Artificial Intelligence & Machine learning is the most exciting and disruptive area in the current era. AI/ML has become an integral part of research and innovations. The main objective of the AI system is to solve real-world problems where businesses are concerned about profitability, sustainability, brand image, cost structure, customers, to compliance. AI products & solutions will be easily adopted by businesses and organizations when this is integrated with the broader enterprise system and consumer-facing organizations can use it to enrich their customers’ experiences. This article will mainly deal with the Machine Learning model in AWS Sagemaker(Sage maker).
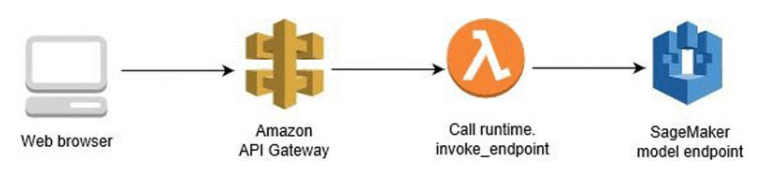
A serverless architecture exposes the runtime inference endpoint available to client software running on consumer devices. REST is a well-architected web-friendly approach and is used to integrate the inference endpoint with the broader enterprise application.
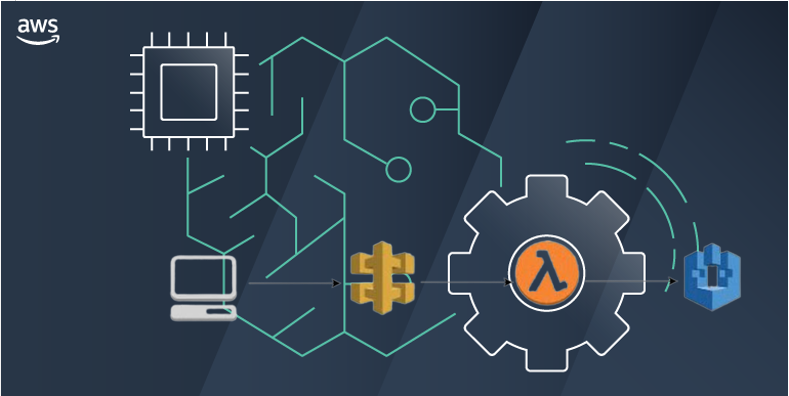
I will describe the step-by-step code and set up to deploy an ML model in AWS Sagemaker using serverless architecture.
The journey from POC to Production is complex and time-consuming. AWS Sagemaker is an advanced Machine Learning platform which is offering a broad range of capabilities to manage large volumes of data to train the model, choose the best algorithm for training it, manage the scalability, capacity of infrastructure while training it, and then deploy & monitor the model into a production environment AWS Sage maker.
Let’s build the problem statement & solution.
This article was published as a part of the Data Science Blogathon.
When we are talking about the data-driven value of Machine Learning systems, customer analysis is always drawing everyone’s interest. There is huge churn in the mobile industry due to the large volume of customers and various service providers.
Mobile operators have historical records on which customers ultimately ended up churning and which continued using the service. Leaving customers affect the business revenue badly. Hence mobile company wants to predict such customers in advance so that they can be retained with additional discount/offers etc.
I am going to build an XGBOOST model with the customer dataset. The data is the historical data. The dataset has the customer behaviour, transaction details which will help the algorithm to detect the pattern and predict the customer churn. The predicted customer is detected as “Churn” and “Not churn”. We will send the prediction to the client system via AWS API Gateway for further use by the business operation team. The operation team will use this data along with other CRM data and try to retain the customer whose churn prediction is high.
The solution will be implemented using AWS Sagemaker-XGBOOST-Container from the Notebook instance. Then the endpoint will be invoked by the Lambda function. AWS API Gateway will call the Lambda when the client system will send a POST request with test data to detect the churn or not churn.
Here we will use a public dataset churn.txt which is available in the AWS Sage maker sample data folder. the folder is accessible from the Sagemaker notebook instance as described below.

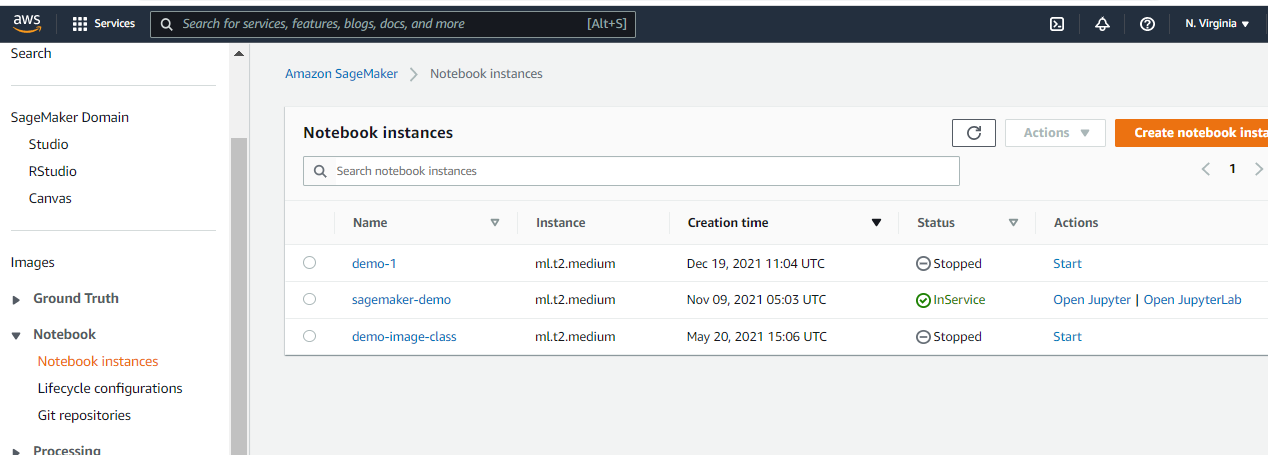
Start the notebook instance from the AWS Sage maker console.
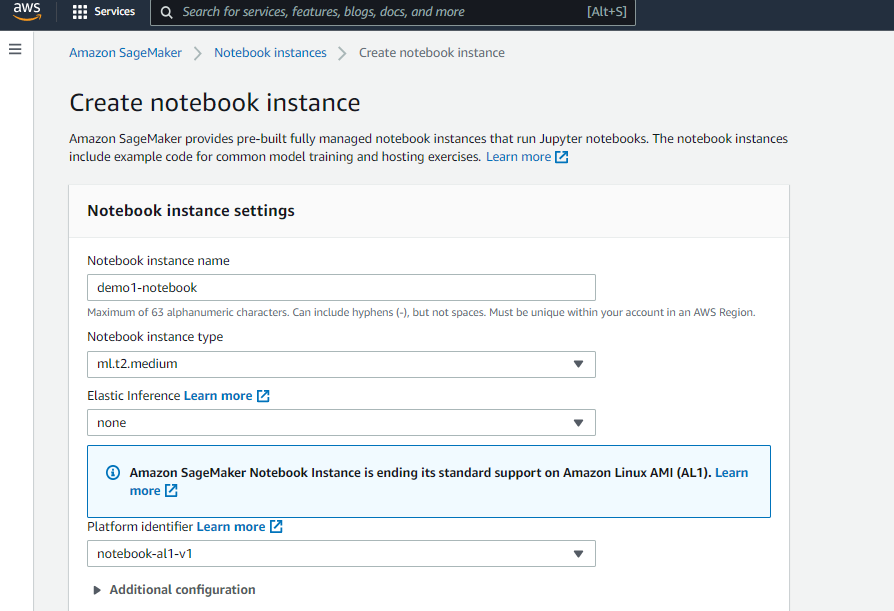
Create the notebook instance with the default setup. Make sure to use the free tier instance (ml.t2.medium) to avoid the accidental costs for the demo project.
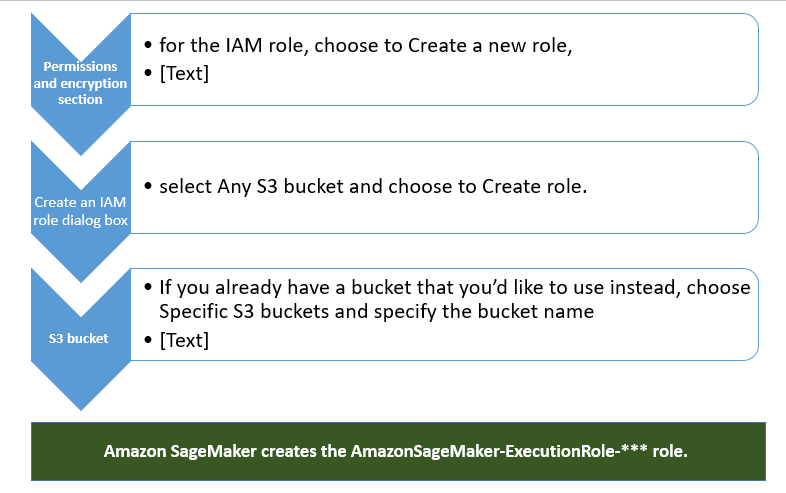
Then open the notebook instance by clicking on jupyter library. In Jupyter, choose New and then choose conda_python3.
For demo purposes, I am using the customer churn notebook available in theAWS Sage maker example. The code details are given below. You can use the same code to perform more data processing, apply different approaches and compare the various results.
However, here the focus is to build the inference endpoint using serverless architecture.
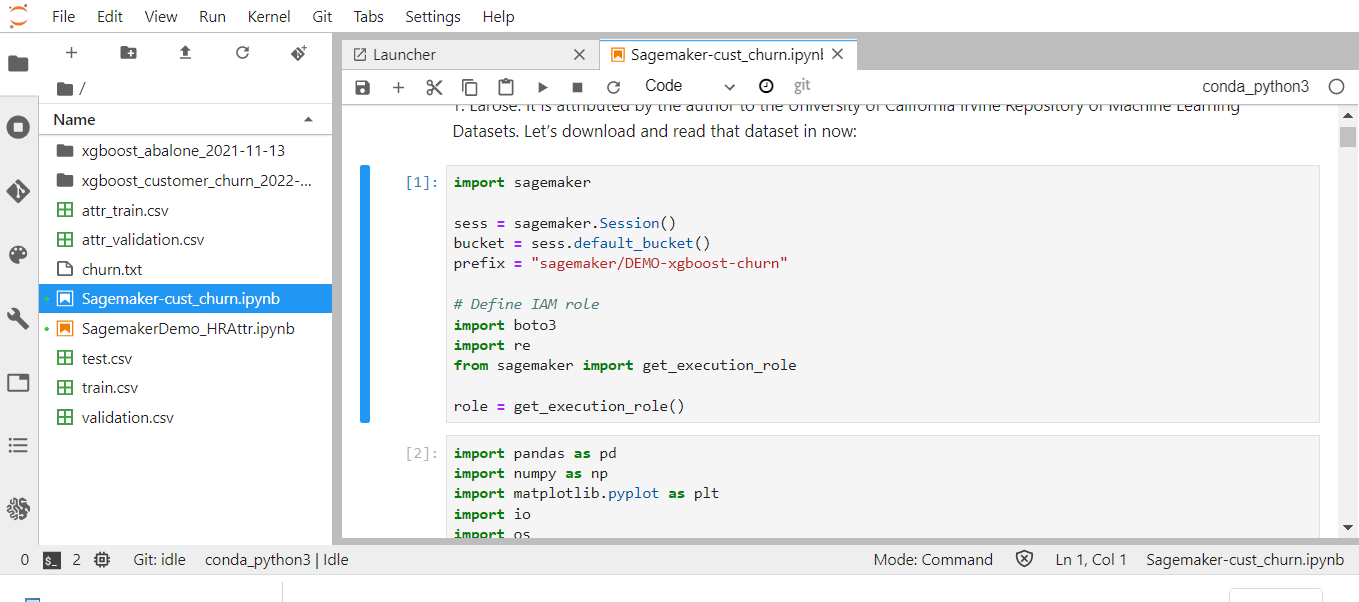
Import the sagemaker libraries, create the AWS Sagemakersession instance. boto3 is imported to use the other AWS services in the notebook instance.
