This article was published as a part of the Data Science Blogathon.
Introduction
A deep learning task typically entails analyzing an image, text, or table of data (cross-sectional and time-series) to produce a number, label, additional text, additional images, or a mix of these. Simple examples include:
- Identifying a dog or cat in a picture.
- Guess the word that will come next in a sentence.
- Creating captions for images.
- Changing the style of a picture (like the Prisma app on iOS/Android).
The underlying data would have to be kept in a particular structure for each job. There will be various intermediate steps in processing and creating these answers, and each one will require a specific system (for example, the weights of a neural network). A tensor can be a generic structure that can be used for storing, representing, and changing data.
Tensors are the fundamental data structure used by all machine and deep learning algorithms. The term “TensorFlow” was given to Google’s TensorFlow because tensors are essential to the discipline.
What is a Tensor?
A tensor is just a container for data, typically numerical data. It is, therefore, a container for numbers. Tensors are a generalization of matrices to any number of dimensions. You may already be familiar with matrices, which are 2D tensors (note that in the context of tensors, a dimension is often called an axis).
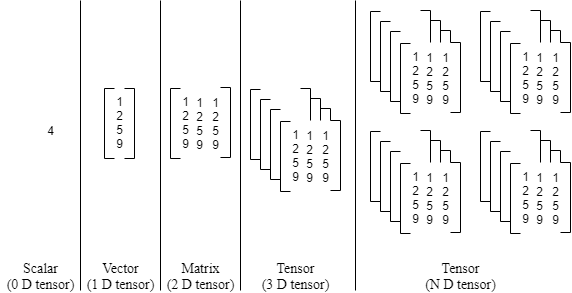
Figure: Different types of Tensors
A scalar, vector, and matrix can all be represented as tensors in a more generalized fashion. An n-dimensional matrix serves as the definition of a tensor. A scalar is a zero-dimensional tensor (i.e., a single number), a vector is a one-dimensional tensor, a matrix is a two-dimensional tensor, a cube is a three-dimensional tensor, etc. The rank of a tensor is another name for a matrix’s dimension.
Let’s start by looking at the various tensor construction methods. The simplest method is to create a tensor in Python via lists. The experiment that follows will show a variety of tensor functions that are frequently employed in creating deep learning applications. The codes and outputs were kept in the Notebook format to make it easier for you to follow the flow.
- Scalars (0 D tensors): The term “scalar” (also known as “scalar-tensor,” “0-dimensional tensor,” or “0D tensor”) refers to a tensor that only holds a single number. A float32 or float64 number is referred to as a scalar-tensor (or scalar array) in Numpy. The “ndim” feature of a Numpy tensor can be used to indicate the number of axes; a scalar-tensor has no axes (ndim == 0). A tensor’s rank is another name for the number of its axes. Here is a Scalar in Numpy:
>>> import numpy as np>>> x = np.array(10)>>> xarray(10)>>> x.ndim0
2. Vectors (1 D tensors):
A vector, often known as a 1D tensor, is a collection of numbers. It is claimed that a 1D tensor has just one axis. A Numpy vector can be written as:
>>> x = np.array([12, 3, 6, 14, 8])>>> xarray([12, 3, 6, 14, 8])>>> x.ndim1
This vector is referred to as a 5D vector since it has five elements. A 5D tensor is not the same as a 5D vector. A 5D tensor will have five axes, whereas a 5D vector has just only one axis and five dimensions along it (and may have any number of dimensions along each axis). Dimensionality can refer to the number of axes in a tensor, such as a 5D tensor, or the number of entries along a particular axis, as in the case of our 5D vector. Although using the ambiguous notation 5D tensor is widespread, using a tensor of rank 5 (the rank of a tensor being the number of axes) is mathematically more accurate in the latter situation.
