This article was published as a part of the Data Science Blogathon.
Introduction
Processing large amounts of raw data from various sources requires appropriate tools and solutions for effective data integration. Many companies prefer to work with serverless tools and codeless solutions to minimize costs and streamline their processes. Building an ETL pipeline using Apache beam and running it on Google Cloud Dataflow is an example of creating an ODS solution from EPAM.
Challenge 1: A data integration solution supporting very different types of data sources
The client contacted EPAM with a challenging task – to create a data integration solution for data analysis and reporting with the ability to integrate with machine learning and AI-based applications. The data integration solution had to collect data from different types of data sources (SQL, NoSQL, REST) and transform the data for reporting, discovery, and ML. The client was interested in an analytical tool like Tableau or Data Studio, looking for a solution that could easily integrate with many traditional and non-traditional data sources and be flexible to any change.
The client expected the developed solution to include a reliable and flexible data pipeline architecture and an internal common data model for abstracting incoming data extracted from various data sources.
What is an ETL pipeline: ETL vs. Data Pipeline
A data pipeline is a process of moving data from a source to a destination for storage and analysis. A data channel generally does not specify how the data is processed along the way. One of the properties of a data channel is that it can also filter data and provide fault tolerance.
If this is a data pipeline, what is an ETL pipeline? In the ETL data pipeline, data is loaded (Extract), processed (Transform), and passed to the target system (Load).
Extract-transform-load pipeline: enables data migration from the source system to the new repository; centralizes and standardizes multiple resources for a consolidated v, and provides a large dataset for BI and analytics. Broadly speaking, ETL is a sub-process, while “data pipeline” is a broader term that represents the entire data transfer process.
EPAM solution
The EPAM team identified the first step as creating an ODS (Operational Data Store); central data storage from multiple systems without specific data integration requirements. ODS makes data available for business analysis and reporting by synthesizing raw data from multiple sources into a single destination.
Unlike a data warehouse that contains static data and executes queries, ODS is an intermediary for the data warehouse. It provides a consolidated repository available to all systems that frequently rewrite and change data, creates reports at a more sophisticated level, and supports BI tools.
When looking for a self-service integration platform, the EPAM team wanted a solution for external teams and external resources that would not be as costly as P2P integration.
First, we found a platform to run our solution on. Then we decided on a solution. We finally put it all together.
What is a data stream?
The Google Cloud Platform ecosystem provides a serverless data processing service, Dataflow, for running batch and streaming data feeds. As a fully managed, f, fast, and cost-effective data processing engine used with Apache Beam, Cloud Dataflow enables users to develop and execute a variety of data processing, extract-transform-load (E, TL), and batch and streaming patterns.
Data can be transferred from multiple sources (CRM, database, REST API, file systems). A pipeline run by Dataflow extracts and reads data transforms it, and finally writes and uploads it to cloud or local storage.
Dataflow is the perfect solution for building data pipelines, tracking their execution, and transforming and analyzing data, as it fully automates operational tasks such as resource management and optimizing your pipeline performance. In Cloud Dataflow, all resources are provisioned on demand and automatically scaled to meet demand.
Dataflow works for both batch and streaming data. It can process different pieces of data in parallel and is designed for big data processing. Dataflow is the perfect solution for automatically scaling resources, balancing dynamic work, reducing the cost of processing a data record, and delivering ready-to-use real-time AI patterns. The range of features allows Dataflow to perform complex pipelines using basic and specific custom transformations.
With Dataflow providing a range of opportunities, your results are only limited by your imagination and your team’s skills.
Why does EPAM choose Dataflow?
Besides Dataflow, there are other data processing platforms. Google’s Dataproc service is also an option, but the EPAM team liked that Dataflow is serverless and automatically adds clusters when needed. Most importantly, Google intended Apache Beam programs to run on Dataflow or the user systems.
Google promotes Dataflow as one of the main components of the big data architecture on GCP. With the ability to extract data from open sources, this serverless solution is native the to Google Cloud Platform, enabling rapid implementation and integration. Dataflow can also run in ETL solution because it has: building blocks for operational data stores and data warehouses; data filtering and enrichment pipelines; PII de-identification pipeline; function for detecting anomalies in financial transactions; and export logs to external systems.
What is Apache Beam?
What is Apache Beam? Apache Beam, which evolved from several Apache projects, emerged as a programming model for creating pipelines for data processing. The Apache Beam framework does the heavy lifting for large-scale distributed data processing.
You can use Apache Beam to create pipelines and run them on cloud runners such as Dataflow, Apache Flink, Apache Nemo, Apache Samza, Apache Spark, Hazelcast Jet, and Twister2.
Why did EPAM choose Apache Beam?
First, Apache Beam is very efficient and easy to use with Java. Unlike Apache Spark, Apache Beam requires less configuration. Apache Beam is an open, vendor-agnostic, community-driven ecosystem.
