This article was published as a part of the Data Science Blogathon.
Introduction
This article will discuss the Hadoop Distributed File System, its features, components, functions, and benefits. This article also describes the working and real-time applications. Hadoop is a powerful platform for supporting an enormous variety of data applications. Both structured and complex data can be processed using this interface, facilitating heterogeneous data consolidation. With HDFS, large data sets are handled by a distributed file system using commodity hardware.
What is HDFS?
Hadoop Distributed File System (HDFS) is the primary data storage system used by Hadoop applications. To implement a distributed file system that provides high-performance access to data across highly scalable Hadoop clusters, HDFS uses the NameNode and DataNode architecture. Apache Hadoop is an open-source framework for managing data processing and storage for big data applications. HDFS is a crucial part of the Hadoop ecosystem. It can manage big data pools and support big data analytics applications.
Components of HDFS
HDFS has two components, which are as follows:
1) Namenode
2) Datanode
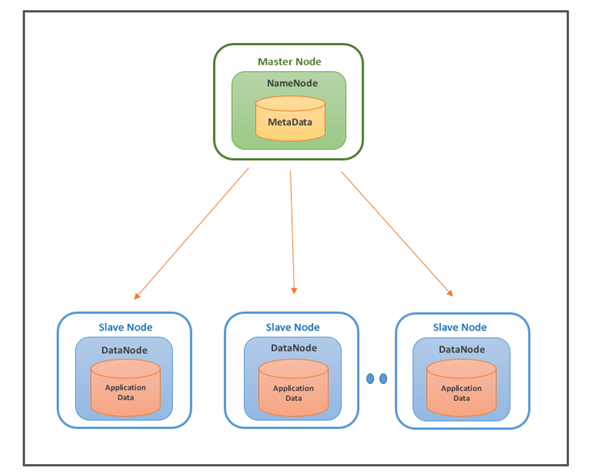
Namenode
The NameNode is the master node of HDFS and stores the metadata and slave configuration. In HDFS, there is one active NameNode and one or more standby NameNodes. The Active NameNode serves all client requests, and the standby NameNode handles high availability configuration.
Functions of NameNode:
- It manages the File system namespace and is the single Hadoop cluster failure point.
-
It keeps track of all blocks in HDFS and where each block is located.
- It manages the client access requests for the actual data files.
- The metadata about the actual data is also stored here, like File information, Block information, permissions, etc.
DataNode
DataNode is a worker node of HDFS, which can be n in number. This node is responsible for serving read and write requests to clients. Datanodes store actual data in HDFS, so they typically have a lot of hard disk space.
Functions of DataNode:
- It stores actual data in HDFS.
- As instructed by the NameNode, the DataNodes are responsible for storing and deleting blocks and replicating these blocks.
- This node handles the client’s read and writes requests.
- DataNodes are synchronized to communicate and ensure that data is balanced across the cluster, moving data for high replication, and copying data as needed.
Working of HDFS
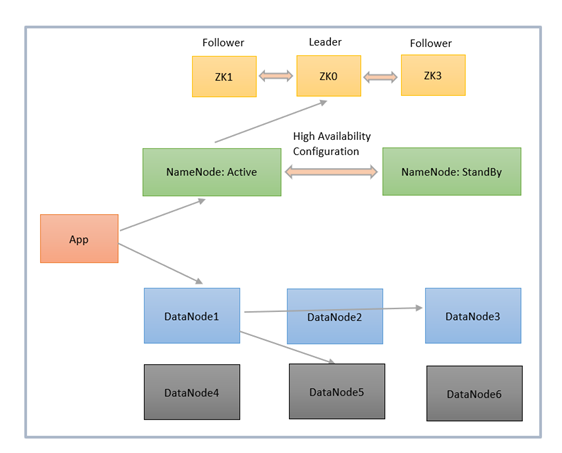
HDFS is based on master-slave architecture. It can consist of hundreds or thousands of servers. Applications such as SQoop, NIFI, and Kafka Connect write data to HDFS. The client communicates with the NameNode for metadata, and the NameNode replies with the location of blocks, the number of replicas, and other attributes.
NameNode sends the High Availability Configuration information to Zookeeper, and it replicates the information to multiple Zookeepers. Zookeepers serve as an election commissioner by selecting one StandBy NameNode when an Active NameNode is down, and there are multiple StandBy NameNodes.
Using NameNode information, the client contacts the DataNode directly. Based on the information received from the NameNode, the client will start writing data directly to data nodes and reading data from the DataNodes in parallel.
Benefits of HDFS
The benefits of the Hadoop Distributed File System are as follows:
1) The Hadoop Distributed File System is designed for big data, not only for storing big data but also for facilitating the processing of big data.
2) HDFS is cost-effective because it can be run on cheap hardware and does not require a powerful machine.
3) HDFS has high fault tolerance since if a machine within a cluster fails, a replica of the data may be available from a different node through replication.
4) Hadoop is famous for its rack awareness to avoid data loss, which results in increased latency.
5) HDFS is scalable, and it includes vertical and horizontal scalability mechanisms so you can adjust the resources according to the size of your file system.
6) Streaming reads are made possible through HDFS.
HDFS Data Replication
Data replication is crucial because it ensures data remains available even if one or more nodes fail. Data is divided into blocks in a cluster and replicated across numerous nodes. In this case, if one node goes down, the user can still access the data on other machines. HDFS maintains its replication process periodically.
Applications of HDFS
The real-time applications range from search engine requirements, ad placement, large-scale image conversion, log processing, machine learning, and data mining. Also, several industries use this to manage pools of big data, a few of which are :
Electric companies:
The health of smart grids is monitored through the use of phasor measurement units (PMUs) installed throughout their transmission networks. Selected transmission stations use these high-speed sensors to measure voltage and current amplitudes. These companies analyze PMU data and adjust the grid to detect segment network faults. With PMU networks logging thousands of records per second, companies take advantage of HDFS.
Marketing:
Targeted marketing campaigns require marketers to have a deep understanding of their target audiences. Marketers can gather this information from several sources, including CRM systems, direct mail, point-of-sale systems, Facebook, and Twitter. An HDFS cluster is the most cost-effective way to store this unstructured data before it is analyzed since it is unstructured.
Oil and gas companies:
The oil and gas industries deal with various data formats and massive data sets, including videos, 3D earth models, and machine sensor data. It is made possible by an HDFS to perform big data analytics on such data.
Conclusion
This article discussed Hadoop Distributed File System, its components, and their functions. In addition, we discussed the architecture and workings of HDFS, its benefits, and real-world applications. Due to Hadoop’s open-source features, its commodity servers are more affordable to use with improved performance. Using Map/Reduce, users can manipulate the methods of analyzing their data. Let’s summarize the best key points we learned and should remember:
- HDFS is fast, affordable, and scalable.
- Hadoop and HDFS are excellent tools for handling big data, especially when you plan to grow at a large scale.
- The NameNode failure is critical to the file system, but the BackupNode or a coordination service such as Zookeeper can maintain data availability during each service cycle.
- Data Replication and Rack Awareness are essential features of HDFS, which help improve networking performance and prevent data loss.
If you have any questions or comments, please post them in the comments below or connect with me on LinkedIn.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Passionate about solving business problems with data-driven solutions. Skilled in the field of Data Science and Big Data Engineering.
I have worked on various projects, including developing predictive models, analyzing complex data sets, and designing and implementing data architectures and pipelines.
I enjoy exploring new data science and data engineering techniques and keeping up with the latest industry trends.






