This article was published as a part of the Data Science Blogathon.
Introduction
Arushi is a data architect in a company named Redeem. The company provides cashback to customers who check in at restaurants & hotels. Customers log in through the app and upload the bills and they got a certain percentage of the total bill amount as cashback. The company is currently using an SQL server to manage the customer database. The user base of the company is increasing very rapidly. In order to meet the accelerated growth of the user base, the company plans to switch to the cloud-based serverless architecture. They got GCP-BigQuery as the solution. It is a cloud-based serverless architecture that is fully managed and can be scaled up and scaled down as per the load.
In this article, we will understand the big query architecture, its advantages, and its use cases. So, let’s begin!
BigQuery Ensures Data-Driven Decision Making
BigQuery is the process of making decisions based on the data and not on intuition. Human intuition or observation tends to be biased and provides false conclusions sometimes. Data-Driven decision-making ensures that it is the data from which the conclusion is to be made as it results in error-free judgment. In order to conduct the process, we must follow these steps:
1. Business Problem Formulation
It is necessary that you identify the correct business questions before going down the journey. It acts as a priority and provides clarity to the goals. It can be formulated based on your company’s customer needs, maximizing profits, identifying potential customers etc. In our scenario, Redeem company is interested in identifying and categorizing restaurants and hotels based on revenue per user. It helps to segment the restaurants & hotels, and they can come up with the right strategy to maximize their earnings.
