This article was published as a part of the Data Science Blogathon.
Introduction
Various contemporary computer science and machine learning applications use multidimensional datasets encompassing a single expansive coordinate system. Two examples are utilizing air measurements over a geographical grid to predict the weather or making medical imaging predictions using multi-channel image intensity values from a 2D or 3D scan. These datasets can be difficult because users may receive and write data at unpredictable intervals and on varied scales. They frequently want to run studies on several workstations simultaneously. Under these conditions, even a single dataset might require petabytes of storage.
In light of this, Google AI has introduced TensorStore, an open-source Python and C++ software library designed to store and manipulate n-dimensional data.
TensorStore
As we briefly discussed in the Introduction section, TensorStore is an open-source Python and C++ software library designed to store and manipulate n-dimensional data. Numerous storage systems, including local and network filesystems, Google Cloud Storage, etc., are supported by this module. It provides a uniform API that can read and write various array types. The library offers read/writeback caching, transactions, robust atomicity, isolation, consistency, and durability (ACID) guarantee. Optimistic concurrency ensures secure access to various programs and systems.
Safe and Performant Scaling
Large numerical datasets require extensive processing power to process and analyze. Typically, this is done by parallelizing activities among numerous CPU or accelerator cores dispersed across multiple devices. TensorStore’s primary objective has been to make it possible for individual datasets to be processed in parallel in a way that is both secure (i.e., prevents corruption or inconsistencies caused by parallel access patterns) and performant (i.e., reading and writing to TensorStore is not a bottleneck during computation). In fact, in a test conducted within Google’s data centers, it was noted that nearly linear scaling of reading and write performance as the number of CPUs was raised:
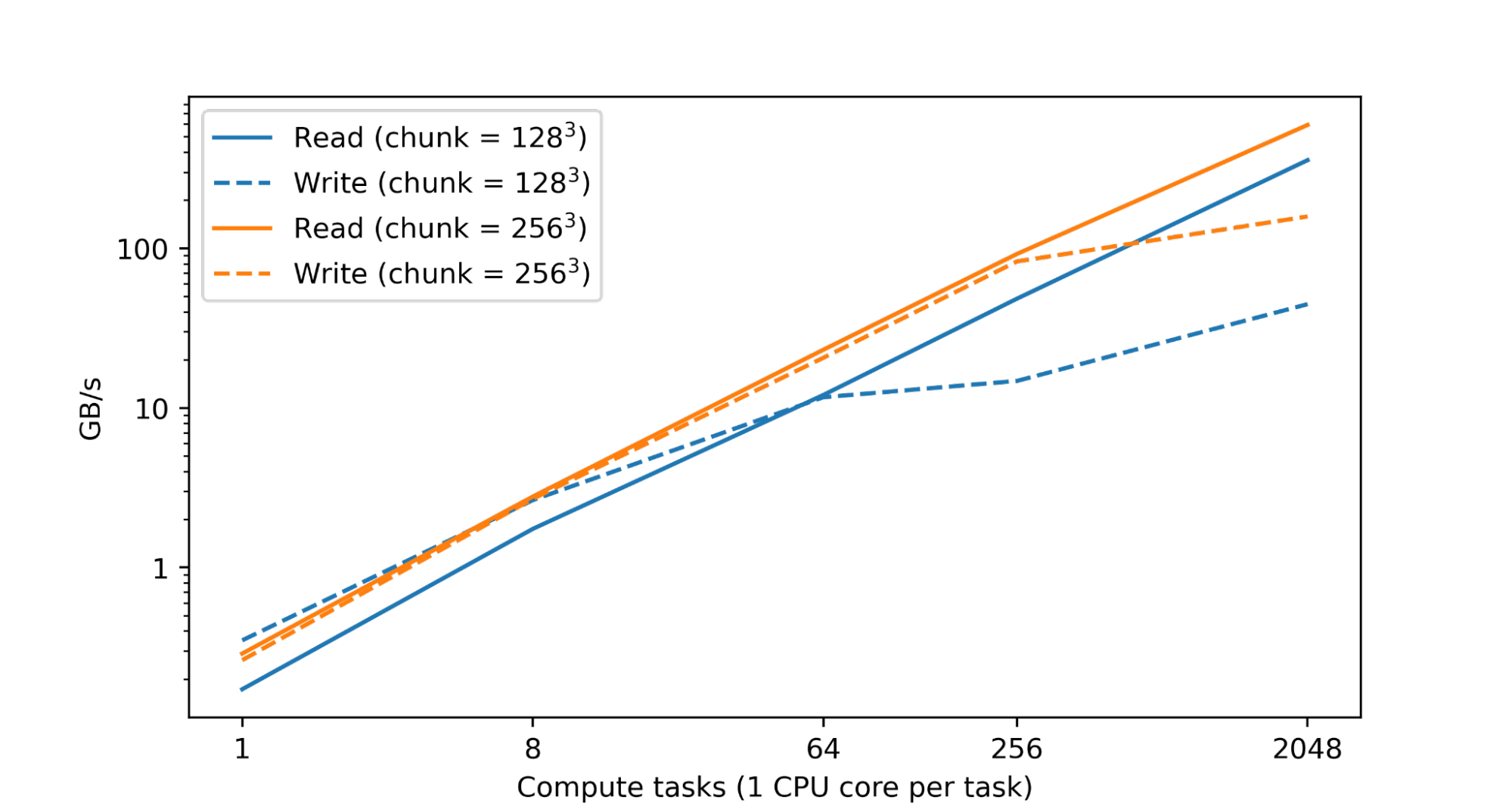
Fig 1: Read/write performance for a TensorStore dataset in Zarr format located on Google Cloud Storage (GCS)
Performance is achieved by implementing fundamental operations in C++, heavily utilizing multithreading for tasks like encoding/decoding and network I/O, and chunking enormous datasets to quickly read and write portions of the full dataset. TensorStore also has an asynchronous API that lets a read or writes operation continue in the background. At the same time, a program completes other tasks, as well as customizable in-memory caching (which reduces slower storage system interactions for the data which is often accessed).
Optimistic concurrency, which maintains compatibility with various underlying storage layers (including Cloud storage platforms, such as GCS, as well as local filesystems), the safety of the parallel operations is achieved when multiple machines are accessing the same dataset. This is done without significantly affecting performance. TensorStore further offers strong ACID guarantees for each action running within a single runtime.
