This article was published as a part of the Data Science Blogathon
Since the initial breakthrough in Computer Vision achieved by A. Krizhevsky et al. (2012) and their AlexNet Network, we have definitely come a long way. Computer Vision has since been making its way into day-to-day human lives without even us knowing about it. The one thing Deep Learning Algorithms need is data, and with the progress in portable camera technology in our mobile devices, we have it. A lot more, and a lot better. With great data, comes great responsibility. Data Scientists and Vision Engineers have been using data to create value in the form of awesome Vision applications.
Computer Vision has found applications in very diverse and challenging fields and these algorithms have been able to assist, and in some cases, outperform human beings. Be it Medical Diagnosis (Biology), Production Automation (Industry), Recommender Systems (Marketing), or everyday activities like driving or even shopping, Vision Systems are everywhere around us. In this blog, I am going to discuss some applications of computer vision, and how companies are implementing scalable vision systems to solve problems and generate value for their customers.
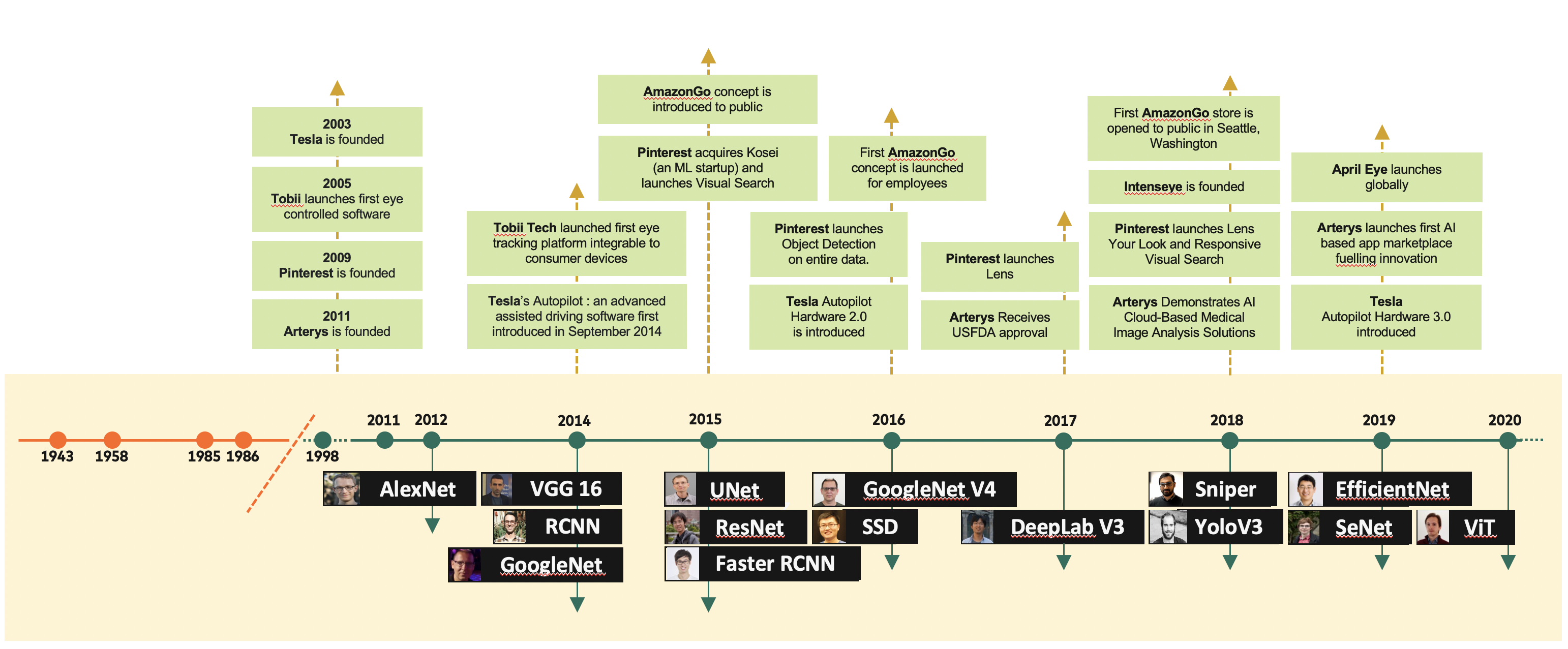
A timeline of some seminal computer vision papers against milestone events in computer vision product applications
Self Driving Vehicles
Self Driving Vehicles appeared to be a futuristic concept, just a few years ago, but they are here. A lot of effort was made in developing purely self-driving vehicles, but with real-world roads, human drivers, and a lot of other complexities, many such endeavours failed eventually, one of the big names being Uber. Starting with AI-assisted Human Drivers, and not leaping to Autonomous Driving Vehicles has proved to be a brilliant move by some of the players, the most notable of them being Tesla.

Tesla was one of the early companies to ditch LiDAR-based driving systems and is one of the few to bet completely on Computer Vision and Radar to guide its fleet. According to Andrej Karpathy, the Director of AI and Autopilot Vision at Tesla, LiDAR is very expensive compared to cameras, and there is a need to pre-scan localities using LiDAR for a vehicle to be able to use the LiDAR-based tech-stack for guided driving on the roads, which massively limits the places where a vehicle can go autonomously. While LiDAR data is good for object detection, the same can’t be said for its image recognition capability. More recently, Tesla has even ditched Radar and is now shipping units guided only by their Vision algorithms. Their vision systems are so reliable that Radar actually adds noise to their models!
