What is numpy.random.seed? Are you confused about what number to feed in the seed? For what situation can I use this function? In case you have any of these or all questions in your mind. You have come to the right place. This article will answer all the above questions in laymen’s terms.
We will explore the syntax of the numpy random seed function in more detail. Then we will explain each element of this function in depth. Finally, this article will provide you with real-time examples applying this function.
This article was published as a part of the Data Science Blogathon
Table of contents
What is numpy.random.seed?
numpy.random.seed is a function in the NumPy library that sets the seed for generating random numbers. By specifying a seed value, the function ensures that the sequence of random numbers generated remains the same across multiple runs, providing deterministic behavior and allowing reproducibility in random number generation.
numpy.random.seed Code Snippets
import numpy as np #Code A
np.random.seed(0) #Code B
s=np.random.choice(5,10) #Code C
print(s)# Code DLet us see how the above python code works in the following section.
- Code A: Import the numpy python package and create an alias name as “np.”
- Code B: Generates pseudo-random number based on seed. Seed can be any number.
- Code C: Returns random samples of numpy array from array between 0 and 5 with the size of 10. The variable “s” stores the result of this code.
- Code D: Prints the variable s.
Once you run the program, you get the following result.
Output:
[4 0 3 3 3 1 3 2 4 0]We get an array of 10 numbers of a random number between 0 to 5.
Now let us explore the pseudo-random number generator in more detail.
numpy.random.seed Syntax Expounded

What is NumPy?
NumPy is an open-source basic python package used in the field of science and engineering. It stands for Numerical Python, discovered by Travis Oliphant, Data Scientist, in 2005. A mix of Python and C ++ programming languages is employed to create this package. Numpy package is used with other Data science python libraries such as Pandas, SciPy, Matplotlib, scikit-learn, scikit-image to name a few.
Numpy provides multidimensional arrays called ndarray objects. It has numerous functions for mathematical operations, statistical operations, logical manipulations, basic linear algebra, random simulation, matrices, and much more.
The Main features of Numpy are listed below:
- Ndarray is 50 times faster than an ordinary python list. Why is it the case? Numpy arrays store the memory in one designated location. So array data is accessed and processed more efficiently than lists.
- When creating the array, the size is fixed. But Python lists size can be changed to the existing list. Whereas to adjust the size of the NumPy array, you have to create a new array and delete the old one.
- The data type of each element for the array is identical in the Numpy array with the same memory size.
- Numpy arrays support advanced mathematical operations where operations require a large amount of numeric data. With few lines of python code, numpy can execute the numerical operations more efficiently than lists, tuple, and range objects.
- Beginner coders to expert researchers use Numpy. These researchers use it for performing high-tech industrial and Scientific R&D Purposes.
What Does numpy.random.seed Do?
Can you guess what is the winning raffle draw number will be in a lottery?
We can’t predict the correct winning number with our knowledge, and it is very unpredictable. The winning number is the random number, and it means a set of digits arranged in an irregular, inconsistent order.
Generating numpy random seed numbers through our computer program is not that easy. It will be easy to predict the numpy random seed number through programs. Then it is not truly a numpy random seed. Thus, Computers are deterministic and can’t be random.
We provide a set of defined instructions to the computer through programming, and it works on it. For each input you provide, you will receive the same output only. So how can we generate random numbers on the computer if this is the case? Our computer scientists solve this issue by creating algorithms.
Algorithm what it is? Let us understand the algorithm’s process first before we continue to numpy random topics.
In laymen’s terms, an algorithm is a series of commands that instructs a computer to transform a set of data about the world into valuable information. This information can be knowledge for people, input for machines, or any other algorithm.
Let us take a simple example to understand more about algorithms
Suppose you are telling five-year-olds how to get dressed in the morning.
The process is as follows:
Input:
[For a Computer, Input is a set of data for making decisions]The data you required to get dressed in the morning areas listed below:
- What are the clothes available to you in your wardrobe?
- What is today’s temperature? “25 degrees C or 40 degrees C”
- What is the weather forecast today? “rainy or foggy or sunny.”
- What is the season ? “winter or summer.”
- What is your liking? “color or fittings.”
We have to answer the above questions to choose proper attire.
Transformation:
[ For a Computer, It is the primary process of algorithm, which is computation. It involves arithmetic operations, decision-making, and repetition process.]In our case, we have to perform a decision-making process based on the above data on getting dressed, for example.
The decisions are as follows:
- Your decision to put on a jacket depends on the temperature,
- Your chosen jacket type depends on the forecast,
The temperature is 25 degrees C, and it is raining, so pick up the rain jacket and long-sleeved top to wear it inside. After choosing an appropriate dress, next, we need to wear it. This process is called repetition in the algorithm.
