This article was published as a part of the Data Science Blogathon
Introduction
Since the onset of life, human vision is essential, beautiful, and complex. Until a decade ago, machines were not able to comprehend the visual world, as efficiently as we did.
Computer vision is an interdisciplinary scientific field that deals with how computers can gain comprehend the visual world in the form of images and videos. From an engineering perspective, it seeks to replicate and automate tasks that the human visual system can do.
Computer vision uses Artificial Intelligence (AI) to train computers to interpret and understand the visual world. Using digital images from cameras and videos and deep learning models, machines can accurately identify and classify objects — and then react to what they “see”.
Computer scientists have been trying to give vision to computer vision for half a century, which led to the field of computer vision. The goal is to give computers the ability to extract a high-level understanding of the visual world from digital images and videos. If you’ve used a digital camera or smartphone, you know that computers are already good at capturing images and videos in incredible fidelity and detail, better than humans.
Today, a lot of things have changed for the good of computer vision:
1. Mobile tech with HD cameras has made quite a huge collection of images and videos available to the world.
2.Computing power has increased and has become easily accessible and more affordable.
3. Specific hardware and tools designed for computer vision are more widely available. We have discussed some tools later in this article.
These advancements have been beneficial for computer vision. Accuracy rates for object identification and classification have gone from 50% to 99% in a decade, resulting in today’s computers being more accurate and quick than humans at detecting visual inputs.
Where is Computer Vision used?
1. Healthcare
Computer vision is heavily used in healthcare. Medical diagnostics relies heavily on the study of images, scans, and photographs. The analysis of ultrasound images, MRI, and CT scans are part of the standard repertoire of modern medicine, and computer vision technologies promise not only to simplify this process but also to prevent false diagnoses and reduce treatment costs. Computer vision isn’t intended to replace medical professionals but to facilitate their work and support them in making decisions. Image segmentation helps in diagnostics by identifying relevant areas on 2D or 3D scans and colorizing them to facilitate the study of black and white images.
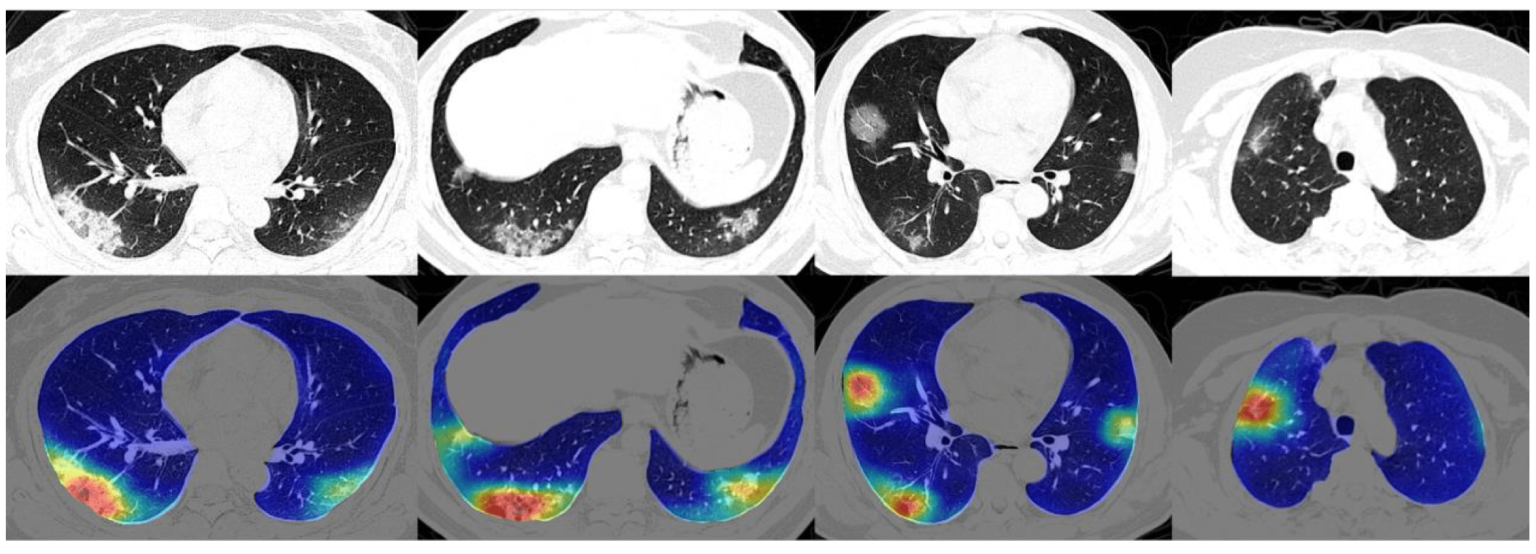
Image Segmentation of Lung CT-Scans
This technology is used in the COVID-19 pandemic. Image segmentation can help physicians and scientists identify COVID-19 and analyze and quantify the infection and course of the disease. The trained image recognition algorithm identifies suspicious areas on CT scans of the lungs. It determines their size and volume so that the disease of affected patients can be clearly tracked. In monitoring a new disease, computer vision not only makes it easier for physicians to diagnose the condition and monitor it during therapy, but the technology also generates valuable data for studying the disease and its course. Researchers also benefit from the collected data and the generated images, allowing more time to be spent on experiments and tests than data collection.
COVID-19 Tracking via CT-Scans
2. Automotive Industry
