This article was published as a part of the Data Science Blogathon
Table of Contents
- Introduction
- About the Dataset
- Let’s Go
- 2D Scatter Plot
- 3D Scatter Plot
- Pair Plot
- Histogram
- Univariate Analysis using PDF
- CDF
- Mean, Variance, and Standard Deviation
- Median, Percentile, Quantile, IQR, MAD
- Box Plot
- Violin Plot
- Multivariate Probability Density Contour Plot
- Final Note
Introduction to Exploratory Data Analysis
Exploratory Data Analysis (EDA) is a critical step in machine learning before developing any model because the original dataset may contain information that is redundant or worthless for training our model, lowering the performance of our model. If you work as a data scientist or a machine learning engineer, you should be able to deliver some useful insights from the data to the company/client given a dataset. Because their business choice is based on your results, there is no room for error in your research. As a result, you’ll need to know what EDA is and how to execute it correctly. Simply apply the EDA techniques that we’ll explore in this blog to ask questions and retrieve responses from the dataset.
We’ll go over several Exploratory Data Analysis (EDA) plotting tools. Now you might be wondering what EDA is and why it is essential, so let me explain. In Data Science or any machine learning task, you must first analyze the data using statistics and linear algebra in order to gain some insightful information or to discover some patterns and anomalies in the data that could impair your model’s performance, and I am sure no one enjoys seeing their model perform poorly.

Photo by Volodymyr Hryshchenko on Unsplash
About the Dataset for Exploratory Data Analysis
Using a sample dataset of Iris Flower available at the UCI Machine Learning Repository, we’ll try to grasp some of the most effective methods for exploring the dataset in this post. The data for this dataset was gathered in 1936 from three different varieties of iris blossoms. The following are the three types:
a) Iris Setosa
b) Iris Versicolor
c) Iris Virginica
We must always remember what our object/task is when performing analytics on the dataset. Given a photograph of a flower from the Iris family, we must determine whether the flower is Setosa, Versicolor, or Virginica, which is essentially a classification task. If we were to look at these flowers for the first time without any domain expertise, we would be unable to tell which class each flower belongs to, yet a botanist could readily classify them using his domain knowledge.
Let’s Go
We’ll start with the most fundamental data exploration by counting the number of data points and features in the dataset. The pandas shape method can help with this.
What are the columns in our dataset?
import pandas as pd
iris=pd.read_csv('Iris.csv')
print(iris.shape)
print(iris.columns)How many data points for each class are present? (or) How many flowers for each species are present?
iris["species"].value_counts()
setosa 50 virginica 50 versicolor 50 Name: species, dtype: int64
We can readily determine that the dataset is balanced because all three species have 50 entries.
Let’s have a look at some plots now.
2-D scatter plot
iris.plot(kind='scatter', x='sepal_length', y='sepal_width') ; plt.show()
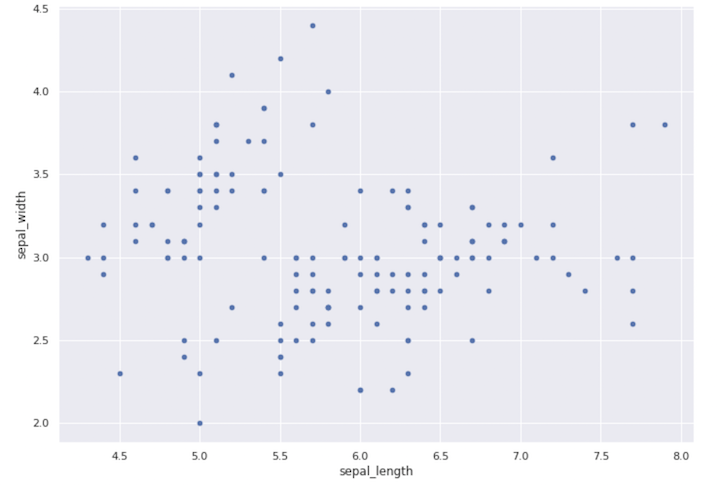
Scatter Plot
Always inspect what the x-axis, y-axis, and scale of these axes are when making a plot. One thing to keep in mind is that the plot’s origin is not (0,0). This graph doesn’t tell us much; it merely shows us the sepal length and width range.
Let’s make this storyline a little more fascinating and educational, shall we?
