This article was published as a part of the Data Science Blogathon.
.png)
Introduction to ETL
ETL is a type of three-step data integration: Extraction, Transformation, Load are processing, used to combine data from multiple sources. It is commonly used to build Big Data. In this process, data is pulled (extracted) from a source system, to move into a format that can be analyzed, and stored in a warehouse or other system. Extract, Load, Transform (ELT) is an alternative, albeit related, an approach designed to push processing to the database to improve performance.,
In this guide we will cover the good practices of ETL implementation, using the Datastream Implemented through the Apache Airflow platform.
Table of Contents
- What is ETL?
- ETL History
- Some ETL Advantages
- Apache Airflow
- How to Install Apache Airflow
- Airflow Config
- Airflow DAG
- Airflow Run
- Airflow Alternative
- Conclusion
- References
What is ETL?
We can understand ETL (Extract, Transform, Load), as a pipeline process, from Data Engineering. As a set of processes, which precede the creation of Big Data. We use ELT with a tool to integrate different data sources: databases, Spreadsheets, Video Files, audio, and others. During this process, data is extracted from a data source, converted into a format that can be analyzed, and stored in a Big Data system, for future modelling by Machine Learning tools.
used to combine data from multiple sources. It is commonly used to build a data warehouse. In this process, data is pulled (extracted) from a source system, converted into a format that can be analyzed, and stored in a warehouse or other system. Extract, Load, Transform (ELT) is an alternative, albeit related, approach designed to push processing to the database to improve performance.
ETL History
The use of ETL started in the 70s when companies started using multiple repositories or databases to store different types of business information. The need to integrate the data that spread across databases grows up fast. The adoption of ETL has become a process of extracting data from different sources to move it, before loading it into a Data Warehouse or Big Data.
In the early 1990s, data warehouses had an explosion. As a different database model, they provided integrated access to data from multiple systems – mainframe computers, minicomputers, personal computers, and spreadsheets. But different departments often use different ETL tools with different warehouses. Add that to mergers and acquisitions, and many companies end up with separate ETL solutions that haven’t been integrated.
Currently, access to data has grown exponentially, the number of formats, sources, and data systems are almost infinite. ETL is today, a critical process in corporations.
Some ETL Advantages
Multiples corporates adopted the ETL process to gain the data that drive the best business decisions. Today, integrating data from multiple systems and sources is still a feeds of Big Data.
When used with Big Data, ETL provides the complete historical context for companies. Offering a consolidated view:
- ETL makes it easy for business users to analyze and report on data relevant to their initiatives;
- ETL has evolved to support emerging integration requirements for things like streaming data;
- Organizations need both ETL and ELT to merge data, maintain accuracy, and provide the controller of stored data, create reports, and perform analytics.
Apache Airflow: a Workflow Management Platform

https://airflow.apache.org
Airflow is a platform created by the community to programmatically author, schedule and monitor workflows.
Airflow Principles:
- Scalable
- Dynamic
- Extensive
- Elegant
Airflow Features:
- Pure Python
- Useful UI
- Robust Integrations
- Open Source
Some Integrations:
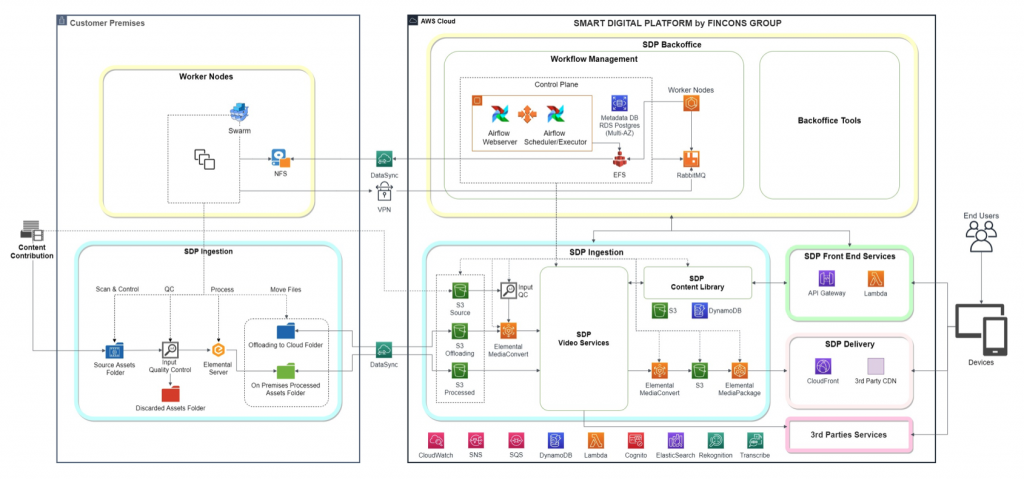
https://aws.amazon.com/pt/blogs/media/managing-hybrid-video-processing-workflows-with-apache-airflow/