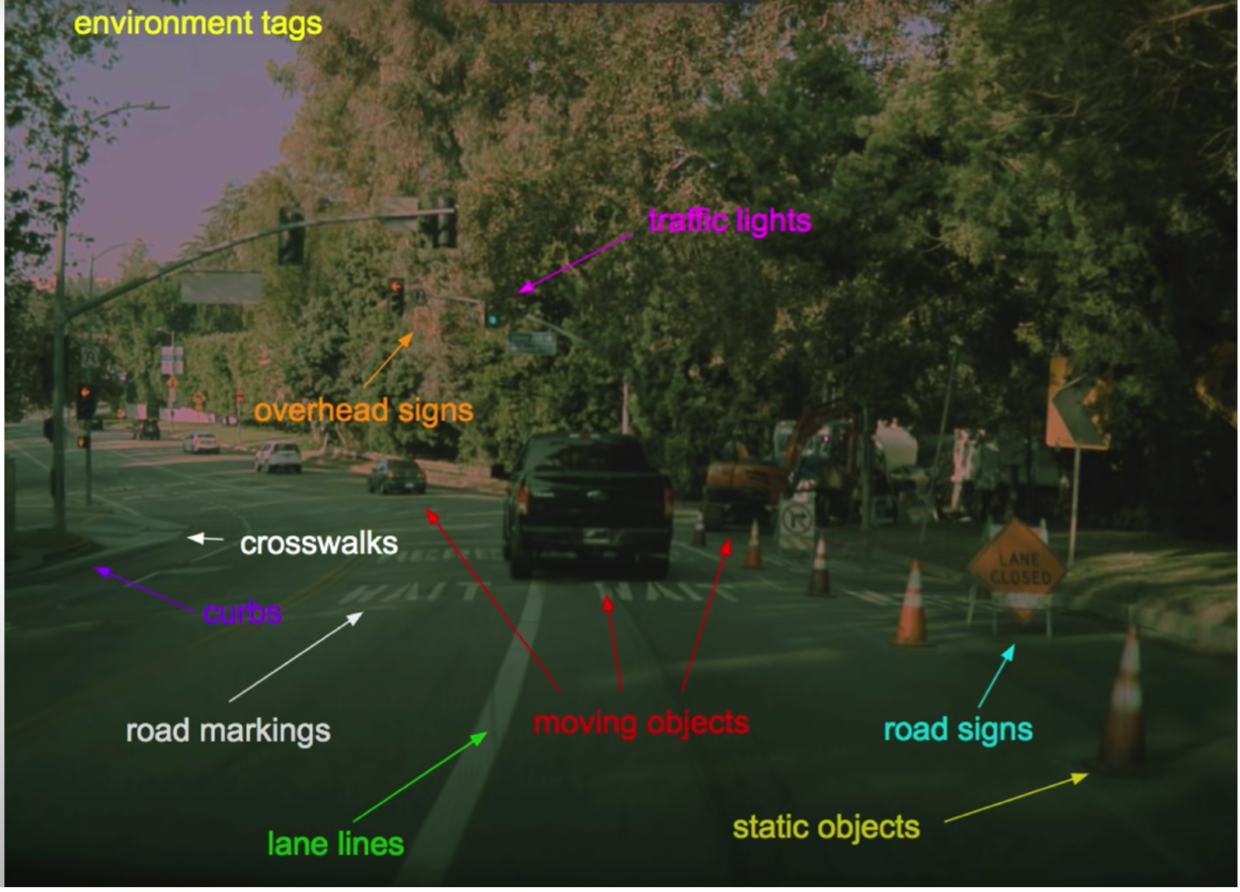
Tesla uses 8 cameras on the vehicle to feed their models, and the models do pretty much everything that can be done using video data, to guide the vehicle. The granular sub-applications that Tesla Autopilot needs to function are:
- Detection and Recognition of Objects (Road Signs, Crosswalks, Traffic Lights, Curbs, Road Markings, Moving Objects, Static Objects) (Object Detection)
- Following the Car Ahead (Object Tracking)
- Differentiating between Lanes/ Lanes and Sidewalk / Switching Lanes (Semantic Segmentation)
- Identifying Specific Objects (Instance Segmentation)
- Responding to events (Action Recognition)
- Smart Summon (Road Edge Detection)
- Depth Estimation
Evidently, this is an extremely multitasked setting, where there is a need to know a lot about the scene at once. That is why the tech stack is designed in such a way that there are multiple outputs for a given input sequence of images. The way it is implemented is that for a set of similar tasks, there is a shared backbone, with a set of tasks, at the end, all of which give a specific output.
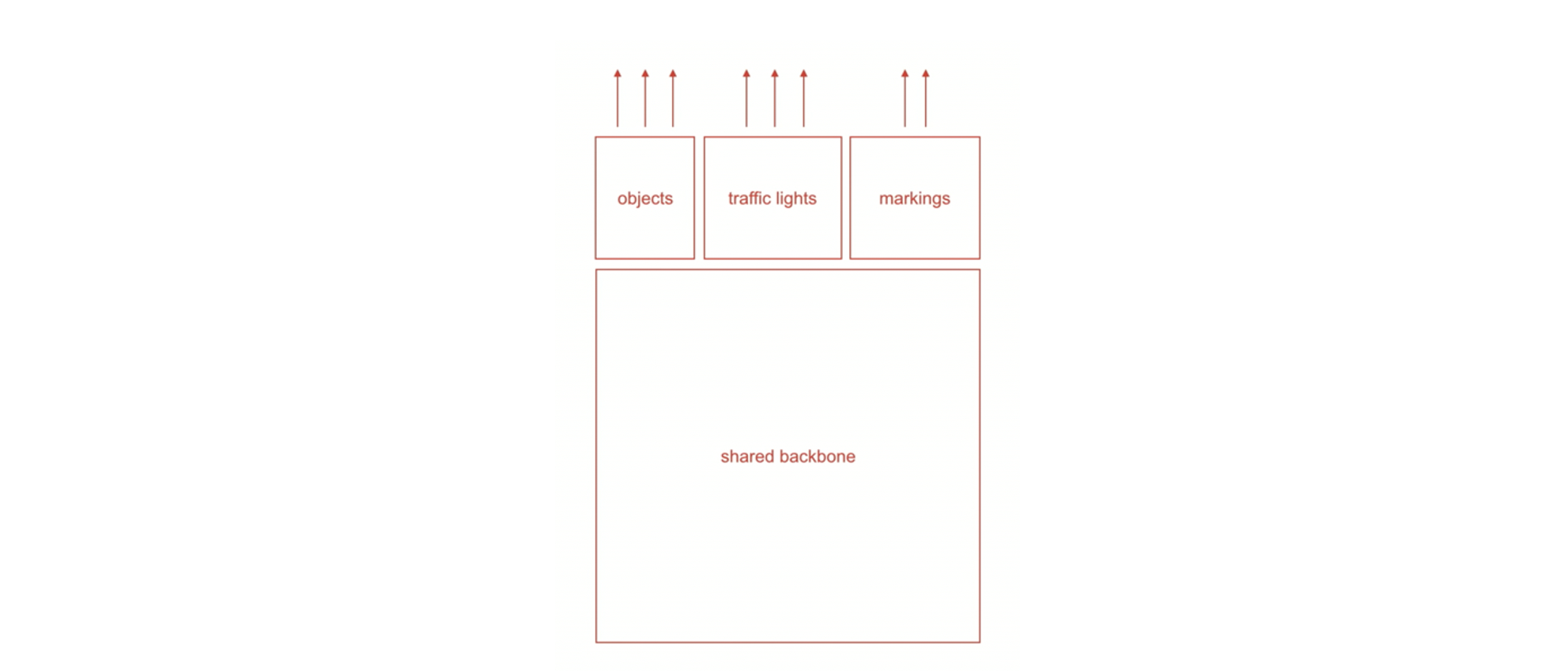
These networks have been termed HydraNets by Tesla. Going into the specifics, these shared backbones are ResNet-50(2015) like networks. The task-specific heads are UNet(2015)/DeepLabV3(2017) like structures that run on the output weights from the shared backbone.
Some tasks require features from specific camera feeds to make a prediction, so each camera has its own HydraNet trained for camera-specific tasks. But there are more complicated tasks like steering the wheel, depth estimation, or estimating road layout, which might need information from multiple cameras, and therefore, features from multiple HydraNets at the same time to make a prediction. Many of these complicated tasks can be recurrent, adding another layer of complexity to the network.