3. Matrices (2D tensors): A matrix, or 2D tensor, is a collection of vectors. Two axes constitute a matrix (often referred to as rows and columns). A matrix can be visualized as a square box of numbers. The NumPy matrix can be written as:
>>> x = np.array([[5, 8, 2, 34, 0],[6, 79, 30, 35, 1],[9, 80, 49, 6, 2]])>>> x.ndim2
Rows and columns are used to describe the elements from the first and second axes. The first row of x in the example is [5, 8, 2, 34, 0], while the first column is [5, 6, 9].
4. 3D tensors or higher dimensional tensors: These matrices can be combined into a new array to create a 3D tensor, which can be seen as a cube of integers. Listed below is a Numpy 3D tensor:
>>> x = np.array([[[5, 8, 20, 34, 0],[6, 7, 3, 5, 1],[7, 80, 4, 36, 2]],[[5, 7, 2, 34, 0],[6, 79, 3, 35, 1],[7, 8, 4, 36, 2]],[[5, 78, 2, 3, 0],[6, 19, 3, 3, 1],[7, 8, 4, 36, 24]]])>>> x.ndim3
A 4D tensor can be produced by stacking 3D tensors in an array, and so on. In deep learning, you typically work with tensors that range from 0 to 4D, though if you’re processing video data, you might go as high as 5D.
Key Attributes:
Three essential characteristics are used to describe tensors:
1. Number of axes (rank): A matrix contains two axes, while a 3D tensor possesses three. In Python libraries like Numpy, this is additionally referred to as the tensor’s ndim.
2. Shape: The number of dimensions the tensor contains across each axis is specified by a tuple of integers. For instance, the 3D tensor example has shape (3, 5) while the prior matrix example has shape (3, 3, 5). A scalar has an empty shape as (), but a vector has a shape with a single element, like (5,).
3. Date type (sometimes abbreviated as “dtype” in Python libraries): The format of the data which makes up the tensor; examples include float32, uint8, float64, and others. A ‘char’ tensor might appear in exceptional cases. Due to the string’s changeable duration and the fact that tensors reside well before shared memory sections, string tensors are not present in Numpy (or in the majority of other libraries).
Real-world examples of data tensors:
With some situations that are representative of what you’ll see later, let’s give data tensors additional context. Nearly all of the time, the data you work with will belong to one of the following groups:
1. Vector data: 2D tensors (samples, features).
2. Sequence or time-series data: 3D tensors of shape (samples, timesteps, characteristics)
3. Images: 4D tensors of shape (samples, height, width, channels) or (samples, channels, height, width)
4. Video: 5D shape tensors of shapes (samples, frames, height, width, channels) or (samples, frames, channels, height, width)
Vector Data:
The most typical scenario is this. A batch of data in a dataset will be stored as a 2D tensor (i.e., an array of vectors), in which the first axis is the samples axis and the second axis is the features axis. Each individual data point in such a dataset is stored as a vector. Let’s focus on two instances:
- A statistical dataset of consumers, where each individual’s age, height, and gender are taken into account. Since each individual may be represented as a vector of three values, the full dataset of 100 individuals can be stored in a 2D tensor of the shape (100, 3).
- A collection of textual information in which each article is represented by the number of times each word occurs in it (out of a dictionary of 2000 common words). A full dataset of 50 articles can be kept in a tensor of shape (50, 2000) since each article can be represented as a vector of 20,00 values (one count per word in the dictionary).
Time series data or sequence data:
It’s imperative to store data in a 3D tensor with an explicit time axis whenever time (or the idea of sequence order) is important. A batch of data will be encoded as a 3D tensor because each instance can be represented as a series of vectors (a 2D tensor).
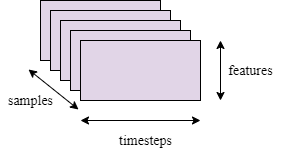
Figure: 3D time-series data tensor
The time axis has always been the second axis (axis of index 1) by convention. Let’s examine a couple of instances:
- A stock price dataset: We keep track of the stock’s current market price as well as its peak and lowest prices from the previous hour. Since there are 390 minutes in a trading day, each minute is encoded as a 3D vector, a trading day may be represented as a 2D tensor of the form (390, 3), and 250 day’s worth of data can be kept in a 3D tensor of shape (250, 390, 3). Each sample, in this case, corresponds to a day’s worth of data.