How to Install Apache Airflow
Airflow Installation and Setup
1. Inside the example directory create the airflow directory.
2. Navigate to the airflow directory and create the dags directory.
3. Download the image and run the Apache Airflow object in Docker
3rd. If you are using Windows open the Shell Terminal run the command:
docker run -d -p 8080:8080 -v "$PWD/airflow/dags:/opt/airflow/dags/" --entrypoint=/bin/bash --name airflow apache/airflow:2.1.1-python3. 8 -c '(airflow db init && airflow users create --username admin --password bootcamp --firstname Andre --lastname Lastname --role Admin --email [email protected]); airflow webserver & airflow scheduler
3b. Install the necessary libraries for the environment:
Run the command below to connect to the airflow container:
docker container exec -it airflow bash
Then install the libraries:
pip install pymysql xlrd openpyxl minio
3c. If there is no error, access the Apache Airflow user interface the address (*Wait about 5 minutes before opening the terminal):
https://localhost:8080
Airflow Config
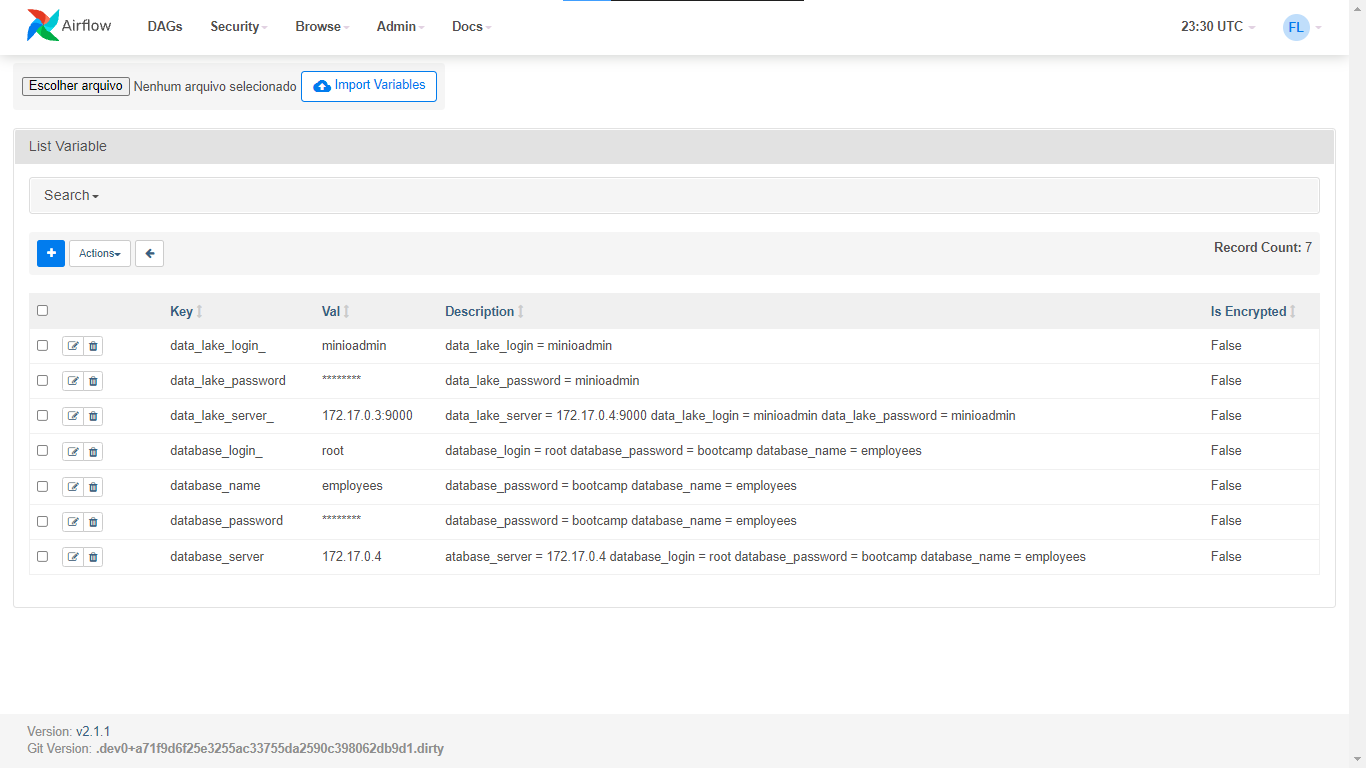
Create the following variables:
data_lake_server = 172.17.0.4:9001 data_lake_login = minioadmin data_lake_password = minioadmin database_server = 172.17.0.2 database_login = root database_password = bootcamp database_name = employees
Airflow Login
Airflow – Demo
Airflow Variables Setup
Airflow Config

Airflow – Demo

Airflow – Demo
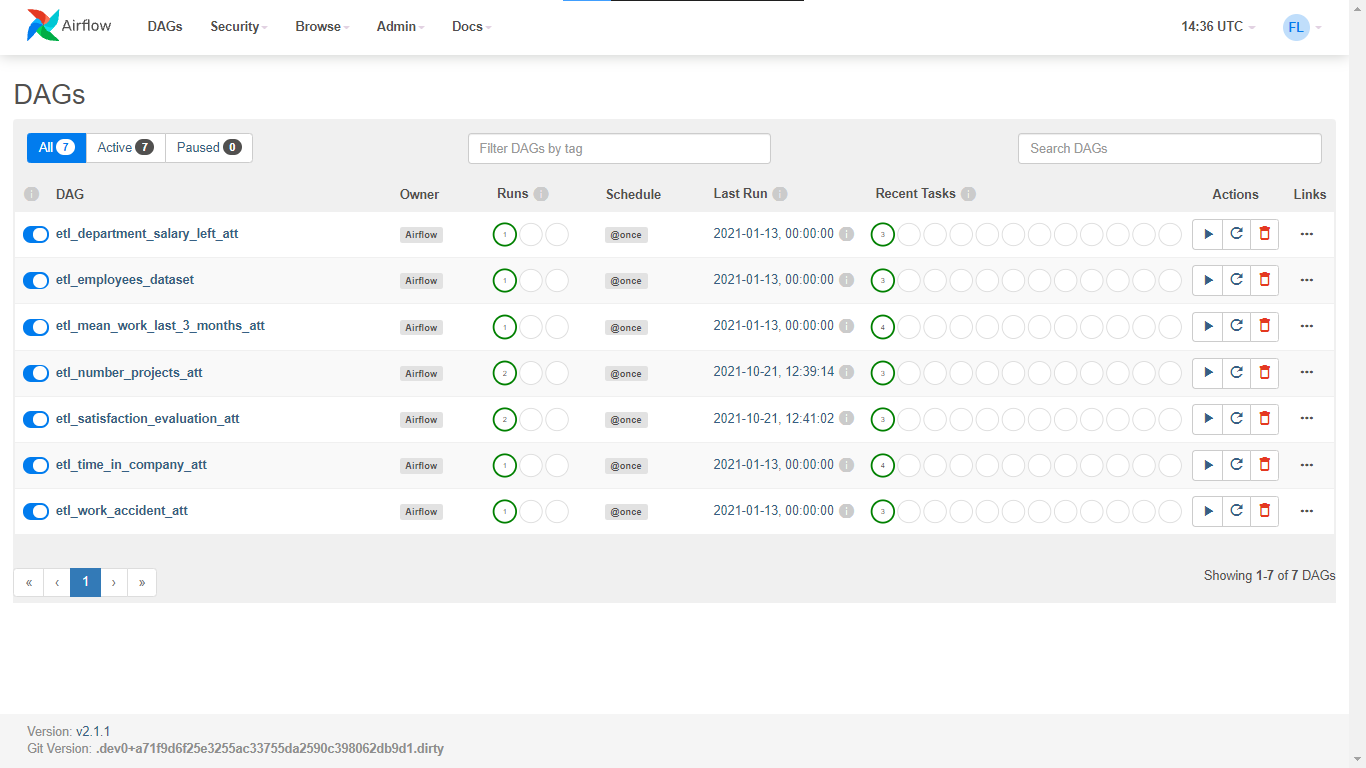
Airflow DAG
DAGs
A DAG (Directed Acyclic Graph) is the core concept of Airflow, collecting Tasks together, organized with dependencies and relationships to say how they should run.