Output:
[For a Computer. This process is an algorithm Output or Result. It can be presenting information into the screen in the form of words, audio, or other forms of communication.]So, after you have dressed, then you go out of the house to enjoy the climate.
I hope you have understood the algorithm process. Now let’s come back to our topic.
For generating a random number into our computers, Computer Scientist has discovered an algorithm called a pseudo-random generator. The pseudo-random number produces numbers close to the properties of randomness. In other words, it means that since the computer is determined, these numpy random seed numbers are not truly random, and it is similar to it. Say, for example, we can say 60% randomness. But there is no pattern in the numbers. In the next section, you understand well what this means when you learn it with python code.
The numpy random seed is a numerical value that generates a new set or repeats pseudo-random numbers. The value in the numpy random seed saves the state of randomness. If we call the seed function using value 1 multiple times, the computer displays the same random numbers. When the value is not mentioned in the numpy random seed, then the computer will use the current system time in seconds or milliseconds as a seed value to generate a different set of random numbers.
Let’s look at the code snippets below to understand better how a numpy random seed works:
Python Code:
import numpy as np
# CodeSet A
np.random.seed(1)
s=np.random.randint(5,10,12)
print("Seed 1")
print(s)
print()
# CodeSet B
np.random.seed(2)
s=np.random.randint(5,10,12)
print("Seed 2")
print(s)
print()
# CodeSet C
np.random.seed()
s=np.random.randint(5,10,12)
print("Seed")
print(s)
print()
# CodeSet D
for i in range(7):
np.random.seed(1)
s=np.random.randint(5,10,12)
print("Seed")
print(s)- CodeSet A: We feed value 1 into the seed and get a random number between 5 to 10 with the size of 12 digits. Refer to code
- CodeSet B: We feed value 2 into the seed and get a random number between 5 to 10 with the size of 12 digits. Refer to code
- We get different random numbers from the above two codes based on the seed values.
- CodeSet C: We don’t feed any value to the seed and run the script, and we get a different array of numbers based on a computer seed value.
- CodeSet D: In this code, we iterate the randint function with seed value set to 1. You can see that each iteration array of the random number is identical each time of the iteration array. This is the case we are trying to explain what pseudo-random number.
numpy.random.seed Functions
This section will learn about a few of the numpy random seed functions used in the scientific and engineering field.
Random Function
numpy.random.random(size=None)
This function returns a random number in float data type like 0.0, 1.0.
The parameter we have to feed is size, and it can be integer and tuple.
import numpy as np
np.random.seed(10)
s=np.random.random(5)
print("The random numbers are:")
print(s)Output:
The random numbers are:
[0.77132064 0.02075195 0.63364823 0.74880388 0.49850701]The above code returns an array of 5 numbers in float type for a seed value of 10.
If you change the seed value, you will get a different set of random numbers.
Random Integer Function
numpy.random.randint(low,
high=None, size=None, dtype=int)randint function returns random integers from low integer to high integer.
Also, you can specify the size of the array.
import numpy as np
np.random.seed(10)
s=10 * np.random.randint(1,5,10)-2
print("The random numbers are:")
print(s)Output:
The random numbers are:
[18 18 8 38 8 18 38 8 18 18]Code above provides our random number between 1 to 5 with the size of 10 digits for a seed value of 10. The result will be in integer data type.
Random Shuffle function
numpy.random.shuffle(x)
The shuffle function changes the order of the arrays, but the contents will be the same where x has to be an array.
import numpy as np
np.random.seed(10)
x = np.arange(10)
print("The ordered Number 0-9 are shown below:")
print(x)
s = np.random.shuffle(x)
print("The shuffle numbers are shown below:")
print(x)
print(s)Output:
The ordered Number 0-9 are shown below:
[0 1 2 3 4 5 6 7 8 9]
The shuffle numbers are shown below:
[8 2 5 6 3 1 0 7 4 9] NoneThe above code shows the ordered and shuffled array using seed value 10. Note that if you print the function itself computer will return None. So you have to print the array itself, which is x in this case.
Random Standard Exponential Function
numpy.random.standard_exponential(size=None)
This function returns random numbers samples from the standard exponential distribution.
The exponential distribution is a constant distribution that we mainly use to measure the estimated time for an event to occur.
import numpy as np
np.random.seed(10)
s=np.random.standard_exponential((3,10))
print("The random numbers are:")
print(s)Output:
The random numbers are:
[[1.47543445 0.0209703 1.0041613 1.3815213 0.69016565 0.25462989
0.22072506 1.42933011 0.18525887 0.09248796]
[1.15632557 3.06601196 0.00395608 0.71783393 1.67462177 0.9481067
1.2792544 0.34513616 2.49828522 1.25377873]
[0.78207538 0.15334939 0.46735236 1.12126784 0.58309739 0.56918592
0.96172485 0.71977506 1.05095757 0.91889149]]The above code produces an output of 30 sets of random numbers in an array. The size here is 3*10 = 30. There are 3 sets of the array, and each array contains 10 random numbers.
