
Image 1
What is data mining?
Data mining is the process of finding interesting patterns and knowledge from large amounts of data. Data sources include databases, data warehouses, web, and other information repositories or data that is flowed into the system dynamically. This analysis is carried out for the decision-making process.
Data mining is used to process data that initially has no meaning into information and then the information becomes knowledge. Data Mining, also known as Knowledge-Discovery-in-Databases.
Several methods or data mining tasks can be used to find, analyze, explore, and mine knowledge. There are 5 main tasks (Larose, 2005): Estimation, Forecasting, Classification, Clustering, and Association.
What are No-code development platforms?
Python and R are the most popular programming languages for data mining at the moment. But if you are short on time or not really familiar with Python, you can utilize the no-code development platforms.
A no-code development platform enables us to perform data mining tasks with drag-and-drop. It also enables us to develop data mining projects quickly without coding. Developers and non-developers can use these tools to practice rapid data mining development with customized workflows and functionality.
What is Rapidminer?
Rapidminer is a comprehensive data science platform with visual workflow design and full automation. It means that we don’t have to do the coding for data mining tasks. Rapidminer is one of the most popular data science tools.
This is the graphical user interface of the blank process in rapidminer. It has the repository that holds our dataset. We can import our own datasets. It also offers many public datasets that we can try. We can also work with a database connection.
Below the repository window, it has an operator. The operators include everything we need to build a data mining process, such as data access, data cleansing, modeling, validation, and scoring.
On the right is a parameters window. The parameters window is to adjust the operators.
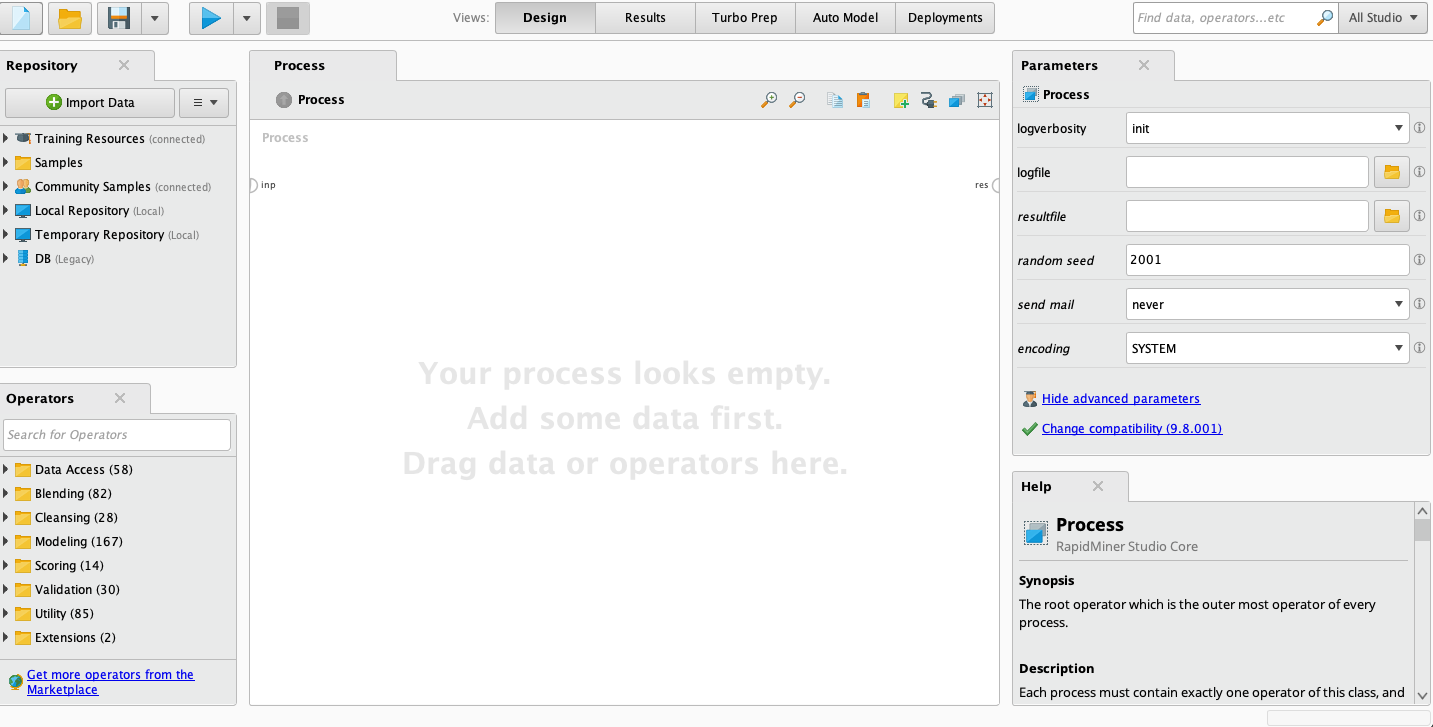
Rapidminer GUI
Rapidminer can be downloaded from their official website(https://rapidminer.com/). It has a free version with limited functionality. The free version includes 10,000 data rows and 1 Logical Processor.