Self-driving cars belong to the use cases in artificial intelligence and have received the most media attention in recent years. This can probably be explained more by the idea of autonomous driving being more futuristic than by the actual consequences of the technology. Several machine learning problems are packed into it, but computer vision is an important core element in their solution. For example, the algorithm (the so-called “agent”) by which the car is controlled must be aware of the car’s environment at all times.
The agent needs to know how the road goes, where other vehicles are in the vicinity, the distance to potential obstacles and objects, and how fast these objects are moving on the road to adapt to the changing environment continually. For this purpose, autonomous vehicles are equipped with extensive cameras that film their surroundings over a wide area. The resulting footage is then monitored in real-time by an image recognition algorithm, which requires that the algorithm can search for and classify relevant objects not only in static images but in a constant flow of images.

Object recognition and classification in road traffic
This technology exists and is used industrially. The problem in road traffic stems from its complexity, volatility, and the difficulty of training an algorithm so that even possible failure of the agent in complex exceptional situations can be excluded. This exposes Computer vision’s Achilles’ heel: the need for large amounts of training data, the generation of which is associated with high costs in road traffic.
3. Retail: Customer Behavior tracking
Online stores like Amazon use their digital platform’s analysis capabilities to analyze customer behavior in detail and to optimize the user experience. The retail industry is also trying to optimize the experience of its customers and make it ideal. Until now, the tools to automatically capture the interaction of people with displayed items have been missing. Computer vision is now able to close this gap for the retail industry.
In combination with existing security cameras, algorithms can automatically evaluate video material and study customer behavior. For example, the current number of people in the store can be counted at any time, which is a useful application during the COVID-19 pandemic with its restrictions on the maximum number of visitors allowed in stores. The ability to track the attention that individual shelves and products receive from customers is revolutionary. Specialized algorithms can detect the direction of people’s gaze and thus measure how long any given object is viewed by passers-by.
With the help of this technology, retailers now have the opportunity to catch up with online trading and to evaluate customer behavior within their stores in detail. This increases sales minimize the time spent in the store and optimize the distribution of customers within the store.
4. Agriculture
Modern technologies enable farmers to cultivate ever-larger fields efficiently. This means that these areas must be checked for pests and plant diseases because if overlooked, plant diseases can lead to painful harvest losses and crop failures.
Machine learning is a savior because large amounts of data can be generated using drones, satellite images, and remote sensors. Modern technology facilitates the collection of various measured values, parameters, and statistics, which can be monitored automatically. Therefore, farmers have an around-the-clock overview of soil conditions, irrigation levels, plant health, and local temperatures, despite the extensive planting of larger fields. Machine learning algorithms evaluate this data so that the farmer can use this information to react to potential problem areas at an early stage and distribute available resources efficiently.