The demo s3 bucket is set to default AWS Sagemaker session bucket. The folder inside the bucket is set by a prefix which will store the train & validation datasets.
import sagemaker
sess = sagemaker.Session()
bucket = sess.default_bucket()
prefix = "sagemaker/DEMO-xgboost-churn"
# Define IAM role
import boto3
import re
from sagemaker import get_execution_role
role = get_execution_role()Import other libraries.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import io
import os
import sys
import time
import json
from IPython.display import display
from time import strftime, gmtime
from sagemaker.inputs import TrainingInput
from sagemaker.serializers import CSVSerializeThe curn.txt file is available in Sagemker demo folder and can be copied using the below command in the notebook.
!aws s3 cp s3://sagemaker-sample-files/datasets/tabular/synthetic/churn.txt ./output->>
download: s3://sagemaker-sample-files/datasets/tabular/synthetic/churn.txt to ./churn.txtRead the file
churn = pd.read_csv("./churn.txt")
pd.set_option("display.max_columns", 500)
churn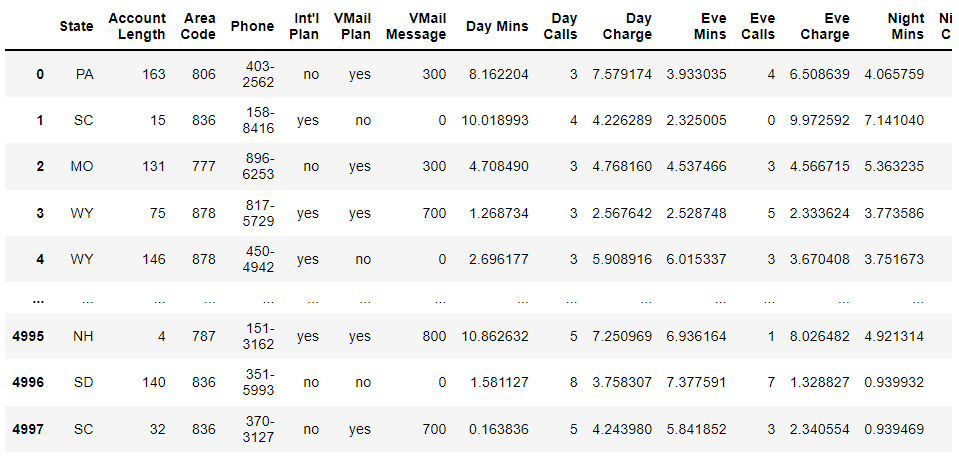
churn.columns

Let’s begin exploring the data:
Frequency tables for each categorical feature
for column in churn.select_dtypes(include=["object"]).columns:
display(pd.crosstab(index=churn[column], columns="% observations", normalize="columns"))
# Histograms for each numeric features
display(churn.describe())
%matplotlib inline
hist = churn.hist(bins=30, sharey=True, figsize=(10, 10))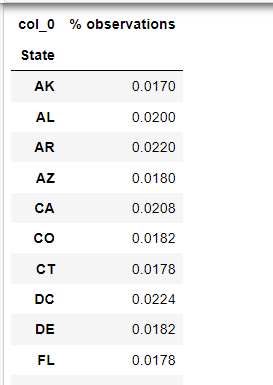
Sample output is shown above, it will show all the columns in the above format.
churn = churn.drop("Phone", axis=1)
churn["Area Code"] = churn["Area Code"].astype(object)for column in churn.select_dtypes(include=[“object”]).columns:
if column != "Churn?":
display(pd.crosstab(index=churn[column], columns=churn["Churn?"], normalize="columns"))
for column in churn.select_dtypes(exclude=["object"]).columns:
print(column)
hist = churn[[column, "Churn?"]].hist(by="Churn?", bins=30)
plt.show()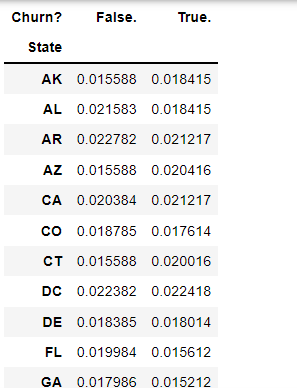
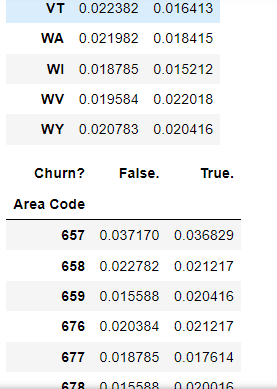
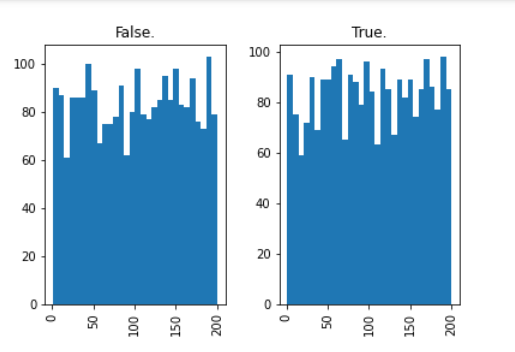
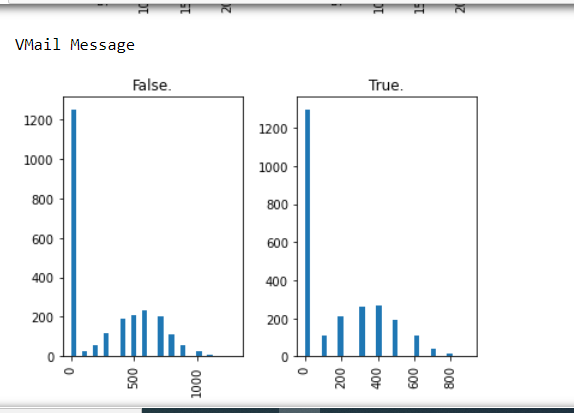
The above screenshots are samples from the output, scroll down on the output section to check all the graphical visuals.
display(churn.corr())
pd.plotting.scatter_matrix(churn, figsize=(12, 12))
plt.show()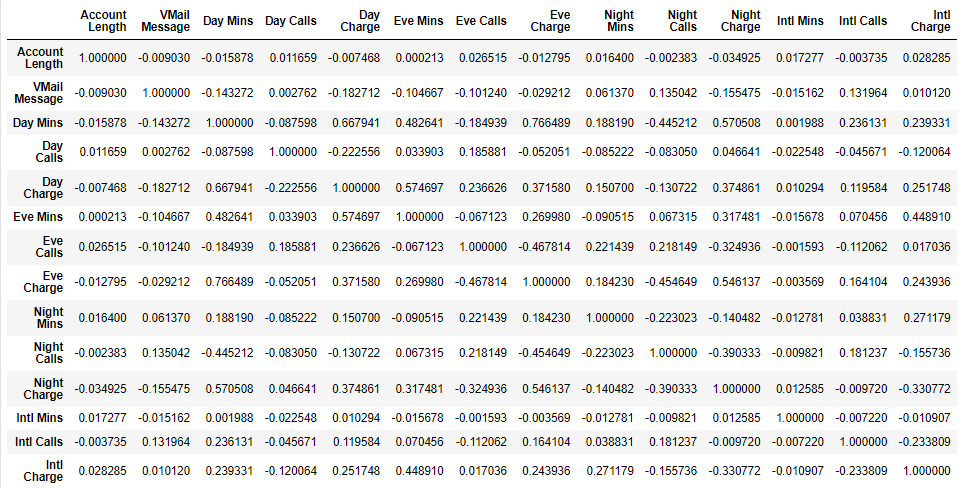
Let’s analyze the data and take decisions on feature extraction:
churn = churn.drop(["Day Charge", "Eve Charge", "Night Charge", "Intl Charge"], axis=1)Applying dummies as one-hot encoding to convert categorical features to numeric.
model_data = pd.get_dummies(churn)
model_data = pd.concat(
[model_data["Churn?_True."], model_data.drop(["Churn?_False.", "Churn?_True."], axis=1)], axis=1
)We will use the Amazon SageMaker pre-built XGBoost container to train the model. This is AWS-managed, distributed scalable environment. Once the model is built we will host the model as a real-time prediction endpoint. The model artifacts will be saved in S3.
XGBoost is an efficient algorithm to handle non-linear relationships between features and the target variable.
Training data will be in either a CSV or LibSVM format for SageMaker XGBoost. We are using CSV format. It must have the predictor variable in the first column & will not have a header row.
Specify the locations of the XGBoost algorithm containers.
train_data, validation_data, test_data = np.split(
model_data.sample(frac=1, random_state=1729),
[int(0.7 * len(model_data)), int(0.9 * len(model_data))],
)
train_data.to_csv("train.csv", header=False, index=False)
validation_data.to_csv("validation.csv", header=False, index=False)
test_data.to_csv("test.csv", header=False, index=False)
len(train_data.columns)
boto3.Session().resource("s3").Bucket(bucket).Object(
os.path.join(prefix, "train/train.csv")
).upload_file("train.csv")
boto3.Session().resource("s3").Bucket(bucket).Object(
os.path.join(prefix, "validation/validation.csv")
).upload_file("validation.csv")
container = sagemaker.image_uris.retrieve("xgboost", boto3.Session().region_name, "latest")
display(container)
Training data is saved in S3. The validation data is used to evaluate the model. test data is used for final prediction. You can test the lambda and API using either validation or test data which are saved in the respective s3 folder as shown below. Also, train and validation csv files are saved in the sagemaker notebook instance folder.
s3_input_train = TrainingInput(
s3_data="s3://{}/{}/train".format(bucket, prefix), content_type="csv"
)
s3_input_validation = TrainingInput(
s3_data="s3://{}/{}/validation/".format(bucket, prefix), content_type="csv"
)
print_train_data = "s3://{}/{}/train".format(bucket, prefix)
print_test_data = "s3://{}/{}/validation/".format(bucket, prefix)
print(print_train_data)
print(print_test_data)
XGBoost hyperparameters are used to build the optimized models.