We may set the ‘hue’ option as the species column from the dataset using the seaborn library, and it will try to color the points based on the distinct values in the column. We’ll receive e different colored spots on the plot because we have three distinct values in the Species column: Setosa, Versicolor, and Verginica.
sns.set_style("whitegrid");
sns.FacetGrid(iris, hue="species", size=4)
.map(plt.scatter, "sepal_length", "sepal_width")
.add_legend();
plt.show();
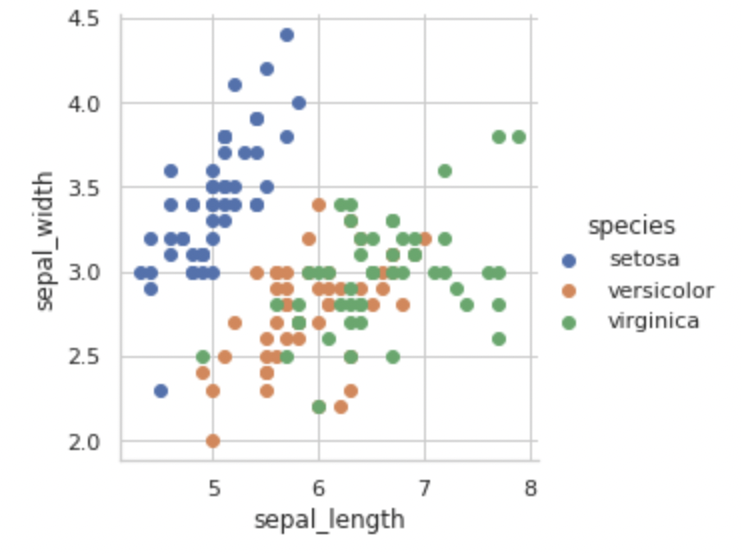
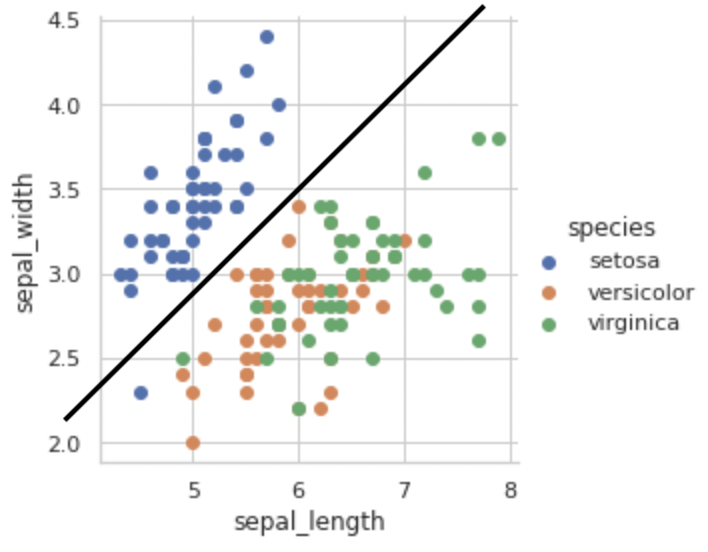
Setosa class can be easily distinguished from the other two classes based on sepal length and sepal width alone by just drawing a line ‘y = mx + c’ as shown below.
3D Scatter Plot
Let’s try to construct a 3D scatter plot now that we’ve seen a 2D scatter plot. We’ll use the plotly library for this because it allows us to interact with the plot in some way.
import plotly.express as px
df = px.data.iris()
fig = px.scatter_3d(df, x='sepal_length',
y='sepal_width',
z='petal_width',
color='species')
fig.show()
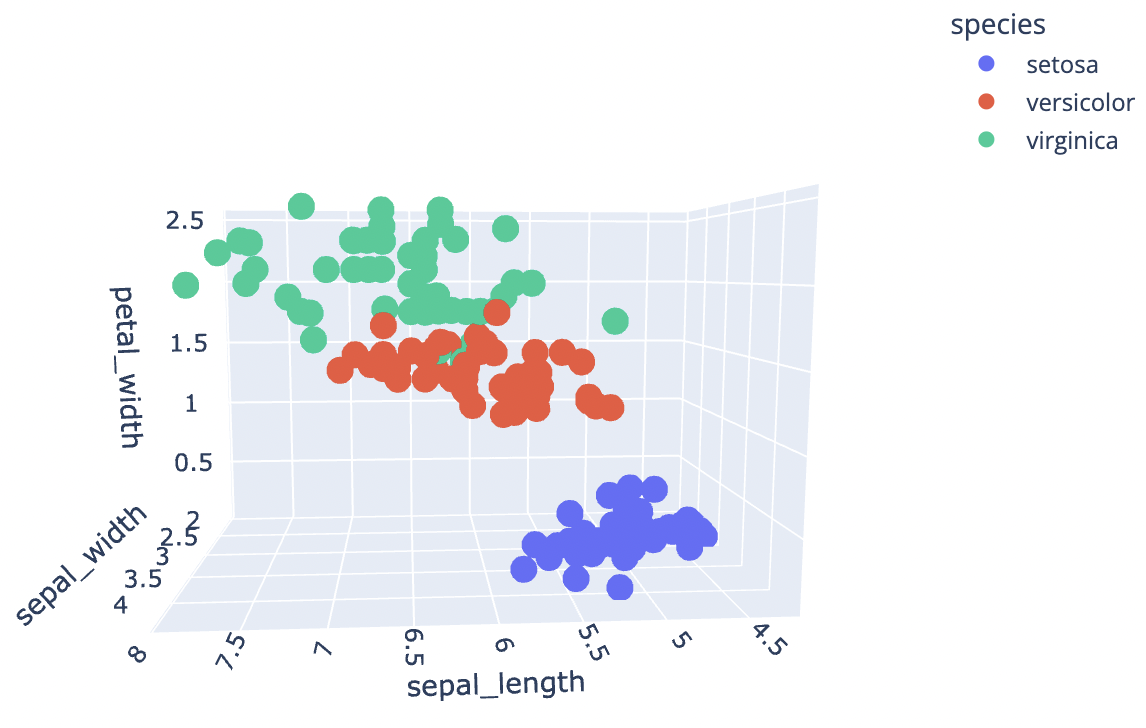
We can observe that the Setosa flowers are nicely separated from the Versicolor and Verginica flowers after moving the plot in 3D space. We can insert a plane separating the flowers here, similar to the line separating the flowers in the 2D scatter plot.