2. Identify Data Sources & Variables to Capture
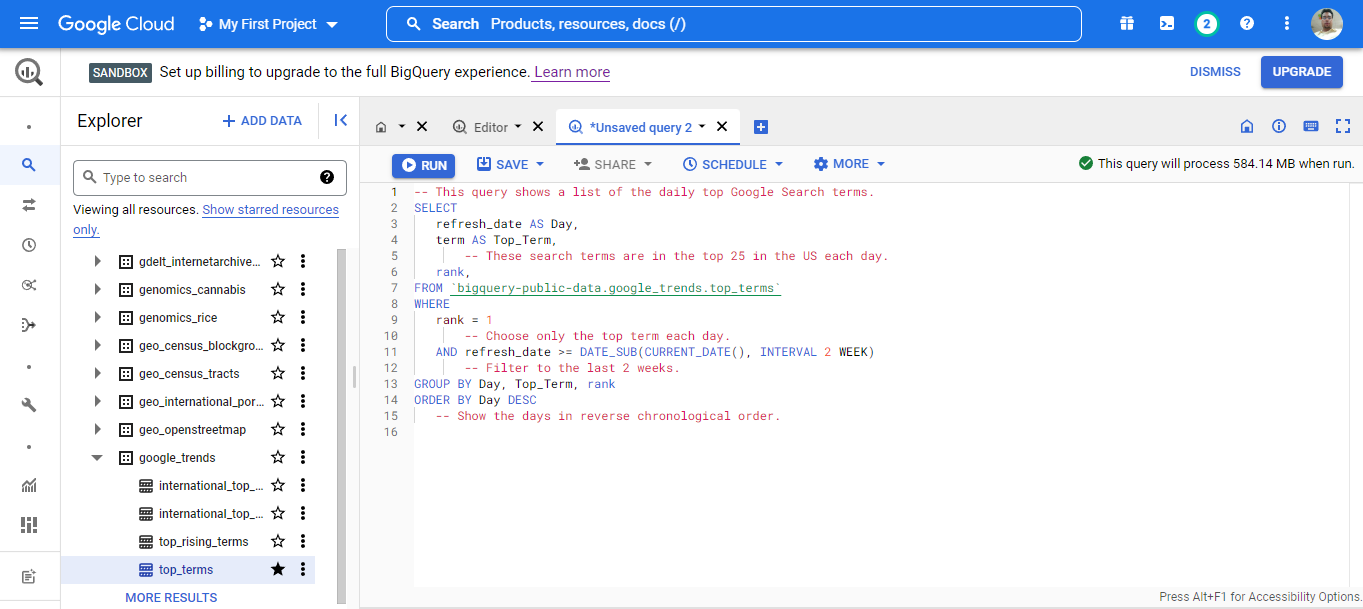
Once the Business problem is formulated, the next step is to identify the sources of data and the mechanism to integrate it and store it in a single place. For example, data can come from CSV files, log files, web forms, marketing campaigns, etc. It is also necessary to identify the variables which are the key to the business problem. In our case, Redeem is capturing the relevant variables(Revenue, Number of user check-in, Customer & User details). This data is captured from the app whenever any user check-in and then it is saved in the Google BigQuery table. See the image of the BigQuery table given below:
3. Data Cleaning & Organization
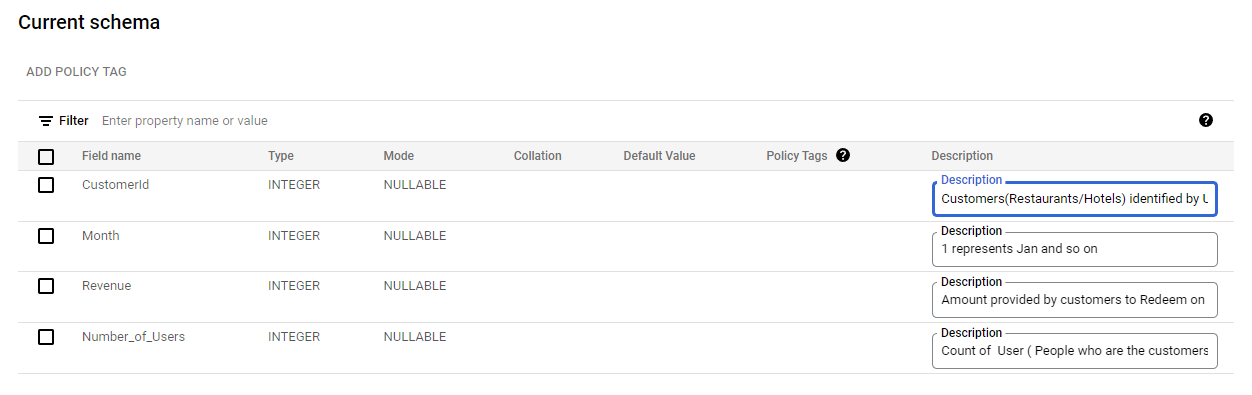
Before querying and generating insights, it is important to ensure that the data is clean. The error arises due to various reasons. For Example, manual errors during data entry, encoding and decoding errors, etc. Apart from cleaning, it is important to organize your data. It means creating a data dictionary that explains all the variables. Here you can see the description of variables given below:
4. Querying the Bigquery Table
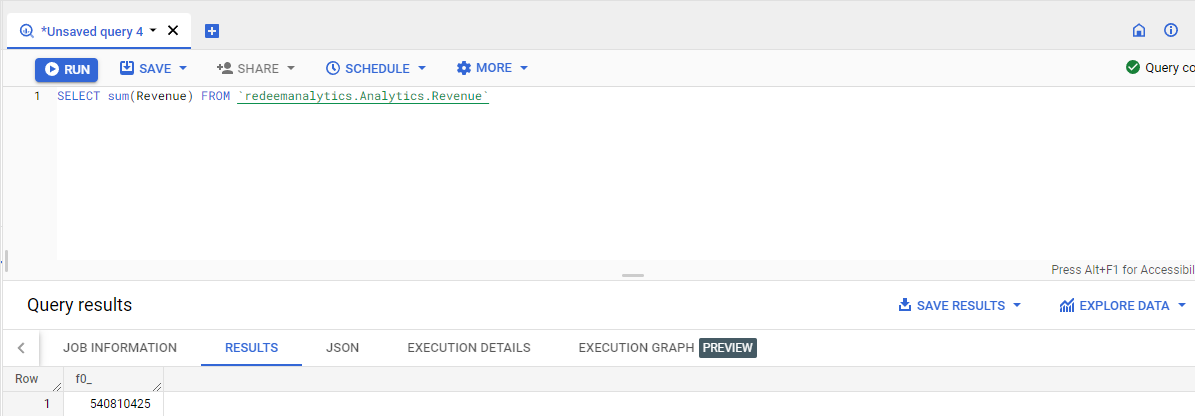
Big Query provides SQL-like syntax to query the table. We can do aggregation on columns, can join tables, and do many more tasks. BigQuery is ultra-fast and can fetch results within seconds. Here we can see that we are selecting the sum of revenue from the Revenue table.
