This article was published as a part of the Data Science Blogathon.
Introduction
With the development of data-driven applications, the complexity of integrating data from multiple simple decision-making sources is often considered a significant challenge. Although data forms the basis for effective and efficient analysis, large-scale data processing requires complete data-driven import and processing techniques in real-time. To help with this, data pipelines help different Service Providers to compile and analyze large data sets by defining a series of functions that convert raw data into valuable data. This article explains how the data pipeline helps process large amounts of data, different architectural options, and best practices for maximizing profits.
.jpg)
What is a Data Pipeline?
The data pipeline is a set of functions, tools, and techniques to process raw data. Pipes include a number of related processes to link the series, which allow the transmission of data from its source to the destination for storage and analysis. Once the data has been imported, it is taken for each of these steps, in which the single-step output results next step input.
In modern technology, extensive data applications rely on a microservice-based model, allowing loads of monolithic functions to be divided into modular sections with more minor codes. This promotes data flow across multiple systems, with data generated by one service into one or more service inputs (applications). In addition, a well-designed data pipeline helps to manage the variability, volume, and speed of data in these applications.
Advantages of Data Pipeline
The main benefits of implementing a well-designed data pipeline include:
IT Service Development
When building data processing applications, the data pipeline allows for duplicate patterns – single pipelines can be reused and used in the flow of new data, which increasingly helps to evaluate IT infrastructure. Repeated patterns also incorporate protection from construction from the ground up, allowing for the enforcement of good reusable security operations as the application grows.
Increase Application Visibility
Data pipelines help expand shared understanding of how data flows in the system and visibility of tools and techniques used. Data engineers can also set the telemetry of data flow throughout the pipeline, allowing for continuous monitoring of processing performance.
Improved Production
With a shared understanding of data processing operations, data teams can better organize new data sources and streams, reducing the time and cost of integrating new streams. Giving statistical groups complete visibility of data flow also enables them to extract accurate data, thus helping to improve data quality.
Important Parts of the Data Pipeline
Data pipelines force data development by moving it from one system to another, usually through separate storage usage. These pipelines allow you to analyze data from different sources by converting it into a compact format. This change consists of various processes and components that handle different data functions.
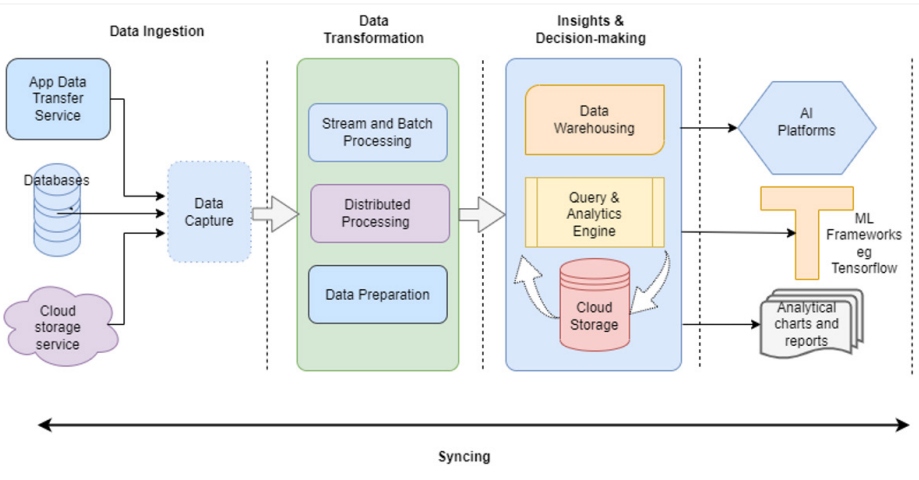
Data Pipeline Processes
Although different operating conditions require different workflows, the following are some common data pipeline procedures:
Data pipeline
Although the complexity of a data pipeline varies based on usage conditions, the amount of data to be extracted, and the frequency of data processing, here are the most common categories of data pipeline:
Export / Import
This category includes the input of data from its source, well known as the source. Data entry points include IoT sensors, data processing applications, online processing applications, social media input forms, social data sets, APIs, etc. Data pipelines enable you to extract information from storage systems, like data pools and storage areas.
Transformation
This section covers the changes made to the data as it moves from one system to another. The data is modified to ensure it matches the format supported by the target system, such as the analytics application.
Processing
This section covers all the functions involved in importing, converting, and uploading data to the output side. Other data processing tasks include merging, sorting, merging, and adding.
Syncing
This process ensures data synchronization across all data sources and pipeline endpoints. The platform actually involves updating the data libraries to keep the data consistent throughout the life cycle of the pipeline.
Data Pipeline Options
The three main design options for building data processing infrastructure for large data pipelines include stream processing, component processing, and lambda processing.
Broadcast Processing
Stream processing involves adding data to a continuous stream and processing data into segments. The purpose of this formulation is a fast-tracking process primarily aimed at real-time data processing in terms of usage conditions such as fraud detection, logging and compilation monitoring, and user behavior analysis.