Because 3D is the maximum dimension we have ever experienced, we are unable to comprehend 4D, 5D, and so on, and so plotting in n dimensions (n>3) makes no sense. But, as creative beings, we’ve invented some methods/hacks for plotting information so that we can make sense of it. So, Pair-plot, our next charting tool, is here.
Pair-Plot
We’ll use a pair-plot to depict our four features (4D data), namely sepal length, sepal width, petal length, and petal width. We’ll build pairs of two features, as the name implies, then plot each pair one after the other. There are a total of 4C2 = 6 distinct graphs.
With the help of a visualization library called seaborn, we can easily accomplish this.
sns.pairplot(iris, hue="species", size=3); plt.show()
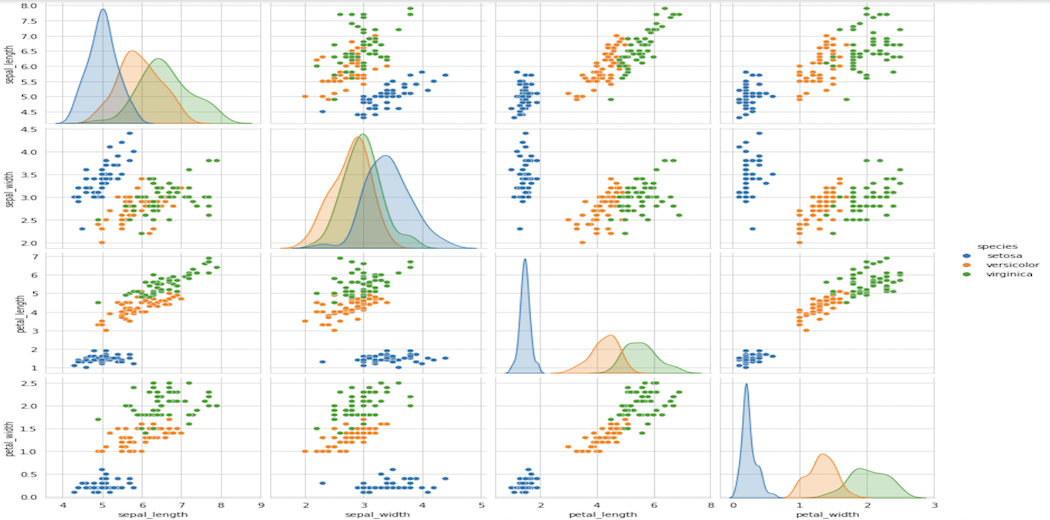
Pair Plot
It’s a 4×4 matrix in our case, with non-diagonal entries being pair-plots and diagonal elements being PDFs for each feature, as we’ll see later in this article.
Some of the observations we can make from this plot are:
The most useful features for identifying different flower varieties are petal length and petal width.
While Setosa is distinguishable (linearly separable), Virnica and Versicolor share some characteristics (almost linearly separable).
To identify the flower varieties, we can use “lines” and “if-else” conditions to create a simple model.
Limitations of Pair-plots:
We can see from this example that we need to look at 6 different plots for 4-dimensional data, but in the area of machine learning, we frequently have a big dimensional dataset with 100, 1000, or even 10,000 features. As a result, we have
10C2 = 45 unique plots for ten features.
We have 100 plots with 100C2 = 4950 unique features.
We have 1000 plots with 1000C2 = 499500 unique features.
It’s mind-boggling to see so many different plots, and it’s impossible to analyze and draw conclusions from all of them.
Other algorithms for dimensionality reduction, like PCA and t-SNE, can be used to deal with this issue so that it can be visualized in 2-dimensional space.