5. Insights
This is the final step towards our data-driven life cycle. Insights are the key to our final business decisions. For Example, users are clicking on a particular item more than others. This can help us to provide a recommendation for other products which resemble very high to this particular item. This decision made after the insight is helpful to increase sales.

Understanding the BigQuery Architecture
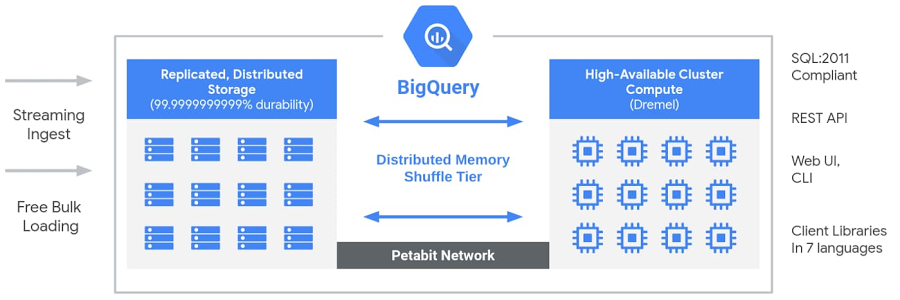
BigQuery is Google’s cloud-based data warehouse system. Its serverless architecture separated computing from storage. It means storage and computing power can be scaled up independently. This architecture provides users flexibility and control in terms of storage and cost respectively. Users don’t worry about the underlying structure, as the Google cloud manages everything. It helps users to focus on business problems without any technical expertise in databases. Data is stored in Google distributed file system, which is highly reliable and automatically scales up as per the load. Users can query through BigQuery clients (Web UI, REST API, CLI, and client-side languages). Data is queried from the storage, and then it goes into the compute part, where all the aggregation and calculations are carried out. Google’s highly reliable network connects the two parts – Storage & compute.
If we go deeper, we see that various low-level technologies like Dremel, Colossus, Jupiter, and Borg are running behind the scenes.
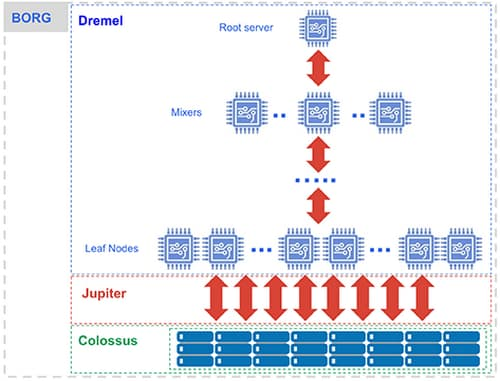
1. Dremel
It is the execution engine that converts SQL queries into a tree. Reading data from the storage(Colossus) occurs through slots(leaves of the trees). Aggregation is carried through mixers(branches). Jupiter is the connection between leaf nodes and the colossus and is a reliable network system. It also dynamically provides slots so that a single user can get multiple slots for a query.
2. Colossus
It is Google’s distributed file system. It provides enough disk to a user. It also handles replication and recovery during disk crashing. It stores the data in a columnar and compressed format, which helps in space optimization and low cost of running.
3. Jupiter
It is a reliable network between computing and storage and helps in communicating. It provides very high bandwidth, which helps in the efficient and quick distribution of large workloads.
4. Borg
It is a large-scale cluster management system. It protects from failures like machine crashes, and power supplies fail, etc.
BigQuery Structure
A traditional database structure is like a database, with tables and columns; similarly, BigQuery follows a structure.

