This article was published as a part of the Data Science Blogathon.
Introduction
Learn how to control your files and large dataset with a few lines of scripts. FastDS combines the power of Git and DVC to provide a hassle-free versioning experience.
Companies are always on the lookout for tools that can improve the productivity of their employees, as 92% of employees say productive tools that help them perform tasks efficiently improve work satisfaction. FastDS is for beginners, data science enthusiasts, and employers looking for a tool to improve the Git and data versioning experience.
In this blog, we will understand everything about FastDS. We will also use it to version file, dataset, and Urdu Automatic Speech Recognition model and push the project files to DagsHub remote.
What is FastDS?
FastDS (fds) is an open-source tool for all data professionals to version control code and datasets. fds at a high level uses Git and DVC to clone repositories, add changes, commit, and push. You can also use fds save for automating committing and pushing tasks.

FastDS provides shortcuts for Git, and DVC commands to minimise the chances of human error, automate repetitive tasks, and provide a beginner-friendly environment.
Key Features of FastDS
When I started using Git with DVC, I was making many mistakes in running commands. It took me a while to understand the mutual relation, and still, I make the same mistakes, which can cause delays during the project. The fds solve all that by automating repetitive tasks. In this section, we will learn about the various features of fds and how they can help us clone, monitor, and save project files.
-
Init: Initialize both Git and DVC repositories.
-
Status: Get the status of the Git and DVC repository.
-
Add: Add files/folders to Git and DVC repository.
-
Commit Commits changes to Git and DVC repository.
-
Clone: Clones from Git repository and pulls data from DVC remote.
-
Push: Push commits to Git and DVC remote.
-
Save: Add all the changes in the project, commit with a message, and push the changes to Git and DVC remote.
Urdu Automatic Speech Recognition
In this project, we will fine-tune a version of Facebook/wav2vec2-Xls-r-300m on the Urdu subset of the common_voice dataset under the CC-0 license. The wav2vec 2.0 model architecture has allowed data scientists to build a state-of-the-art speech-to-text application in more than 80 languages. Like Siri or Google, you can create your speech recognition in your native language.

I have followed XLSR-Wav2Vec2 for the low-resource ASR guide to fine-tune the model and used Wav2Vec2 with n-grams to boost the model performance. Combining a fine-tuned model checkpoint with a language model using Kenlm can improve the word error rate (WER) by 10 to 15 points.
In this project, we will learn:
-
To create a repository on DagsHub.
-
Clone the repository using fds.
-
Run the training script.
-
Monitor the results.
-
Add the Data and Model folder to DVC.
-
Add a language model.
-
Use one line to save and push changes to the DagsHub remote.
Setting up FastDS
First, we need to create a repository on DagsHub and add the required details. Your storage consists of Git, DVC, and MLflow remote links, and you can use them to upload files, datasets, and machine learning experiments.
.png)
Then, on your local machine, you can run the script below to clone the repository or if you are working on Colab, use `!` at the start of each script. The fds usually pull both Git and DVC files, but currently, we have an empty repository.
pip install fastds fds clone https://dagshub.com/kingabzpro/Urdu-ASR-SOTA.git cd Urdu-ASR-SOTA |
Note: It is recommended to add a dvc username and password early. You can click on “?” on DVC remote to see DVC credentials.
.png)
dvc remote modify origin --local auth basic dvc remote modify origin --local user dvc remote modify origin --local password
Before running the training notebook, we need to move the dataset and required file to the local directory and then install all the packages required to fine-tune the model. You can check the list here.
Training FastDS
We won’t go deep into the training process. Instead, we will focus on generating model files and adding them to Git and DVC using fds. If you are interested in learning about the fine-tuning process, read XLSR-Wav2Vec2 for a low-resource ASR guide.
We will pull local audio data using the Hugging Face dataset library and use a transformer to download and finetune facebook/wav2vec2-xls-r-300m. We will also integrate DagHub logger and MLflow to track all the experiments.
Committing
After running the notebook and saving model checkpoints in a Model folder, we will use `fds add .` This will trigger an automatic response asking you to add large files/folders into DVC. After that, it will add those folders to .gitignore to avoid Git conflict.