Histogram
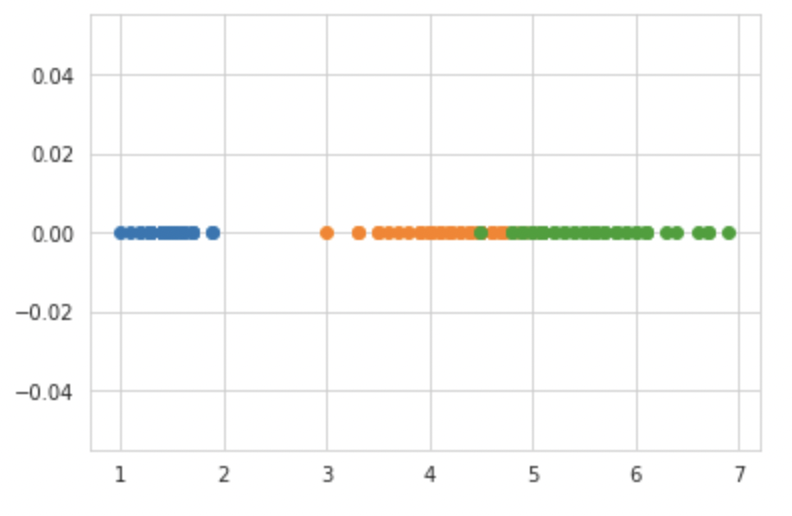
So far, we’ve talked about how to plot 2D scatter plots, 3D scatter plots, and other types of plots, but what about 1D plots? The goal is to use the NumPy library to plot one feature on the x-axis and zeros on the y-axis.
import numpy as np iris_setosa = iris.loc[iris["species"] == "setosa"]; iris_virginica = iris.loc[iris["species"] == "virginica"]; iris_versicolor = iris.loc[iris["species"] == "versicolor"]; #print(iris_setosa["petal_length"]) plt.plot(iris_setosa["petal_length"], np.zeros_like(iris_setosa['petal_length']), 'o') plt.plot(iris_versicolor["petal_length"], np.zeros_like(iris_versicolor['petal_length']), 'o') plt.plot(iris_virginica["petal_length"], np.zeros_like(iris_virginica['petal_length']), 'o') plt.show()
Because there are so many overlapping points in a 1D scatter plot like this, we can’t determine the count of points in a specific zone, which would be useful in further analysis.
So, instead of setting y-axis values to 0, if we have the count of points as y-axis after dividing the feature into regions of size ‘n,’ there is a simple workaround to this. What we now have is a Histogram plot, with the x-axis representing the feature and the y-axis representing the frequency of these points.
sns.FacetGrid(iris, hue="species", size=5) .map(sns.distplot, "petal_length") .add_legend(); plt.show();
This plot is also known as a density plot since it shows the number of points in a given area. If I were to create a very simple model based just on this plot, I could write if petal length <= 2 then categorize it as Setosa, but there would be some uncertainty in determining the threshold value for classifying Versicolor and Verginica due to some overlap. The Probability Density Function, or PDF, is the smooth curve that we observe here. As of now, you can think of it as a smooth version of a histogram.
Univariate Analysis using PDF
Univariate analysis is used to look at only one variable at a time. One such tool that aids in the univariate analysis is PDF.
If we want to know which feature is more useful in identifying these flowers, we can plot the PDF for all features to get an answer to our question
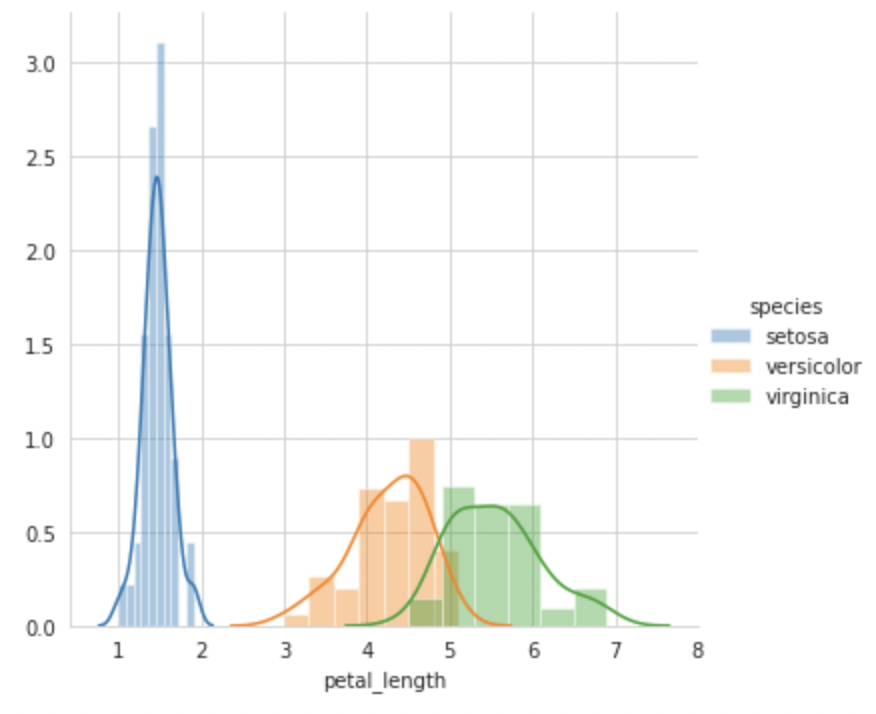
Based on these four plots, we can conclude that petal length is a better feature than any other for classifying flowers into Setosa, Versicolor, or Verginica, as there is a considerably bigger difference between each PDF.