1. Project
It is a top-level container and is like a database in a traditional database system. In order to create its log-in to the GCP account. You can use the sandbox for free. After Login, click the new project, enter the project name, and create.
2. Dataset
As there are different departments within a company, you can have different purposes. A project can have more than one dataset.
3. Tables
Tables are the columnar representation of the data. A dataset can have more than one table.
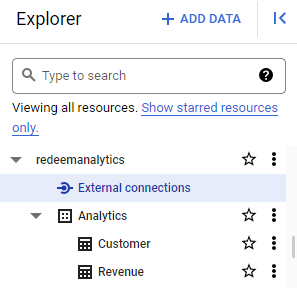
In our case(Redeem): Project Name – redeemanalytics
Dataset- Analytics
Tables: Customer & Revenue
Use Case of Customer Segmentation
Customers are very important to any organization. As a business, we uniquely fulfill our customer’s needs, generating revenue and profits. Customers’ needs vary from one to another, and it is part of the segmentation process is to group similar customers in the same group.
Redeem is a cashback company that provides cashback to users of restaurants and hotels. The company generates revenue from restaurants/hotels by providing customers with them. It is essential to identify which customers are getting more check-ins. It helps to strategize a new pricing policy.
Business Problem Formulation: How to Know the customers(Restaurants/Hotels) to whom we are providing very good business and categorize them?
Data Source: Redeem capturing the app’s customer and revenue data, then insert it in the BigQuery table. We have two tables: Customers & Revenue. Let’s have a look and do some Exploratory data analysis in BigQuery.
1. How many customers do we have?
Let’s count the unique customers.
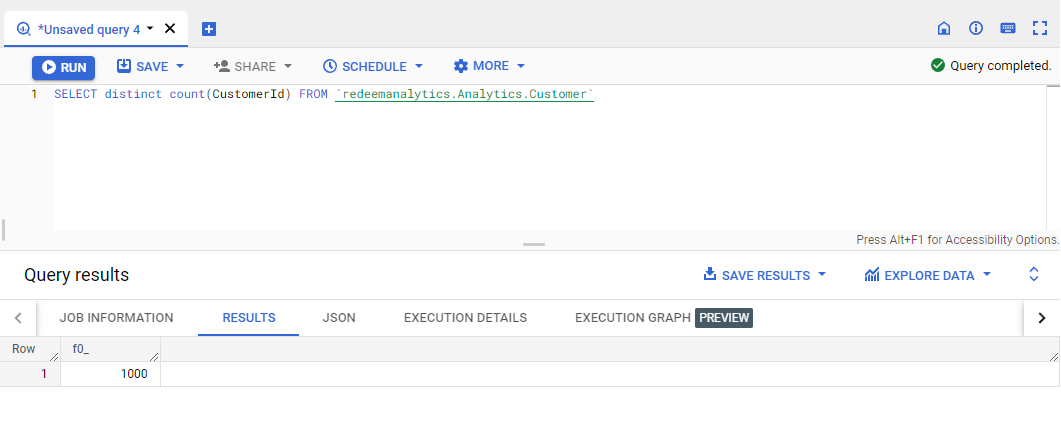
The query is quite simple. We selected distinct customers from the Customer table, and we got 1000.
`redeemanalytics.Analytics.Customer`: The sequence is – Project Name.Dataset.Table
2. Revenue Generated by the Redeem per user
Restaurants/Hotels provide a certain amount for each user check-in. In this scenario, only those users will be taken into account who check in and upload the bill on the Redeem app.
