Introduction
In the field of Machine Learning, owing to ‘No Free Lunch’ (NFL), there are numerous algorithms for problem-solving. However, time constraints often necessitate ready-made solutions. While working on an NLP project, I faced a similar challenge. Amidst a plethora of options, I discovered Rapid Automatic Keyword Extraction (RAKE), a valuable tool for text analysis, parsing, and text mining. Interested in NLP-based unsupervised learning, I found RAKE immensely useful. In this RAKE algorithm tutorial you will learn advanced uses for fine-tuning RAKE-based keyword extraction.
Learning Objectives
- Understand the principles behind the RAKE algorithm for keyword extraction.
- Learn how to preprocess text data for feature extraction using RAKE.
- Explore the concept of content words and their significance in keyphrase extraction.
- Gain insights into the scoring mechanism used by RAKE to prioritize candidate key phrases.
- Acquire practical knowledge of implementing RAKE in Python using the
rake-nltklibrary. - Discover advanced usage scenarios and customization options for fine-tuning RAKE-based keyword extraction.
This article was published as a part of the Data Science Blogathon!
Table of contents
Feature Extraction from Text
The provided content delves into the challenges related to analyzing unstructured text data, like social media posts and e-commerce feedback. It emphasizes the significance of efficient feature extraction methods in natural language processing (NLP).
Challenges of Unstructured Text Analysis
Unstructured text data, such as social media posts and customer feedback, often contains noise like spelling mistakes, mixed language use, and Unicode characters. While libraries like TextBlob in Python aid in data cleaning, extracting meaningful insights from such dataset remains challenging.
Need for Specific Feature Identification
In scenarios like analyzing feedback on a product, identifying specific features of interest, such as ‘Camera,’ ‘Screen,’ ‘Performance,’ and ‘Battery life,’ is crucial for businesses. However, relying solely on traditional approaches or predefined feature lists may not yield accurate or comprehensive results.
Variety of Feature Extraction Techniques
Various unsupervised feature extraction techniques exist to address this challenge. These techniques include Word Frequency analysis, which counts the occurrence of each word; Word Collocations, which identify words frequently occurring together; Co-occurrences analysis, which examines the simultaneous occurrence of words; TF-IDF, which measures the importance of a word in a document relative to a collection of documents; and Graph-based Approaches, which model relationships between words using graph structures.
Role of Automated Extractors
Among these techniques, Rapid Automatic Keyword Extraction (RAKE) stands out as an automated extractor that efficiently identifies keywords or key phrases in text. RAKE operates by analyzing word frequency and co-occurrence patterns, prioritizing content words over stop words and delimiters. It simplifies the process of extracting meaningful insights from unstructured text data, making it a valuable tool for text analysis tasks in NLP.
Also Read: Automate Everything With Python: A Comprehensive Guide to Python Automation
RAKE Algorithm Tutorial
Let’s delve into Rapid Automatic Keyword Extraction (RAKE) algorithm. First, I’ll provide an overview of the algorithm’s intuition, followed by a perspective from Python code.
One of RAKE’s key principles is that keywords often comprise multiple words but rarely include punctuation, stop words, or other terms with minimal lexical meaning. The algorithm emphasizes word collocation and co-occurrence, evident when analyzing feedback data from sources like e-commerce websites, where phrases like ‘Good Camera’ or ‘Customer Service’ frequently occur together, demonstrating semantic proximity. Conversely, terms like ‘Bad’ and ‘Worst’ in phrases like ‘Bad Camera’ or ‘Worst Camera’ share similar meanings, further highlighting their likelihood of co-occurring, especially in specific contexts such as mobile phones or DSLR cameras.
After obtaining the text corpus, RAKE proceeds by segmenting the text into a word list, filtering out stop words to derive what is known as the Content Words list. Natural language processing practitioners understand stop words to be terms like ‘are’, ‘not’, ‘there’, or ‘is’, which contribute minimal meaning to a sentence and can be safely disregarded. Removing these stop words streamlines the main corpus, making it more concise and relevant.
Consider the example sentence: “Feature extraction is not that complex. There are many algorithms available that can help you with feature extraction. Rapid Automatic Key Word Extraction is one of those.”
The initial word list would be: [feature, extraction, is, not, that, complex, there, are, many, algorithms, available, that, can, help, you, with, feature, extraction, rapid, automatic, keyword, extraction, is, one, of, those]
Highlighted stop words: [is, not, that, there, are, many, that, can, you, with, is, one, of, those]
Upon processing, the algorithm filters out stop words and delimiters, resulting in the Content Words list.
Also Read: Keyword Extraction Methods from Documents in NLP
Content_Word= Corpus – Stopwords – Delimiter
· Content_Word=[ feature, extraction, complex, algorithms, available, help, feature, extraction, rapid, automatic, keyword, extraction]
Now, when we have the content word, this list also considers the text as candidate key phrases. Below is an example of the same where candidate phrases are being highlighted in bold.
“feature extraction is not that complex. There are many algorithms available that can help you with feature extraction. rapid automatic keyword extraction is one of those”.