Beam has four basic components:
- A pipeline is a complete process consisting of steps that read, transform, and store data. It starts with an input (source or database table), includes transformations, and ends with an output (sink or database table). Transformation operations may include filtering, joining, aggregation, etc., and are applied to data to give it the meaning and form desired by the end user.
- A collection is a specialized container of almost unlimited size representing a data set in a pipeline. Collections are the input and output of the real transformation operation.
- PTransform is the data processing step inside your pipeline. Whatever operation you choose—data format conversion, math calculation, data grouping, combining, or filtering—you specify it, and the transformation performs it on each collection element. The P in the name stands for parallel because transformations can run parallel across many distributed workers.
Apache Beam code examples
Although Java or Python can be used, let’s look at the Apache Beam code pipeline structure using Java.
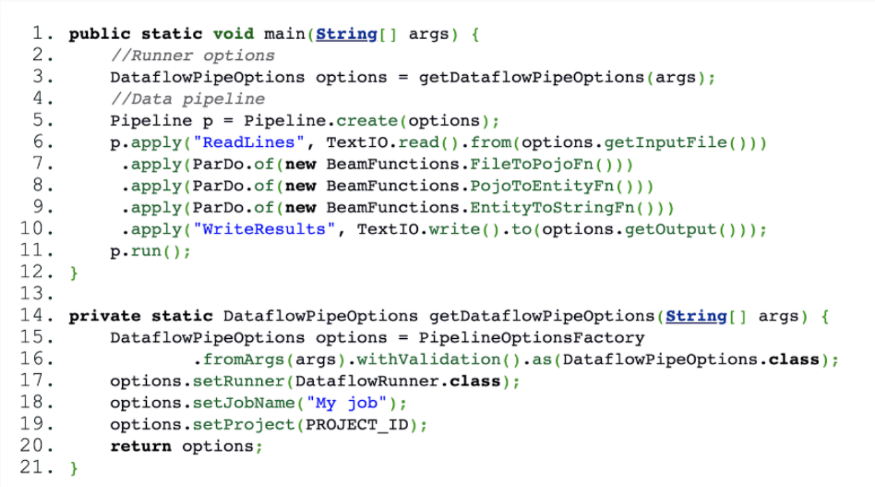
Here is an example created using Dataflow. To create and operate a pipeline, you must
- Create a PCollection
- Use the PTransforms sequence
- Run the pipeline
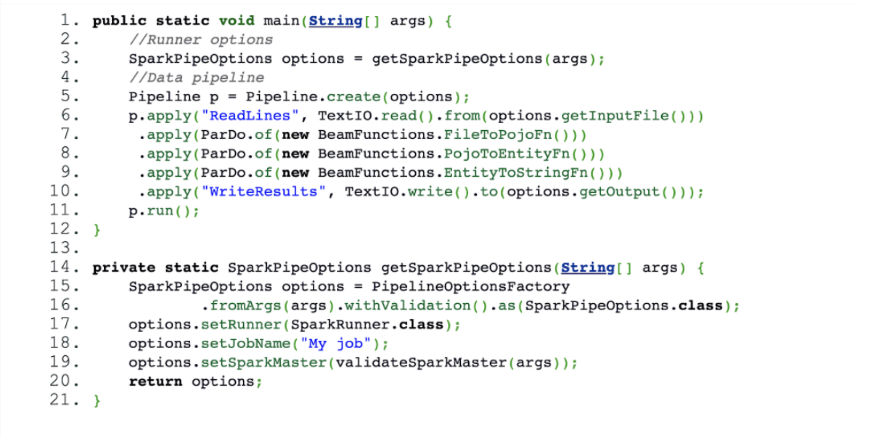
Here’s an example built using the Apache Spark runner that replicates the code but uses a different Runner options fragment.
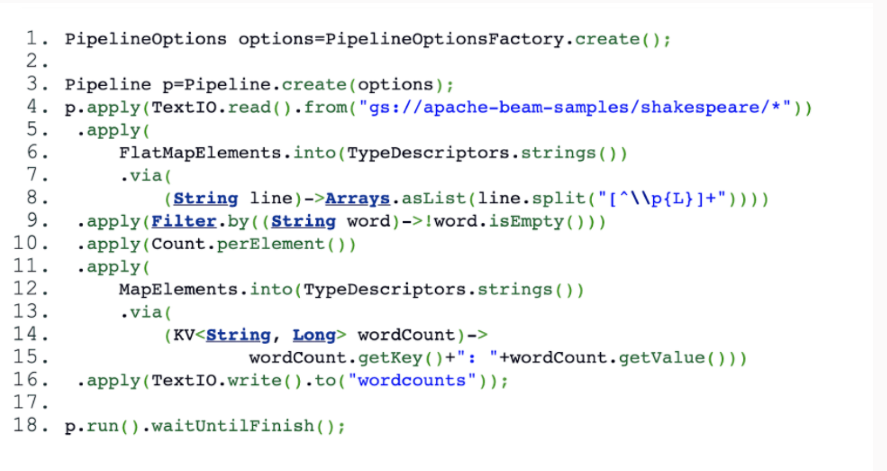
Now run this code for basic transformations. Here is an example of Word Count. The channel reads from multiple text formats by supporting “read” and “write” operations.