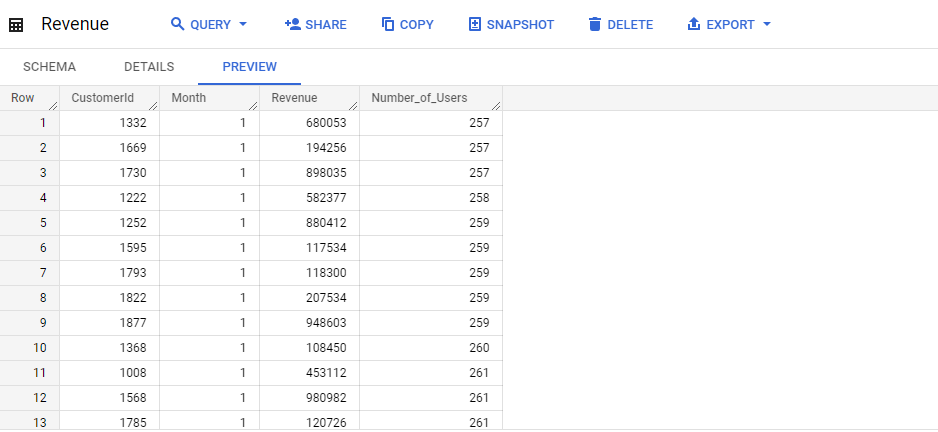
Let’s see the Revenue table by selecting all the columns.
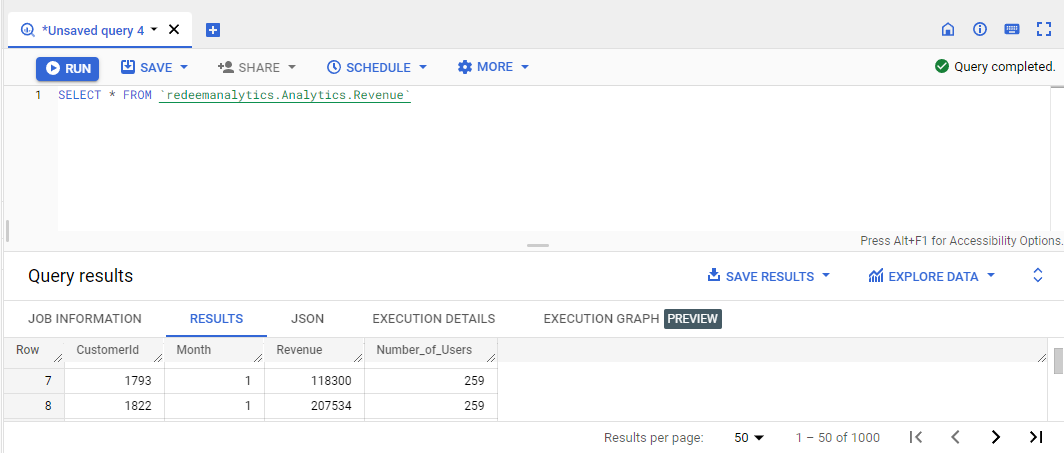
We can see that there are 4 variables: CustomerId, Month, Revenue, and Number of Users. Our variable of interest, Revenue/User, is not present, but we can create it in the big query table by the formula:
RevenuePerUser = Revenue / Number of Users
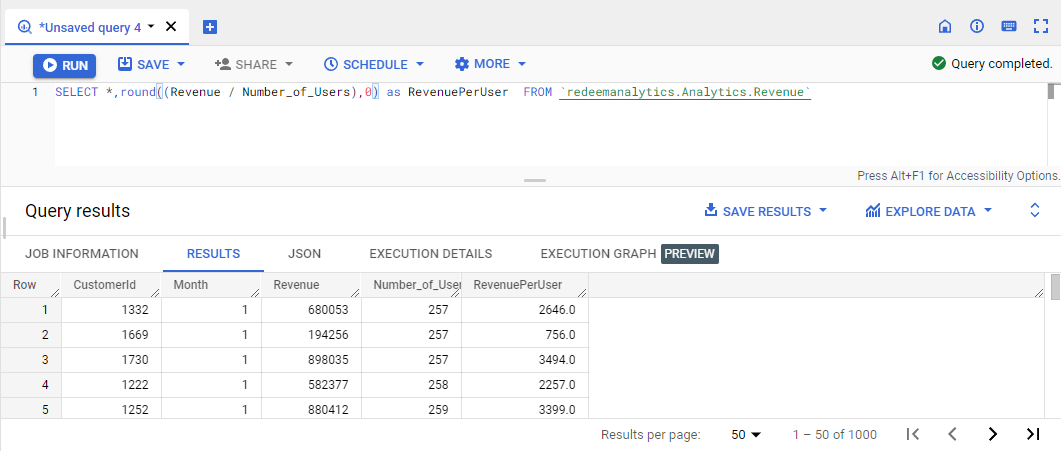
3. Categorize Customers based on median
The Median is the mid-point of a series when arranging it in ascending order. We can calculate each data point’s median and how far each data point lies away from the median.