They also offer an educational program. So that students, professors, instructors, and researchers can have a free educational license for free.
Case Study on Rapidminer
Let’s go to practice with Rapidminer. In this study case, we will perform a data mining process using the built-in dataset, using the classification method to compare accuracy from the various algorithms.
Activity Selection
This is the first interface that will pop up when we launch the rapidminer application. The blank process is to build from scratch. It works by dragging-and-dropping operators to the process field manually. This is the menu that you want to choose if you are at the intermediate level with this application.
Turbo Prep is for dataset preparation only. It includes transform, cleaning, and combines datasets. Auto Model will bring us the wizard to perform data mining tasks. Just like installing an application on Windows. Next-Next and Finish.
It also has a lot of templates for us to start with. We will choose the Auto Model for this study case.
Importing Dataset
Here we can choose the dataset that we will use. We can import our own dataset or select from the available dataset provided by rapidminer. Import-New-Data button below the select data list is to import our own dataset.
To use the available dataset from Rapidminer, click on the samples folder, then expand the data folder, and let’s choose the Titanic dataset for our study case and click the green Next button.
Notice in the progress bar there are only six easy steps to perform a data mining task with rapidminer.
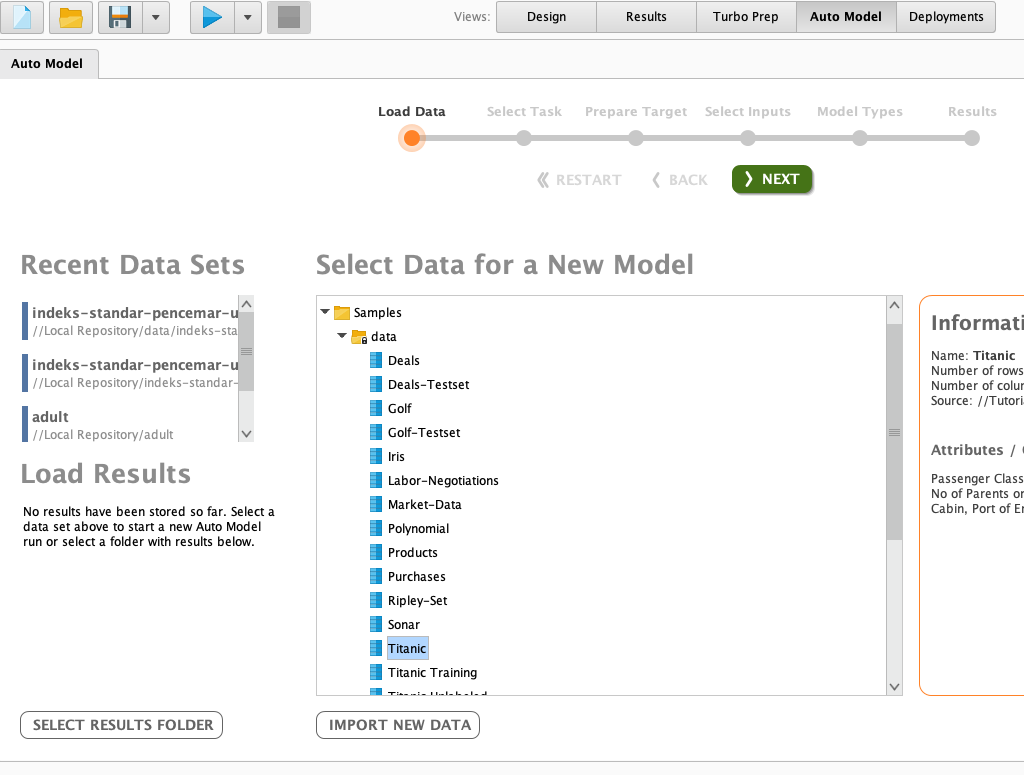
Datamining Method Selection
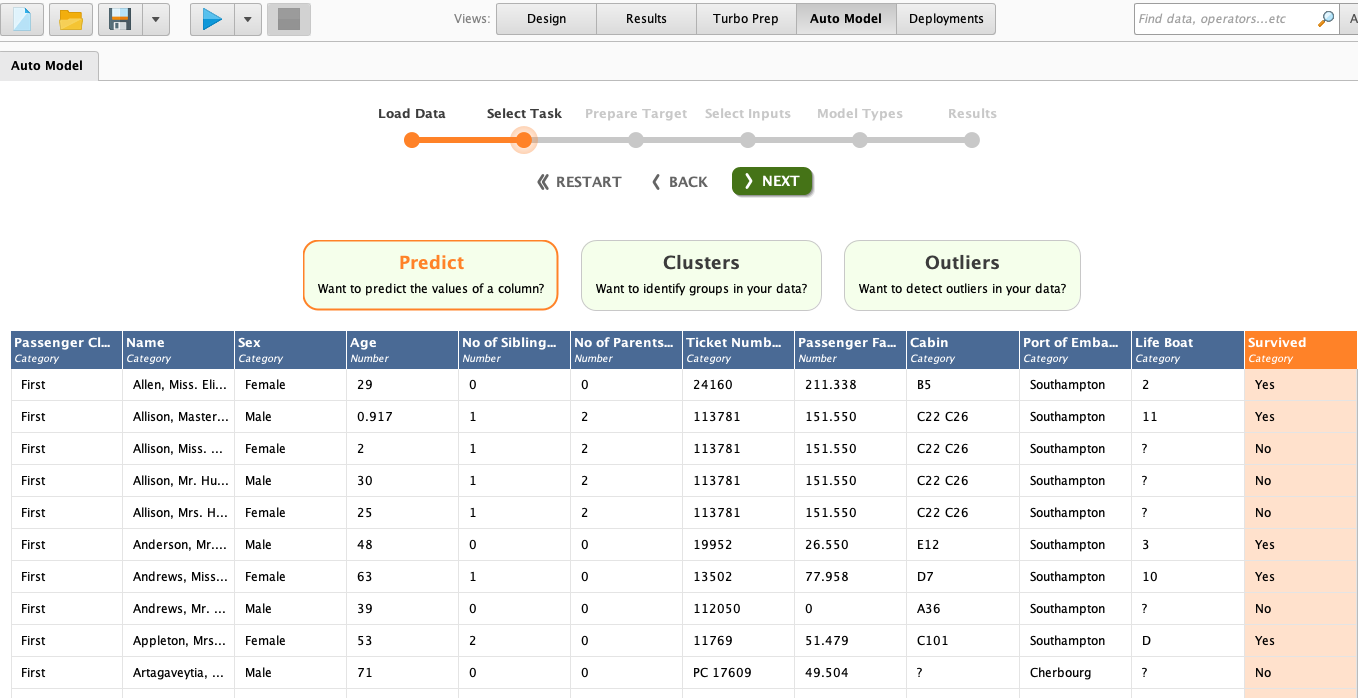
The details from a chosen dataset will be displayed. The titanic is a dataset to predict whether the passenger will survive on the titanic ship from the available input parameters. There are eleven input (x) parameters and one label (y) from this dataset.
There are three actions that we can choose for our dataset. Predict, clusters and outliers. The outliers button will help us detect outliers in our data. Clusters will help us detect common groups in our data. Predict will classify the data from the given input parameter.
Here we can observe our dataset’s input parameter. We can see that the Titanic dataset consists of both categorical and numerical data. The target label is in categorical, yes, or no format.