Airflow – Demo
DAG Python Code Example
from datetime import datetime, date, timedelta
import pandas as pd
from io import BytesIO
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from airflow.operators.bash import BashOperator
from airflow.models import Variable
from minio import Minio
from sqlalchemy.engine import create_engine
DEFAULT_ARGS = {
'owner': 'Airflow',
'depends_on_past': False,
'start_date': datetime(2021, 1, 13),
}
dag = DAG('etl_department_salary_left_att',
default_args=DEFAULT_ARGS,
schedule_interval="@once"
)
data_lake_server = Variable.get("data_lake_server")
data_lake_login = Variable.get("data_lake_login")
data_lake_password = Variable.get("data_lake_password")
database_server = Variable.get("database_server")
database_login = Variable.get("database_login")
database_password = Variable.get("database_password")
database_name = Variable.get("database_name")
url_connection = "mysql+pymysql://{}:{}@{}/{}".format(
str(database_login), str(database_password), str(
database_server), str(database_name)
)
engine = create_engine(url_connection)
client = Minio(
data_lake_server,
access_key=data_lake_login,
secret_key=data_lake_password,
secure=False
)
def extract():
# query para consultar os dados.
query = """SELECT emp.department as department,sal.salary as salary, emp.left
FROM employees emp
INNER JOIN salaries sal
ON emp.emp_no = sal.emp_id;"""
df_ = pd.read_sql_query(query, engine)
# persiste os arquivos na área de Staging.
df_.to_csv("/tmp/department_salary_left.csv", index=False
)
def load():
# carrega os dados a partir da área de staging.
df_ = pd.read_csv("/tmp/department_salary_left.csv")
# converte os dados para o formato parquet.
df_.to_parquet(
"/tmp/department_salary_left.parquet", index=False
)
# carrega os dados para o Data Lake.
client.fput_object(
"processing",
"department_salary_left.parquet",
"/tmp/department_salary_left.parquet"
)
extract_task = PythonOperator(
task_id='extract_data_from_database',
provide_context=True,
python_callable=extract,
dag=dag
)
load_task = PythonOperator(