CDF (Cumulative Distribution Function)
#Plot CDF of petal_length
counts, bin_edges = np.histogram(iris_setosa['petal_length'], bins=10,
density = True)
pdf = counts/(sum(counts))
print(pdf);
print(bin_edges);
cdf = np.cumsum(pdf)
plt.plot(bin_edges[1:],pdf);
plt.plot(bin_edges[1:], cdf)
counts, bin_edges = np.histogram(iris_setosa['petal_length'], bins=20,
density = True)
pdf = counts/(sum(counts))
plt.plot(bin_edges[1:],pdf);
plt.show();
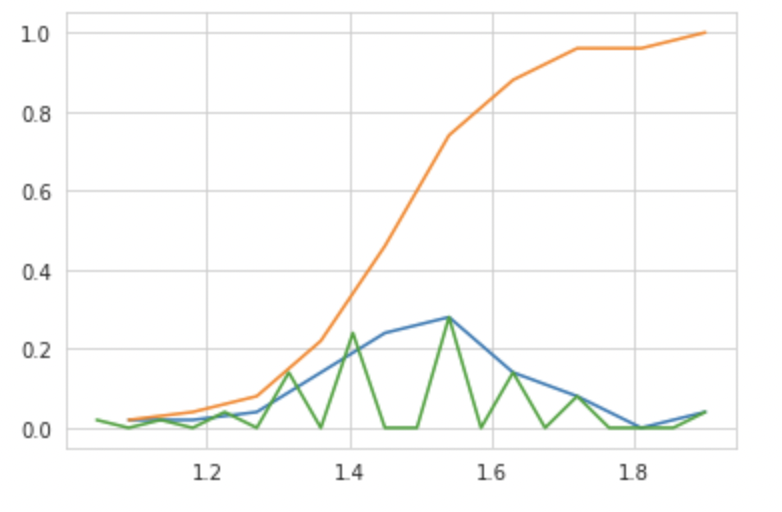
CDF Plot
The number of points in a given location is represented by PDF, whereas the percent of Setosa flowers with petal length equal to ‘x’ is represented by CDF. For example, PL=1.6 is seen in 82 percent of Setosa flowers.
For example, PL=1.6 is seen in 82 percent of Setosa flowers.
NOTE: CDF always starts at zero and ends at one.
Now that we know how to read a CDF, we’d like to learn how to create one; we already know how to create PDF, which is created by plotting a smooth kind of histogram.
Take the x-axis value and count how many Setosa flowers have a length equal to the x-axis value, then divide by the total number of Setosa flowers. Assume there are 41 Setosa flowers with petal lengths of 1.6 and a total of 50 Setosa flowers. As a result, the CDF value for x=1.6 is 41/50 = 0.82.
Another method is to count the values of each histogram of x-axis values cumulatively to obtain the CDF at that particular x-axis value, or to put it another way, the Area under the Curve of PDF is nothing more than the CDF.
=> Differentiate CDF ⇒ PDF
=> Integrate PDF ⇒ CDF
How is CDF useful?
We may use the basic if-else condition to determine the correctness of classification of each flower kind using simply CDF.
Mean, Variance, and Standard Deviation
The mean is the sum of all the observations. It reveals the flower’s central tendency.
When the mean petal length for each of the three flower varieties is printed, it is evident that the Setosa has a substantially shorter petal length than the Versicolor and Virginica.
WARNING: The mean can be influenced by outliers in the dataset.
For example, if 49 of the 50 Setosa petal length readings are between 1 and 2, but one is 100 (say), which is absurdly large for a petal length, this number is referred to as an outlier and will have an impact on the mean value. There could be a variety of reasons why this value exists, such as a typing error, data tampering, and so on.
Variance: It is basically how far are the points from the mean value.
Standard Deviation: square root of variance – It tells us what is the average deviation of the points from the mean value.
WARNING: Outliers in the dataset can affect the Variance and Standard Deviation.
