully, because the business outcome from the model could be influenced by external factors, due to Data drift, Model drift and finally ends with Concepts drift.
so that the model could start degrading sooner in the production.
In the ML world, the model needs to be monitored and giving its feedback for the retraining phase is indeed a step to stabilize the model to achieve the goals of the organization, with unseen data and to address the drift challenges pertaining to the model performance improvements as it continues the process.
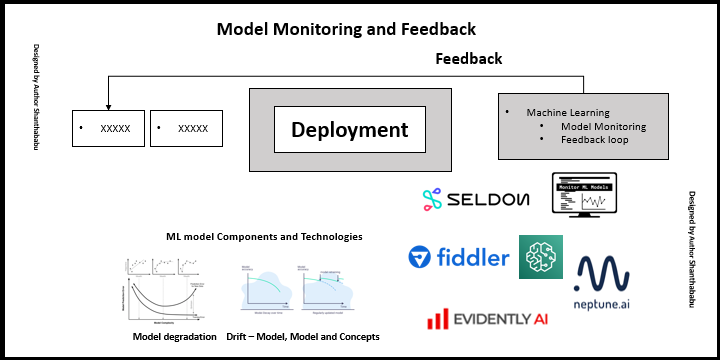
Designed by the author Shanthababu
As I pointed out above, if retraining is a continuous process, then there might be a question about, how often we should retrain. Hourly? or Daily? or Weekly? or Monthly? or Yearly? my straight answer is depending on the following factors domain and cost. If the domains are very sensitive areas like trending or recommendation systems or voice recognition, then there should be regular retaining and organisation should know the cost impact on this and eventually, they should realise the performance in the considerable figure by x%.
Governance in MLOps
Governance is a set of goals to ensure that the business has to deliver on its responsibilities starting with stakeholders, employees and to public. The key focus on financial, personal, legal and ethical depends on banking, finance, health care and retail sectors. I believe you are all aware that there are data-specific regulations implemented to protect public data from business usage. In UK & Europe, there is GDPR (General-Data-Protection-Regulation and from the US – CCPA (California-Consumer-Privacy-Act).
With respect to MLOps, the governance initiatives are into two categories.
- Data Governance
- Process Governance
Data Governance: Always deals with the data being used during the model training and testing, and make sure the below criteria.
- Source of the data and evidence for the same
- Data has been collected as per the standard process and terms and conditions
- Data is valid and meets the requirements for the ML implementations
- Is Data has been collected based on the GDPR/CCAP/PII norms
Process Governance: This involves documenting the MLOps process and aligning with this and getting into an agreement.
- Make sure all the validations are carried out before moving into production with agreed timelines.
Frequently Asked Questions
Q1. What is MLOps used for?
A. MLOps is used to streamline and manage the lifecycle of machine learning models in production, ensuring efficient development, deployment, monitoring, and maintenance. It helps enhance model performance, enable faster iteration cycles, and reduce operational risks by combining machine learning, software engineering, and DevOps practices.
Q2. What is the salary of MLOps engineer in India?
A. The salary of an MLOps engineer in India can vary based on factors such as experience, location, company size, and industry. On average, an entry-level MLOps engineer in India can earn around ₹6-10 lakhs per year. With a few years of experience, the salary can range from ₹10-20 lakhs per year. Senior MLOps engineers with extensive experience and expertise can earn higher salaries, ranging from ₹20-30 lakhs or more per year. These figures are approximate and can vary significantly depending on various factors mentioned earlier.
Conclusion
Guys! so far, we have discussed very detailed steps and processes involved in the MLOps. Be remember this is a very expansive area, we couldn’t accommodate this simple article.
The key takeaways from this article are as follows:
- MLOps People and their roles and responsibilities.
- Workflow of Development, Preparation and Deploying of the Model and its challenges.
- Importance of Model Monitoring and Feedback Loop in MLOps.
- The strategy of Governance in MLOps.
- Overall understanding of MLOps Culture End-to-End.
On top of that, The ML implementation is something similar to working nicely in demo or test sites and no guarantee it will work fine in production because in the real-time scenario models have to play with unseen data. So, making hands are dirty on the green field is the real challenge here. And in recent years there are many more open sources are evolved and the list is growing. I entrust, in the near future most of the challenges will be addressed and the process will be well streamlined. Thanks for your time. I will connect with you all, about some interesting topics shortly.
Read our latest articles on the blog.
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.
Shanthababu Pandian has over 23 years of IT experience, specializing in data architecting, engineering, analytics, DQ&G, data science, ML, and Gen AI. He holds a BE in electronics and communication engineering and three Master’s degrees (M.Tech, MBA, M.S.) from a prestigious Indian university. He has completed postgraduate programs in AIML from the University of Texas and data science from IIT Guwahati. He is a director of data and AI in London, UK, leading data-driven transformation programs focusing on team building and nurturing AIML and Gen AI. He helps global clients achieve business value through scalable data engineering and AI technologies. He is also a national and international speaker, author, technical reviewer, and blogger.