sess = sagemaker.Session()
xgb = sagemaker.estimator.Estimator(
container,
role,
instance_count=1,
instance_type="ml.m4.xlarge",
output_path="s3://{}/{}/output".format(bucket, prefix),
sagemaker_session=sess,
)
xgb.set_hyperparameters(
max_depth=5,
eta=0.2,
gamma=4,
min_child_weight=6,
subsample=0.8,
silent=0,
objective="binary:logistic",
num_round=100,
)
xgb.fit({"train": s3_input_train, "validation": s3_input_validation})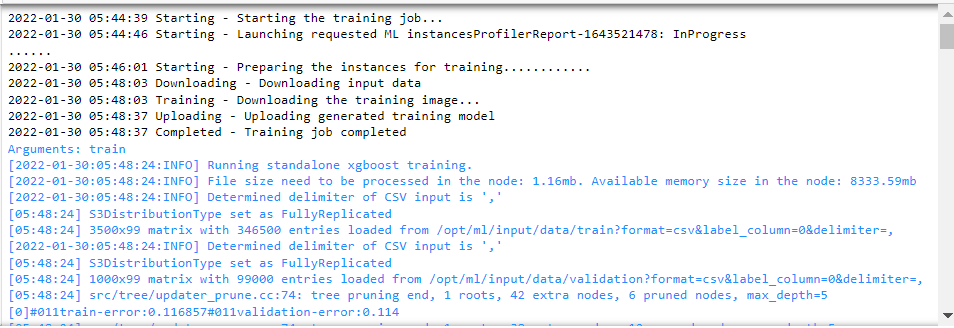
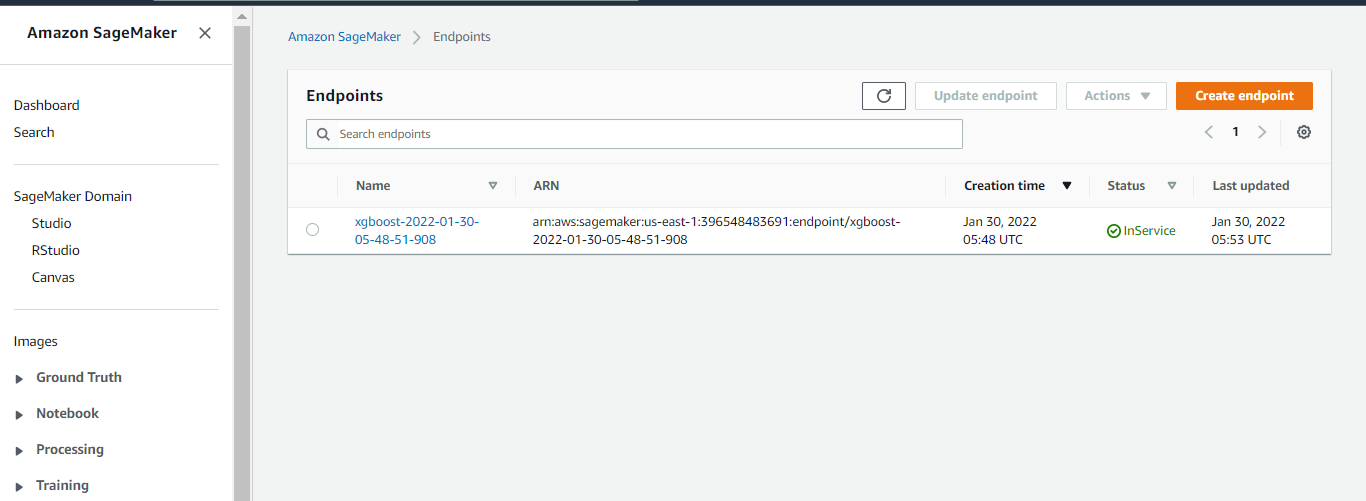
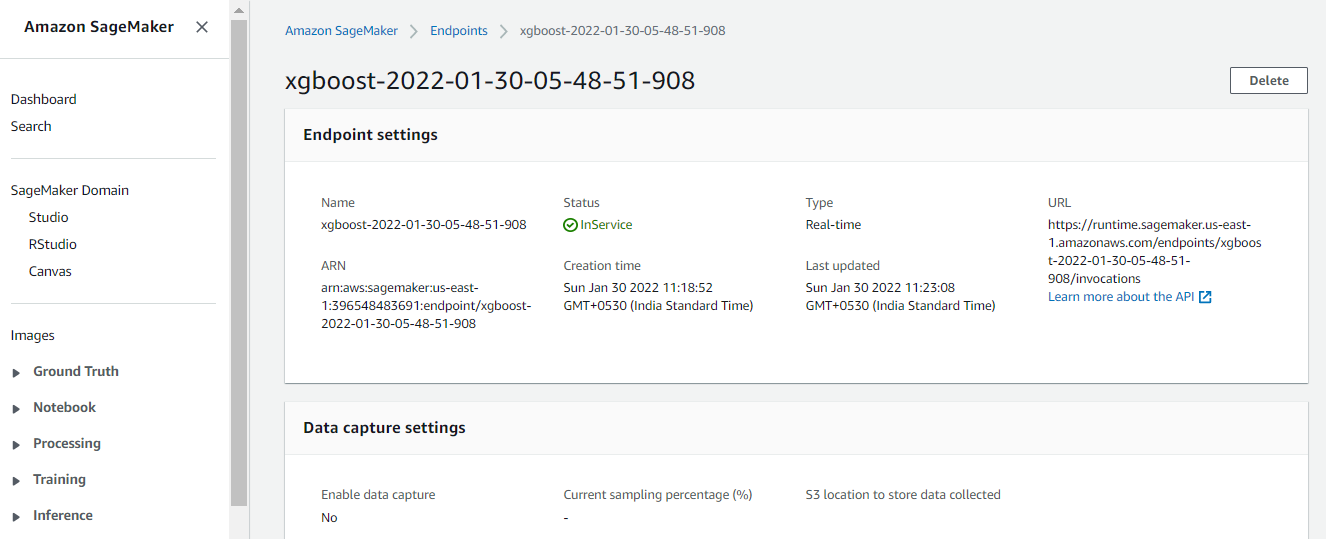
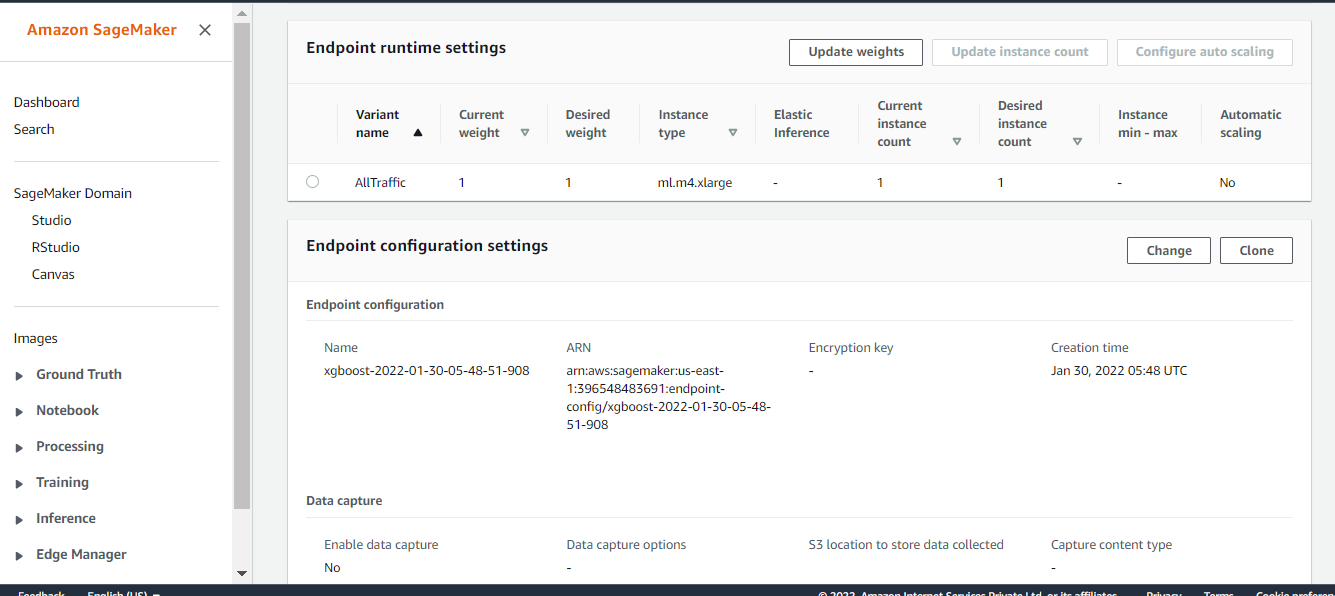
This code deploys the model on a server and creates a AWS SageMaker endpoint that we can access. This step may take a few minutes to complete. Once we have a hosted endpoint running, we can make real-time predictions from the model simply by making an HTTP POST request via AWS API Gateway which will invoke the lambda, and lambda will send a request to the endpoint and get the response back from the endpoint.
xgb_predictor = xgb.deploy(
initial_instance_count=1, instance_type="ml.m4.xlarge", serializer=CSVSerializer()
)Now the below code will deploy the model on an instance and create the SageMaker endpoint. Let’s wait for the endpoint to come “InService”. Then we can make real-time predictions if we pass the test data by making an HTTP POST request via AWS API Gateway. API will invoke the lambda function. Lambda will send a request to the endpoint and get the response back from the endpoint.