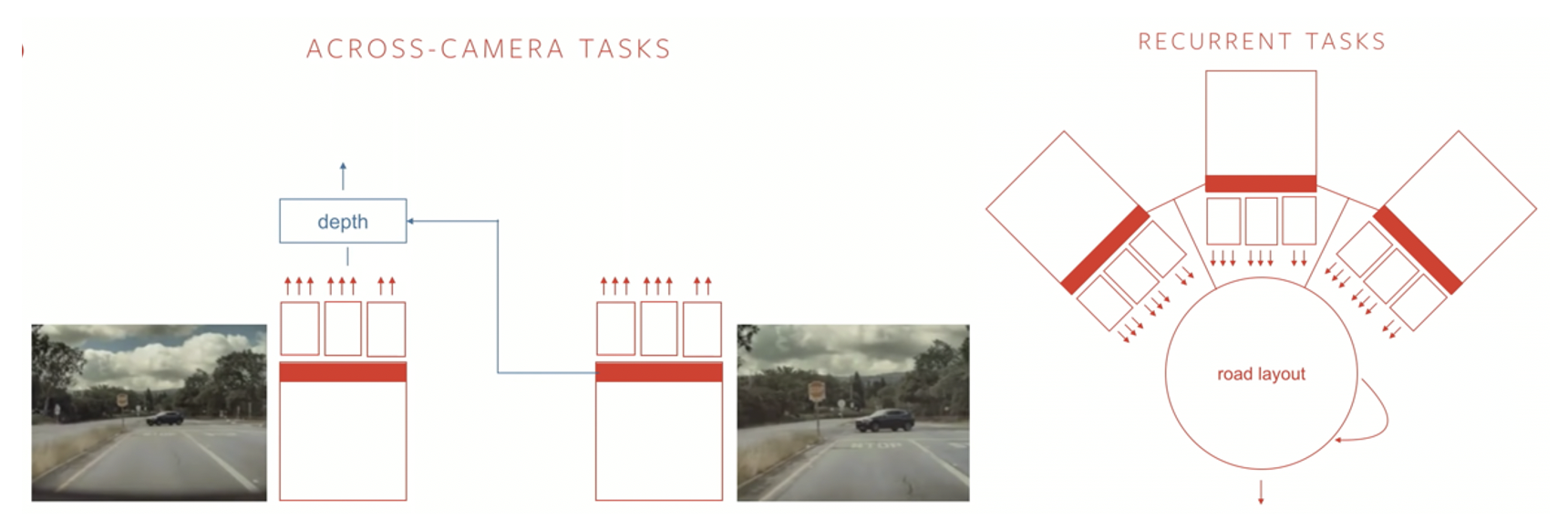
Summing it up, Tesla’s Network consists of 8 HydraNets (for 8 cameras), each responsible for specific tasks. In addition to that, the features from these HydraNets go into another run of processing which requires camera interactions with each other, and spread over time, to derive meaningful insights and is responsible for more complex tasks.
According to Tesla, there are nearly a hundred such tasks. This modular approach has many benefits for Tesla’s specific use case:
- It allows the network to be specifically trained for specific tasks. The network is subsampled for that specific task and is then trained for it.
- It drastically reduces the overall number of trainable parameters, thus amortizing the process.
- It allows certain tasks to be run in shadow mode while the overall system performs as usual.
- It allows for quicker improvements to the overall network, as updates can be installed in parts rather than overall.
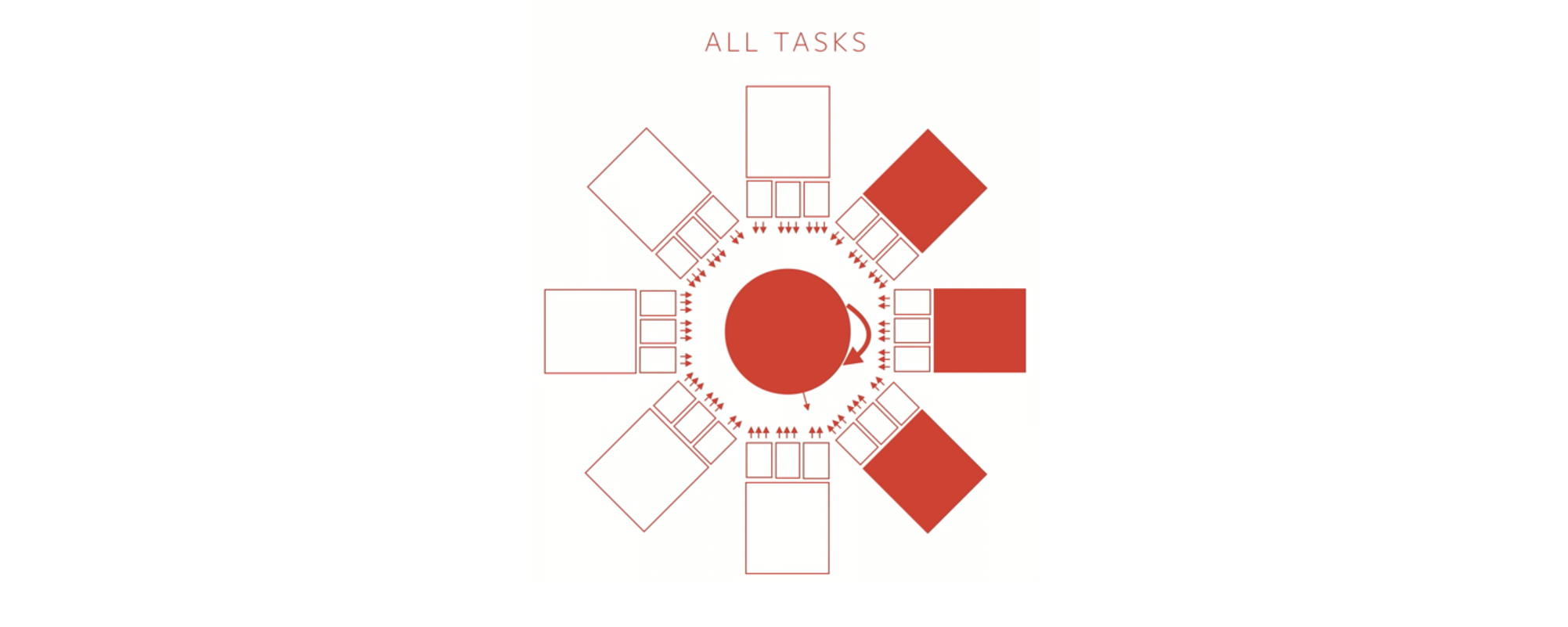
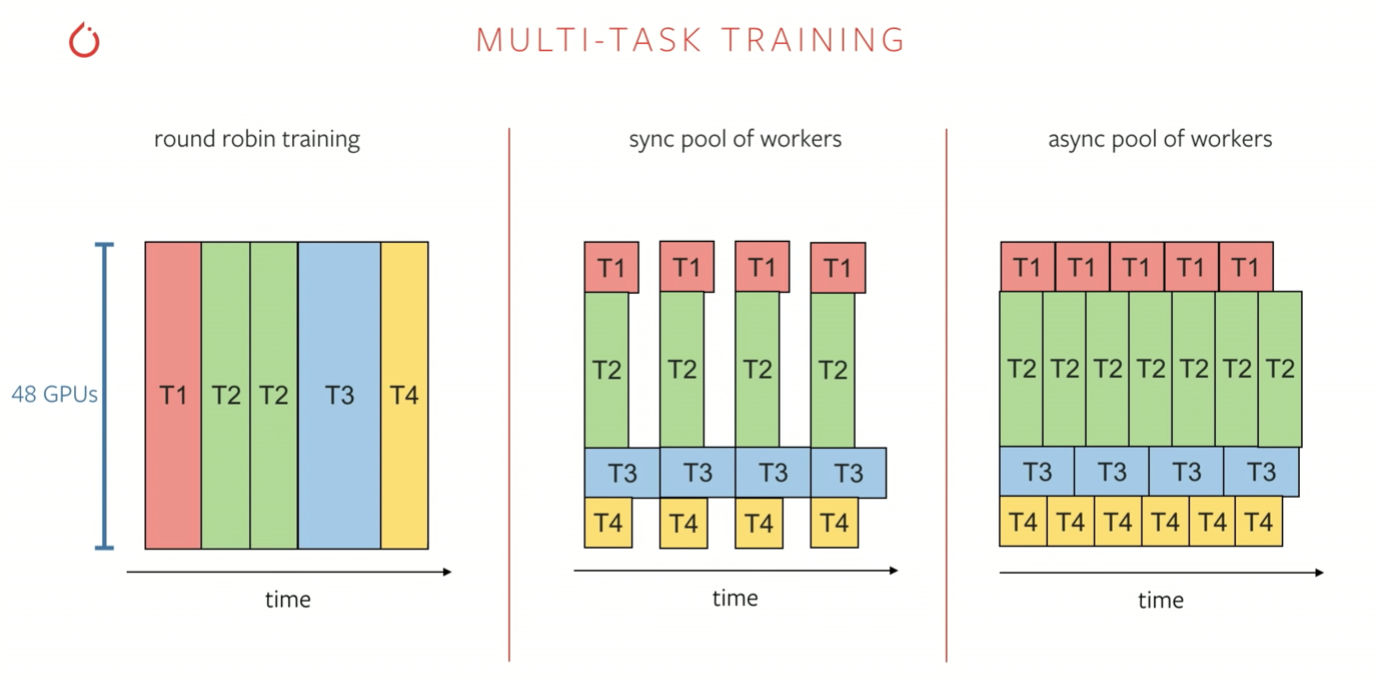
The training process for the recurrent tasks is quite compute-intensive. Data from 8 Cameras, unrolled over 16 time-steps, with a batch size of 32 leads to 4096 images for a single forward pass! This problem is solved by a set of data-parallel and model-parallel training pipelines. Rather than a simple round-robin training process, where each task is trained for sequentially, techniques like a task-specific pool of workers work better because the number of tasks is huge (~100).
