This article was published as a part of the Data Science Blogathon.
Introduction
In this blog, let’s explore how to train a state-of-the-art text classifier by using the models and data from the famous HuggingFace Transformers library. We will see how to load the dataset, perform data processing, i.e. tokenisation and then use the processed input ids to fine-tune the pre-trained language models available in the HuggingFace Hub. Let’s use the TensorFlow and HuggingFace library to train the text classifier model.
Classification is one of the most important tasks in Supervised Machine Learning, and this algorithm is being used in multiple domains for different use cases. Now let’s discuss one such use case, i.e. Text classification or Sentiment Detection.
Text classification is one of the most common and fundamental tasks in natural language processing. In this task, we will train the machine learning model to classify given text into different categories or sentiments in the case of sentiment detection. Text classification has a broad range of applications, such as
- Sentiment analysis, i.e. determining the sentiment of tweets, or reviews
- Spam detector, i.e. identifying whether the message or mail is spam. Gmail uses an internal spam detector to categorise incoming emails as spam or not.
- Toxicity prediction, i.e. prediction of the amount of toxicity or how toxic or abusive any text is etc
We have seen above some examples and use cases of text classification. Now let’s see how to train a sentiment analyser model as a use case of text classification.

About the Dataset
We will be using the tweet_eval dataset from the hugging face hub. We will load the dataset using the datasets library. This dataset consists of seven heterogeneous tasks in Twitter, all framed as multi-class tweet classification. These tasks include – irony, hate, offensive, stance, emoji, emotion, and sentiment. We will be using the emotion task of the dataset. We have to classify each of the texts into the following classes: anger, joy, optimism and sadness.
Before we proceed, let’s install some libraries that we would need.
Using HuggingFace Datasets
Let’s get started by installing the transformers and the datasets libraries,
!pip install transformers[sentencepiece] -q !pip install datasets -q
Now let's download the dataset from the hub using the datasets library.
from datasets import load_dataset
dataset = load_dataset("tweet_eval", "emotion")
The above code will download the dataset named “tweet_eval” with the task/sub-category “emotion”. We can print and check the dataset,
# Print and check some details about the dataset print(dataset)
Our dataset is the type of DatasetDict and has the train, validation and test split defined. We can directly access the training set of the dataset as follows,
# Select the training set from the dataset train_ds = dataset['train'] print(train_ds)
When we print the training dataset, we can observe that it has two features, i.e. text and label. It also has information about the total number of samples in the dataset. We can find more details about the features by,
# More details about the features print(train_ds.features)
Here we can see that the text feature is of the type String and the label feature is ClassLabel. The ClassLabel type shows the total number of classes and their names, i.e. 4 in our example.
We can easily explore the dataset if it is Pandas Dataframe type. This can be done as follows,
# Convert the dataset to pandas dataframe
import pandas as pd
##########################################################
dataset.set_format("pandas")
train_df = pd.DataFrame(dataset["train"][:])
Now we can easily do basic checks like finding null values and the frequency of labels. Now let's check for null values in the data frame,
# Check for null values train_df.isnull().sum()
Well, we don't have null values. Before we find the frequency of the labels, let's convert the integers to corresponding label names in the dataframe.