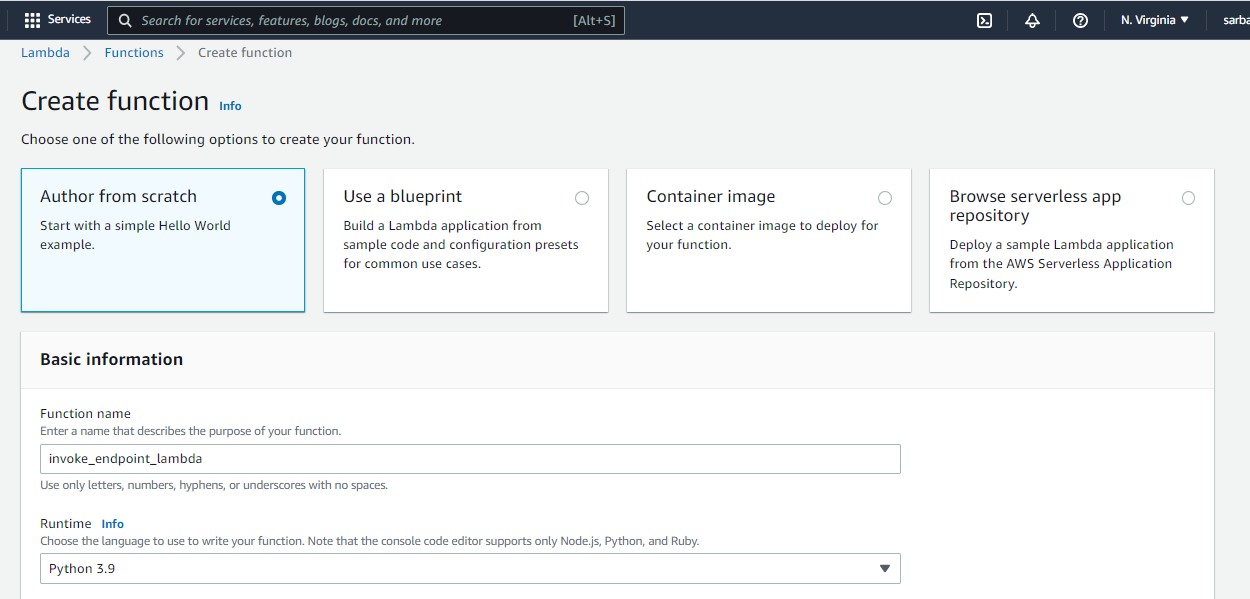
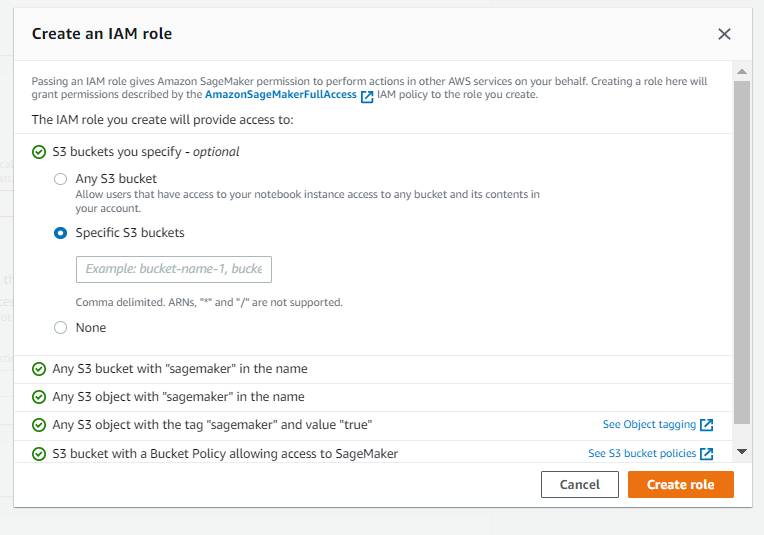
I selected the new execution role for this lambda function. Once created, choose the Lambda AWS Identity and Access Management (IAM) role and add the following policy, which gives the function permission to invoke a model endpoint:
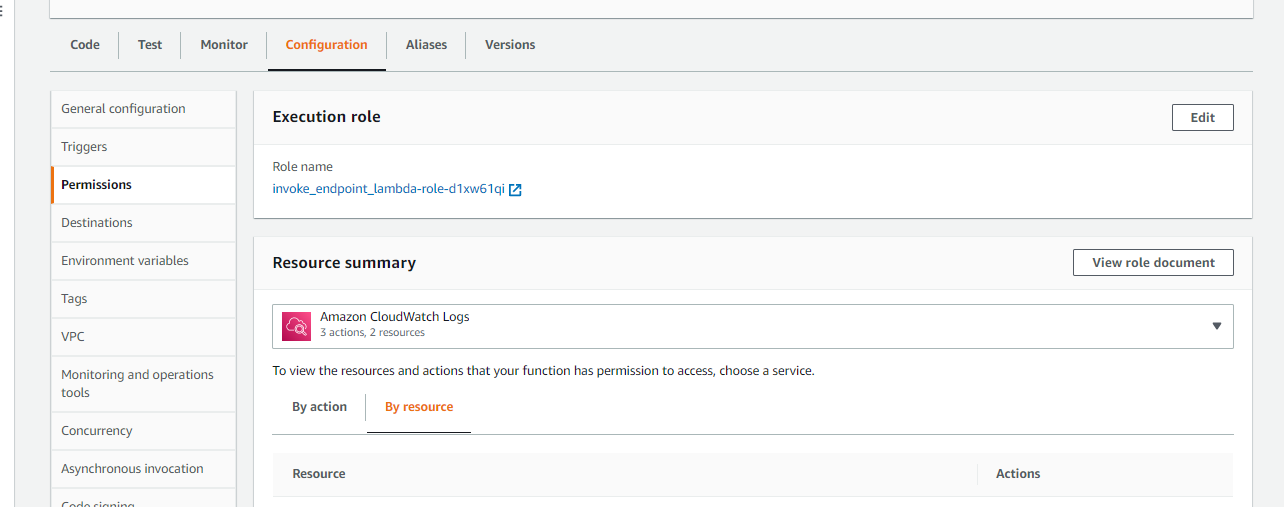
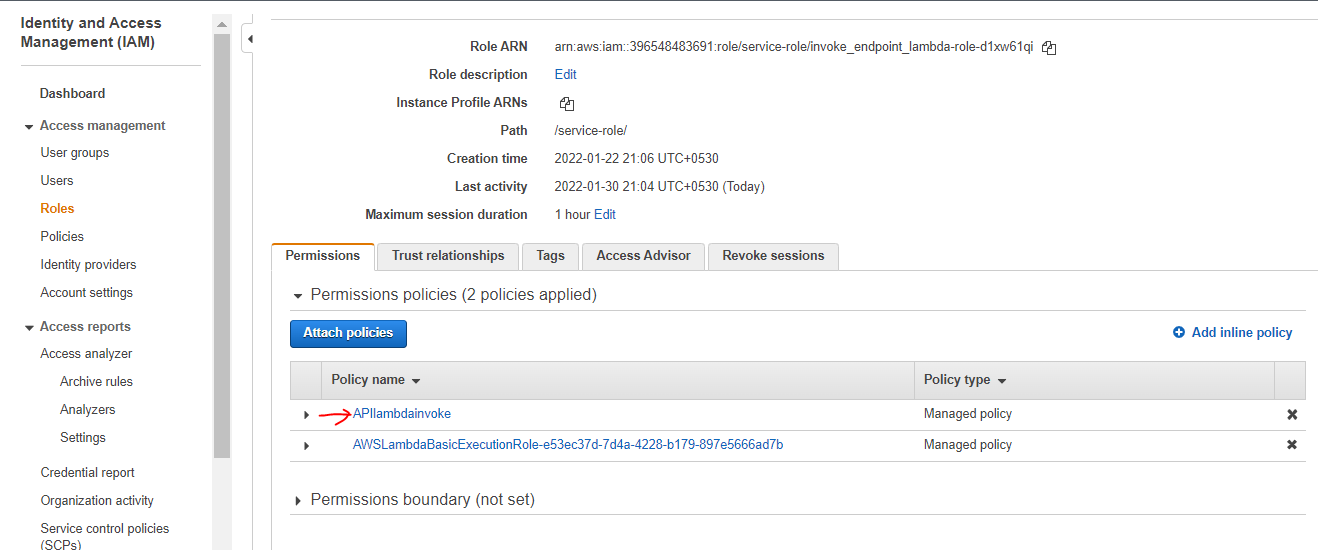
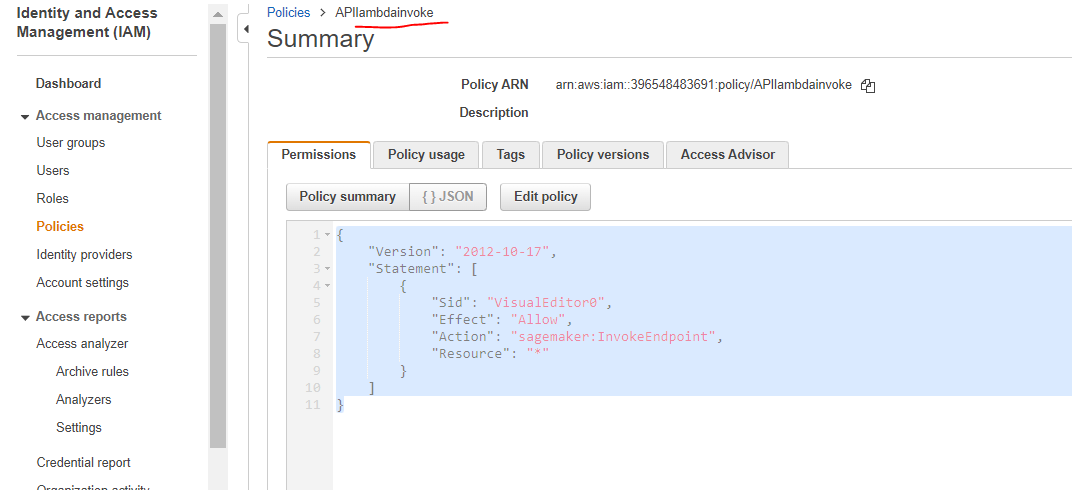
The new policy is shown below for reference, it can be pasted directly in attach policy screen.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "sagemaker:InvokeEndpoint",
"Resource": "*"
}
]
}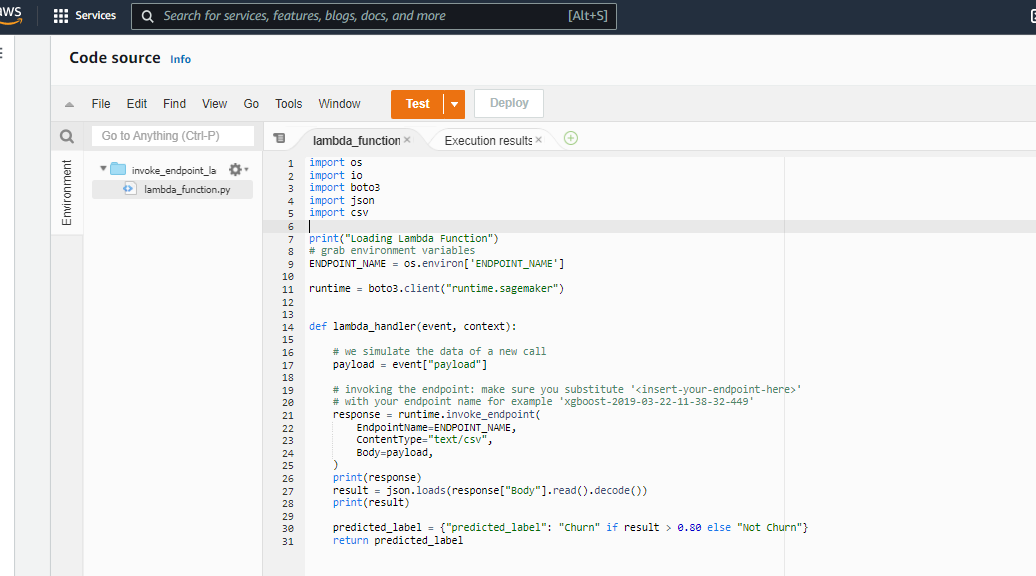
You can copy the Lambda Function from here
import os
import io
import boto3
import json
import csv
print("Loading Lambda Function")
# grab environment variables
ENDPOINT_NAME = os.environ['ENDPOINT_NAME']
runtime = boto3.client("runtime.sagemaker")
def lambda_handler(event, context):
# we simulate the data of a new call
payload = event["payload"]
# invoking the endpoint: make sure you substitute ''
# with your endpoint name for example 'xgboost-2019-03-22-11-38-32-449'
response = runtime.invoke_endpoint(
EndpointName=ENDPOINT_NAME,
ContentType="text/csv",
Body=payload,
)
print(response)
result = json.loads(response["Body"].read().decode())
print(result)
predicted_label = {"predicted_label": "Churn" if result > 0.80 else "Not Churn"}
return predicted_labelENDPOINT_NAME is an environment variable that stores the name of the AWS SageMaker model endpoint, Add the new ENDPOINT_NAME variable on the “Edit environment variables” screen as shown below. Add value as the same name as the endpoint created by Customer Churn Model deployed in the above notebook.