What Tesla has done well, and many other efforts at autonomous driving failed to achieve is data generation. By giving more and more products in the hands of consumers, Tesla now has a large source of quality data. They are able to capture disagreements between the Human and the Autopilot by deploying models in live mode as well as shadow mode. In this way, they have been able to improve their models by inference capabilities on real-world data, capturing disagreements and mistakes made by both, the Human and the Autopilot. As long as they receive well-labeled data, their models keep on improving with minimal effort.
Medical Imaging
Medical Diagnosis has seen a watershed moment since the advent of Computer Vision. Deep Learning Vision Systems have already outperformed their Human counterparts on accurate medical diagnosis. The real power of these systems is in early diagnosis, at which stage even lethal diseases are curable. Medical Specialists like Radiologists, Cardiologists, and Neurologists are often in short supply and overworked, leading to bottlenecks like long wait times and errors in diagnosis. Medical Imaging Startups are providing Computer Vision-based solutions to these crucial, complicated, and largely domain-specific problems.

Arterys is one of such leading players, reducing subjectivity and variability in medical diagnosis. They have used Computer Vision to reduce the downtime to image blood flow in the heart, which took hours initially, to minutes. This allowed cardiologists to not only visualize, but also quantify blood flow in the heart and cardiovascular vessels, thus improving the medical assessment from an educated guess to directed treatment. It allowed cardiologists as well as AI to diagnose heart diseases and defects within minutes of MRI.
But why did it take hours for scans to generate flows in the first place? Let’s break this down.
- Multiple in vivo scans are done to capture 3D Volume cycles over various cardiac phases and breathing cycles.
- Iterative Reconstruction Methods on MRI data to evaluate flow increases reconstruction times automatically.
The solution to this problem was implemented as a Vision-based system that incorporates data correlation over a large number of subjects. This allows for fewer in vivo scans and using the model to predict 4D flow Volumes as well as to reconstruct blood flow over various cardiac phases and breathing cycles. In the training stage, the neural network learns abstract features from a set of scans. Training is done on a reconstruction loss which is taken as nRMSE (normalized RMSE). After training, newly acquired MRI data is reconstructed by inference with the learned weights. The computational overhead is very low and leads to a reduction in reconstruction times. Also, reconstruction is generally superior to traditional iterative reconstruction methods.
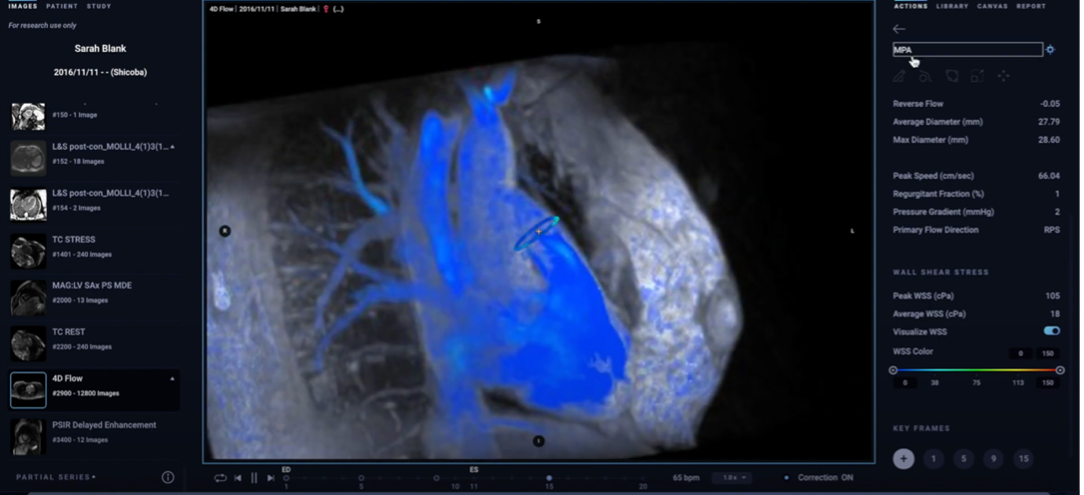
Along with 4D flow generation, object detection algorithms (Fast R-CNN(2015), R-FCN(2016)) in Arterys’ tech stack help to identify unidentifiable abnormalities and contours in the heart, lungs, brain, and chest scans. It automatically indexes and measures the size of the lesions in 2D and 3D space. Image Classification Networks help to identify pathologies like fracture, dislocation, and pulmonary opacity. Arterys trained its CardioAI network, which can process CT and MRI scans, on NVIDIA TITAN X GPUs running locally and on Tesla GPU accelerators running in Google Cloud Platform. Both were supported by the Keras and TensorFlow deep learning libraries. Inference occurs on Tesla GPUs running in the Amazon cloud.
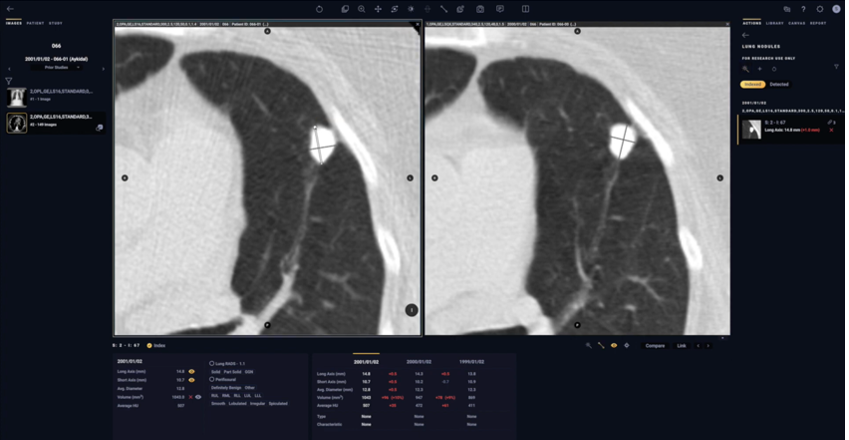
Though these insights are very important for the medical professional, their availability to the medical professional can cause bias in the medical professional’s assessment of the case. Arterys mitigates this problem by flagging certain cases for attention but not specifying the exact location of the abnormality in the scan. These can be accessed once the specialist has made an unbiased assessment of the case.