# Function to convert integer to string
def label_int2str(x):
return dataset["train"].features["label"].int2str(x)
# Add a label name train_df['label_name'] = train_df["label"].apply(label_int2str)
Now let's check the distribution of the labels,
# Let's check the distribution of different labels import matplotlib.pyplot as plt
train_df["label_name"].value_counts(ascending=True).plot.barh()
plt.title("Frequency of Labels")
plt.show()
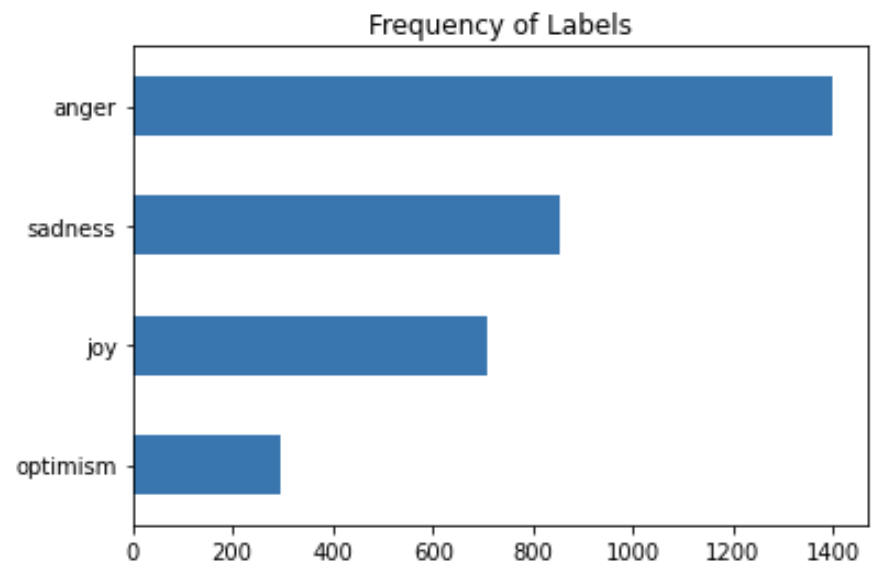
From the above graph, we can see that our dataset is heavily imbalanced. We can further do processing and data analysis from the data frame, but let’s convert it back to the Dataset type suitable for HuggingFace tokenisers and models.
# reset the format dataset.reset_format()
Now let’s further continue with tokenisation.
Tokenisation
Tokenisation is the most essential preprocessing step in natural language processing. It is converting unstructured text data into a numerical array based on the mapping present in the text vocabulary. Tokenisation is done as follows:
- Find a list of all unique words in the dataset
- Associate each word/token with a unique number. This is called vocab.
- Encode the dataset using the mapping present in the vocab.
There are different ways to perform tokenisation. Some of the prominent ones are:
- Word-based tokeniser
- Character-based tokeniser
- Sub-word based tokeniser
HuggingFace uses the sub-word based tokeniser to tokenise the datasets by default. Let’s see how to tokenise our dataset using HuggingFace’s AutoTokenizer class.
The most important thing to remember while using HuggingFace Library is:
Always use the tokenizer and model belonging to the same model checkpoint while fine-tuning models for custom tasks. This will ensure that both model and tokenizer have the same knowledge about the tokens and their encodings.
We are using the Distill-Bert model to fine-tune the tweets_eval dataset. More information about the model can be found in the model card here. We can access the tokeniser and model weights by using the HuggingFace library just by specifying the model name.
Now let’s download and import the tokeniser using the AutoTokenizer module,
from transformers import AutoTokenizer model_ckpt = "distilbert-base-uncased" tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name_or_path=model_ckpt)
HuggingFace will automatically download and cache the tokeniser locally. Now let's see how the tokeniser works with an example,
text = "This is an example of tokenization"
output = tokenizer(text)
tokens = tokenizer.convert_ids_to_tokens(output['input_ids'])
print(f"Tokenized output: {output}")
print(f"Tokenized tokens: {tokens}")
print(f"Tokenized text: {tokenizer.convert_tokens_to_string(tokens)}")
Let’s check some important information about the tokeniser like voacb_size, model_max_length etc.,
print(f"Vocab size is : {tokenizer.vocab_size}")
print(f"Model max length is : {tokenizer.model_max_length}")
print(f"Model input names are: {tokenizer.model_input_names}")
Model max length defines the maximum number of tokens that a single data sample can have, i.e. in the above case, our model DistilBert can accept text sequences of up to 512 tokens long. Model input names are the fields that the model will take as inputs for training and inference purposes.
Since we have seen how the tokeniser works, let’s now tokenise the entire dataset.
# Tokenization function
def tokenize(batch):
return tokenizer(batch["text"], padding=True, truncation=True)
# Tokenize entire dataset
tokenized_dataset = dataset.map(tokenize, batched=True, batch_size=None)
Great! We can print the dataset and check that extra fields, i.e. input_ids and attention_mask have been added. Now we are ready for the final step, i.e. training the text classifier.
Training the Text Classifier
Let’s start by importing the TFAutoModelForSequenceClassification method from the transformers library. This will automatically download and cache the model provided with the checkpoint name. Since we have defined the checkpoint while downloading the tokeniser, we should also use the same to download the model.
from transformers import TFAutoModelForSequenceClassification
num_labels = 4
model = TFAutoModelForSequenceClassification.from_pretrained(model_ckpt,
num_labels=num_labels)
We have installed the pre-trained DistilBert Model along with the newly attached model head; thus, this model can now be trained for classification tasks with 4 output labels. Now let’s prepare our data to train it with our model using the Tensorflow deep learning framework.