Additionally, researchers combined TensorStore with parallel computing frameworks like Apache Beam (sample code) and Dask to make distributed computing with TensorStore compatible with many already used data processing workflows (example code).
Use Case 1: Language Models
Introducing more complex language models, like PaLM, is an exciting new advancement in machine learning. These neural networks display excellent natural language processing and generation abilities with hundreds of billions of parameters. These models also strain available computational resources; for example, training a language model like PaLM necessitates thousands of concurrent TPUs.

One challenge during this training process is reading and writing the model parameters efficiently. Although training is spread across numerous machines, parameters must be periodically recorded to a single object (referred to as a “checkpoint”) on a permanent storage system without slowing down the training process. Individual training jobs must be able to read the specific set of parameters they are concerned with to eliminate the overhead required to load the whole set of model parameters (which could be 100s of gigabytes).
These issues have already been addressed using TensorStore. It has been integrated with frameworks like T5X and Pathways and has been used to handle checkpoints connected to large-scale (“multipod“) models trained with JAX (code sample). The entire set of parameters, which can take up more than a terabyte of memory, is divided among hundreds of TPUs using model parallelism. TensorStore stores checkpoints in Zarr format, with a chunk structure that enables independent parallel reading and writing of the partition for each TPU.
Use Case 2: 3D Brain Mapping
Synapse-resolution connectomics aims to trace the intricate network of individual synapses in animal and human brains. This calls for petabyte-sized datasets to be produced by imaging the brain at extremely high resolution (nanometers) over fields of view of up to millimeters or more. These databases could eventually reach exabyte size as scientists consider mapping complete mouse or monkey brains. In contrast, even a single brain sample may require millions of gigabytes with a coordinate system (pixel space) of hundreds of thousands of pixels in each dimension, posing major storage, manipulation, and processing issues.
The researchers used TensorStore to overcome the computational difficulties presented by large-scale connectomic datasets. Using Google Cloud Storage as the underlying object storage technology, TensorStore has managed some of the largest and most popular connectomic datasets. It has been used, for instance, to analyze the human cortex “h01” dataset, which is a three-dimensional image of brain tissue with a nanometer-level resolution. The raw image data, which is 1.4 petabytes in size (or around 500,000 * 350,000 * 5,000 pixels), is also coupled with other content, such as 3D segmentations and annotations, which are stored in the same coordinate system. The “Neuroglancer precomputed” format, ideal for web-based interactive viewing and readily manipulable from TensorStore, is used to store the raw data, which is separated into discrete chunks 128x128x16 pixels in size.