#Mean, Variance, Std-deviation
print("Means:")
print(np.mean(iris_setosa["petal_length"]))
#Mean with an outlier.
print(np.mean(np.append(iris_setosa["petal_length"],50)));
print(np.mean(iris_virginica["petal_length"]))
print(np.mean(iris_versicolor["petal_length"]))
print("nStd-dev:");
print(np.std(iris_setosa["petal_length"]))
print(np.std(iris_virginica["petal_length"]))
print(np.std(iris_versicolor["petal_length"]))

Median, Percentile, Quantile, IQR, MAD
Because at least one outlier can readily alter the mean, variance, and standard deviation, we have notions like Median, Percentile, and others to cope with outliers.
#Median, Quantiles, Percentiles, IQR.
print("nMedians:")
print(np.median(iris_setosa["petal_length"]))
#Median with an outlier
print(np.median(np.append(iris_setosa["petal_length"],50)));
print(np.median(iris_virginica["petal_length"]))
print(np.median(iris_versicolor["petal_length"]))
print("nQuantiles:")
print(np.percentile(iris_setosa["petal_length"],np.arange(0, 100, 25)))
print(np.percentile(iris_virginica["petal_length"],np.arange(0, 100, 25)))
print(np.percentile(iris_versicolor["petal_length"], np.arange(0, 100, 25)))
print("n90th Percentiles:")
print(np.percentile(iris_setosa["petal_length"],90))
print(np.percentile(iris_virginica["petal_length"],90))
print(np.percentile(iris_versicolor["petal_length"], 90))
from statsmodels import robust
print ("nMedian Absolute Deviation")
print(robust.mad(iris_setosa["petal_length"]))
print(robust.mad(iris_virginica["petal_length"]))
print(robust.mad(iris_versicolor["petal_length"]))
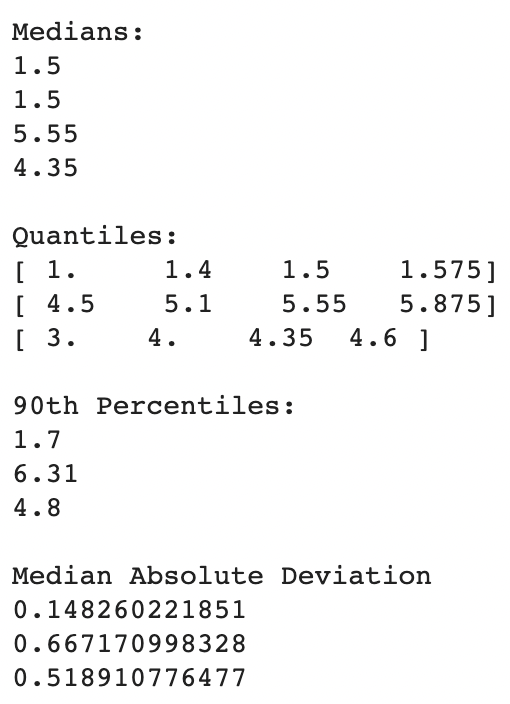
The existence of outliers has no/very little effect on these values.
How is Median calculated:
Arrange your numbers in numerical order.
Count how many numbers you have.
If you have an odd number, divide by 2 and round up to get the position of the median number.
If you have an even number, divide by 2. Go to the number in that position and average it with the number in the next higher position to get the median.
Let’s start with a definition of Quantiles and Percentiles. Percentiles are a unit of measurement that divides organized data into hundredths. A given percentile in a sorted dataset is the point where that percent of the data is less than where we are now. The median is what the 50th percentile is. It signifies that half of the data has a lower value than the median. Quartiles are a type of percentile that divides data into fourths. The 25th percentile corresponds to the first quartile, Q1, and the 75th percentile corresponds to the third quartile, Q3. The median is also known as the 50th percentile and the second quartile.
The Interquartile Range (IQR), also known as the midspread, middle 50%, or spread, is a statistical dispersion measure that equals the difference between the 75th and 25th percentiles, or upper and lower quartiles.
Let me now discuss the MAD, or Median Absolute Deviation, which is the standard deviation’s equal. It also determines how far the data points deviate from the central tendency of the data without being influenced by outliers.
Box Plot
While PDF is excellent at determining data density and distribution, it cannot tell me where the 25th and 75th percentiles are located, which is crucial information. Instead of utilizing CDF, a plot known as the Box Plot can be used.