- Tweets dataset: let’s 300 characters be used to represent each tweet in a dataset of tweets, with a total of 125 different characters in the alphabet. Each character in this scenario can be represented as a binary vector of size 125 that is all zeros with the exception of a single item at the character-specific index. Then, a dataset of 10 million tweets can be kept in a tensor of shape by encoding each tweet as a 2D tensor of shape (300, 125). (10000000, 300, 125).
Image Data:
Height, width, and colour depth are the three dimensions that most images have. By definition, image tensors are always 3D, with a one-dimensional colour channel for grayscale images. Even though grayscale images (like our MNIST digits) only have a single colour channel and may therefore be stored in 2D tensors. Thus, a tensor of shape (32, 64, 64, 1) might be used to save a batch of 32 grayscale photos of size 64 x 64, while a tensor of shape (32, 64, 64, 1) could be used to store a batch of 32 colour images (32, 64, 64, 3).
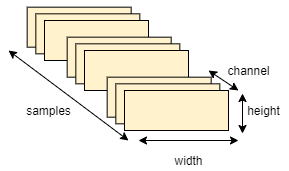
Figure: 4D image data tensor
The channels-last format (used by TensorFlow) and the channels-first format are the two standards for the shapes of image tensors (used by Theano). The colour-depth axis is located at the end of the list of dimensions in the Google TensorFlow: (samples, height, width, colour-depth). The batch axis is placed first, followed by the samples, colour-depth, height, and width axes by Theano. The previous instances would be transformed into (32, 1, 64, 64) and (32, 3, 64, 64). Both file types are supported by the Keras framework.
Video data:
Among the few real-world datasets for which you’ll require 5D tensors is video data. A video could be viewed as a set of coloured images called frames. A batch of various movies can be saved in a 5D tensor of shape (samples, frames, height, width, and colour-depth) since each frame can be kept in a 3D tensor (height, width, and colour-depth). A series of frames can also be saved in a 4D tensor (frames, height, width, and colour-depth).
For instance, 240 frames would be present in a 60-second, 144 x 256 YouTube video clip sampled at 4 frames per second. Four of these video clips would be saved in a tensor shape as a batch (4, 240, 144, 256, 3). There are 106,168,320 values in all. The tensor could store 405 MB if the dtype of the tensor was float32 since each value would be recorded in 32 bits. Heavy! Because they aren’t saved in float32 and are often greatly compressed, videos you see in real life are significantly lighter (such as in the MPEG format).
Conclusion
The “weights” of the input data to the “neurons” in a deep neural network are fundamentally only a group of floating point numbers, along with some techniques for analyzing the signals based on such weights. The input samples cannot be directly seen, heard, or sensed by machine learning or deep learning algorithms. To give the algorithms a relevant perspective on the data’s important characteristics, you must therefore develop a representation of the data. The input data representation is created by analyzing the various data representation techniques. A model can instantaneously find the representations required for feature learning, classification, segmentation, and detection from raw data using a set of algorithms known as feature learning or representation learning. Therefore, the required representations (data representation) must be in a meaningful manner for the algorithms to complete the required downstream tasks (such as classification, segmentation, and detection). The various categories of data distribution have been discussed in this article, which will be useful when working with machine learning or deep learning algorithms.
- This article covers the various data type categories that are used in different machine learning and deep learning algorithms.
- Various forms of data in the real world, along with their basic codes, have been discussed.
- The difference in data type styles in Tensorflow and Theano framework has been studied.
- The use of NumPy for data representation is shown with the help of codes, and also various data visualization has been discussed.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.






