This article was published as a part of the Data Science Blogathon.
on NLP Preprocessing
Hello friends, In this article, we will discuss text preprocessing techniques used in NLP. In any Machine learning task, cleaning or preprocessing the data is as important as model building. Text data is one of the most unstructured forms of available data and when comes to dealing with human language then it’s too complex. Have you ever wondered how Alexa, Siri, and Google assistants can understand, process, and respond to Human language. NLP is a technology that works behind it where before any response lots of text preprocessing takes place. This tutorial will study the main text preprocessing techniques that you must know to work with any text data.
Overview
What is Natural Language? and What is NLP(Natural language processing)?
Natural Language — Any language in which humans are making a conversation that language is the Natural language.
NLP — Natural language processing (NLP) is a field of artificial intelligence in which computers analyze, understand, and derive meaningful information from human language in a smart and useful way.
What is Text Analytics/ Text Mining?
Text Analytics is the process of deriving meaningful information from the natural language’s text. Text Analytics is Nothing but the preprocessing that is required before giving the data to the model.
Why do we need to do text preprocessing?
It helps to remove unhelpful parts of the data, or noise, by converting all characters to lowercase, removing stopwords, punctuation marks, and typos which available in the data. After doing data preprocessing accuracy of the model get increases.
Text Preprocessing Techniques
Lowercasing
As we know python is case sensitive language. if Ram and ram words are present in our data. then these two words process separately that’s why we convert all data in lower case.
df['text'].str.lower()
df['text'].apply(lambda x:x.lower())
2. Remove HTML Tags
HTML tags are not important in model building. We have to remove HTML tags.
For removing HTML tags we use regex.
import re
def remove_html_tags(text):
pattern = re.compile('')
return pattern.sub(r'', text)
df['text'].apply(remove_html_tags)
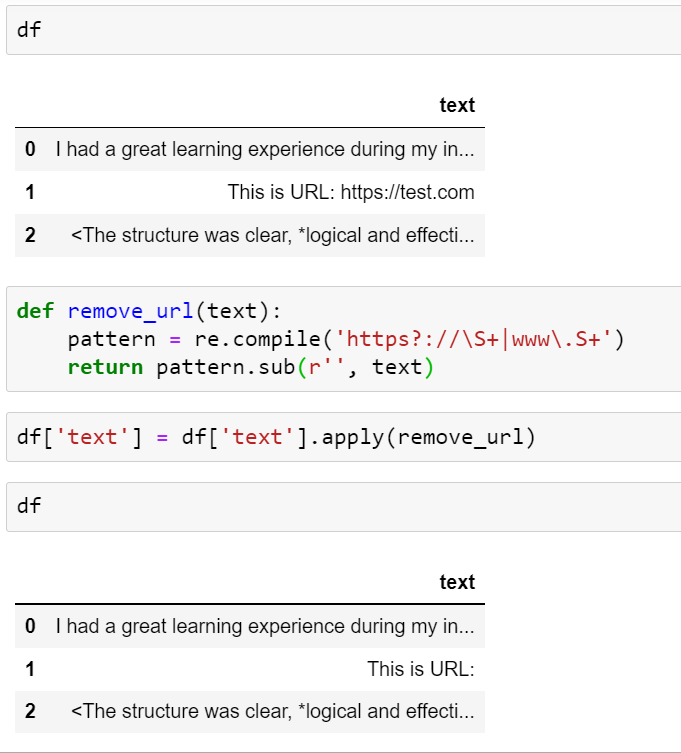
3. Remove URLs
URLs are not important in model building. We have to remove URLs.
For removing URLs we can use regex.
def remove_url(text):
pattern = re.compile('https?://S+|www.S+')
return pattern.sub(r'', text)
df['text'].apply(remove_url)
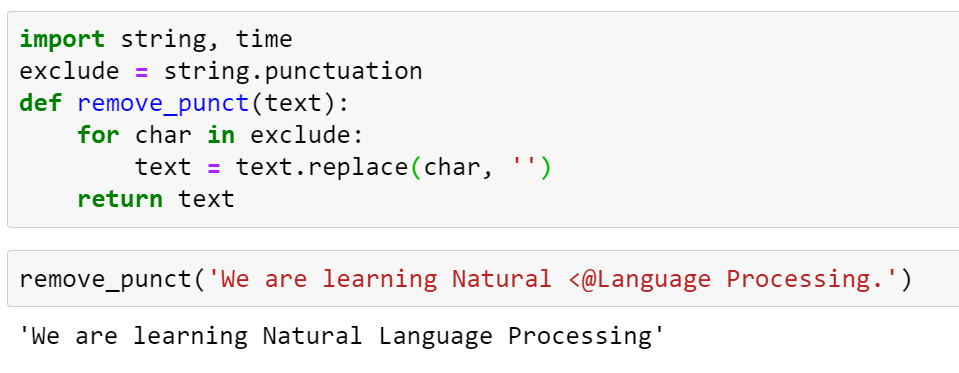
4. Removing Punctuation
If we did not remove punctuation then punctuation is also considered one word for this situation we remove punctuation.
import string, time
exclude = string.punctuation
def remove_punct(text):
for char in exclude:
text = text.replace(char, '')
return text
If we define our function then it takes lots of time. maketrans function takes less time.
def remove_punct(text):
return text.translate(str.maketrans('','',exclude)
5. Chat word Treatment
In normal chatting we use short abbreviation of words. We have to change this short form to full form.