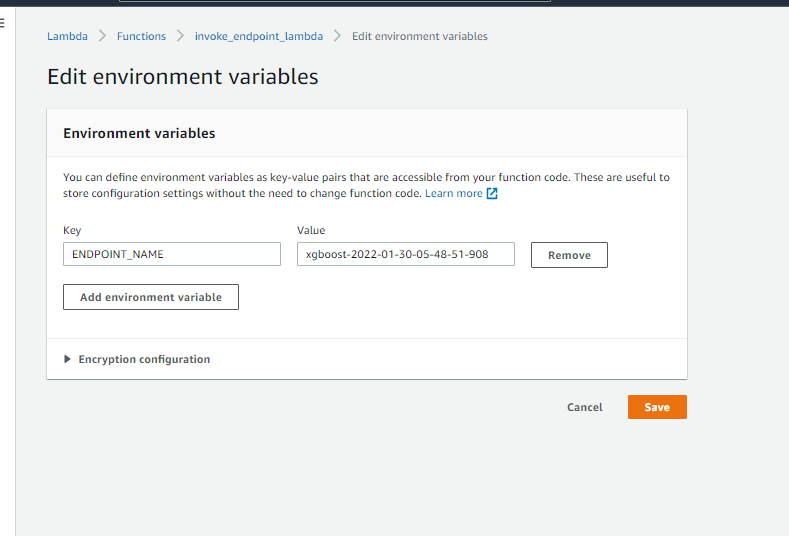
Test the Lambda Function
Pass the below data to test the Lambda Function. The data format can be checked from the validation dataset which is saved in the S3 bucket as mentioned in the Notebook.
I downloaded the validation dataset, selected one record from the file, and saved it as CSV. Then opened the CSV with a notepad, removed the first column as it was the Target column. Copy this format and pasted in the Lambda function test section as shown below. For this function, the test data format is shown below.
This may vary from model to model. Basically, the test data format will be the same as the train data format which is used to train the model. The data parsing can be done in the lambda function also.
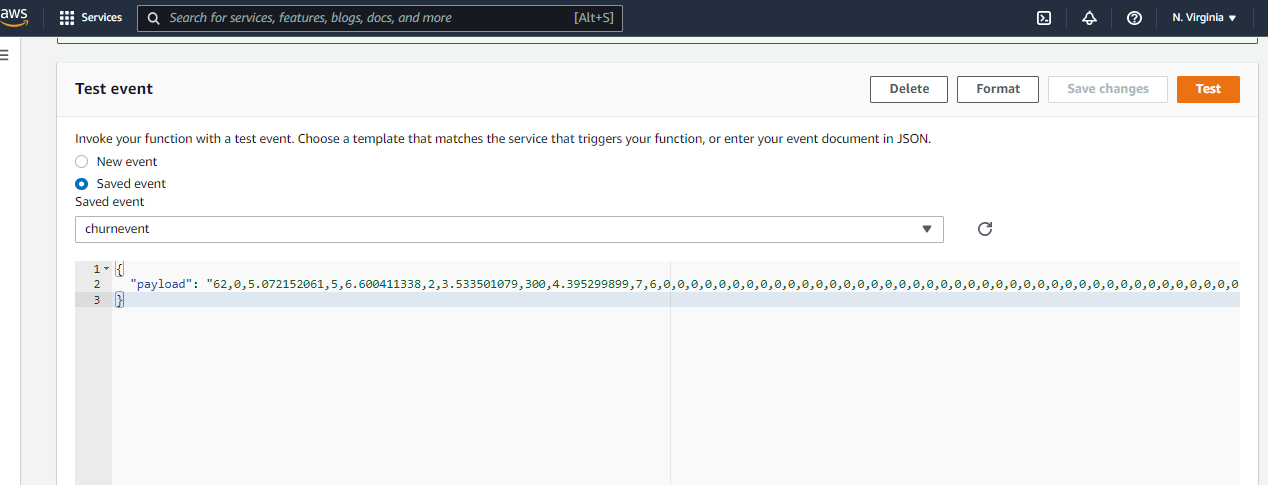
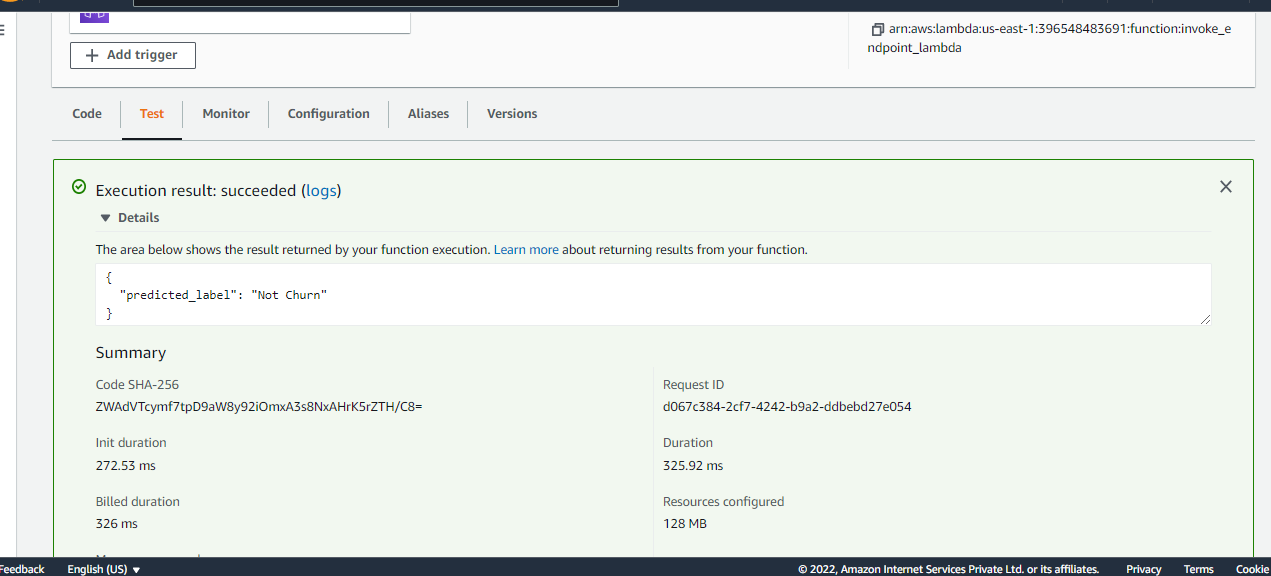
The result is showing a pass and returns the predicted value as “Not Churn” as returned by the endpoint. We can test with other records from the validation data set and will expect the predicted values as returned by the model endpoint.
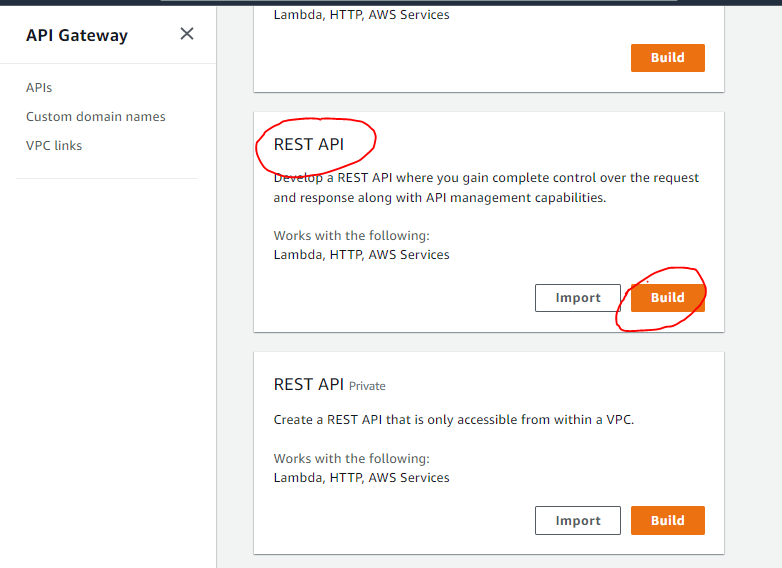
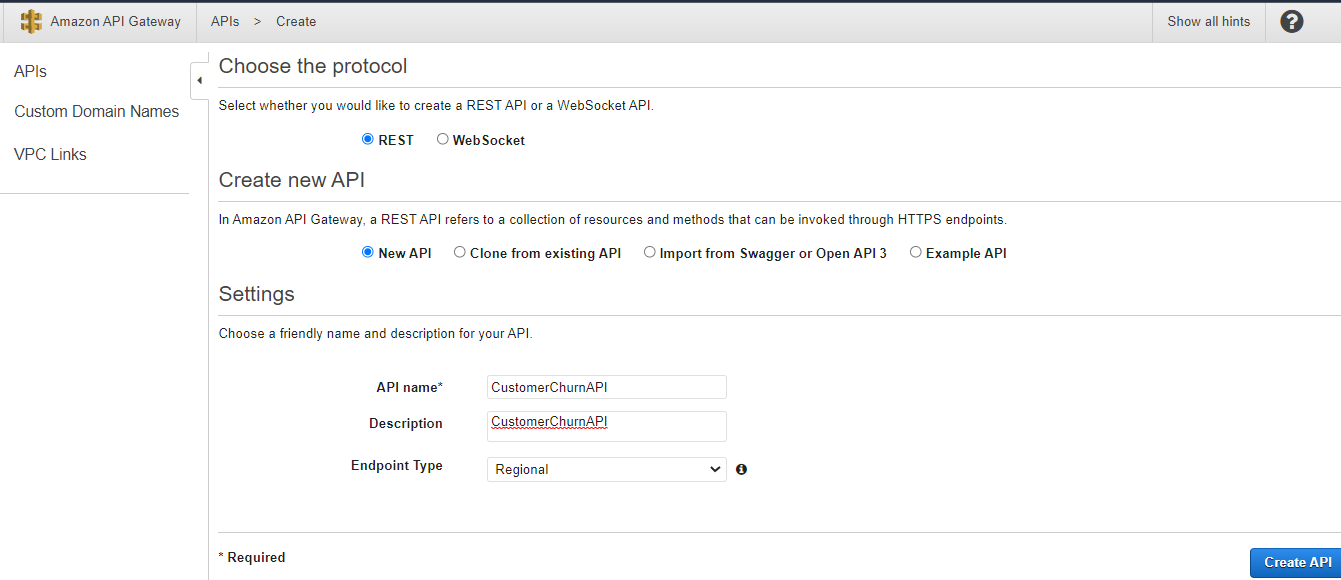
Create API steps:

1. On the API Gateway console, choose the REST API
2. Choose Build.
3. Select New API.
4. For API name¸ enter a name.
5. Leave Endpoint Type as Regional.
6. Choose Create API.
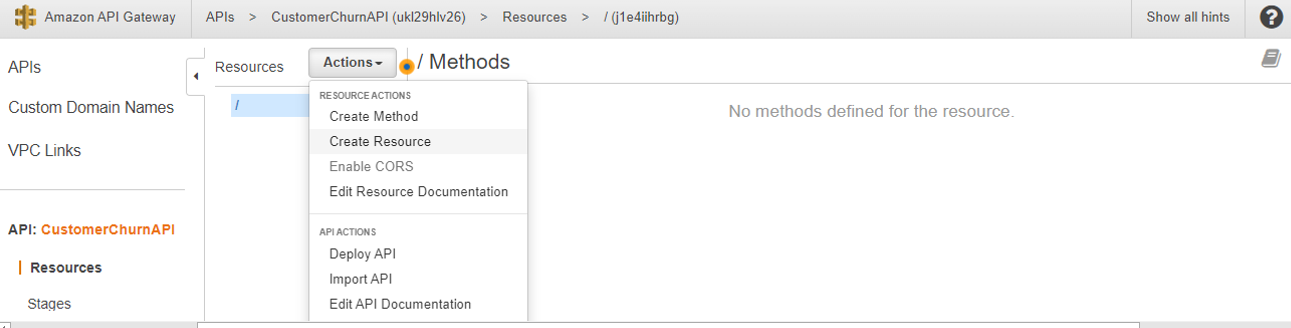
7. On the Actions menu, select Create a resource.
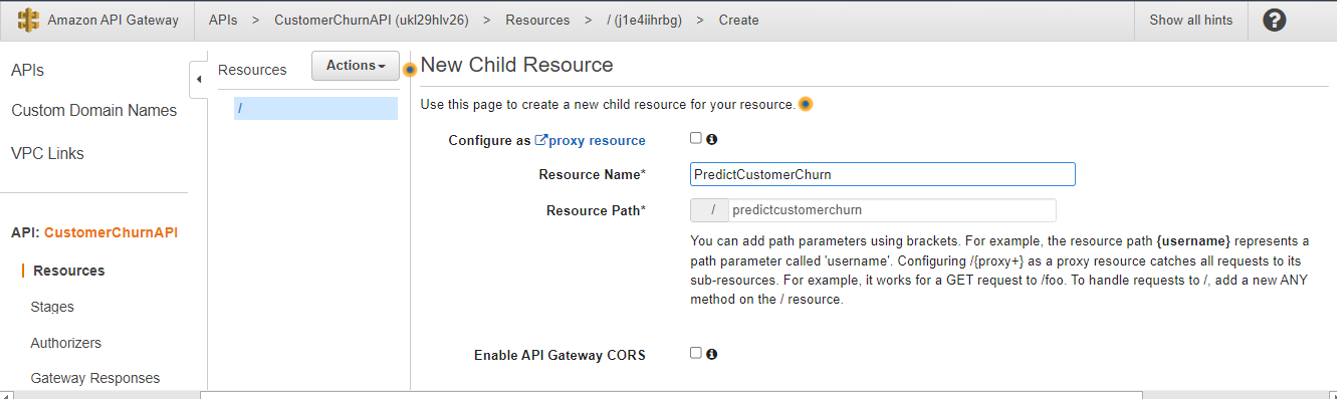
8. Enter a name for the resource -(eg PredictCustomerChurn)
9. After the resource is created, on the Actions menu, select Create Method to create a POST method.
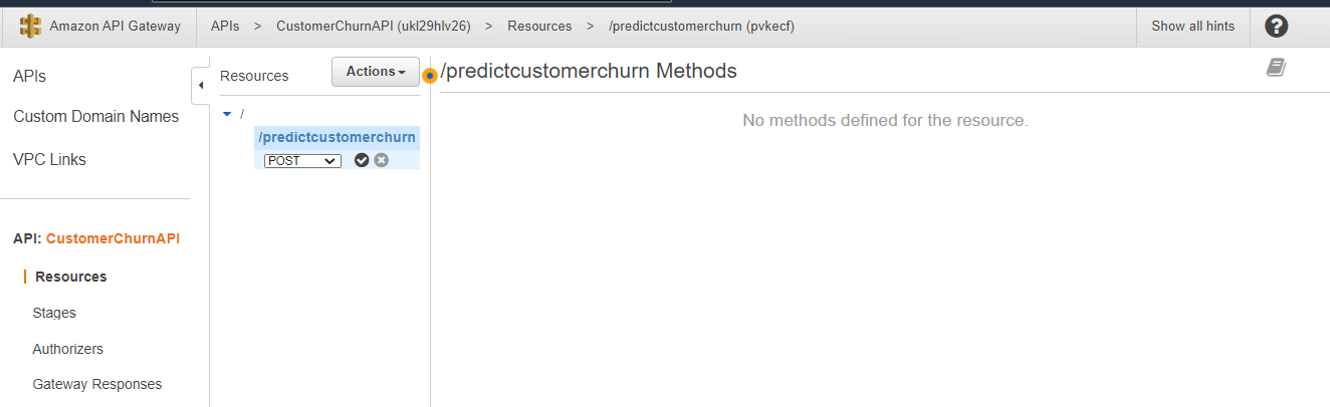
10. For Integration type, select Lambda Function.
11. For Lambda function, enter the function created above.
12. Add permission to Lambda function – select OK
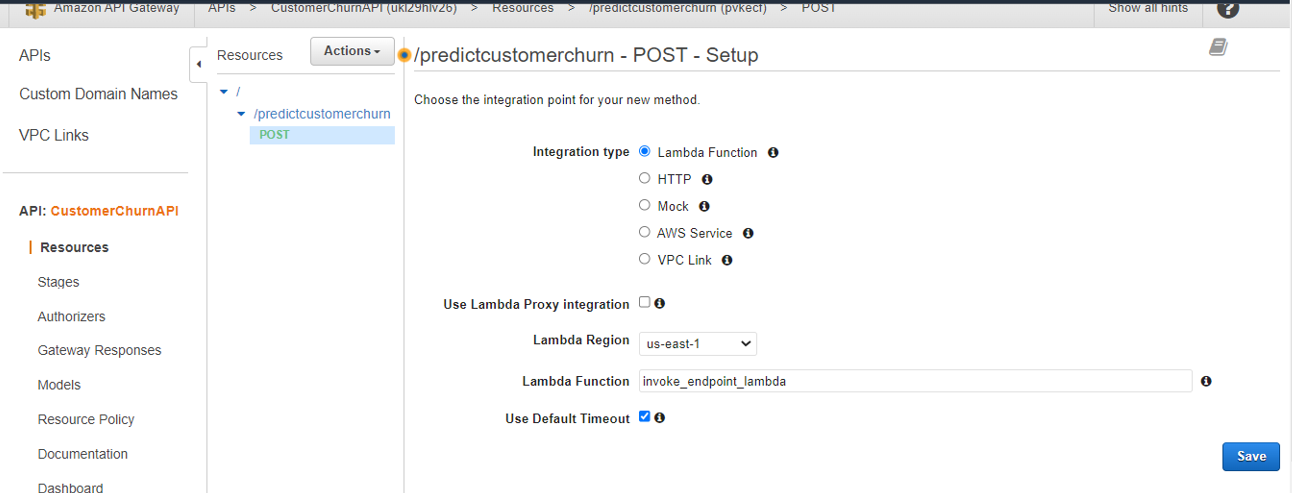
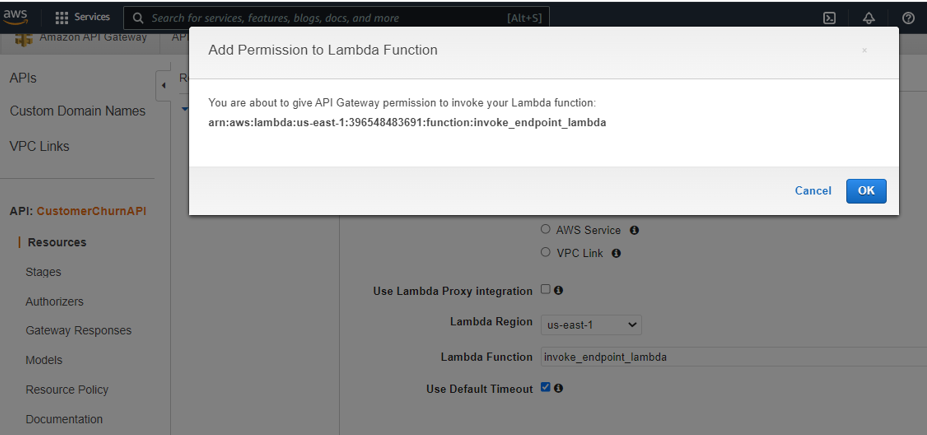
When the setup is complete, deploy the API to a stage.
13. On the Actions menu, Select Deploy API.
14. Create a new stage.
15. Select Deploy.
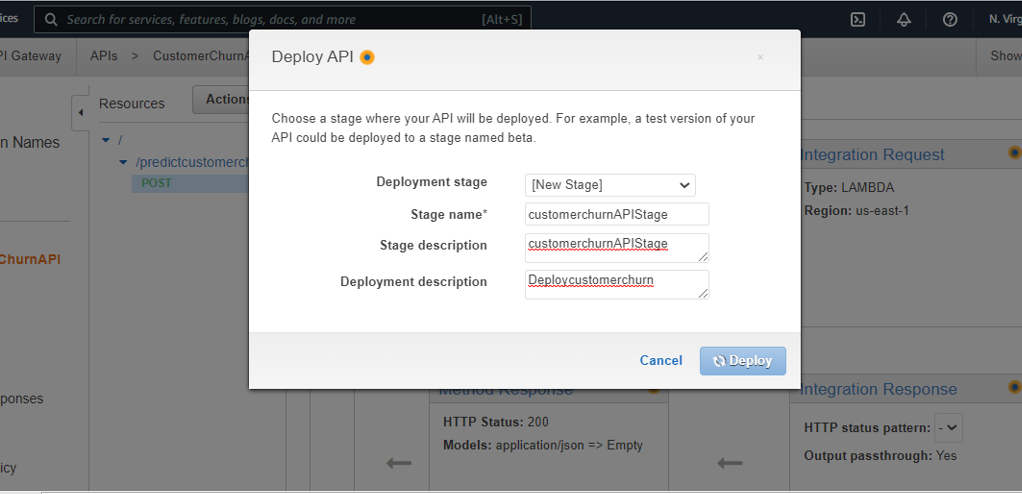
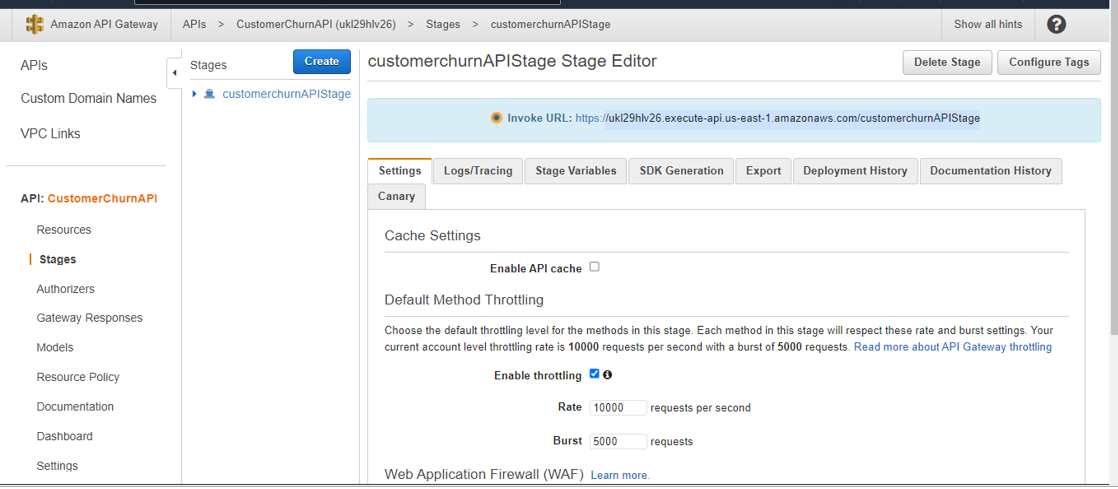
Select the correct Invoke API URL carefully. The below invoke URL is correct as it contains both staging (eg-customerchurnAPIStage) and resource name (eg –predictcustomerchurn)
This URL is available on the Staging editor, click on the staging name link on the left pane (eg-customerChurnAPIStage), expand the staging name, expand the list to the resource, and then method – POST. Click on POST and then the Invoke URL will be visible on the right panel with the correct URL.