The analysis of image material allows plant diseases to be detected at an early stage. Just a few years ago, plant diseases were often only noticed when they were already able to spread. The extensive spread can now be detected and stopped at an early stage using early warning systems based on computer vision, which means that farms lose less crop and save on counter-measures such as pesticides since comparatively smaller areas need to be treated.

Example: Wheat rust detection with computer vision
How does Computer Vision work?
- Images on computers are often stored as big grids of pixels. Each pixel is defined as color, stored as a combination of 3 additive primary colors: RGB(Red Green Blue). These are combined in varying intensities to represent different colors. Colors are stored inside pixels.
- Let’s consider a simple algorithm to track a bright orange football on a football field. For that, we’ll take the RGB value of the centermost pixel. With that value saved, we can give a computer program an image, and ask it to find the pixel with the closest color match. The algorithm will check each pixel at a time, calculating the difference from the target color. Having looked at every pixel, the best match is likely a pixel from the orange ball. We can run this algorithm for every frame of the video and track the ball over time. But, if one of the teams is wearing an orange jersey, the algorithm might get confused. So, this approach doesn’t work for features larger than a single pixel, such as edges of objects, which are made up of many pixels.
- To identify these features in images, computer vision algorithms have to consider small regions of pixels, called patches. For example, an algorithm that finds vertical edges in a scene, to help a drone navigate safely through a field of obstacles. For this operation, a mathematical notation is used, which is called a kernel or filter. It contains the values for a pixel-wise multiplication, the sum of which is saved into the center pixel.
- Earlier, an algorithm called Viola-Jones Face Detection was used, which combined multiple kernels to detect features of the faces. Today, the newest and trending algorithms on the block are Convolutional Neural Networks (CNN).
Convolutional Neural Networks (CNNs)
- An artificial neuron is the building block of a neural network. It takes a series of inputs, and multiplies each by a specified weight, then sums those values altogether. The input weights are equivalent to kernel values, but unlike a predefined kernel, neural networks can learn their own useful kernels that are able to recognize interesting features in images.
- CNNs use banks of these neurons to process image data, each outputting a new image, essentially digested by different learned kernels. These outputs are then processed by subsequent layers of neurons, allowing for repeated convolutions.
- The first convolutional layer might find things like edges, the next layer might convolve on those edge features to recognize simple shapes, comprised of edges, like corners. The next layer might convolve on those corner features, and contain neurons that can recognize simple objects, like mouths and eyebrows. This keeps repeating, building up in complexity, until there’s a layer that does a convolution that recognizes all features: eyes, ears, mouths, nose, etc., and says “it’s a face”.
- Once we’ve isolated a face, we can apply more specialized computer vision algorithms to pinpoint facial landmarks, like the tip of the nose and the corners of the mouth. This can be used to determine if the eyes are open, the position of the eyebrows, which is easy once you have the landmarks. The relative distance between eyes and eyebrows can be compared to reveal surprise or delight.
- Similarly, all of this information can be interpreted by emotion recognition algorithms, giving computers the ability to infer basic ‘moods’. This can help computers become context-sensitive, i.e., aware of their surroundings.
CNNs aren’t required to be many layers deep, but they usually are, in order to recognize complex objects and scenes. This technique is considered deep learning.
Recent advancements have enabled computers to track and identify hand gestures as well. The exciting thing, however, is that scientists are just getting started, enabled by advancements in computing like superfast GPUs.
CNNs are applied to many image recognition tasks, beyond faces, like recognizing handwritten text, spotting tumors in CT scans, and monitoring traffic flow on roads.
Top Tools used for Computer Vision
Currently, there are various online tools that provide algorithms for Computer Vision and a platform to execute these algorithms or create new ones. These tools also provide an environment for connecting with various other software and technologies in conjugation with computer vision. So let’s check out some of the Computer Vision tools now!
1. OpenCV
OpenCV (Open Source Computer Vision Library) is an open-source computer vision library that contains many different functions for computer vision and machine learning.