.png)
You can now commit both Git and DVC and push the files to DagsHub remote storage by running the script below.
fds commit "first try" fds push |
Results
I ran multiple experiments; some failed, some inconclusive, and some gave optimal results. You can access all the experiments under the Experiment tab. In the end, I was able to produce the best results by training the model for 200 epochs on four V100S GPUs (OVH cloud). The model is significant, and it is impossible to run it on Google Colab.
Usually, on Google Colab, training a model on 30 epochs can take up to 14-27 hours, depending on the available GPU.
.png)
If you want to evaluate the results, run the below script in the base directory. It will generate both WER and CER with target and predicted TXT files.
python3 eval.py --model_id Model --dataset Data --config ur --split test --chunk_length_s 5.0 --stride_length_s 1.0 --log_outputs |
Language Model
To boost model performance, I have added a language model. If you are interested in learning about n-grams and want to add a language model to your ASR model, check out this tutorial: Boosting Wav2Vec2 with n-grams in Transformers.
.png)
Let’s save all the changes and push them to the remote by running the `fds save` script.
fds save "language model added"
We can rerun a model evaluation script to monitor the improvement. Combining the n-gram language model with Wav2Vec2 has improved WER 56 to 46.
sh run_eval.sh
The evaluation results with prediction are available in the Eval Results folder. The Eval Results folder has subfolders “With LM” and “Without LM”.
Quick Start