Box plots, like any other plot, are simple to plot with the seaborn library.
sns.boxplot(x='species',y='petal_length', data=iris) plt.show()
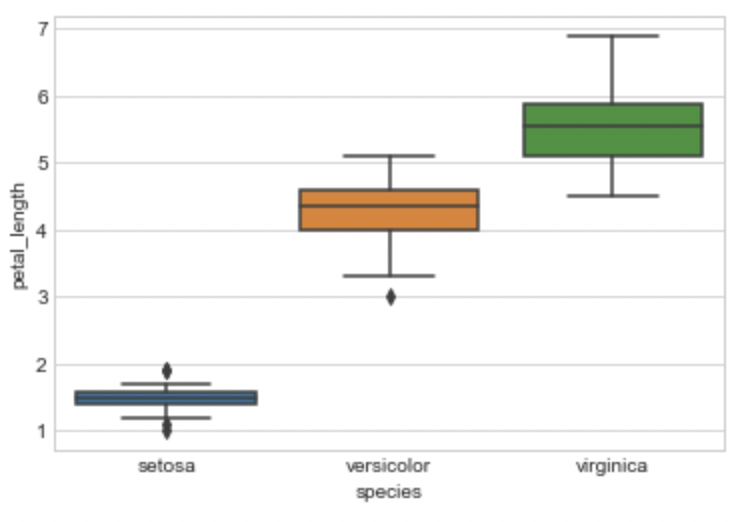
Box Plot
I’m charting the box plot for the petal length of each iris flower species here. Let’s try to comprehend the box plot immediately. The IQR is represented by the box, with the 25th percentile at the bottom, the 50th percentile in the middle, and the 75th percentile at the top. The box’s horizontal length makes no difference. The Whiskers are the two lines above and below the box. To calculate these whiskers, the Seaborn library multiplies IQR by 1.5. The majority of the points are located in this area. The outliers are the spots outside the whiskers.
Violin Plots
sns.violinplot(x="species", y="petal_length", data=iris, size=8) plt.show()
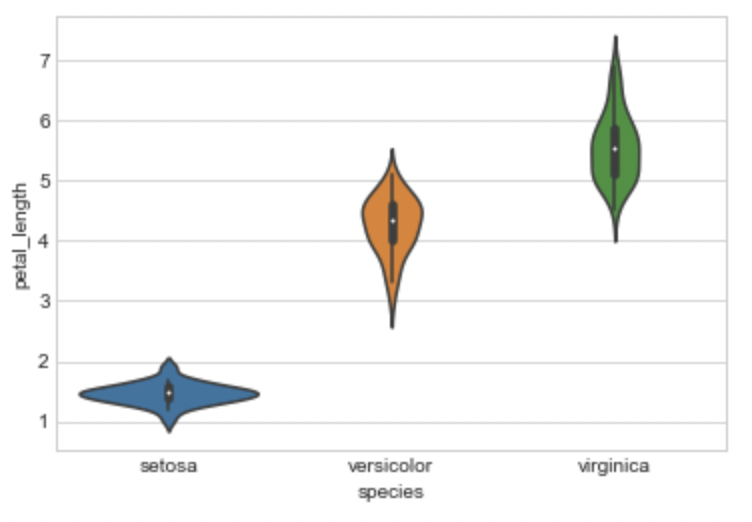
Violin Plot
The benefits of the box plot and the PDF are combined in a violin plot, which then simplifies them.
Let’s try to figure out what’s going on in this plot. The box plot’s thick black box represents the result, while the white dot in the middle represents the median value, with the base representing the 25th percentile and the top representing the 75th percentile. The whiskers signifying IQR are the two thin lines that emerge from the box.
The PDF is plotted on the sides of the box plot, and the PDF is represented by a leaf-like structure. So we get the best of both worlds in a single plot.