Cloud-based deployment of its stack has allowed Arterys to provide reconstructions as well as invaluable visual and quantifiable analysis to its customers on a zero-footprint web-based portal in real-time. Computer Vision’s biggest impact in the coming years will be its ability to augment and speed the workflow for the small number of radiologists compared to the quickly growing elder patient populations worldwide. The high-value applications are in rural and medically underdeveloped areas where physicians or specialists are hard to come by.
Visual Search
Visual Search is a search based on images rather than text. It heavily depends on computer vision algorithms to detect features that are difficult to put into words or need cumbersome filters. Many online marketplaces, as well as search tools, have been quick to adopt this technology and consumer feedback for the same has been strongly positive. Forbes has forecasted that early adopters of visual search are projected to increase their digital revenue by 30%. Let us talk about a few early adopters and even late adopters to the visual search technology and how they have gone about implementing it.
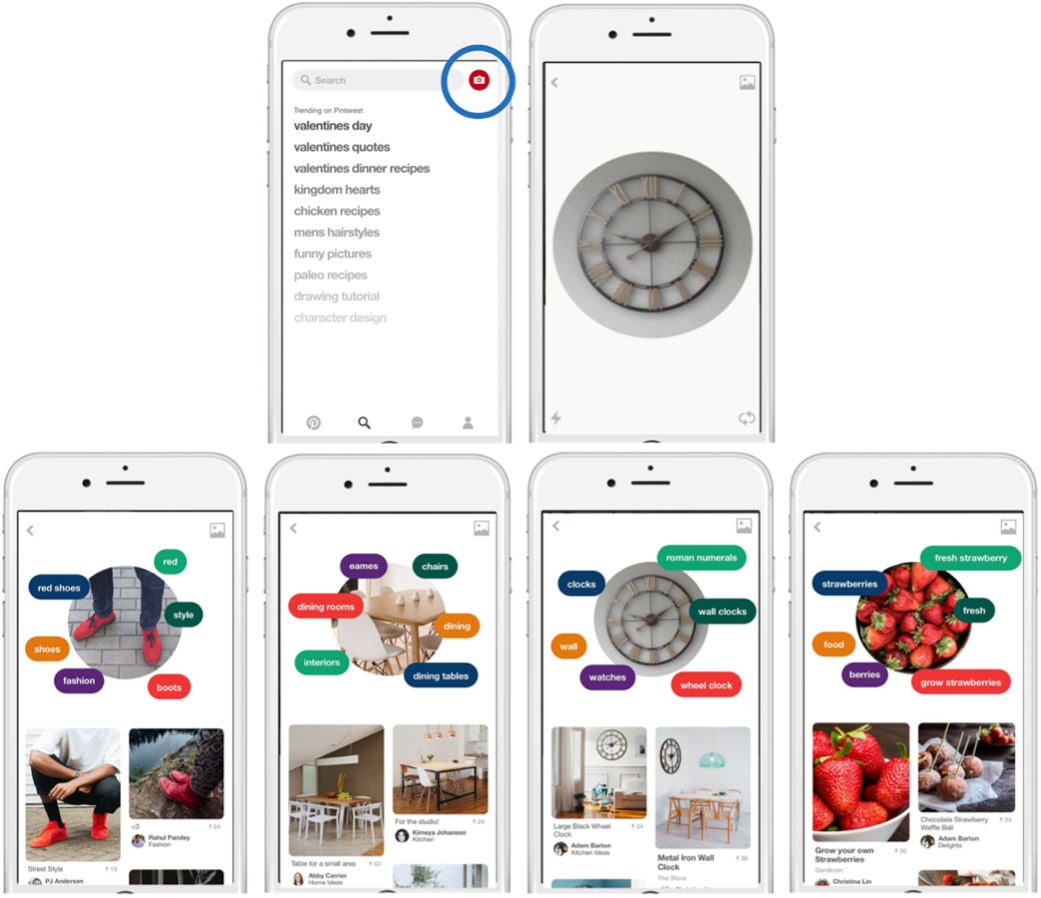
Pinterest’s Visual Lens added a unique value to their customers’ experience wherein they could search for something difficult to put in words. Essentially, Pinterest is a giant Bipartite Graph. On one side are objects, which are pinned by the users, and on the other side are boards, where mutually coherent objects are present. An edge represents pinning an object (with its link on the internet) on a board that contains similar objects. This structure is the basis of Pinterest’s data and this is how Lens can provide high-quality references of the object in similar as well as richly varied contexts. As an example, if Lens detects Apple as an object, it can recommend Apple Pie Recipe and Apple farming techniques to the user, which belong to very separate domains. To implement this functionality, Pinterest has separated Lens’ architecture into two separate components.
In the first component, a query understanding layer has been implemented. Here, certain visual features are generated like lighting conditions and image quality. Basic object detection and colour features are also implemented as a part of the query understanding layer. Image Classification algorithms are also used to generate annotations and categories for the queried images.
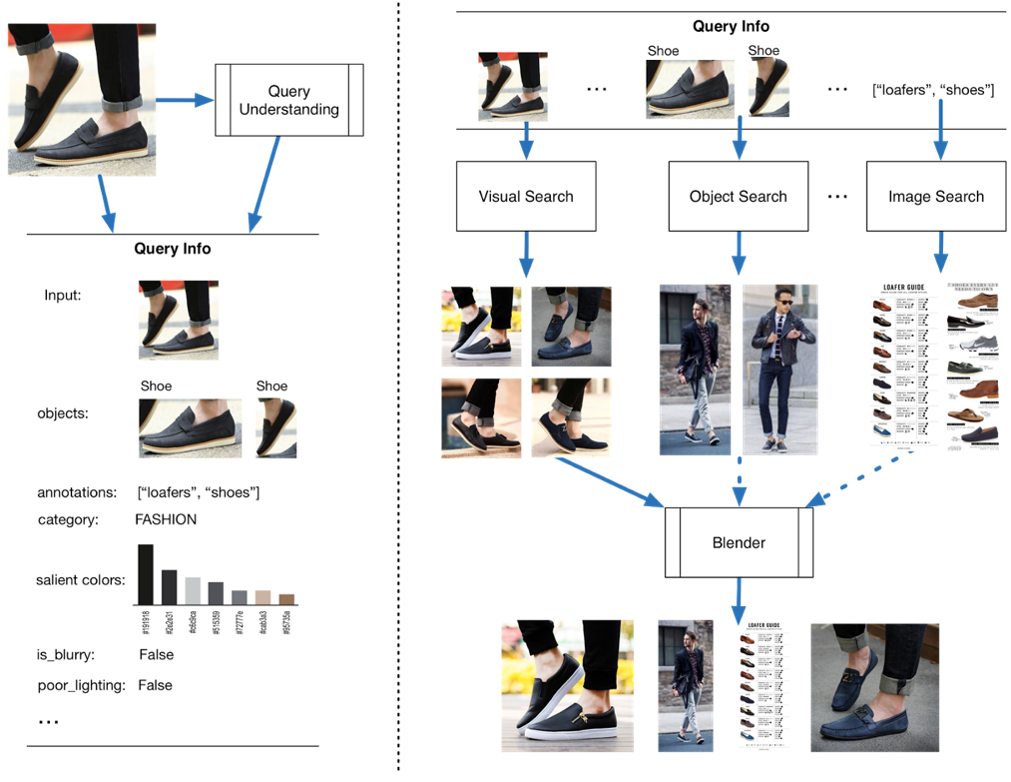
In the second component, results from many models are blended to generate a continuous feed of results relevant to the queried image. Visual search is one of these models which returns visually similar results where the object and its context are strongly maintained. Another one would be an object search model which gives results that have the given object in the results. The third model uses the generated categories and annotations from the query understanding layer to do a textual image search to get the results. The blender does a very good job of dynamically changing the blending ratios as the user scrolls through the search results. Confidence thresholds are also implemented such that low confidence results from the query understanding layer are skipped while generating the final search results. Evidently, the basic technology supporting Pinterest Lens is object detection. It supports Visual Search, Object Search, and Image Search. Let’s understand in detail how object detection is done at Pinterest.