Select the predict button to do classification, select the Survived column as a label or classification target, and click on the Next button.
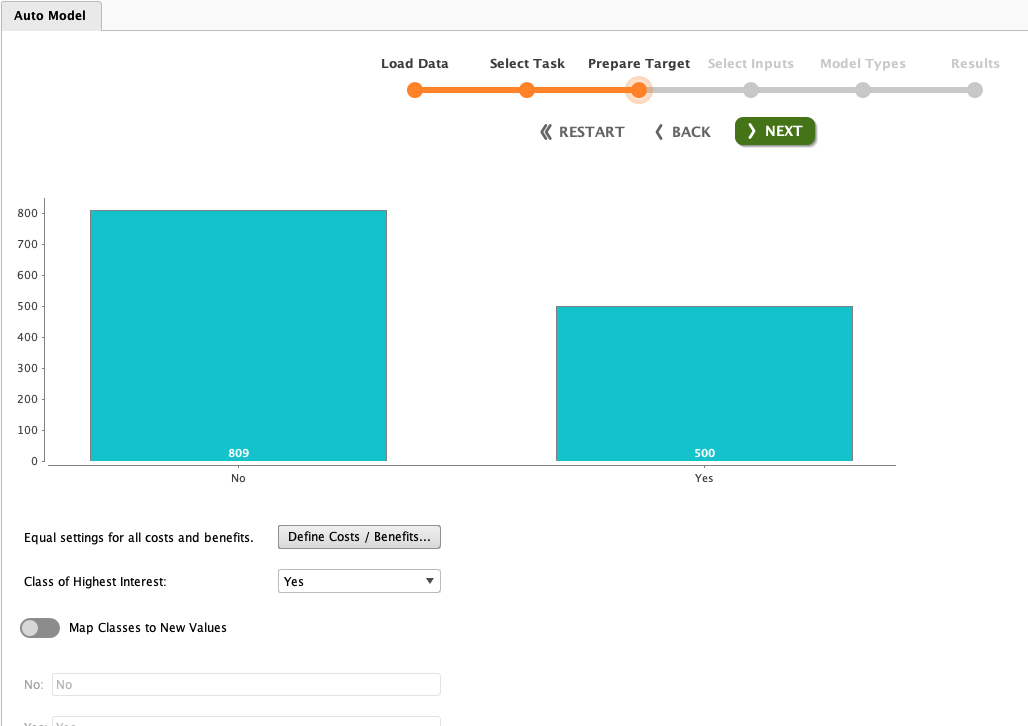
Data Balance
After selecting the data mining method and selecting the target column, we will be served with the data balance in a chart. See that the No data is more than the Yes data. This condition is quite common in reality. The ratio is around 60:40 which is still acceptable.
We need to start to worry when the ratio is higher than 70:30. A highly imbalanced class will lead to imbalanced prediction. The classification is usually tended predicted to the majority class.
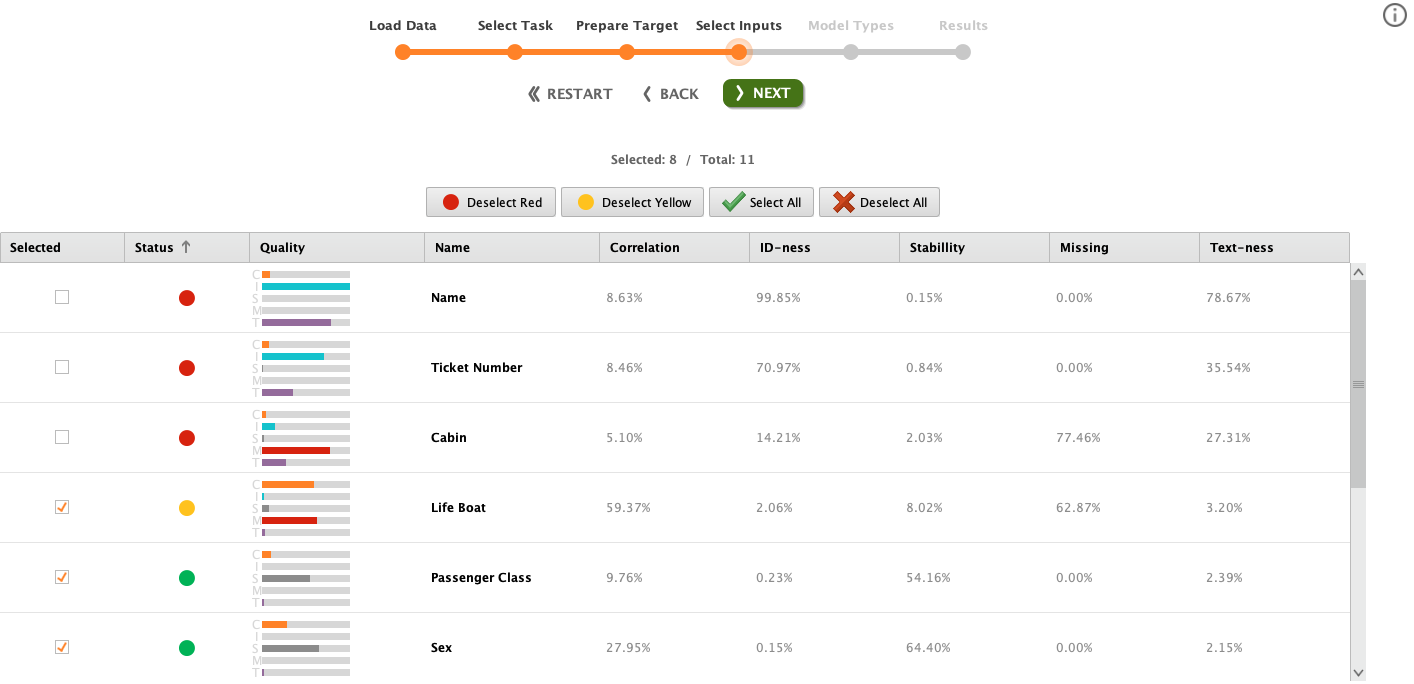
Input Selection
In this section, we can exclude the columns from the input parameters. The default is all column is included. Rapidminer will recommend which columns should be included or excluded.