Random Triangular Function
numpy.random.triangular(left, mode, right, size=None)
The numpy.random.seeds.triangular functions return samples of random numbers from a triangular distribution between left to right intervals.
The triangular distribution is a constant probability distribution starting from the lower limit (left in above function) then moving higher at peak (mode in above function) end to the upper limit (right in above function). The data plotted in a chart is a Triangular Shape.
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(10)
plt.hist(np.random.triangular(0,20,30,200000), bins = 300,density=True, facecolor='g')
plt.show()Output:
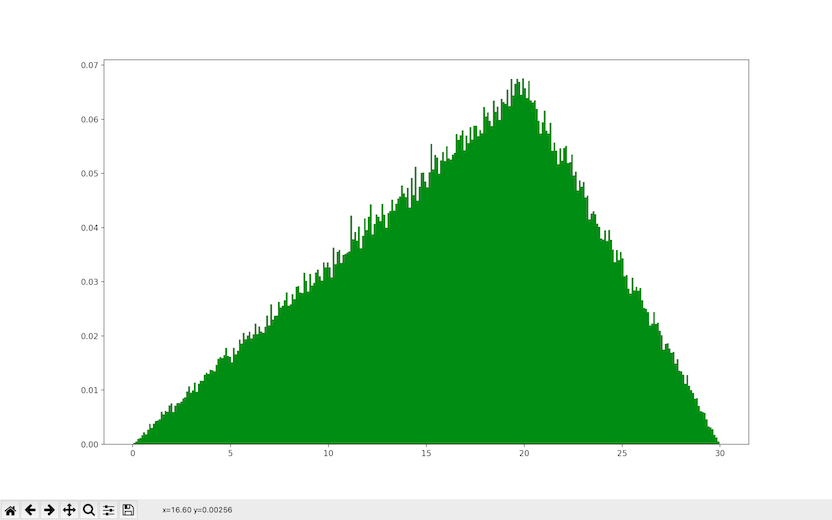
The above code plots histogram starting from number zero, the lower limit on the left side, then peaks at 20 levels, i.e., mode, and ends at the upper limit to the right side at 200000 levels. We can see that histogram is triangular. Refer to the Image 2.
Where is numpy.random.seed used?
Let’s take an example to show how we employ NumPy Random Seed functions in the code.
Suppose you plan to sell new products into the market in the FMCG sector. You have decided to sell chocolate cookies with the brand name Martin Cookie.
During the first month of business, you have sold 100 biscuits at a price of USD 10 each. Now you are thinking if business sales will grow in the following months. And you want to predict the growth almost accurately. So, you have conducted a survey and consulted the FMCG brand specialist. From the survey results and consultation from a specialist, you have gathered the following data:
- The Net Growth of the business sales will be between 10%-15% monthly
- There will be a drop in the growth in a few months
- Total Sales for the first month is USD 1000.
Now you want to know what average sales for each month for a year will be with a higher probability. Also, you want to see the probability of achieving higher sales.
We can find out this by using the Monte Carlo simulation method.
Monte Carlo simulation is a tool to estimate different outcomes with each probability from given random variables.
We use the normal distribution to estimate the five-year growth rate to get information close to accuracy. In normal distribution function, the bell curve peaks at the mean (average), and the majority of the numpy random seed sample data will be close to the mean. So, we can get an accurate picture.
#import libraries
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
#create seed value
np.random.seed(1) #Code A
#create hypothetical revenue growth rate data for 60 months
growth_rate = np.random.normal(0.10,0.15,61) #Code B
#Run 10,000 times of simulation
simulation = 10000 #Code C
revenue =[] #Code D
for rnd in range(simulation): #Code E
#Randomly select the revenue growth rate for 12 months from a list of 60 months
indx = np.random.randint(0,61,12) #Code F
select_growth_rates=growth_rate[indx] #Code G
#Intially 100 bisuits are sold in first month for USD 10/- each
total_bis_sold = 100 #Code H
price_bis = 10 #Code I
#Create formula to calculate revenue
start_revenue = price_bis * total_bis_sold #Code J
#Calculate the monthly revenue from initial revenuing using growth rate
monthly_revenue = [start_revenue] #Code K
for grow_rate in select_growth_rates: ] #Code L
monthly_revenue.append((1+grow_rate) * monthly_revenue[-1])n #Code M
#Sum the total revenue for the 12 months after the intial revenue
total_revenue = np.sum(monthly_revenue[1:]) #Code N
revenue.append(total_revenue) #Code O
#Plot the total revenue data in to the histogram
cx=sns.displot(revenue,kind ="hist", stat="probability") #Code P
plt.xlabel("Annual Biscuits sales for 12 Months") #Code Q
plt.title(f"""Average annual Biscuits Sales : USD {round(np.mean(revenue))}""") # Code R
plt.show() # Code S
#Calculate average number of biscuits will be sold for a month
print(((np.mean(revenue))/12)/10) # Code TWorking of the Python Code
- Import numpy, seaborn, and matplotlib.pyplot python libraries and create alias names.