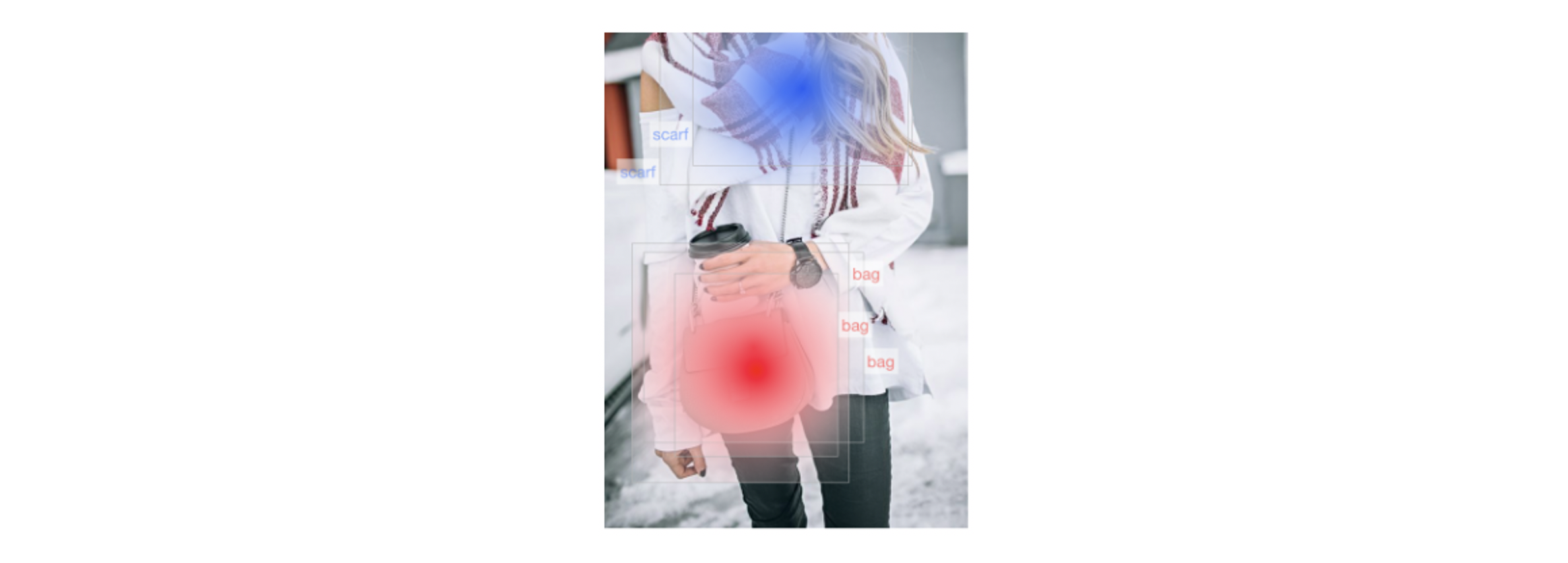
Initially, they faced the issue of getting high-quality labelled bounding boxes for object detection. Pinterest turned to their user base and they have processed over one billion cropped images since. For a given image, user crops are aggregated by creating heat maps to isolate actual objects. Weak labels are then assigned to isolate multiple objects in a given image. This exercise is used to generate the bounding box labels for different objects. Now, Lens needs to give real-time results from unseen data, mostly data generated mere milliseconds ago. For quick turnaround time, the algorithm uses many advanced object detection algorithms, one of which is Faster R-CNN(2015). The algorithm works in two steps.
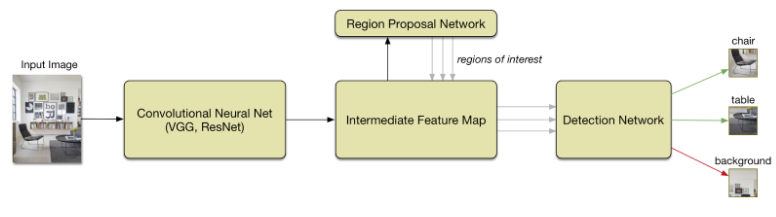
In step 1, the input image is fed into an already trained CNN, which identifies regions that might contain objects, and converts the image into a feature map. Once the feature map is generated, in step 2, A Region proposal network is used to extract sub-mappings of various sizes and aspect ratios from the original feature map. These sub-mappings are fed into a binary softmax classifier which predicts whether a given sub-region contains an object. If a promising object is found, it is indexed into a list of possible objects, along with the region bounded sub-mappings, which are then classified into object categories by an object detection network.

This is how Lens has been able to use Computer Vision and Pinterest’s bipartite graph structure to generate highly relevant and diverse results for visual search.
Gaming
Eye-tracking is a technology that makes it possible for a computer system to know where a person is looking. An eye-tracking system can detect and quantify the presence, attention, and focus of the user. Eye-tracking systems were primarily developed for gaming analysis to quantify the performance of top gamers; but since then, these systems have found utility in various devices like consumer and business computers.
Tobii is the world leader in eye-tracking tech and the applications they support have moved from gaming to gesture control and VR. Data acquisition by Tobii is done via a custom-designed sensor which is pre-set on the device where eye-tracking information is needed. The system consists of projectors and customised image sensors as well as custom pre-processing with embedded algorithms. Projectors are used to create an infrared light-map on the eyeballs. The camera takes high-resolution images of the eyeballs to capture the movement pattern. Computer Vision algorithms are then used to map the movement of eyeballs from the images onto a point on the screen, thus generating the final gaze point. The stream of temporal data thus obtained is used to determine the attention and focus of the subject.

This original application has now been improved upon by utilities like gesture control. It has applications in hands free interaction with smart devices and is especially helpful for physically challenged users who are unable to use normal input devices like fingers, mice, and keyboards. Another utility is in behaviour research where it is now easier to capture what actually catches human attention and how it leads to decision making and affects emotions and body vitals. Here, the data is captured using a wearable eye-tracker that looks like normal specs. Virtual and Augmented Reality also has wide-ranging applications of eye-tracking, adding another layer of input to immerse oneself into the experience and interact better with it.
Workplace Safety
The human and economic cost of workplace injuries around the world is a staggering $250 billion per year. With AI-enabled intelligent hazard detection systems, workplaces prone to a high level of onsite injuries are realizing the decrease in number as well as the severity of injuries. Imagine a resource that works 24/7 without fatigue and keeps a watchful eye on whether safety regulations are being followed in the workplace!