Notice that the first three rows are excluded by default. This happens because the status is red. The red status will automatically be excluded by rapidminer though we still can include it. You can hover the red circle in the status column to see the details.
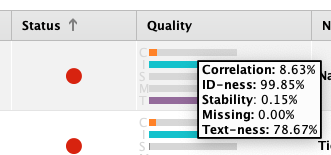
The Quality column will help us make a decision. It consists of five important parameters CISMT.
- Correlation (C) : measures the linear correlation between the data column and the target column.
- ID-ness (I) : measures the likelihood of the column resemble an ID.
- Stabilty (S) : Indicates that nearly all values are identical.
- Missing (M) : measures how much missing value is in the column.
- Text-ness (T) : measures the likelihood of the column resemble free text.
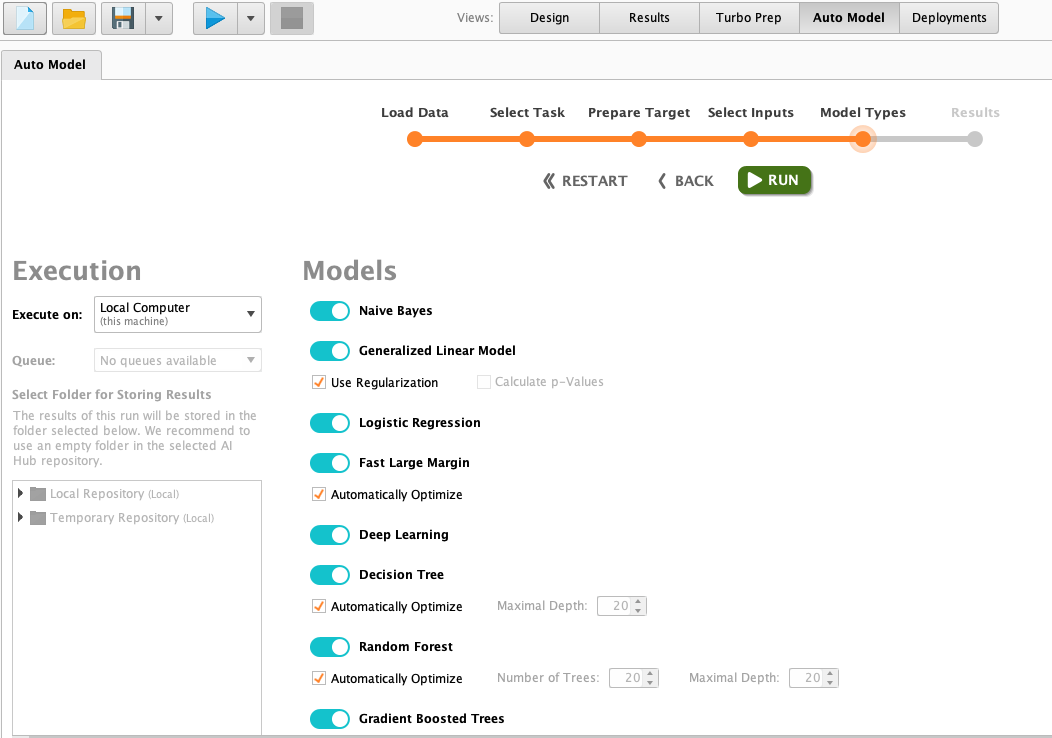
Algorithm Selection