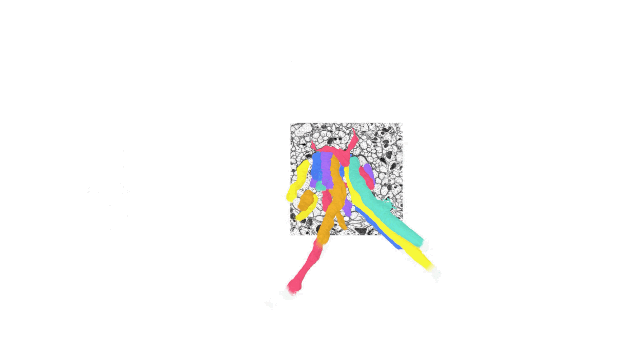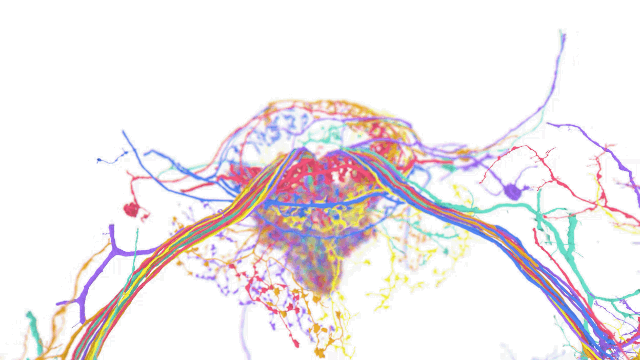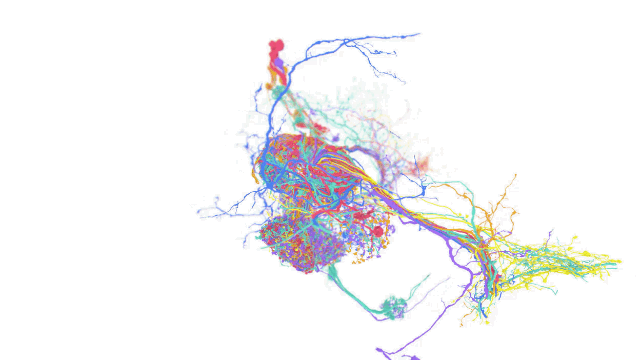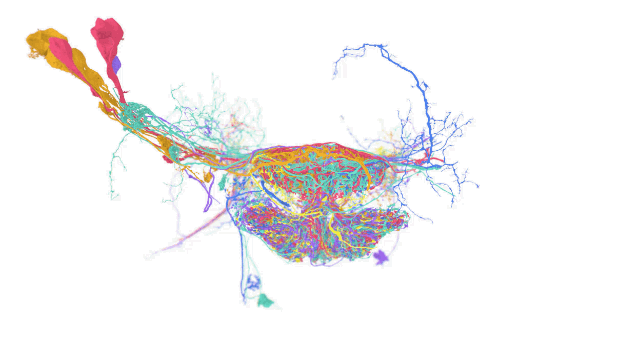
A fly brain reconstruction with freely accessible and manipulatable underlying data using TensorStore (Source: Google AI)
Conclusion
To summarize, in this article, we learned that the TensorStore, an open-source C++ and Python software library, is designed for storage and manipulation of n-dimensional data that:
- Enables the reading and writing of numerous array formats, such as Zarr and N5, using a unified API.
- Natively supports multiple storage systems, including local and network filesystems, Google Cloud Storage, HTTP servers, and in-memory storage.
- Supports read/writeback caching and transactions with consistency, strong atomicity, isolation, and durability (ACID) guarantees.
- Supports efficient and safe access from multiple processes and machines via optimistic concurrency.
- An asynchronous API provides high-throughput access to external storage even with high latency.
- Provides fully composable and advanced indexing operations and virtual views.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I'm a Researcher who works primarily on various Acoustic DL, NLP, and RL tasks. Here, my writing predominantly revolves around topics related to Acoustic DL, NLP, and RL, as well as new emerging technologies. In addition to all of this, I also contribute to open-source projects @Hugging Face.
For work-related queries please contact: [email protected]