- Input the Seed value 1 as shown in the Code A
- Create hypothetical revenue data for five years between the estimated growth rate of 10%-15% using random.normal function. Refer to Code B
- Create “simulation” variable to run 10000 times simulation. See Code C
- Build “revenue” lists to collect revenue data. Refer to Code D
- Generate for loop to simulate the estimate revenue function for 10000 times. Refer to Code E
- Select randomly 12 months sales growth rate from a list of 60 months list using random.randint function. Refer to Code F and G
- Create two variables, “total_bis_sold” and “price_bis,” to store the number of biscuits sold and biscuit’s price. Refer to Code H and I.
- Construct the simulation formula as shown in Code J.
- Insert the initial revenue to variable “monthly_revenue” to calculate the revenues per month as shown in Code L.
- Calculate the biscuits sales revenue for each month until the 10000 time simulation. Refer to Code M and N.
- Append the revenue list with monthly revenues. Refer to Code O.
- Finally, create a histogram plot using the displot function. Refer to Code from P.
Output:
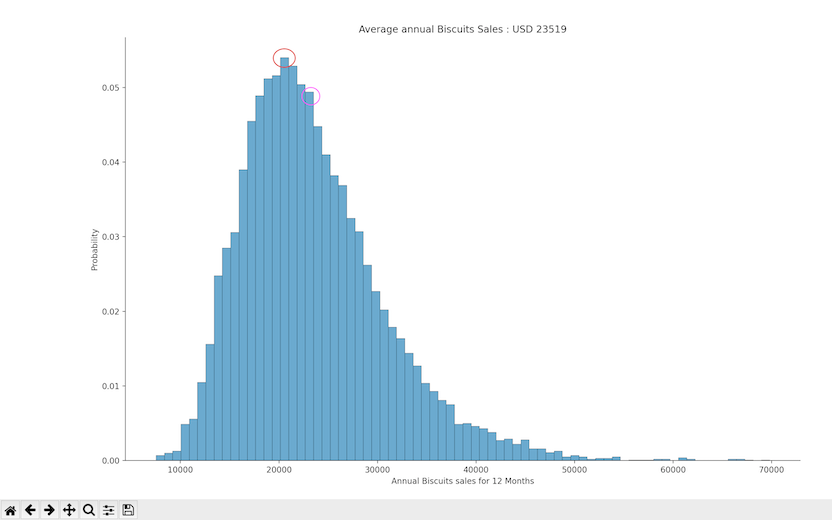
From the output, we can see that, above the 5% probability of having the chance to obtain 20,000 USD sales. The annual average biscuits sales are USD 23,519 that is closer to a higher probability. Sales ranging between USD 30,000 and USD 40,000 have a probability below 3%. We can conclude that we can sell an average of 195 biscuits each month with a confidence of 4.8% probability. Refer to the Image 3.
Conclusion
As we know, Computer output cannot create unpredictable outcomes. NumPy helps us create random numbers with no identical pattern on our computers. We mainly use the numpy.random.seed functions in the scientific and engineering fields, as they derive from statistical concepts. Additionally, we apply the numpy.random.seed function in machine learning and deep learning. So you are familiar with numpy.random.seed() function. Now it’s your time to have a try. Please comment with your feedback.
If you would like to know more, then here is an article to refresh your memory about NumPy.
Thank you for reading! Happy Coding!
Frequently Asked Questions
Q1. What is a random seed in NumPy?
A. A random seed in NumPy is an initial value used to initialize the random number generator. It ensures that the sequence of random numbers generated is reproducible and consistent across different program runs.
Q2. How to set seed for random NumPy?
A. To set a seed for random number generation in NumPy, you can use the numpy.random.seed() function. By passing a specific seed value as an argument, you can initialize the random number generator to produce the same sequence of random numbers.
Q3. What does random seed () do?
A. NumPy’s random.seed() function initializes the random number generator with the specified seed value. It ensures that subsequent calls to random number generation functions produce the same sequence of random numbers when we use the same seed value.
Q4. Why random seed 42?
A. Using a random seed of 42 is a common practice in programming examples or tutorials to demonstrate a specific random sequence. The number 42 holds no inherent significance but often gets chosen for its simplicity and as a reference to Douglas Adams’ “The Hitchhiker’s Guide to the Galaxy,” where it serves as the “Answer to the Ultimate Question of Life, the Universe, and Everything.”
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.







NumPy Random Seed() is a function that returns a random seed for the NumPy random number generator.