This article was published as a part of the Data Science Blogathon.
Introduction
Almost every one of us nowadays is using YouTube, and it turned out to be fascinating to know how YouTube recommends videos in the same genre/type that we watched a day ago, an hour ago, or a minute ago. In the backend, that is what the recommendation system does in its tasks to recommend the video based on user preferences.
In this article, we will be building the recommendation system using PySpark’s MLIB library. Many resources are available for building recommendation engines using various machine learning algorithms. Still, here, we will explore how easy and convenient it is to build the same using PySpark’s MLIB.
We are using a famous movie lens dataset, and following up will build the suggestion engine that helps users to choose a movie based on their fellow viewers.
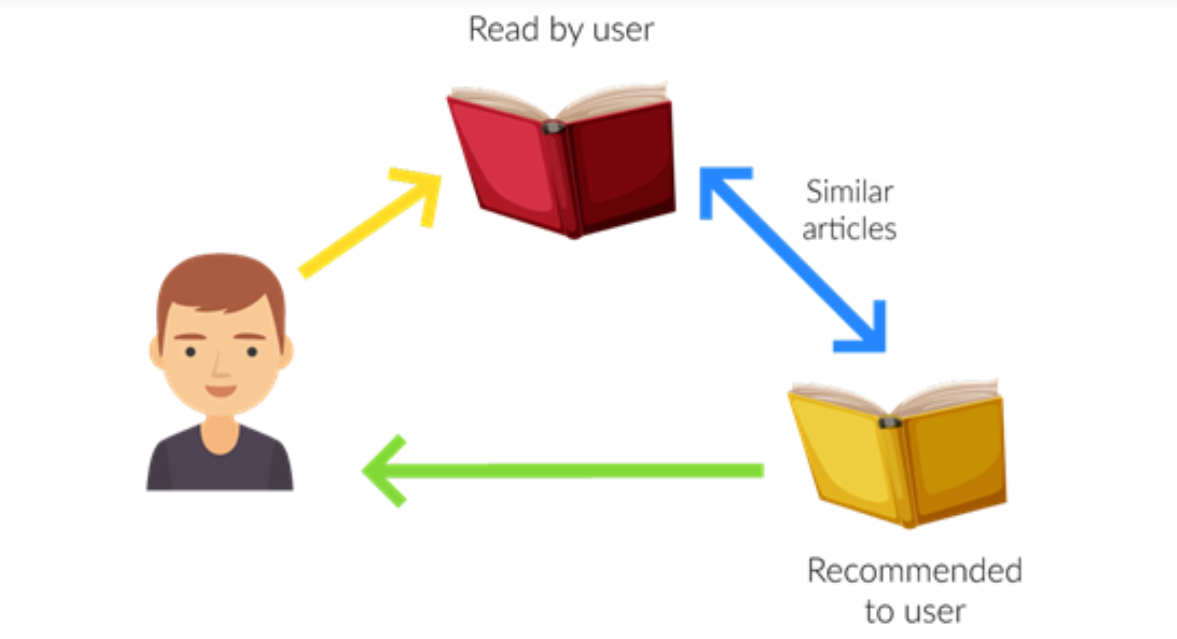
Type of Recommendation System
Before moving to the implementation part of building such an engine, we need to know the type of it so that it would be easier to spot the difference between such systems.
We have two types of recommendation systems:
- Content-Based Filtering: This type of filtering involves tangible items as it filters the content based on the user preferences, the features of the products, and other relatable items.Let me take an example to simplify: suppose you went to Amazon to buy a mobile phone, and you will see the other options showing the same product features (high or low) at almost the same prices but different mobile phones.
- Collaborative filtering: This is different from content-based as collaborative filtering involves user-to-user recommendations based on previous feedback and choices. That’s why collaborative filtering is widely implemented in the real world, based on previous users.Example: In the Amazon store only, we see the “the items bought together” section it has certainty because of collaborative filtering only.