The project is open to the public under an open-source license, and if you are starting from zero, follow the steps mentioned in the code block to get started.
.png)
After that, you can run a prediction by running the Python script.
from datasets import load_dataset, Audio
from transformers import pipeline
model = "Model"
data = load_dataset("Data", "ur", split="test", delimiter="t")
def path_adjust(batch):
batch["path"] = "Data/ur/clips/" + str(batch["path"])
return batch
data = data.map(path_adjust)
sample_iter = iter(data.cast_column("path", Audio(sampling_rate=16_000)))
sample = next(sample_iter)
asr = pipeline("automatic-speech-recognition", model=model)
prediction = asr(
sample["path"]["array"], chunk_length_s=5, stride_length_s=1)
prediction
# => {'text': 'اب یہ ونگین لمحاتانکھار دلمیں میںفوث کریلیا اجائ'}
|
Conclusion
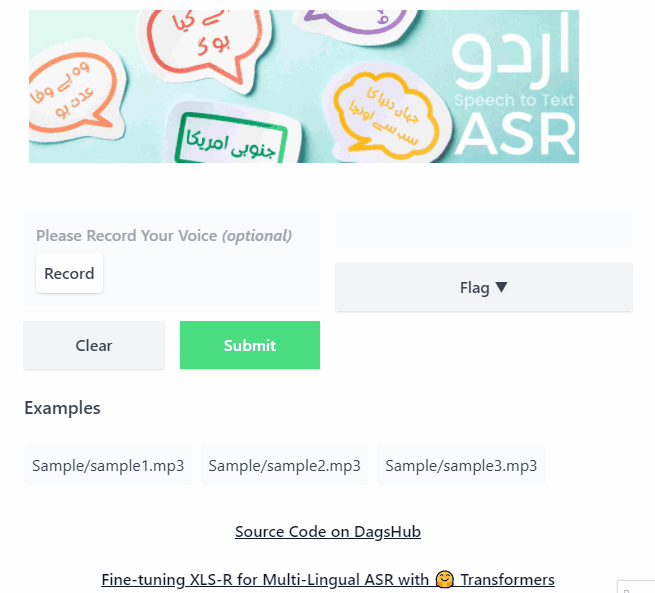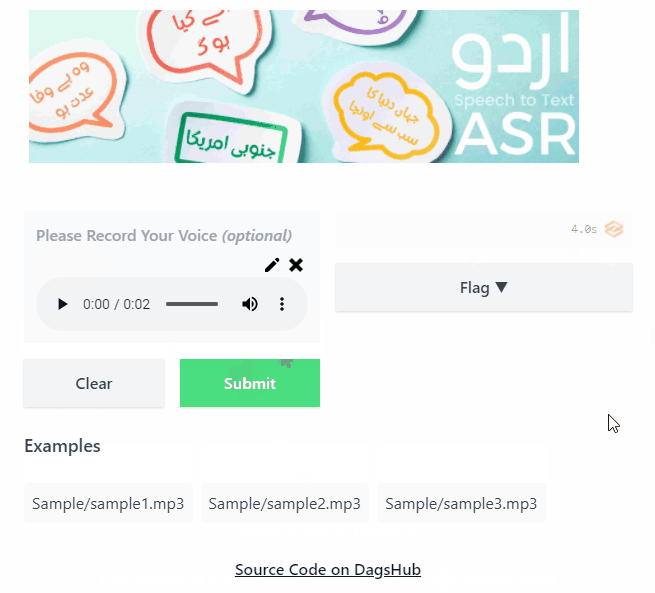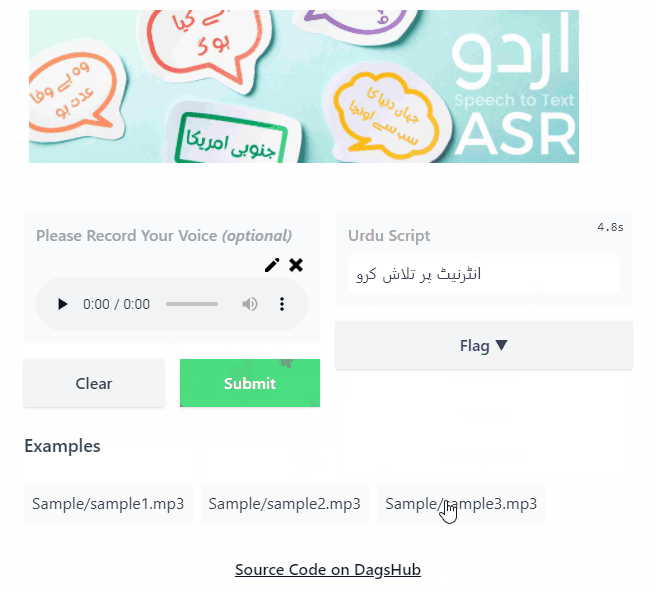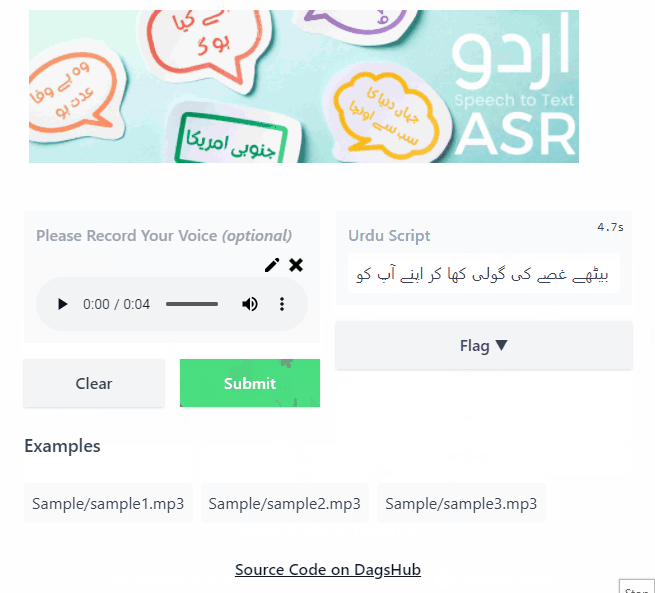
In this blog, we have learned about fds and how they can be used in a machine learning project. We have covered all the critical features with examples. The Urdu ASR project is open to contribution, and if you see a mistake in the code or have suggestions about the project, please create an issue. I made a Gradio demo and deployed it on Hugging Face spaces: Urdu-ASR-SOTA Gradio App.
Read more articles on FastDS here.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I am a technology manager turned data scientist who loves building machine learning models and research on various AI technologies. My vision is to build an AI product that will help identify students who are struggling with mental illness.