Here’s the algorithm selection. Rapidminer will serve several popular classification algorithms for us to choose from.
This is the list of algorithms you can choose:
- Naive Bayes
- Generalized Linear Model
- Logistic Regression
- Fast Large Margin
- Deep Learning
- Decision Tree
- Random Forest
- Gradient Boosted Trees
- Support Vector Machine
We can choose all of them If the dataset being used is small. But we need to be wise when using a large dataset. Because the more algorithm being selected, the more time and hardware resources will be needed.
After choosing them, click on the run button.
Getting Insights from the Result
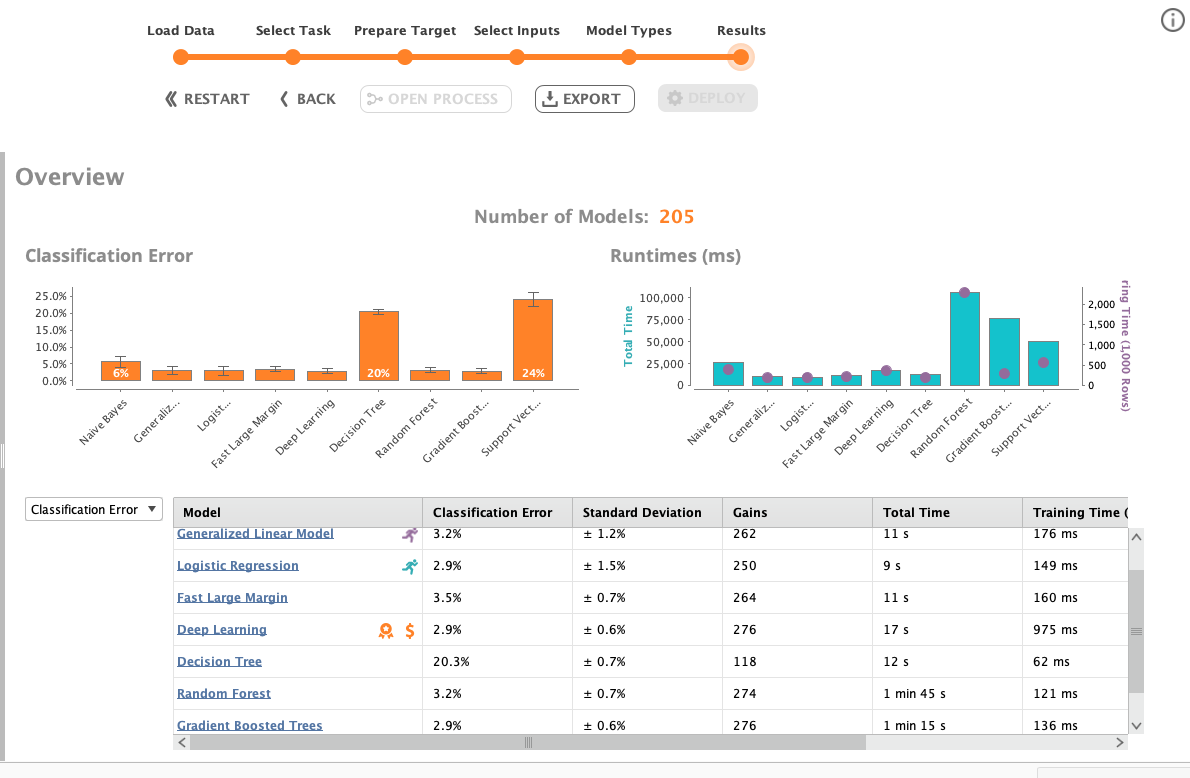
Depending on how many algorithms have been chosen, it will take longer to process. After we’re waiting for a while, the results will be served. The results will appear as a table and charts.