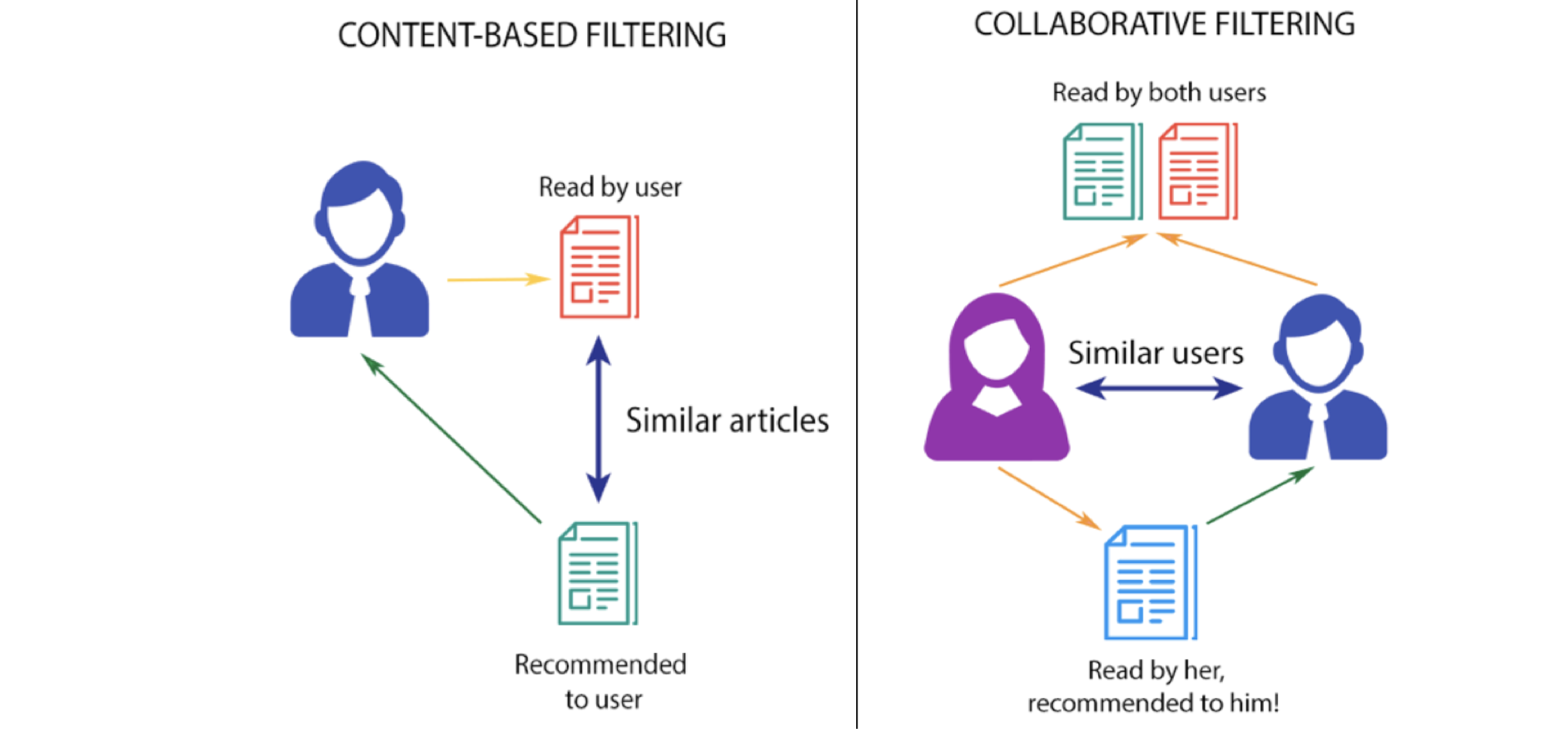
Note: I have put forward the same website example to let you guys know that we need to work with both types of filtering for real-world recommendation engines based on our use case.
About the Dataset
As mentioned above, we are using the famous movie lens dataset. This dataset for building the recommendation engine is similar to using IRIS or MNIST datasets for other machine learning tasks. Let’s have a quick look at the columns of this dataset.
- Movie: This is the unique ID provided to each movie name so that algorithm could track the unique movie (as a real number, not with a name)
- Rating: This column holds the rating given to each film. The highest is 5, and the lowest rating given to films is 1.
- UserID: The unique ID given to each user giving a rating to films.
Now, we are almost done, so let’s get started and build our movie recommendation engine using Spark MLIB.
For getting things ready we are importing the SparkSession module from the pyspark.sql package and this module will provide the base for building and initializing the Spark Session.
from pyspark.sql import SparkSession
spark_rec = SparkSession.builder.appName('recommendation_system').getOrCreate()
spark_rec
Output:
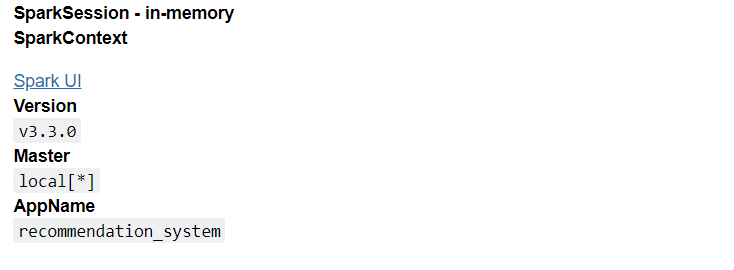
Inference: So first, we imported the SparkSession module, then, with the help of it, we created the Spark Session (tagging the name as “recommendation system“) by using the getOrCreate() function. One can see some specifications of ready-to-service Spark Session-in-memory.
Collaborative Filtering for Recommendation System
As discussed previously, we have two types of filtering here. For our suggestion-based system, we will do hands-on Collaborative filtering; in this type, we predict and draw the choices based on the interests of our fellow users by accessing their feedback and interests.
Here is the GIF from Wikipedia, which will graphically illustrate how collaborative filtering works for better understanding.

PySpark Implementation of Collaborative Filtering
In Spark machine learning, i.e., in MLIB, it has the provision of Collaborative filtering, which is implemented by the Alternate Least Squares method (algorithm). While implementing, we need to be aware of the following parameters, which are responsible for how the model will perform.
- numBlocks: This parameter will define the total number of blocks used to parallelize the computation it is set to -1 for auto-configuration.
- Rank: To maintain the latency, it has several latent factors for the model.
- Iterations: The total number of iterations the algorithm needs to run to the best of its capabilities.
- Lambda: It handles the regularization and specifies the parameter in Alternate Least Square.
- implicitPrefs: It determines whether explicit or implicit feedback will be used.
- Alpha: This parameter implies dealing with the baseline confidence of the implicit feedback observations.
Enough of the theory part. Now, let’s do the hands-on building of the recommendation engine.
from pyspark.ml.evaluation import RegressionEvaluator from pyspark.ml.recommendation import ALS
Inference: Here, we are importing two main modules:
- Regression Evaluator: This module helps analyze and evaluate our model. Remember one thing the mathematics behind the recommendation engine is an adaptation of Linear algebra.
- ALS: As discussed, we are working on the concept of ALS to build the model. Hence, it is imported from the recommendation package.
data_rec = spark_rec.read.csv('movielens_ratings.csv',inferSchema=True,header=True)
data_rec.show()
Output:
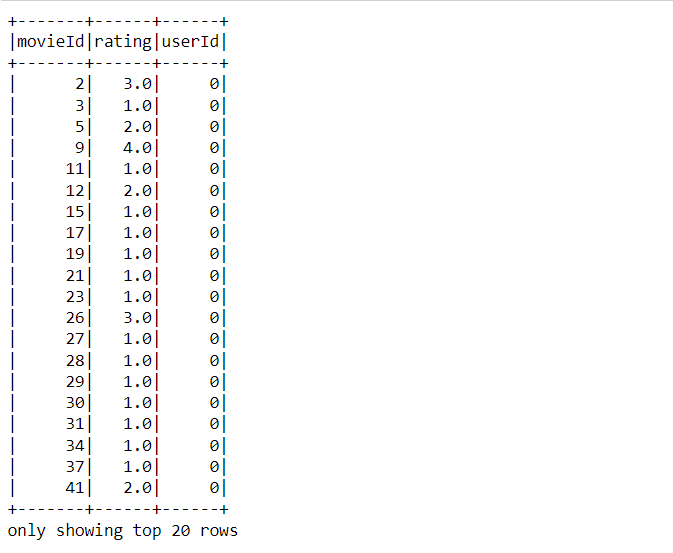
Inference: Now, we are reading the movie lens dataset by using PySpark’s read.csv function, keeping the inferSchema and header tagged as True. In the output section, one can see the top 20 rows of this particular dataset.
data_rec.head(5)
Output:
[Row(movieId=2, rating=3.0, userId=0), Row(movieId=3, rating=1.0, userId=0), Row(movieId=5, rating=2.0, userId=0), Row(movieId=9, rating=4.0, userId=0), Row(movieId=11, rating=1.0, userId=0)]
Inference: Head method is just another way to look closely at the dataset as it returns the Row object, which holds the values and subsequent column names.
data_rec.describe().show()
Output:
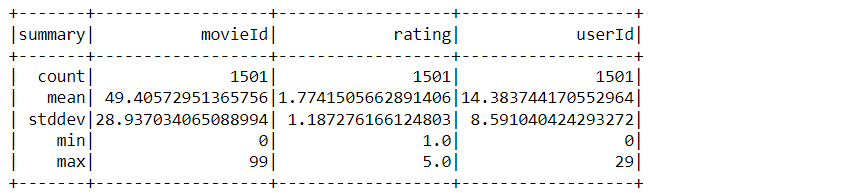
Inference: Describe function is quite informative when getting the statistical information about the dataset. For example, we can see the maximum and minimum rating, the total count of records, and other statistical measures like mean and standard deviation.
Train Test Split for Recommendation System
This is an important step in any machine learning pipeline development which eventually splits the dataset into training and testing sets to see how our model will perform in the case of unseen data.
While doing the same when building a recommendation system, we need to keep one thing in our mind that many times conclusively it is hard to determine how the system will perform in some topics, mainly when it is subjective.
(training, test) = data_rec.randomSplit([0.8, 0.2])
Inference: With tuple unpacking, we are holding the training and testing data by splitting it using the random split method into 80% and 20%, respectively.
Note: We have a smaller dataset; hence we are taking more percentage of data as the training set.
Model Building in Recommendation System
So we are in the model building phase where we will use the Alternate Least Squares method as an algorithm to build the system. Note that we have to deal with multiple parameters previously discussed.
Let’s build the model now!
als = ALS(maxIter=5, regParam=0.01, userCol="userId", itemCol="movieId", ratingCol="rating") model = als.fit(training)
Inference: Firstly, the ALS object is initiated, and we also provided relevant parameters and their values to start the model building phase. Then, the fit method is used on the training data.
Now, let’s evaluate the model that we just trained above!
predictions = model.transform(test)
Inference: As the recommendation system is built on top of linear algebra hence Root Mean Square Error i.e., RMSE, will be the right choice to evaluate the model, and for that, we will use the transform method.
predictions.show()
Output:
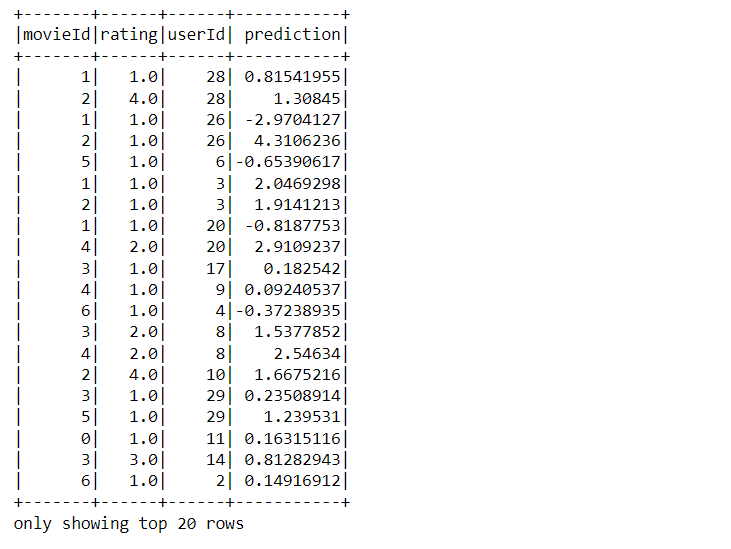
Inference: Now, one can see the new column populated as “prediction,” which will eventually tell us about what rating our model predicted for a specific movie ID.
evaluator = RegressionEvaluator(metricName="rmse", labelCol="rating",predictionCol="prediction")
rmse = evaluator.evaluate(predictions)
print("Root-mean-square error = " + str(rmse))
Output:
Root-mean-square error = 1.577312369917389
Inference: Here, we learned how our model has performed by looking at the RMSE value. Which was attained by the RegressionEvaluator object and specifying the metric name as RMSE and other mandatory parameters.
Note: The RMSE value describes the errors we will supposed to get compared to the actual results.
Conclusion
Here comes the last part of the article, where we will discuss everything we have done by far in this article, i.e., importing the relevant libraries to evaluate the model built to predict the movie rating.
- First, we started with theoretical knowledge about the recommendation engines, imported and loaded the PySpark relevant libraries, and then read the movie lens dataset.
- Then we learned how to implement the collaborative filtering using PySpark later, for transformation stuff, we split the dataset into training and testing sets.
- In the last step, we carry forward with the model building phase, and later for evaluation purposes, we evaluated the model using RMSE metrics.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Aman Preet Gulati
02 Sep, 2022