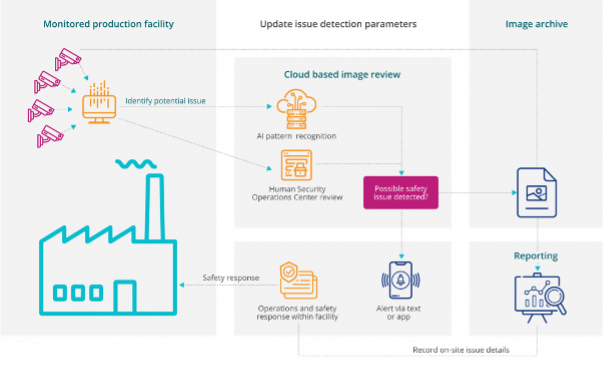
Intenseye is an AI-powered employee health and safety software platform that helps the world’s largest enterprises to scale employee health and safety across their facility footprints. With real-time 24/7 monitoring of safety procedures, they can detect unsafe practices in the workplace, flag them and generate employee level safety scores along with live safety-norm violation notifications. Assistance is also provided in operationalising the response procedures, thus helping the employer in being compliant with the safety norms. Along with normal compliance procedures, they have also developed Covid-19 compliance features which help in tracking whether covid appropriate norms like masking and social distancing are being followed in the workplace.
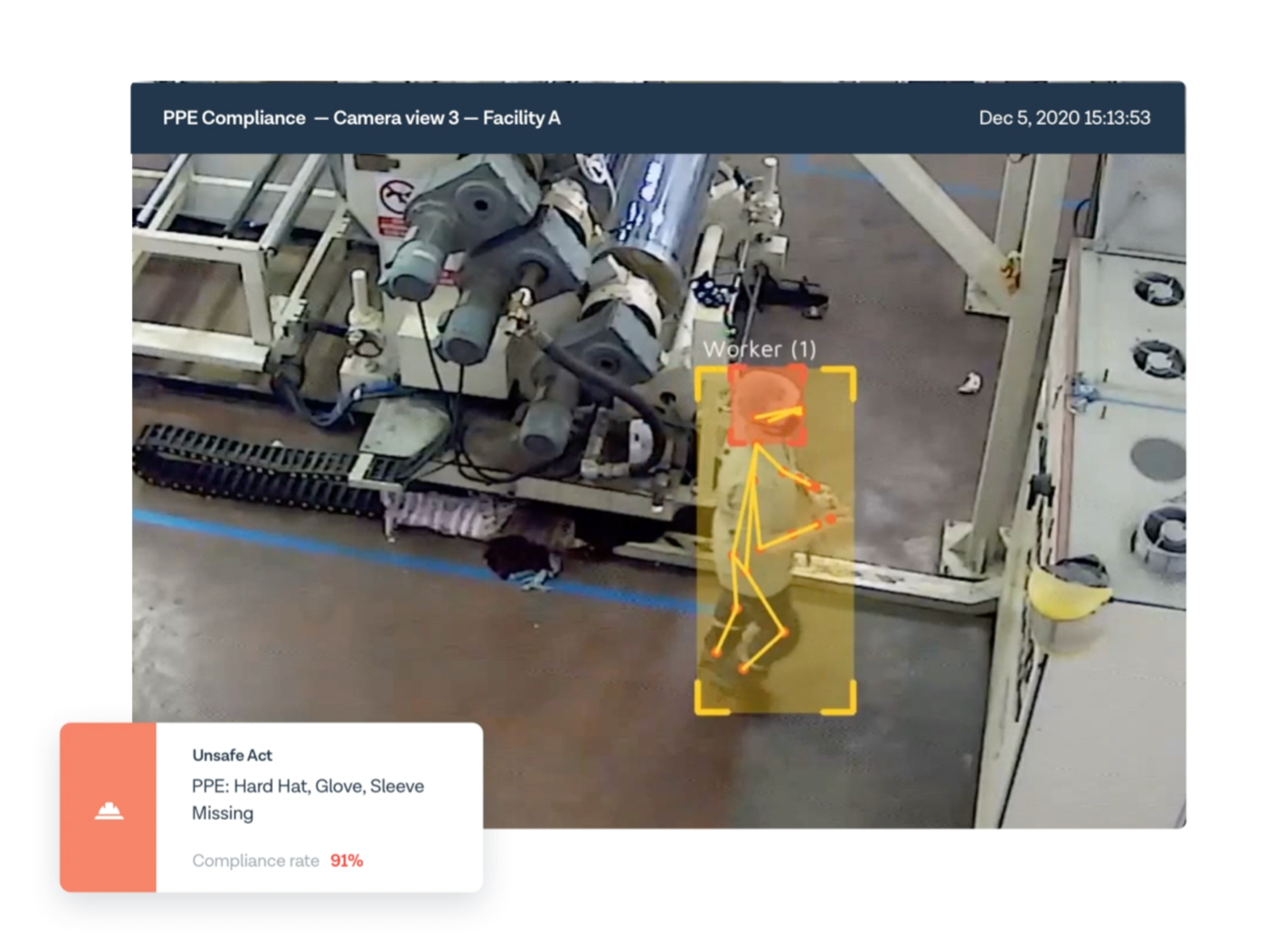
The product is implemented on two levels. The basic driver for the product is Computer Vision. A big challenge for the org was to implement real-time predictions from live video streams. This is inherently a slow process and requires parallelisation and GPU computation to achieve due to the nature of the data pipeline. The vision systems employed range from anomaly detection to object as well as activity detection. Finally, the predictions generated are aggregated to rapidly create analysis, scores, and alerts on the suite available with the EHS professionals in the workplace who can ensure compliance from the workers.
Intenseye has developed general-purpose suites for workplaces, like PPE Detection, Area Controls, Vehicle Controls, Housekeeping, Behavioural Safety, and Pandemic Control measures. With their AI-based inspection system, Intenseye has been able to add a lot of value to the businesses they support. Along with saved lives, there have been decreased costs in damages, a boost in productivity, improved morale, and gain in goodwill for their clients.
Retail Stores
In-aisle innovation is shifting how we perceive the future of retail, opening the possibilities of what can be done to shape customer experiences. Computer vision is posed to tackle many retail store pain points and can potentially transform both customer and employee experiences.
Amazon opened the doors on its first AmazonGo store in Seattle in January 2018 after a year of testing its Just Walk Out technology on its employees at its headquarters. This concept creates an active shopping session, links the shopping activity to the amazon app, and allows the customer to have a truly hassle-free experience. It eliminates the need to group with other buyers at checkout points to make the purchase, thus creating a unique value proposition in the current pandemic stricken world.

How does Amazon do it? The process which is primarily driven by Computer Vision can be divided into a few parts:

- Data Acquisition: Along with an array of application-specific sensors (pressure, weight, RFID), the majority of data is visual data extracted from several cameras. Visual data ranges from images to videos. Other data is also available to the algorithm, like amazon user history, customer metadata, etc.
- Data Processing: Computer Vision algorithms are used to perform a wide array of tasks that capture the customer’s activity and add events to the current shopping session in real-time. These tasks include activity detection (eg. article picked up by customer), object detection (number of articles present in cart), image classification (eg. customer has a given product in the cart). Along with tracking customer activity, visual data is used to assist the staff in other store-specific operations like inventory management (object detection), store layout optimisation(customer heat maps), etc.