The first chart will show us the classification error comparison. Here we can see from our Titanic data, DT and SVM show the worst performance. The smaller the better for the charts. The second chart will shows us the runtimes comparison. The random forest algorithm takes the longest runtime.
While the charts give us a quick insight, the table will provide the details. The model name column also has badges. See the Deep learning, it has two badges. The badges show that deep learning gets the best overall performance and the best low-cost computation.
Exporting Result
Imagine if we have to prepare our data manually, and create the classification code with a deep learning algorithm. That one itself must be taken so many hours to code. It’s only one algorithm, how about coding all of them and create the visualizations.
In just ten minutes we have already finished our data mining process without the fuss to code them from the ground up. All we have to do is to click the Next button and finish.
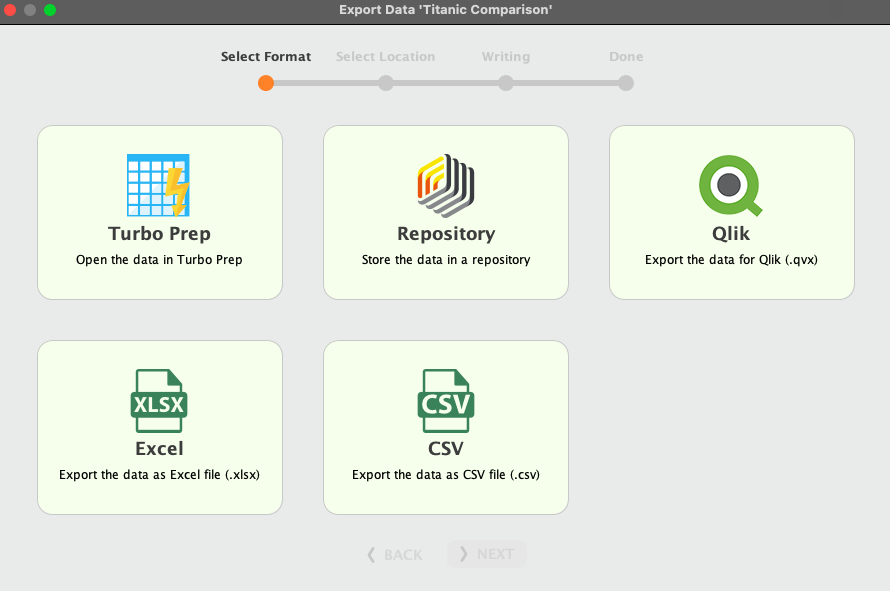
We also can save the result in various formats. Excel is one of them. Click the export button from the previous dialog and just click on the desired format and finished.
Conclusion
- No-code development platforms can greatly simplify data mining works
- Rapidminer is one of the tools that are effective for data mining tasks and safe a lot of times.
- Rapidminer also includes data pre-processing and algorithms selection
- At the end of the task, rapidminer will serve visualizations for us to get an insight.
- All the tasks done in rapidminer are so effortless compared to manual coding.
What’s next
- Build a data mining model with different datasets
- Build a data mining model with your own dataset
- Try to use another method, clustering
Short Author Bio
My name is Muhammad Arnaldo, a machine learning and data science enthusiast. Currently a master’s student of computer science in Indonesia.
Image Source:
- Image 1: https://www.pexels.com/photo/smiling-formal-male-with-laptop-chatting-via-phone-3760263/?utm_content=attributionCopyText&utm_medium=referral&utm_source=pexels