Let’s create a Word degree matrix like below, where each row will display the number of times a given content word co-occurs with another content word in candidate key phrases.
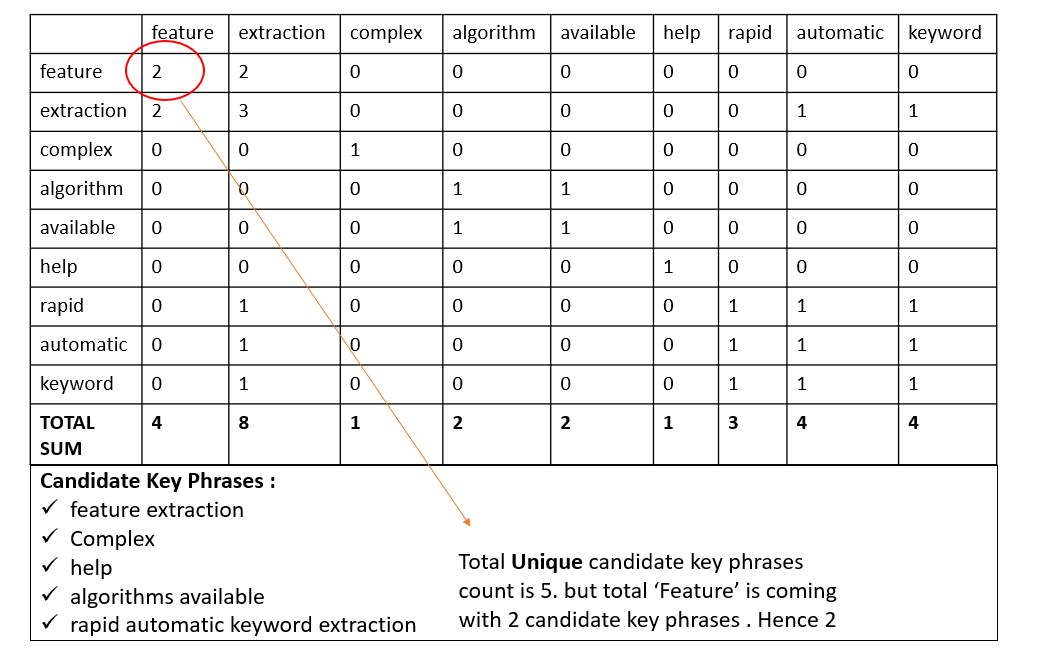
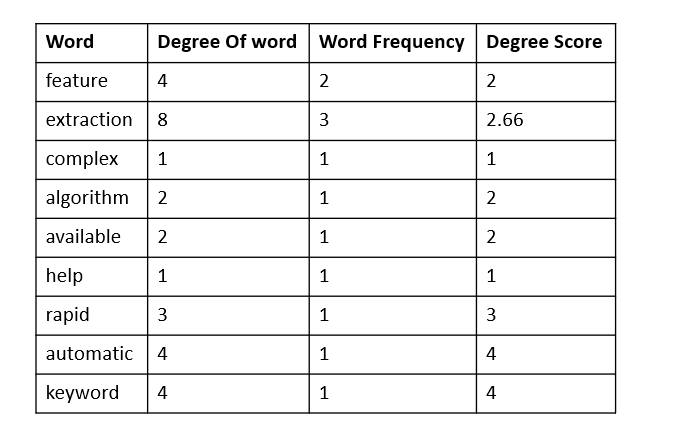
We have to give a score to each word. Calculate the ‘degree of a word’ in the matrix, the sum of the number of co-occurrences, then divide them by their occurrence frequency. Occurrence frequency means how many times the word occurs in the primary corpus. Check below.
Now consider the candidate key phrases and consider a combined(sum) score of each word for each candidate key phrases. It will look like below.
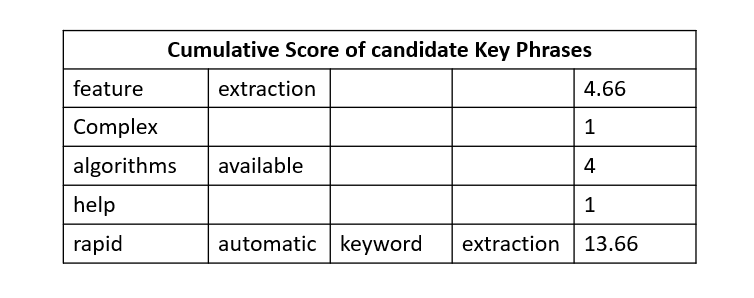
Suppose two keywords or key phrases appear together in the same order more than twice. A new key phrase is created regardless of how many stop words the key phrases contained in the original text. The score of the key phrases is computed just like the one for a single key phrase.