- Charging the customer: As soon as the customer has made their purchase and moves to the store’s transition area, a virtual bill is generated on the items present in the virtual cart for the customer’s current shopping session. Once the system detects that the customer has left the store, their Amazon account is charged with that purchase.

AmazonGo is a truly revolutionary use of computer vision and AI. It solves a very inherent problem for the in-store retail customers, assisting staff, improving overall productivity, and generating useful insights from data in the process. Though, it still needs to make economic sense in the post-pandemic world. There are privacy concerns that also need to be addressed before this form of retail shopping is adopted by the larger world.
Industrial Quality Control
The ability of Computer Vision to distinguish between different characteristics of products makes it a useful tool for object classification and quality evaluation. Vision applications can sort and grade materials by different features, such as size, shape, colour, and texture so that the losses incurred during harvesting, production, and marketing can be minimized.
The involvement of humans introduces a lot of subjectivity, fatigue, delay, and irregularity in the quality control process for a modern-day manufacturing line/sorting line. Machines are able to sort unacceptable items better than humans 24/7 and with high consistency. The only requirement is a robust computer vision system. Vision systems are being implemented for the same on a large scale to push products in the refurbished market or improve on manufacturing shortcomings.

Let’s solve the problem of detecting cracks in smartphone displays. The system needs a few important things to function as intended.
- Data: Quality data is imperative for the success of any machine learning system. Here, we require a camera system that captures the screen at various angles in different lighting conditions.
- Labels: We might want to eliminate human shortcomings in the process, but quality labels generated by humans under normal working conditions are crucial for the success of a vision system. For a robust, large-scale process, it is best to employ multiple professional labellers and let them agree on different labelling results, thus eliminating subjectivity from the process.
- Modelling: Models must be designed and deployed keeping in mind the throughput required for a given sorting line. Simple classification/object detection models are enough for detecting cracks. The main focus should be on prediction time which will be different for different sorting lines.
- Inference and Monitoring: Models can be initially deployed in shadow mode where their performance is evaluated against human workers on live data. They can be deployed if the performance is acceptable, otherwise, another modelling iteration can be adopted. Data Drift must be monitored manually / automatically along with model performance when data drift is high. Retraining should be done when results are not acceptable.
Many manufacturing lines have implemented automated control systems for screen quality, be it televisions, phones, tablets, or other smart devices. Companies like Intel are also providing services to develop such systems which provide great value to many businesses.
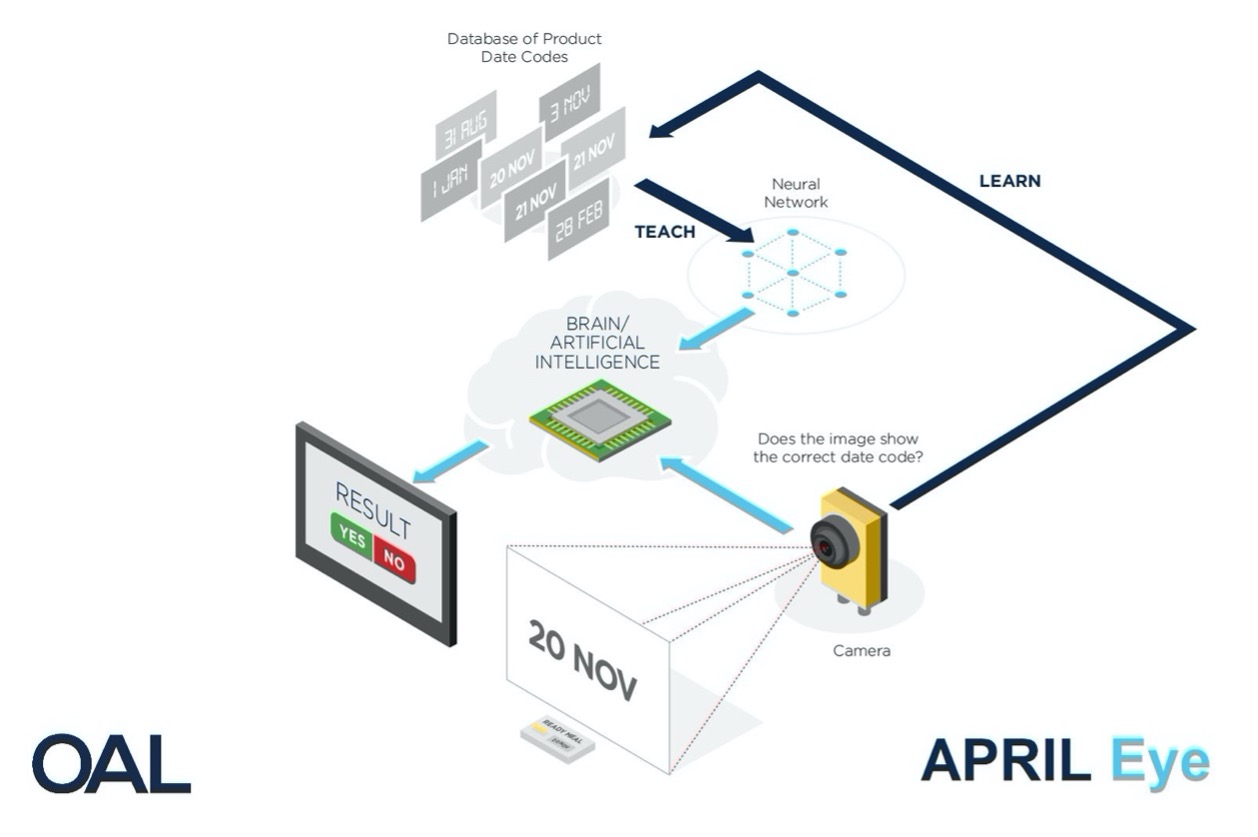
Another quality control application using vision systems has been launched by food technology specialist, OAL, who have developed a vision system, April Eye, for automatic date code verification. The CV-based system achieves full automation of the date-verification process, removing the need for a human operator. They have reduced the risk of product recalls and emergency product withdrawals (EPWs) which are majorly caused by human error on packaging lines. The product is aimed at solving mistakes that cost food manufacturers £60-80 million a year. The system has managed to increase throughput substantially to 300 correct packs a minute. The precision of the system is also highly acceptable. A neural network trained on acceptable and unacceptable product date codes is used to generate predictions on live date codes in real-time. The system ensures that no incorrect labels can be released into the supply chain, thus protecting consumers, margins, and brands.
Computer Vision adds value to quality control processes in a number of ways. It adds automation to the process, thus making it productive, efficient, precise, and cost-effective.
With a deeper understanding of how scalable vision-based systems are implemented at leading product-based organisations, you are now perfectly equipped to disrupt yet another industry using computer vision. May the accuracy be with you.
References
Pytorch at Tesla
Medical Imaging
Medical Imaging 2
Medical Imaging by Arterys
Visual Search
Visual Search at Pinterest
Visual Search at Pinterest 2
Eyetracking by Tobii
Eyetracking by Tobii 2
Workplace Safety by Intenseye
Computer Vision in Retail
AmazonGo
AmazonGo 2
Computer Vision for Quality Control
Detecting Cracked Screens
April Eye
About me
AI Engineer at Mastercard | Data Science, Python, C/C++ Dev | IIT (BHU) Varanasi, 2020 | Mathematics & Computing.
For immediate exchange of thoughts, please write to me at [email protected]






Nice article and well explain ed