Score = (RevenuePerUser – Median of RevenuePerUser ) / Median of RevenuePerUser
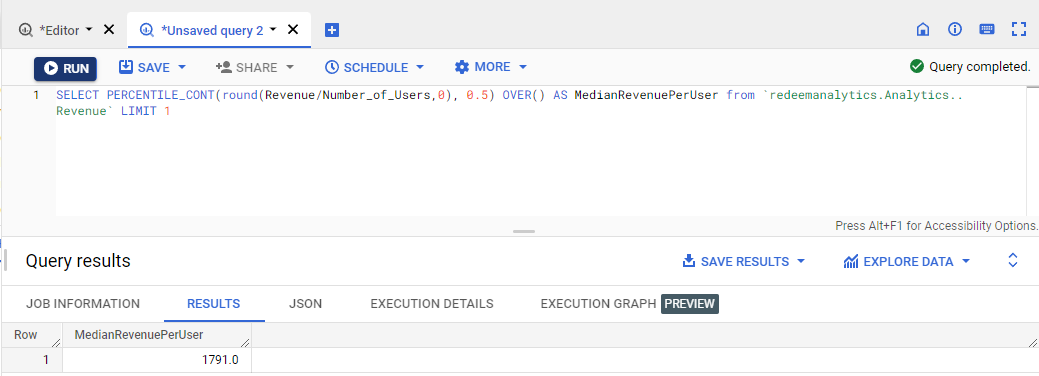
We got the Median of Revenue Per User = 1791. Now we will calculate the score by the formula given above.
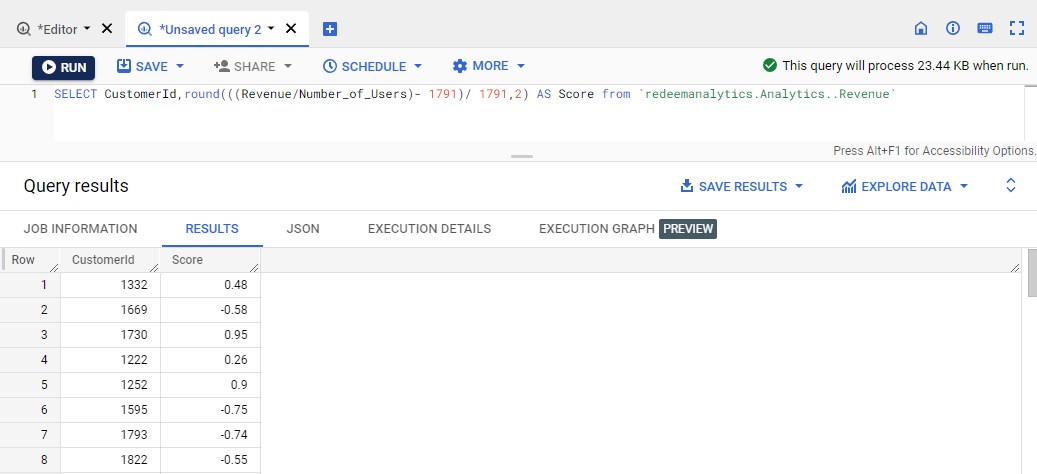
The result can be saved in a new table named CustmoerScore. A score of 0.5 means it lies 50% higher than the median. We can segment our customers based on the table given below:
| Score | Segment |
| > 0.5 | Elite |
| > 0 and <= 0.5 | Good |
| = -0.5 | Average |
| < -0.5 | Low |
4. Statistics of Customer Segment
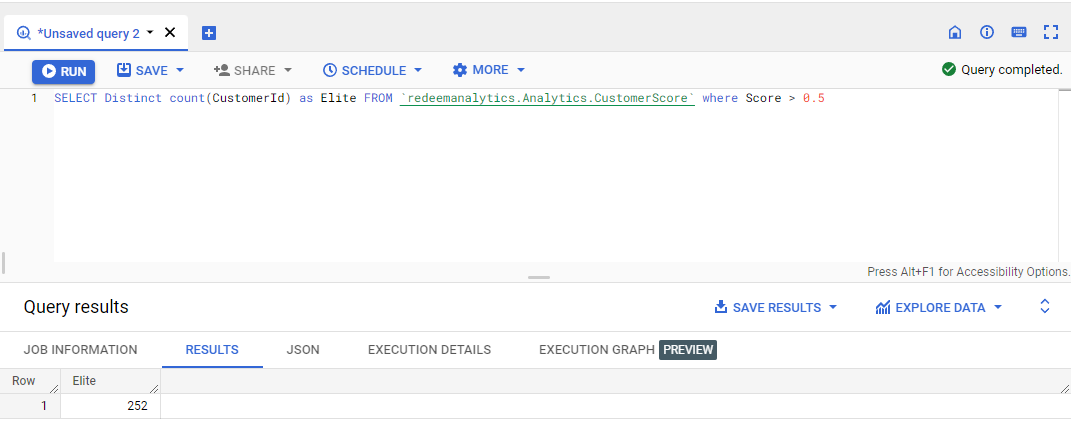
a) Find out the number of customers in the elite segment.
We will query the CustomerScore table and find the Elite Customers count.
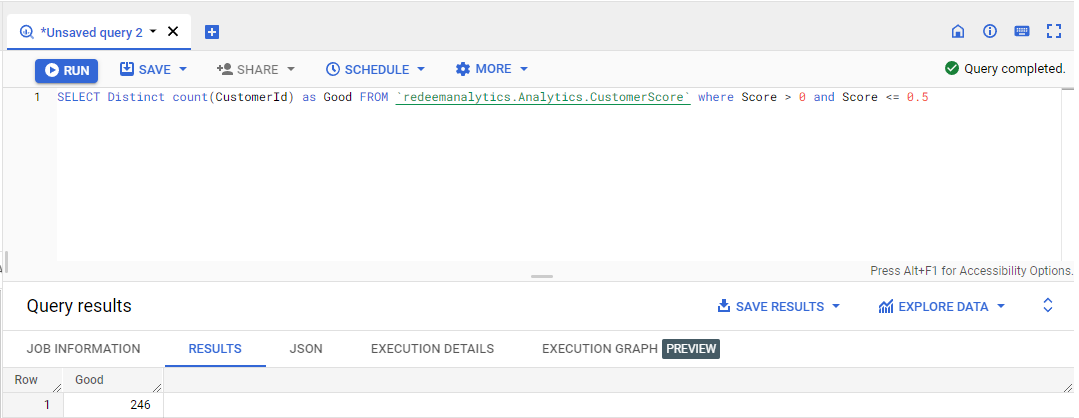
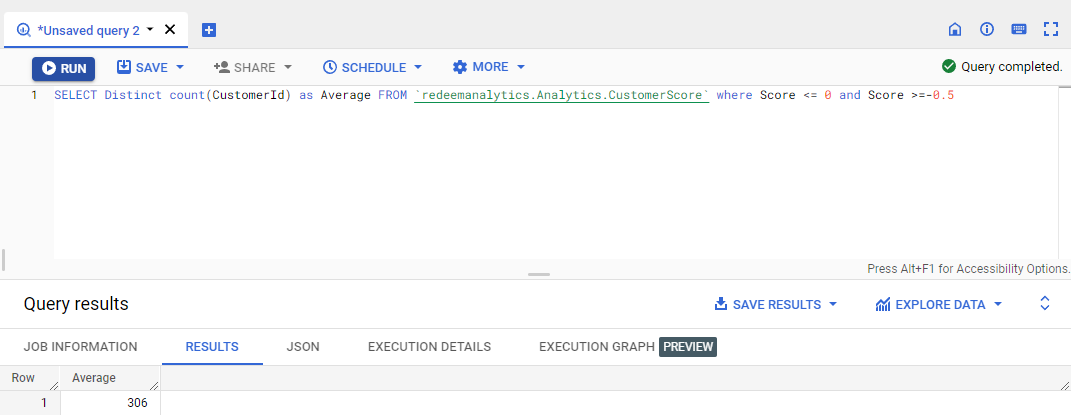
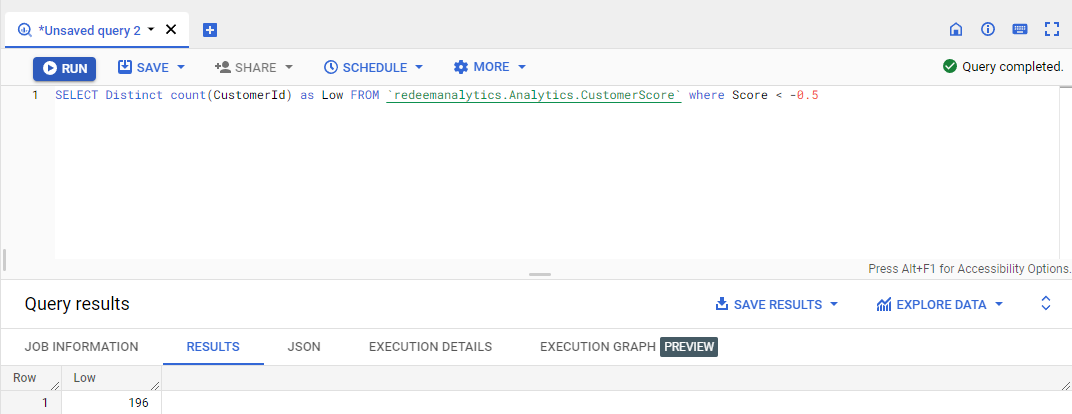
b) Similarly, we will find the count of other segments.
5. Final Summary of Customer Segment
| Segment | Count of Customers(% of total count) |
|
|
|
|
|
|
|
|
6. Insights & Key Business Decision