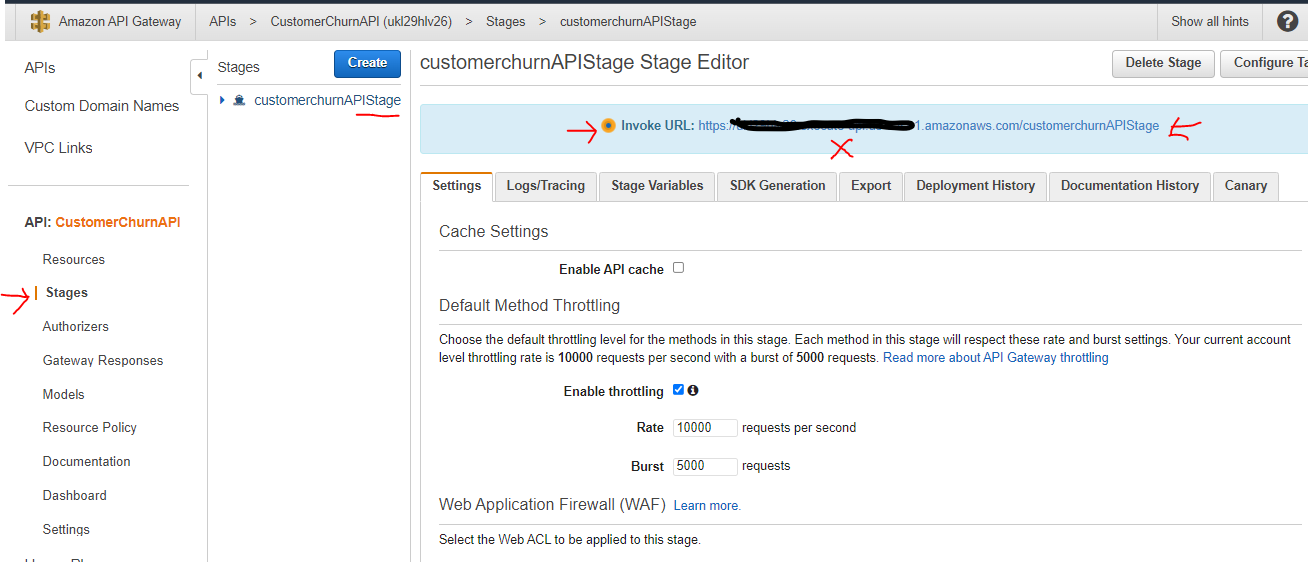
Please note: The below invoke URL is incorrect – this is shown when the API is deployed and control goes to the staging editor. If we click on the staging name link on the left pane (eg-customerChurnAPIStage), the Invoke URL shown on the right-hand side area does not include the resource name. Do not use this to copy invoke API URL.
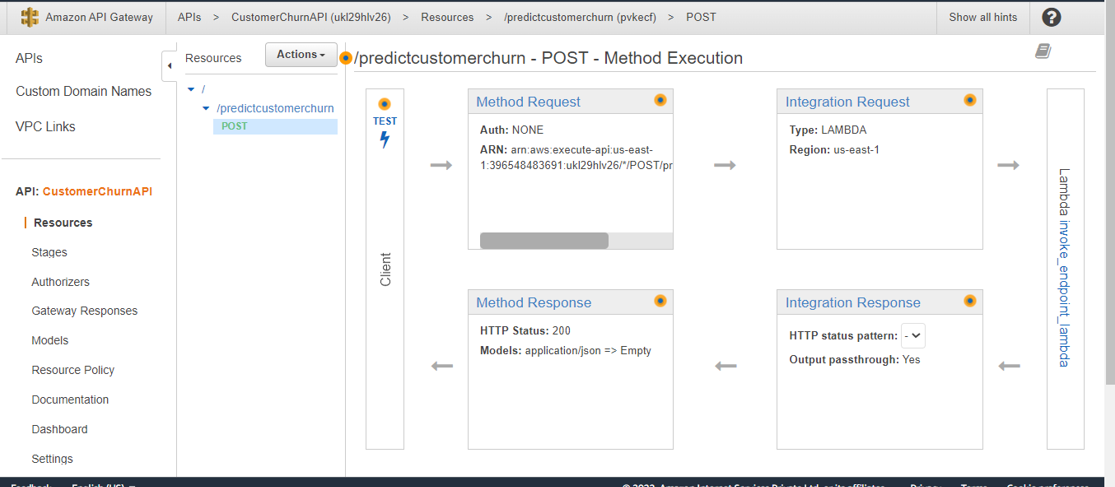
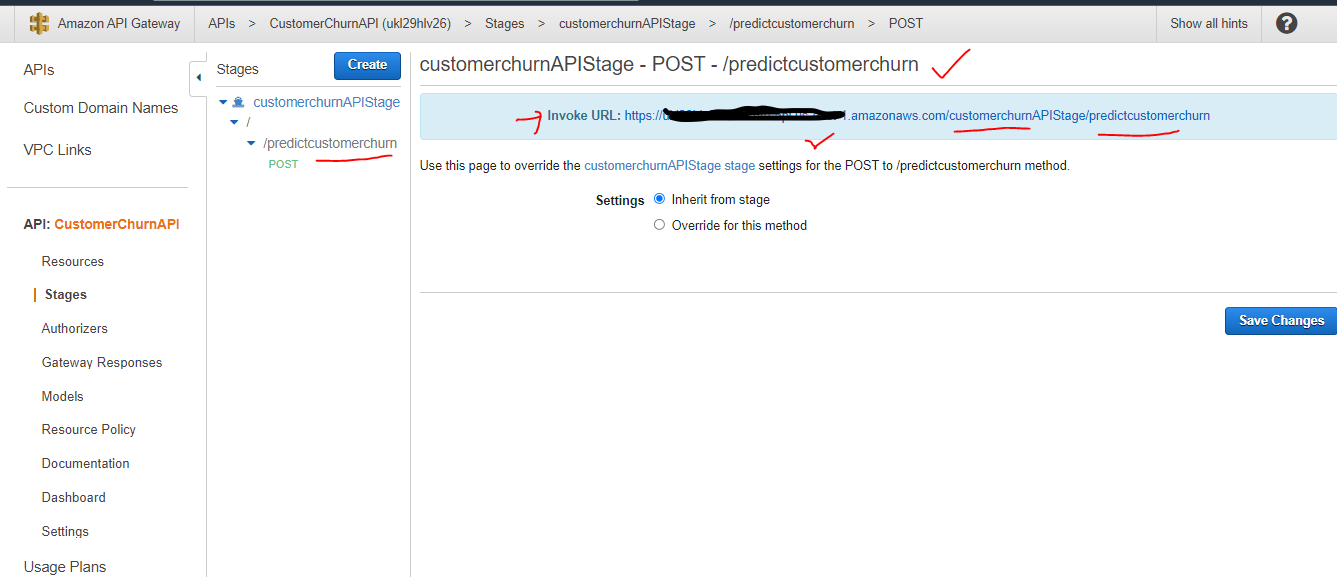
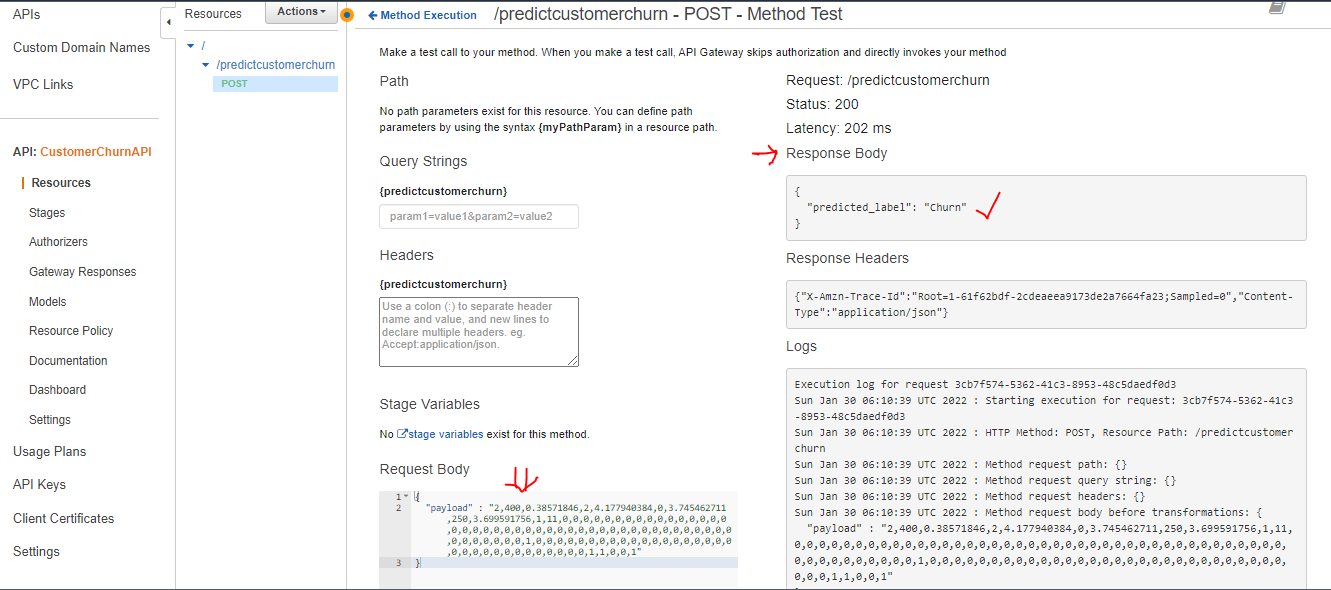
Execute the test with the API Post method from the Method Execution Screen. Click on the TEST which will open the POST-method Test screen.