Multivariate Probability Density Contour Plot:
sns.jointplot(x="petal_length", y="petal_width", data=iris_setosa, kind="kde"); plt.show();
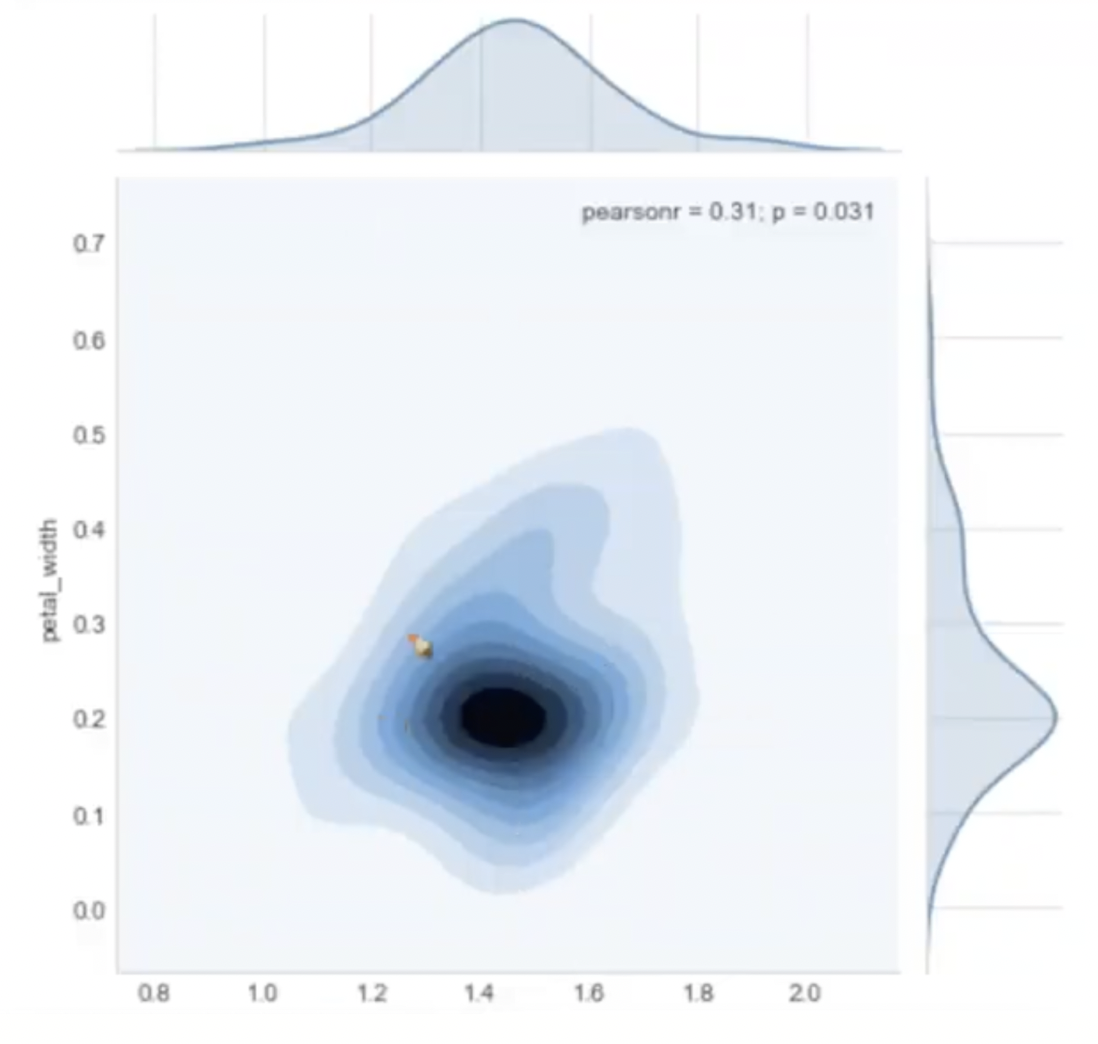
Contour Plot
The darker color denotes the presence of more points in this area. It can offer us a sensation of density in a 2D plane in some ways.
Final Note On Exploratory Data Analysis
Explain your findings/conclusions in plain English
Never forget your objective (the problem you are solving). Perform all of your EDA aligned with your objectives.
These plots can be divided into 3 categories:
Univariate: Analyzing the data using one variable. Eg. PDF, CDF, Box plot, Violin plot
Bivariate: Analyzing the data using two variables. Eg. Pair plot, Scatter plot
Multivariate: Analyzing the data using more than 2 variables. Eg. 3D scatter plot.
Please note that this is just the beginning of EDA, as you start practicing it more often, the more confident you’ll become at it and slowly you’ll have more EDA tools at your disposal to play with.
References
Thanks for Reading!🤗
If you like reading my blogs, consider following me on Analytics Vidhya, Medium, Github, LinkedIn.
Hello there! 👋🏻 My name is Swapnil Vishwakarma, and I'm delighted to meet you! 🏄♂️
I've had some fantastic experiences in my journey so far! I worked as a Data Science Intern at a start-up called Data Glacier, where I had the opportunity to delve into the fascinating world of data. I also had the chance to be a Python Developer Intern at Infigon Futures, where I honed my programming skills. Additionally, I worked as a research assistant at my college, focusing on exciting applications of Artificial Intelligence. ⚗️👨🔬
During the lockdown, I discovered my passion for Machine Learning, and I eagerly pursued a course on Machine Learning offered by Stanford University through Coursera. Completing that course empowered me to apply my newfound knowledge in real-world settings through internships. Currently, I'm proud to be an AWS Community Builder, where I actively engage with the AWS community, share knowledge, and stay up to date with the latest advancements in cloud computing.
Aside from my professional endeavors, I have a few hobbies that bring me joy. I love swaying to the beats of Punjabi songs, as they uplift my spirits and fill me with energy! 🎵 I also find solace in sketching and enjoy immersing myself in captivating books, although I wouldn't consider myself a bookworm. 🐛
Feel free to ask me anything or engage in a friendly conversation! I'm here to assist you in English. 😊