Batch Processing
For batch processing, data is collected over time and later sent for cluster processing. In contrast to streaming processing, batch processing is a time-consuming process and is designed for large amounts of unwanted data in real-time. Collection processing pipelines are commonly used for applications such as customer orders, payment, and billing.
Lambda Processing
Lambda processing is a hybrid data processing model that combines a real-time streaming pipeline and big data processing. This model divides the pipeline into three layers: clusters, clusters, and feeds.
In this model, data is continuously imported and integrated into both collection and distribution layers. The batch layer incorporates batch views and handles the main database. Stream layer handles unloaded data in big view as big performance is time-consuming. The feed layer creates an indicator of batch view so that from time to time it is asked about low latency.
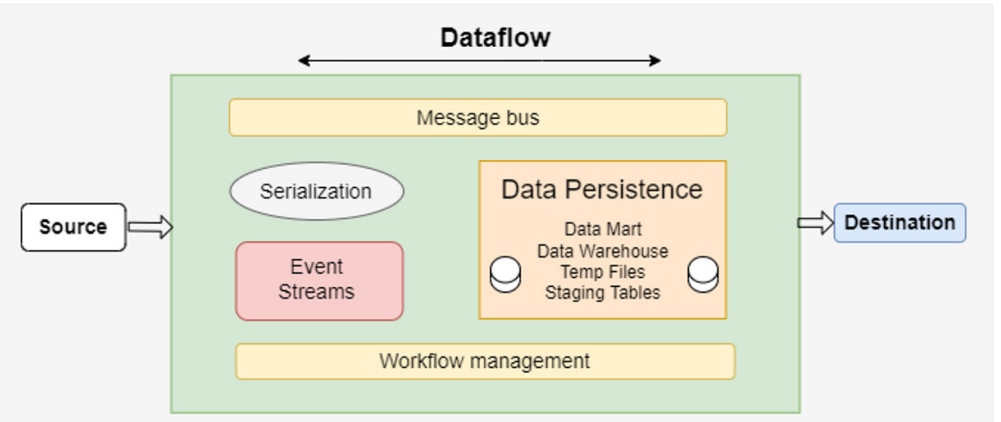
Key Components of Data Pipeline
- Data serialization– Data editing defines common formats that make data easily and accessible and responsible for converting data objects into byte streams.
- Event structures – These structures identify actions and processes that lead to change in the system. Events are included for analysis and processing to assist in app-based decisions and user behavior.
- Workflow management tools – These tools help to organize activities within the pipeline based on directional dependence. These tools also facilitate the automation, monitoring, and management of piping processes.
- Message bus – Message buses are part of an important pipeline, which allows data interchange between systems and ensures the compatibility of different databases.
- Data Persistence – A backup system in which data is noted and read. These systems allow the integration of different data sources by enabling a data access protocol in different data formats.
Best Practices for Using a Pipeline
In order to build efficient pipelines, recommended team processes include the simultaneous performance of tasks, the use of layered tools with built-in connections, investing in appropriate data processing tools, and enforcing catalog data processing and ownership.
- Enable the Performance of Similar Tasks
Multiple big data applications are used to carry out multiple data analysis tasks at a time. A modern data pipeline should be built with elastic, big, and shared patterns that can handle multiple data flows at a time. A well-designed pipeline should load and process data from all data flows, which DataOps teams can analyze to use. - Use Extensible Tools for Internal Connection
Modern pipelines are built on a number of frameworks and tools that connect and interact. Inbuilt integration tools should be used to reduce time, labor, and cost to build connections between the various systems in the pipeline. - Invest in Proper Data Arguments
Because inconsistencies often lead to poor data quality, it is recommended that the pipeline use appropriate data dismissal tools to resolve disagreements in different data companies. With clean data, DataOps teams can gather accurate data to make effective decisions. - Enable Data Entry Installation and Identity
It is important to maintain the log of the data source, the business process that owns the database, and the user or process that accesses those databases. This provides complete visibility of data sets to use, which strengthens data quality reliability and authenticity.
Conclusion
Gartner predicts that the value of automation will continue to rise so much that, “By 2025, more than 90% of businesses will have an automation designer.” In addition, Gartner stated that “by 2024, organizations will reduce operating costs by 30% by combining hyper-automation technology with redesigned operating systems.”
In the end, let’s recap what we have learned, from What is
- Data Pipeline to how it is used in industry to get the continuous flow of data,
- Data Pipeline Infrastructure which includes Import/Export, Transformation, scanning, and Processing
- an advantage like It Service Development, Increase Application visibility & Improved production and key Components, we have seen it all in detail.
This is all you need in order to get started working and Building a Data Pipeline.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Data Analyst who love to drive insights by visualizing the data and extracting the knowledge from it. Automating various tasks using python & builds Real time Dashboard's using tech like React and node.js. Capable of Creaking complex SQL queries to fetch the accurate data.






