This article was published as a part of the Data Science Blogathon.
Introduction
This article will discuss some data science interview questions and their answers to help you fare well in job interviews. These are data science interview questions and are based on data science topics. Though some of the questions may sound basic, these are frequently asked in interviews. Most candidates overlook them and won’t focus on the basics, and they face rejection in job interviews. It is important to start learning the basics to nail the data science job interviews. The following data science interview questions are your guide to performing well in data science job interviews.

Source: SEEK
Frequently Asked Data Science Interview Questions
Q1: Elaborate on the differences between Data Science and Data Analytics.
Firstly data analytics is a part of data science. Multiple things come under data science, like data mining, data analytics, data visualization, and many more.
There are also differences in the programming languages used to implement. Data analytics uses only basic programming languages like python or R. To deal with databases, it uses SQL(structured query language). Data science uses advanced programming languages like java, Julia, Scala, C, C++, Java Script, Python, and R.
The job of a data analyst is to find the solution to the current problem. At the same time, the job of a data scientist is to find the solution to the present problem and predict the future by taking inputs from the past.
Q2: Explain the Confusion matrix.
A confusion matrix is used to know how well the model is performed.
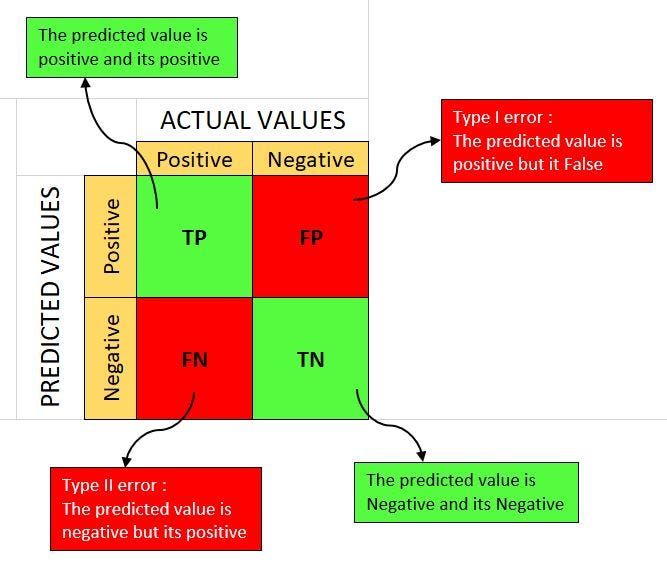
Source: medium
If the predicted value is positive and the actual result is also positive, then the model will perform well (True positive).
If the predicted value is positive and the actual result is negative, then the model is not performing well (False positive)- Type I error.
If the predicted value is negative and the actual result is also negative, then the model will perform well (True negative).
If the predicted value is negative and the actual result is positive, then the model is not performing well (False negative)- Type II error.
The formula knows the accuracy of the model
(True Positive + True Negative) / Total Observations
let us say true positive observations are 5 and true negative observations are 4, out of total observations 10, then the accuracy of the model is (5+4)/10=9/10=0.9
It is 90% accurate.
Q3:Differentiate between the terms error and residual.
The difference between the observed value and the theoretical value gives the error. The difference between the observed and predicted values gives the residual value.
Error = Observed value - Theoretical value Residual = Observed value - Predicted value
Q4:What are the precautions taken to avoid overfitting our model?
Suppose the model is performing well on the data sets we are using for our training and testing and not on some other data set, then such a model is said to be overfitting.