Before we feed the processed token ids into the model, we need to ensure that the dataset is provided as batches and that each data set has an equal length. To do this, HuggingFace gives us a DataCollator method that automatically performs padding to every sample in a batch. The size of every input data sample is equal to the length of the sample with maximum length.
batch_size=64 from transformers import DataCollatorWithPadding data_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="tf")
Now let’s create the TensorFlow datasets from the tokenised dataset,
# Create tf datasets
tf_train_dataset = tokenized_dataset["train"].to_tf_dataset(
columns=column_names,
label_cols=["label"],
shuffle=True,
batch_size=batch_size,
collate_fn=data_collator
)
tf_valid_dataset = tokenized_dataset["validation"].to_tf_dataset(
columns=column_names,
label_cols=["label"],
shuffle=False,
batch_size=batch_size,
collate_fn=data_collator
)
We are ready to proceed with model training. Before that, let’s do the necessary imports,
# Imports import tensorflow as tf from tensorflow.keras import optimizers from tensorflow.keras import metrics from tensorflow.keras import losses
Compile the model with Adam optimiser, SparseCategoricalCrossEntropy loss function and SparseCategoricalAccuracy as the metric.
# Compile the model
model.compile(
optimizer=optimizers.Adam(learning_rate=5e-5),
loss=losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=metrics.SparseCategoricalAccuracy()
)
Now finally, let’s fit the model for 5 epochs,
# Fit the model
model.fit(tf_train_dataset,
validation_data=tf_valid_dataset,
epochs=5)
Great! Now we have trained our model for 5 epochs. Now let’s test the model on some sentences.
outputs = model.predict(tokenizer("I feeling very happy")["input_ids"])
outputs['logits'][0].tolist()
We have fed the model a sentence in the above code, i.e. I am feeling thrilled. We can observe that this sentence belongs to the emotion of joy. Now let’s check the model prediction,
# Apply softmax and pick the label with maximum probability import numpy as np label_int = np.argmax(tf.keras.layers.Softmax()(outputs['logits'][0].tolist())) print(label_int.item())
Since the model outputs just the logits, we need to apply softmax activation to convert the values into probabilities. We use softmax and not sigmoid activation because softmax converts logits of multiple classes into the range 0 to 1, therefore suitable for multi-class classification. Now we got the index of maximum probability, and let’s check which type it corresponds to.
print(label_int2str(label_int.item()))
Great! Its joy. Our model quickly picked up the sentiment of the sentence. Now we can further improve this model by training for more epochs or preparing better validation sets etc. Then finally, deploy the model in production settings.
Conclusion on Text Classifier
In this blog post, we have seen how to train a state-of-the-art text classifier by fine-tuning the pre-trained models from HuggingFace Hub. Pre-trained models made publicly available as a part of HuggingFace Hub are a treasure to the machine learning community. As seen above, we can quickly load and train on our datasets instead of training from scratch, which forms the basis for Transfer Learning. Through the number of models and resources available, we can experiment and create new models that might someday revolutionise the world.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Hi,
I am Narasimha Karthik J, a Data Scientist at Boeing Research in Bengaluru. I have experience in fine-tuning language model models (LLMs) for various domain-specific applications and deploying them. Additionally, I am experienced in LLM training, fine-tuning, RAG, and working with the latest frameworks and technologies.
Thanks and Regards,
Narasimha Karthik J





Hey Narasimha, excellent content and timely for me, thanks! Just one small thing: column_names was not defined when I tried to follow it to Create tf datasets: tf_train_dataset = tokenized_dataset["train"].to_tf_dataset( columns=column_names, label_cols=["label"], shuffle=True, batch_size=batch_size, collate_fn=data_collator ) Would you please take a look? Have a great day, -Ju
Hey I tried to use one of following: column_names = ['text', 'label', 'input_ids', 'attention_mask'] column_names = ['text', 'label', 'input_ids'] But all got the same type of error: ValueError: `labels.shape` must equal `logits.shape` except for the last dimension. Received: labels.shape=(64,) and logits.shape=(1, 64) Woud you please take a look and let me know? Thanks! -Ju