Created by Intel and originally released in 2000, OpenCV has many different algorithms related to computer vision that can perform a variety of tasks including facial detection and recognition, object identification, monitoring moving objects, tracking camera movements, tracking eye movements, extracting 3D models of objects, creating an augmented reality overlay with a scenery, recognizing similar images in an image database, etc. OpenCV has interfaces for C++, Python, Java, MATLAB etc. and it supports various operating systems such as Windows, Android, Mac OS, Linux, etc.
2. TensorFlow
TensorFlow is a free open-source platform that has a wide variety of tools, libraries, and resources for Artificial Intelligence and Machine Learning which includes Computer Vision. It was created by the Google Brain team and initially released on November 9, 2015. TensorFlow can be used to build and train Machine Learning models related to computer vision that include facial recognition, object identification, etc. Google also released the Pixel Visual Core (PVC) in 2017 which is an image, vision, and Artificial Intelligence processor for mobile devices.
This Pixel Visual Core also supports TensorFlow for machine learning. TensorFlow supports languages such as Python, C, C++, Java, JavaScript, Go, Swift, etc. but without an API backward compatibility guarantee. There are also third-party packages for languages like MATLAB, C#, Julia, Scala, R, Rust, etc.
3. MATLAB
MATLAB is a numerical computing environment that was developed by MathWorks in 1984. It contains the Computer Vision Toolbox which provides various algorithms and functions for computer vision. These include object detection, object tracking, feature detection, feature matching, camera calibration in 3-D, 3D reconstruction, etc. You can also create and train custom object detectors in MATLAB using machine learning algorithms such as YOLO v2, ACF, Faster R-CNN, etc. These algorithms can also be run on multicore processors and GPUs to make them much faster. The MATLAB toolbox algorithms support code generation in C and C++.
4. CUDA
CUDA (Compute Unified Device Architecture)is a parallel computing platform that was created by Nvidia and released in 2007. It is used by software engineers for general purpose processing using the CUDA-enabled graphics processing unit or GPU. CUDA also has the Nvidia Performance Primitives library that contains various functions for image, signal, and video processing.
Some other libraries and collections include GPU4Vision, OpenVIDIA for popular computer vision algorithms on CUDA, MinGPU which is a minimum GPU library for Computer Vision, etc. Developers can program in various languages like C, C++, Fortran, MATLAB, Python, etc. while using CUDA.
5. SimpleCV
SimpleCV is an open-source computer vision framework that can be used for building various computer vision applications. SimpleCV is simple (as the name suggests!) and you can use various advanced computer vision libraries with it such as OpenCV without learning all the CV concepts in-depth such as file formats, buffer management, color spaces, eigenvalues, bit depths, matrix storage, bitmap storage, etc. SimpleCV allies you to experiment in computer vision using the images or video streams from webcams, FireWire, mobile phones, Kinects, etc.
It is the best framework if you need to perform some quick prototyping. You can use SimpleCV with Mac, Windows, and Ubuntu Linux operating systems.
6. GPUImage
GPUImage is a framework or rather, an iOS library that allows you to apply GPU-accelerated effects and filters to images, live motion video, and movies. It is built on OpenGL ES 2.0. Running custom filters on a GPU calls for a lot of code to set up and maintain. GPUImage cuts down on all of that boilerplate and gets the job done for you.
Computer Vision as a Service
1. Microsoft Azure
Microsoft API allows you to analyze images, read the text in them, and analyze video in near-real-time. You can also flag adult content, generate thumbnails of images and recognize handwriting.
2. Google Cloud and Mobile Vision APIs
Google Cloud Vision API enables developers to perform image processing by encapsulating powerful machine learning models in a simple REST API that can be called in an application. Also, its Optical Character Recognition (OCR) functionality enables you to detect text in your images.
The Mobile Vision API lets you detect objects in photos and video, using real-time on-device vision technology. It also lets you scan and recognize barcodes and text.
3. Amazon Rekognition
Amazon Rekognition is a deep learning-based image and video analysis service that makes adding an image and video analysis to your applications, a piece of cake. The service can identify objects, text, people, scenes, and activities, and it can also detect inappropriate content, apart from providing highly accurate facial analysis and facial recognition for sentiment analysis.
Author
Saurabh Mahajan, a tech enthusiast



{kind=link}
{kind=link}