Pass the test data in the request body and click on test. The response will be displayed on the right-hand side panel. The Response Body will display the response value – eg “Churn” here.
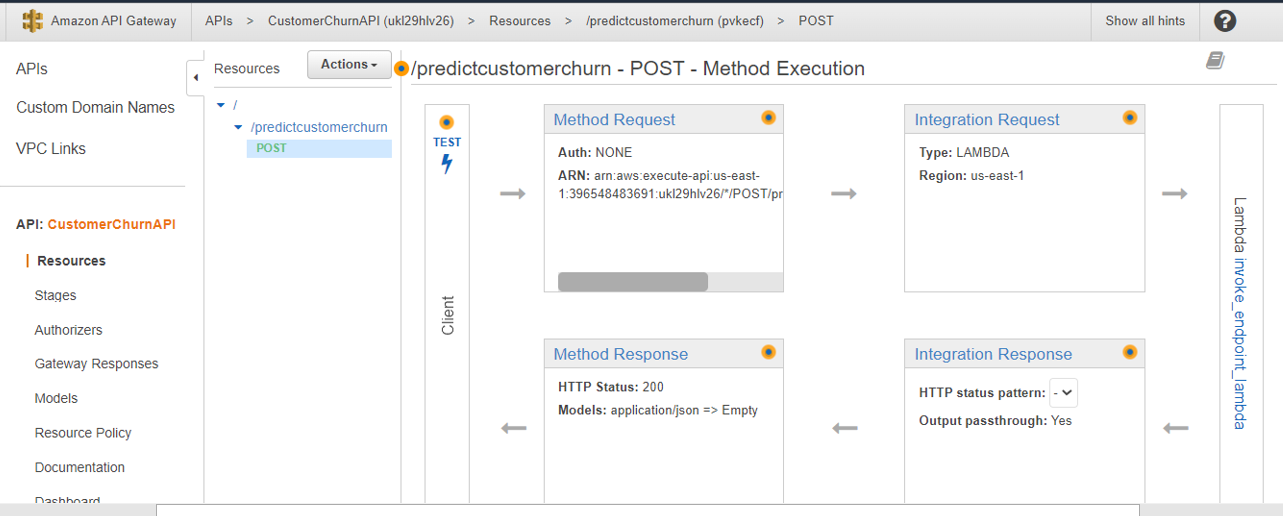
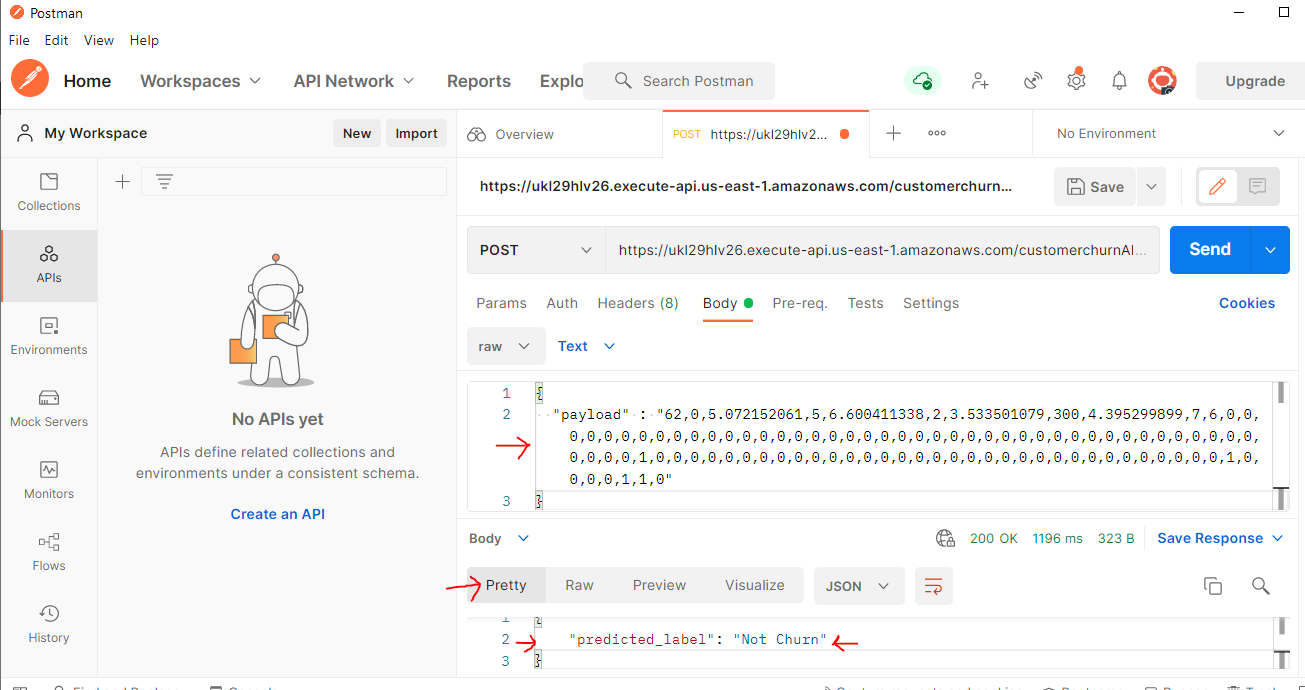
As Lambda and API are now tested, let’s test the endpoint from outside the AWS cloud – I have selected the Postman application which is running on my laptop.
Here is the Postman setting, I passed the AWS API invoke URL on the right-hand side panel -> POST tab.
Then paste the same test data in the same JSON format with the “payload” variable in the Test “Body”. then click “Send”.
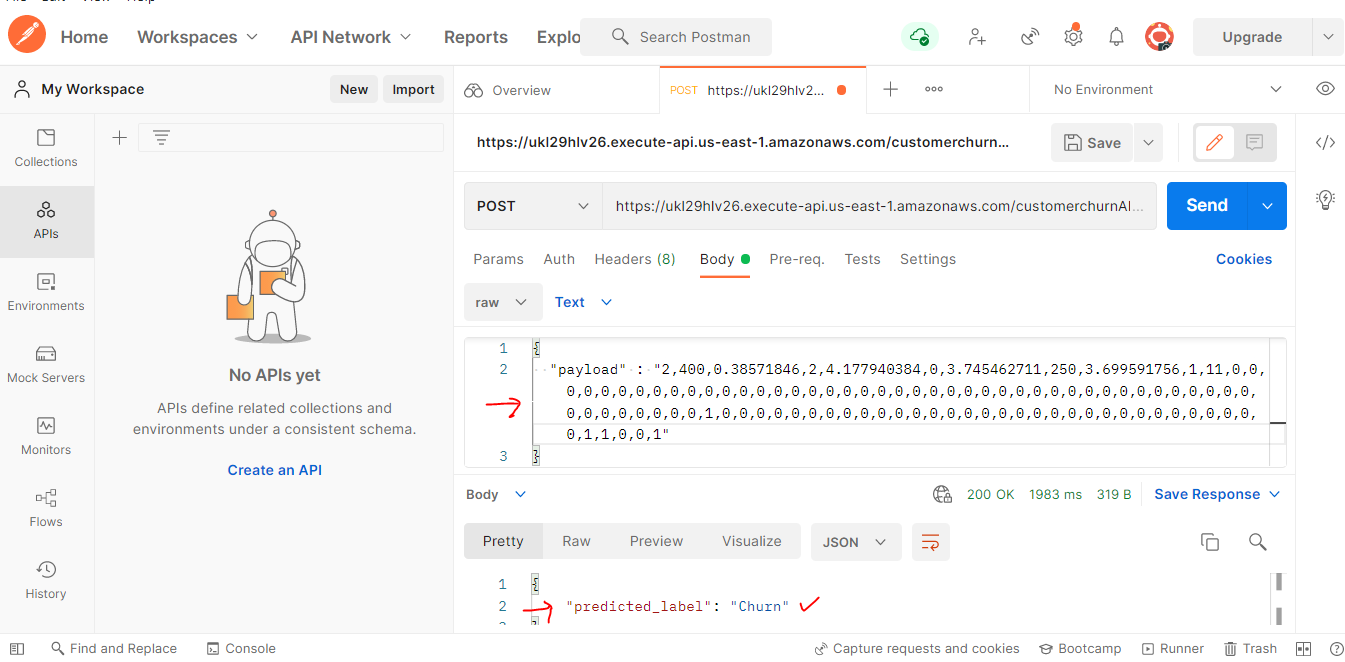
The response will be received from AWS Sage maker model endpoint via AWS API and is shown on the bottom of the Postman screen in the response section.
Two test examples are shown here – one with Response =”Churn” and another one with “Not Churn”.

Any data science project starts with an iterative process of Data engineering, model development, model optimization, model evaluation, and finally the best fit model is delivered.
Then we face the major challenge to integrate the ML model with the existing IT and business system. A successful AI adoption needs a seamless integration between ML workflow and the consumer application. AWS API Gateway along with Sagemaker endpoint and Lambda offers a managed integration service that enables us to build end-to-end production-ready ML systems.
This step-by-step guide can help to build the basic integration architecture and then we can build other infracting components.
A. Amazon aws Sage Maker is a fully managed machine learning service provided by Amazon Web Services (AWS). It is used for building, training, and deploying machine learning models at scale. SageMaker simplifies the entire machine learning workflow, offering tools for data labeling, model training, automatic model tuning, and deployment in a scalable and cost-effective manner.
A. SageMaker is useful for several reasons:
1. Simplified Workflow: AWS Sage maker provides a streamlined workflow, from data preparation to model deployment, making it easier to build and manage machine learning models.
2. Scalability: It allows scaling machine learning workloads, handling large datasets and high inference loads, enabling efficient utilization of resources.
3. Managed Service: SageMaker is a fully managed service, handling infrastructure provisioning, maintenance, and updates, freeing users to focus on model development.
4. Cost-Effectiveness: It offers cost optimization features like automatic model tuning and the ability to provision resources on-demand, reducing unnecessary expenses.
5. Integration and Compatibility: It seamlessly integrates with other AWS services, facilitating data storage, retrieval, and processing, while also supporting popular machine learning frameworks like TensorFlow, PyTorch, and scikit-learn.
6. Collaboration and Deployment: SageMaker allows teams to collaborate on model development, provides easy deployment options, and supports model monitoring and management for production-grade deployments.
A. The main objectives of using AI/ML in businesses are to solve real-world problems, enrich customer experiences, enhance decision-making, improve operational efficiency, and drive innovation.
A. Serverless architecture in AI/ML deployment offers benefits such as scalability, cost savings, simplicity, faster time to market, and ease of integration.
A. AWS Sagemaker simplifies the end-to-end machine learning workflow by providing managed infrastructure, scalability, built-in algorithms, and simplified model deployment into production environments.
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.
Lorem ipsum dolor sit amet, consectetur adipiscing elit,








Hi, thanks a lot for the article!!! Will like to know if its possible to implement a tabular binary classification created with sagemaker outside of AWS? Is so, is it possible for you to tell me what to look for or if you have some repos that I can look for will be more than gratefull Thanks a lot