Also Read: Understanding of Word Embeddings: From Count Vectors to Word2Vec
Python Tutorial for RAKE and TextRank Algorithms
To leverage both RAKE and TextRank algorithms for keyword extraction in Python, follow these steps:
Install Libraries
First, ensure you have the necessary libraries installed. You can install rake-nltk and gensim using pip:
pip install rake-nltk gensimRAKE Implementation
Here’s how to use RAKE for keyword extraction:
from rake_nltk import Rake
# Initialize RAKE
r = Rake()
# Define the text
text = "Feature extraction is not that complex. There are many algorithms available that can help you with feature extraction. Rapid Automatic Key Word Extraction is one of those"
# Extract keywords from the text
r.extract_keywords_from_text(text)
# Get the ranked phrases
keywords_rake = r.get_ranked_phrases()- Import the
Rakeclass from therake_nltkmodule. - Create an instance of the
Rakeclass. - Provide a sample text.
- Use the
extract_keywords_from_text()method to tokenize the text and extract keywords. - Use the
get_ranked_phrases()method to get ranked phrases based on their significance in the text.
Output:
phrases = [
'rapid automatic key word extraction',
'many algorithms available',
'feature extraction',
'one',
'help',
'complex'
]Special Case
Use the get_ranked_phrases_with_scores() method to get ranked phrases along with their significance scores.
r.get_ranked_phrases_with_scores()Output:
[
(23.5, 'rapid automatic key word extraction'),
(9.0, 'many algorithms available'),
(5.5, 'feature extraction'),
(1.0, 'one'),
(1.0, 'help'),
(1.0, 'complex')
]Control Parameters
This line creates a new instance of the Rake class with parameters to control the minimum and maximum length of the phrases.
r = Rake(min_length=2, max_length=4)Including Repeated Phrases
This line creates a new instance of the Rake class with the option to include or exclude repeated phrases from the output.
r = Rake(include_repeated_phrases=False)Explanation:
RAKE and TextRank are two popular algorithms for keyword extraction. RAKE identifies keywords based on word frequency and co-occurrence patterns, while TextRank ranks words based on their importance in the text graph. By combining both algorithms, you can leverage their strengths to extract comprehensive keyword sets from text data.
Also Read: How To Remove the list of Stop words In Python?
Conclusion
RAKE (Rapid Automatic Keyword Extraction) presents a valuable solution for automated keyword extraction in NLP tasks. Its simplicity belies its effectiveness, making it a preferred choice for text analysis and feature extraction. The algorithm’s intuitive approach, coupled with practical implementation in Python, offers a robust tool for handling unstructured text data.
Key Takeaways
- RAKE facilitates keyword extraction by analyzing word frequency and co-occurrence patterns, prioritizing content words over stop words and delimiters.
- Understanding the principles behind RAKE helps in preprocessing text data and extracting meaningful insights, particularly in NLP tasks.
- RAKE identifies significant keywords by focusing on content words, disregarding stop words, and delimiters, ensuring relevance in keyword identification.
- RAKE utilizes a scoring mechanism to evaluate the significance of extracted keywords or phrases, considering factors like word frequency and co-occurrence patterns.
- Practical knowledge of implementing RAKE in Python using libraries like rake-nltk empowers data scientists to automate text analysis tasks efficiently.
- Exploring advanced usage scenarios and customization options further enhances the flexibility and applicability of RAKE-based keyword extraction techniques in various NLP applications.
Also Read: Evaluation Metrics For Classification Model
Frequently Asked Questions
Q1. What is the RAKE algorithm?
A. The RAKE algorithm, or Rapid Automatic Keyword Extraction, is a domain-independent algorithm used for keyword extraction in natural language processing (NLP). It identifies keywords or key phrases from text documents based on word co-occurrence patterns.
Q2. What is the RAKE algorithm in R?
A. In R, the RAKE algorithm is a text mining technique used for automated keyword extraction. It operates by analyzing word frequencies and co-occurrence patterns in text data to identify significant keywords or phrases.
Q3. How does RAKE Python work?
A. RAKE Python is a Python implementation of the RAKE algorithm for keyword extraction. It processes text data by analyzing word frequencies, removing stop words, and identifying significant keywords based on word co-occurrence patterns.
Q4. What is a RAKE score?
A. The RAKE score is a measure used in the RAKE algorithm to evaluate the significance of keywords or key phrases extracted from text data. It is calculated based on factors such as word frequency and co-occurrence patterns within the text.
Q5. What is rake algorithm in artificial intelligence?
A. The RAKE algorithm in artificial intelligence is a domain-independent method used for rapid keyword extraction from text data based on word co-occurrence patterns.
Q6. What role does IDF play in the RAKE algorithm for keyword extraction in natural language processing?
A. In the context of the RAKE algorithm, inverse document frequency (IDF) is a measure used to weigh the importance of a term in a document corpus, helping to identify significant keywords.
Q7. What is candidate keywords is RAKE algorithms?
A. Candidate keywords in RAKE algorithms refer to the potential keywords or key phrases extracted from text data before final scoring. These are typically content words identified after removing stop words and delimiters from the text corpus.
References
- https://csurfer.github.io/rake-nltk/_build/html/advanced.html
- https://github.com/csurfer/rake-nltk
- https://www.researchgate.net/publication/227988510_Automatic_Keyword_Extraction_from_Individual_Documents
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.
Subhasis Sanyal
20 Feb, 2024








That is vey helpful , thanks