task_id='load_file_to_data_lake',
provide_context=True,
python_callable=load,
dag=dag
)
clean_task = BashOperator(
task_id="clean_files_on_staging",
bash_command="rm -f /tmp/*.csv;rm -f /tmp/*.json;rm -f /tmp/*.parquet;",
dag=dag
)
extract_task >> load_task >> clean_task
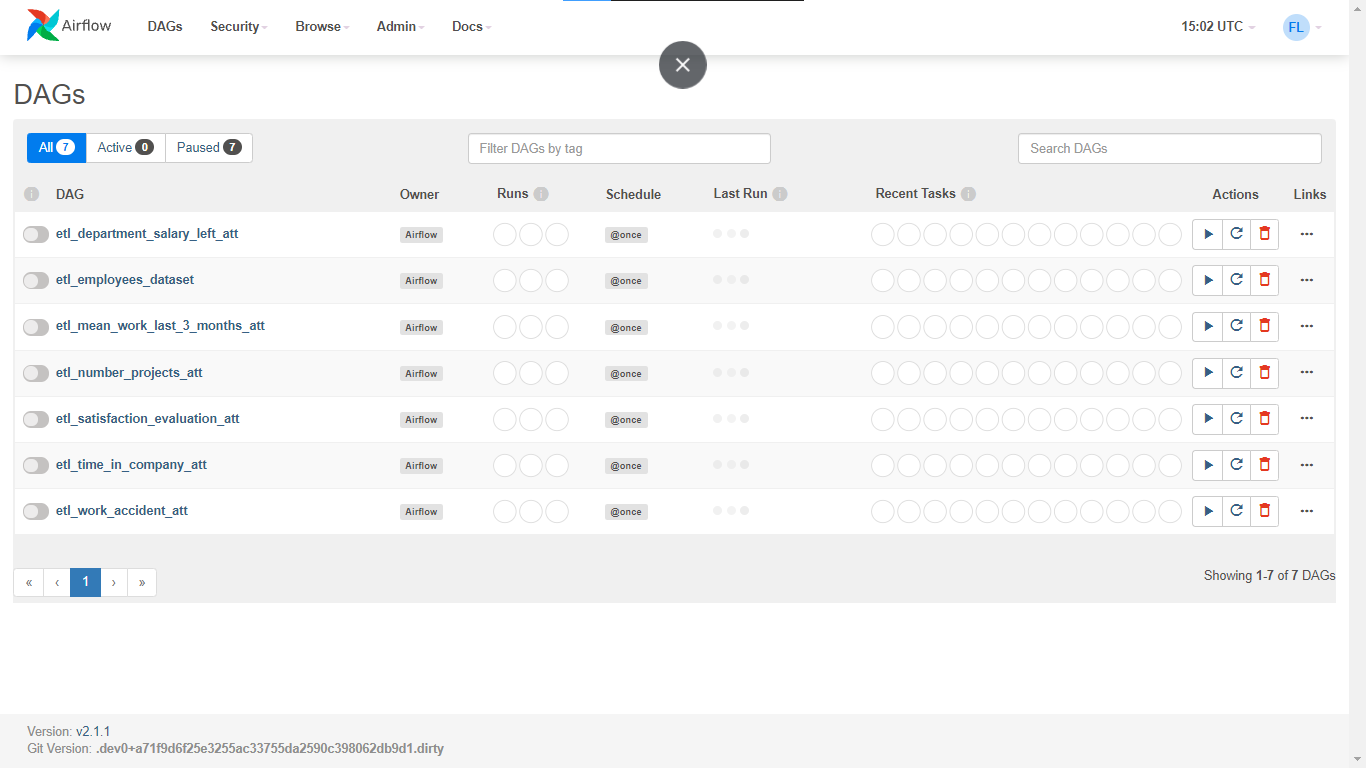
Airflow Run
Airflow – Demo
Airflow – Demo
Airflow Alternative – Stitch
Most associations have data taken care of in a combination of regions, from in-house informational collections to ERP software. To get a full picture of their assets and errands, they move data from that large number of sources into a data dispersion focus or data lake and run assessments against it. In any case, they would prefer not to shape and stay aware of their data pipelines.
Luckily, it’s not important to code everything in-house. Here is a correlation of two such instruments, straight on.
About Apache Airflow
Apache Airflow is an open-source project that allows designers to organize work processes to extricate, change, burden, and store information.
Connectors: Data sources and objections
In a digital technology ecosystem, several devices contain a great diversity of data and objects, stored in object storage, which can be defined as a Data Lake, and a set of these constitute Big Data.
Conclusion
We can use Apache Airflow, as a workflow tool for managing Big Data Streaming, with the ability to integrate with different environments. Through best practices in ETL, we will be able to focus on the development of Machine Learning algorithms that will generate insights and business predictions.
References
- https://hdsr.mitpress.mit.edu/pub/da99kl2q/release/2
- https://hdsr.mitpress.mit.edu/pub/4vlrf0x2/release/1
- https://link.springer.com/article/10.1057/jma.2015.5
- https://link.springer.com/article/10.1057/jma.2015.5
- https://airflow.apache.org/docs/
- https://towardsdatascience.com/python-etl-tools-best-8-options-5ef731e70b49
Author Reference:
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion