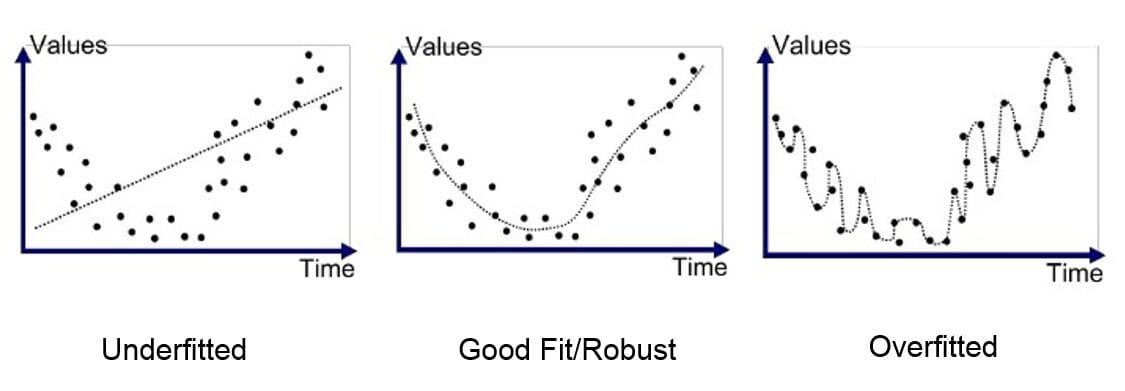
Source: kdnuggets
Precautions-
- Can be avoided by having our model as simple as possible
- Using cross-validation techniques
- Using regularization techniques
- Using feature engineering
Q5: Differentiate between data science and traditional application programming.
In traditional application programming, we need to analyze the input first. To get the expected output, certain code needs to be written on our own, which could be challenging as it is a manual process.
However, in Data Science, the process is entirely different. We need to have data first and divide it into two sets. One is called the testing data, and the other set is called the training data. With the help of training data and data science algorithms, rules are created to map an input to an output. These rules are tested using the testing data set. If the rule succeeds, it is said to be the model.
Q6:Explain bias in Data Science.
Categorically, a model is based on the ability of an algorithm to understand, design, etc. If the algorithm is less effective and cannot conclude from the given data, it leads to a less efficient model, leading to an error. This error is also called bias in data science. Usually, bias occurs when simple algorithms like linear and logistic regression are deployed.
Q7: What do you know about dimensionality reduction?
Some Datasets would have more fields than required. Even after removing some fields, the functionality would remain the same. The process of reducing such fields or dimensions while taking care of the functionality is known as dimensionality reduction.
Q8: Mention the popular libraries used in Data Science.
Some of the popular libraries used in data science are:
- TensorFlow
- SciPy
- Pandas
- Matplotlib
- PyTorch
Q9: Explain the working of a recommendation system.
A recommendation system filters all the videos or movies based on our preferences and watches history. It offers recommendations to the users based on the above two inputs and behaviour models.
A recommendation system is either a program or an algorithm based on watch and search history inputs. It analyses the genre, cast, director, and more to recommend movies to the viewers. That is how the recommendation system works for a product-selling platform like Amazon, Myntra, or Flipkart, or an OTT platform like Netflix, Amazon prime Video, Aha, and so on.
Generally, there are three types of recommendation systems.
1. Demographic filtering
2. Content-based filtering
3. Collaboration-based filtering
Demographic filtering: In this, the recommendations are the same for every user regardless of their interests. For example, let’s take the top trending movies column in OTT platforms. These are the same for every user because of the demographic filtering system.
Content-based filtering: Filterings are based on movie metadata. Metadata contains details like movies, songs, genres, cast stories, etc. Based on this data, the system recommends movies related to that data for user consumption.
Collaboration-based filtering: Here, the system will group users with similar interests and recommend movies to them.
Question 10: Explain the benefit of dimensionality reduction.
Some Datasets would have more fields than required, meaning that even after removing some fields, the functionality would remain the same. The process of reducing such fields or dimensions by taking care of functionality is known as dimensionality reduction.
After reducing fields, it requires less time to process the data and to train the model, and speed is increased compared to data with more dimensions. Also, the accuracy of the model is increased.
Conclusion
Data science is a lucrative career option with ample opportunities across diverse sectors. There is a surge in the number of companies based on Data science like machine learning and artificial intelligence and the career options they offer. This write-up helps us cover some frequently asked and basic data science interview questions and their answers.
Overall in this article, we have seen,
- Some basics of data science and data analytics
- Bias, Error, and Overfitting related topics.
- Questions related to data science.
Hello Everyone,
This is Srivani. I had completed my B.Tech in the computer science department. I am interested in Data Science and programming. Thanks for reading my articles and hope you get knowledge from them.