# Add chat words in form of dictionary
chat_words = {}
def chat_conversion(text):
new_text = []
for w in text.split():
if w.upper() in chat_words:
new_text.append(chat_words[w.upper()])
else:
new_text.append(w)
return ' '.join(new_text)
6. Spelling Correction
from textblob import TextBlob
incorrect_text = 'any tezt with for checing'
textblob = TextBlob(incorrect_text)
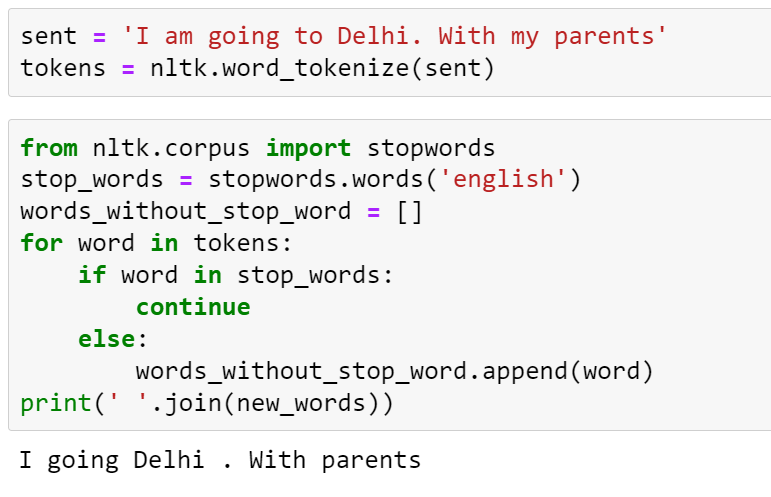
7. Removing Stop Words
Stop words are only for sentence formation but in the meaning of the sentence, stop words are not important.
from nltk.corpus import stopwords
stopwords.words('english')
8. Handling Emojis
Emojis are not understood by the machine learning model.
Two approaches we can use to handle emojis:
- Remove Emojis
- Change with meaning
9. Tokenization
In tokenization, we break data into tokens. We can do word tokenization or sentence tokenization.
sent = 'I am going to Delhi. With my parents.'
1. Using the split function
sent.split()
2. Using NLTK Library
import nltk
from nltk.tokenize import word_tokenize, sent_tokenize
word_tokenize(sent)
sent_tokenize(sent)
3. Using Spacy Library
import spacy
nlp = spacy.load('en_core_web_sm')
doc1 = nlp(sent)
for token in doc1:
print(token)
10. Stemming/Lemmatization
Stemming – Stemming means mapping a group of words to the same stem by removing prefixes or suffixes without giving any value to the “grammatical meaning” of the stem formed after the process.
In simple word-stemming remove suffixes and prefixes from the word.
Stemmer — It is an algorithm to do stemming
1. Porter Stemmer — specific for the English language
2. Snowball Stemmer — used for multiple languages
3. Lancaster Stemmer
#importing the Stemming function from nltk library
from nltk.stem.porter import PorterStemmer
#defining the object for stemming
porter_stemmer = PorterStemmer()
sent = 'History is the best subject for teaching'
tokens = nltk.word_tokenize(sent)
for word in tokens:
print(word,'---->',porter_stemmer.stem(word))
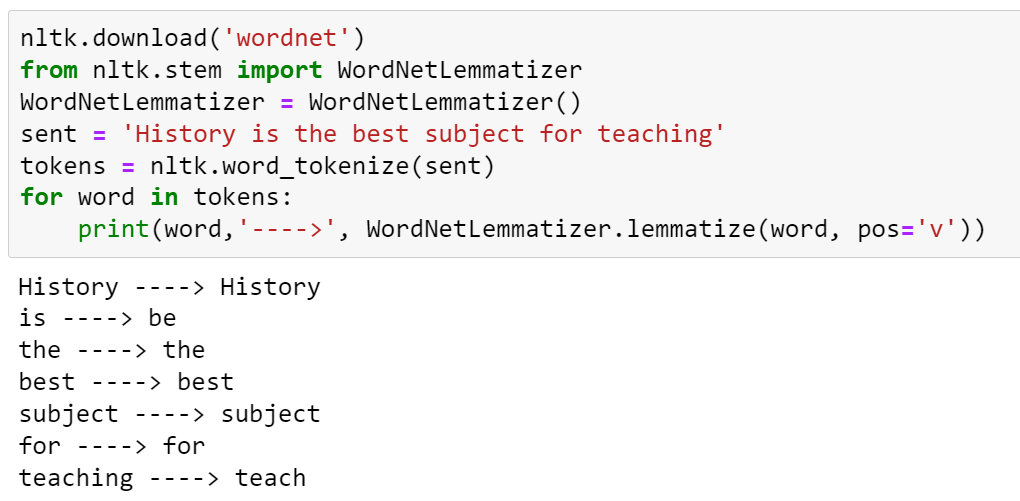
Lemmatization— Lemmatization also does the same thing as stemming and tries to bring a word to its base form, but unlike stemming it does keep into account the actual meaning of the base word.
In Lemmatization we search words in wordnet.
nltk.download(‘wordnet’)
from nltk.stem import WordNetLemmatizer
WordNetLemmatizer = WordNetLemmatizer()
sent = ‘History is the best subject for teaching’
tokens = nltk.word_tokenize(sent)
for word in tokens:
print(word,’—->’, WordNetLemmatizer.lemmatize(word, pos=’v’))
Conclusion
In this article, we learned different NLP Preprocessing Steps. The key takeaways from the article are,
- We learned different Preprocessing steps such as lowercasing, removing HTML tags, tokenization, removing stopwords and punctuation, etc.
- After cleaning data using the above-preprocessing steps model accuracy may be increased.
- Various python libraries like nltk, spaCy, and TextBlob can be used.
So, this was all about Preprocessing Steps. Hope you liked the article.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Hi, I am shankar working as data engineer, I love to play with data.
My passion for data science and my expertise as a data engineer make me a valuable asset in driving data-centric projects and leveraging the power of data to solve real-world problems.