The first transformation is ‘TextIO.read’, and the output is a P Collection with string lines of text from the input file. The second turn is the rows of strings in the P Collection. The third transformation is empty word filtering. The fourth transformation counts the number of times a word appears. This map transformation applies a function to each element in the input PC collection and produces a single output element. Every word count counts. The fifth and final transformation formats the Map Elements into strings of Type Descriptors and produces an output text file.
This example is done with standard Beam frame transformations.
Now let’s see how to run a pipeline with user-defined custom transformations. After the channel is created, the Read transforms text file is used. The Count transformation is a custom transformation that counts words. The map transform uses the new FormatAsTextFn custom function to format each word count occurrence into a string. The strings are then passed to the output file.
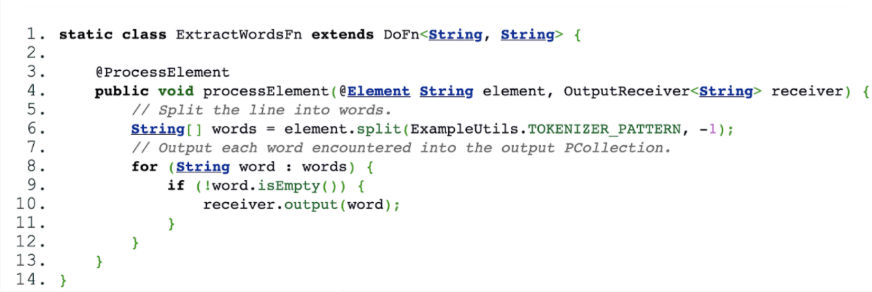
Now let’s see how to create compound transformations. Here we use the ParDo steps (transformation for generic parallel processing) and the transformations in the SDK to count words. Transform subclass Count Words have two complex transformations. ParDo extracts the words, and the transformation provided by the SDK runs Count.perElement.
A similar algorithm is used for word extraction. We just split the row into words and filter out the empty values. In this exam, plus, we enter explicit DoFns. This function gets one element in the input PCollection and the receiver in the resulting output file.
Challenge 2: unexpected context
The customer was satisfied with the solution that EPAM designed based on Dataflow. A fully serverless data processing system, built on GCP and using Google’s big data architecture, was exactly what they needed to support multiple resources and use machine learning and AI.
However, after presenting the solution, the customer revealed an unexpected piece of information: the databases were critical and sensitive. Therefore, the customer could not trust Google or use most GCP services for security reasons.
Our solution
In response, the EPAM team leveraged available software services and built a separate ETL solution for each data source. In the future, each new data source will be added by generating a new project from a common ETL archetype and applying business logic code. When designing the customer’s project pipeline, the EPAM team studied the customer’s data sources and decided to unify all data in the workspace before loading it into the data warehouse. The workspace acts as a buffer and protects data from corruption.
Essentially, we have arrived at a Lambda architecture variant that allows users to process data from multiple sources in different processing modes.
The EPAM solution is open to expansion and external integrations. The EPAM solution has two independent phases that increase system reliability and expand the possibilities for external systems by using a batch system and a stream processing system in parallel. External systems can passively integrate through data source access and actively send data to the staging area, either to Google BigQuery or directly to the BI reporting tool. A workspace in the project pipeline allows users to clean data and combine multiple data sources.
EPAM Integrators have created a software architecture design ideal for data integration and a GCP Dataflow framework that can be used as a starting point for building ETL pipelines. EPAM’s software architecture design enables the use of ready-made ETL solutions and codeless integration. Over time, the customer and integrators will increase the number of integrations and extend the Apache Beam framework with new components. This will greatly facilitate subsequent integrations.
Conclusion
A data pipeline is a process of moving data from a source to a destination for storage and analysis. A data channel generally does not specify how the data is processed along the way. One of the properties of a data channel is that it can also filter data and provide fault tolerance.
Our conclusions from the construction of the ETL gas pipeline for the customer can be summarized as follows:
- Using a serverless approach significantly speeds up data processing software development. The Apache Beam framework does the heavy lifting for large-scale distributed data processing.
- Apache Beam is a data processing pipeline programming model with a rich DSL and many customization options.
- A framework-style ETL pipeline design enables users to build reusable solutions with self-service capabilities. A serverless and decoupled architecture is a cost-effective approach to meeting your customers’ needs.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
.png)