Elite Customers: These customers are providing very high revenue per user. The customers of these restaurants & hotels are high-net-worth individuals looking for wonderful experiences. We can promote these restaurant offerings to users looking for quality.
Good Customers: These are somewhat below the Elite customers, and the users of these are looking for a balance between quality and quantity. We can promote a nice experience with discount offerings.
Average Customers: Users looking for discount offerings
Low Customers: free services and offering to the users.
The strategy of the Redeem based on the insight is tabulated below:
| Customer Segment | User Types | Key Business Strategy of Redeem |
| Elite | Very High-income individuals | Promote Quality(Experience) |
| Good | High-Income Individuals | Balance of experience and pricing |
| Average | Average- Income Individuals | Discount Offerings |
| Low | Low- Income Individuals | Free offerings |
Conclusion
In this article, we understood the BigQuery architecture. It is highly reliable, ultra-fast, and scalable due to its cutting-edge technology. It is very popular among businesses as a data-driven solution for complex business problems. It provides useful insights to help in making key business decisions. We also wrote SQL syntax-like queries in BigQuery for our customer segmentation use case. We also identified a sequential approach to data-driven decision-making and applied it in our use case successfully.
The key takeaways of the article are:
- GCP- BigQuery is a cloud-based data warehouse serverless self-managed solution. It is scalable as per load demand.
- It is highly useful for businesses to make data-driven decisions.
- We understood the use case: Customer Segmentation with the help of BigQuery.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
As a writer, I specialize in creating content that explains complex concepts in a clear and concise manner for both technical and non-technical audiences. I have experience writing about a variety of topics, including statistical analysis, data mining, predictive modelling, deep learning, computer vision, natural language processing (NLP) and other technical and business stuff.
My goal as a writer is to make these complex topics accessible to a wider audience by breaking down technical jargon into easy-to-understand terms and providing real-world examples that illustrate the concepts at hand. I strive to create content that is informative, engaging, and easy to read.



