This article was published as a part of the Data Science Blogathon.
Introduction
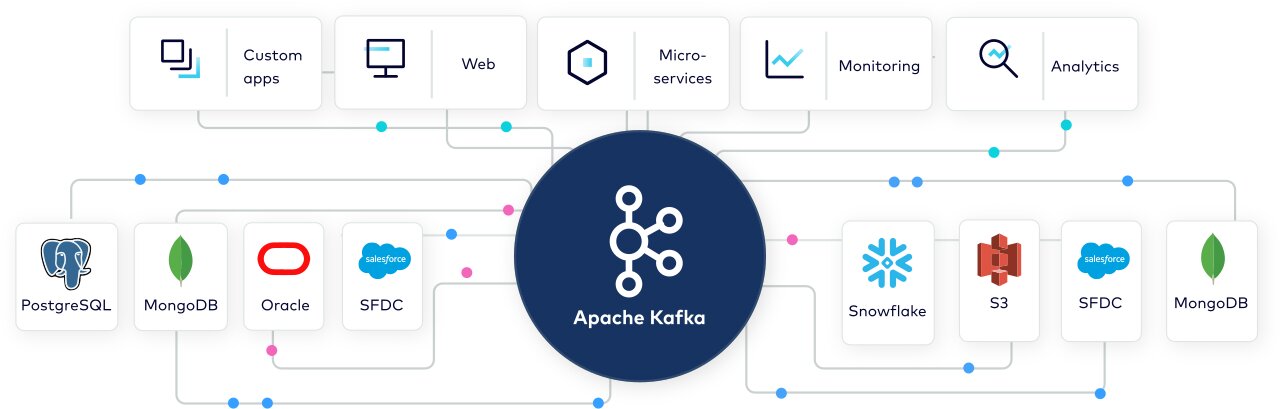
Have you ever wondered how Instagram recommends similar kinds of reels while you are scrolling through your feed or ad recommendations for similar products that you were browsing on Amazon? All these sites use some event streaming tool to monitor user activities. Kafka is one of the most popular events streaming platforms out there.
Big companies like Netflix, LinkedIn, Uber, Walmart, and Airbnb use Kafka for a lot of things. Such as,
- Netflix uses Kafka to provide tv show recommendations in real time.
- Walmart uses Kafka for the real-time inventory management system.
- For Uber’s technology stack, Kafka is considered the cornerstone. It uses Kafka for many things, such as computing the cab fare in real time depending on the demand, destination, and availability of cabs.
Apart from these, many other companies use Kafka for large-scale streaming analysis, log analysis, message brokerage services, etc. A real-time event-driven system is essential when every user activity is valuable and every second has a financial cost.
So, in this article, we will learn about the fundamentals of Apache Kafka and how it works. We will learn how to set up Kafka servers with Zookeeper and KRaft from the terminal and use the Kafka python client library to read and write events to topics.
source: confluent
What is Apache Kafka?
Apache Kafka is a distributed, real-time streaming platform for large-scale data processing. Organizations use Kafka for real-time analytics and building event-driven architectures and streaming pipelines to process data streams.
Brief History
In 2010, a group of engineers at LinkedIn started working on a tool to handle high amounts of data produced daily. In 2011, considering its usefulness, the technology was open-sourced. Jay Kreps, one of the co-creator, named it Kafka after the author Franz Kafka as he liked Kafka’s writings. Later on, in 2012, Kafka graduated from the Apache Incubator.
How does Kafka work?
Kafka has various components like Topics, Producers, Consumers, and Brokers that make Kafka a scalable, fault-tolerant and durable event-streaming platform. So, let us understand how each component works one by one.
Common Definition of Terms
Kafka event
An event is a real-world phenomenon. A Kafka event has an event key, values, time-stamp and optional metadata.
- The event key is specific to an event. It can be a number or string value. For example, if we want to store the GPS data of cabs, we may assign the cab ID to the event key.
- The event value field stores the data we want to write to the topics.
- A timestamp is added to an event
Publish-subscribe messaging
The publish-subscribe messaging is a messaging pattern where the sender sends messages to a destination, and whoever subscribes to that destination receives messages. In this case, the central destination is called the topic.
Event-streaming
Event streaming is an evolution of pub-sub messaging where messages are stored and transformed as they occur, in addition to typical pub-sub capabilities. An event stream is a continuous flow of events from sender to destination.
Kafka Topics and Partitons
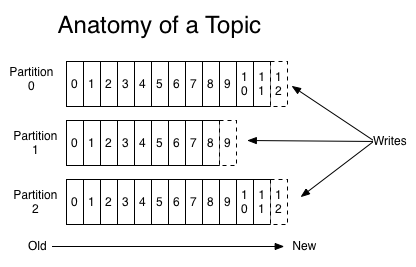
A Kafka topic is similar to a database table and is used to store data. You can create as many topics as you want, such as a “tweets-data” topic to hold tweets data. Topics are partitioned to allow data to be spread across multiple brokers for scalability. Partitions are log files that hold the actual data. A topic can have many partitions, which can also be configured programmatically.
When a new event is published, it gets appended to one of the partitions. Events with the same event key are appended to the same partition. An event key could be a string or a number, for example, a user id. Kafka guarantees the order of events; consumers will read the events in the same order as they were written on that topic.
Every time a message is published on a Topic, an offset is added. An offset is an integer value that identifies a record or event inside a partition. Earlier records will have smaller offsets compared to later ones.
source: Kafka log
Apache Kafka Producers
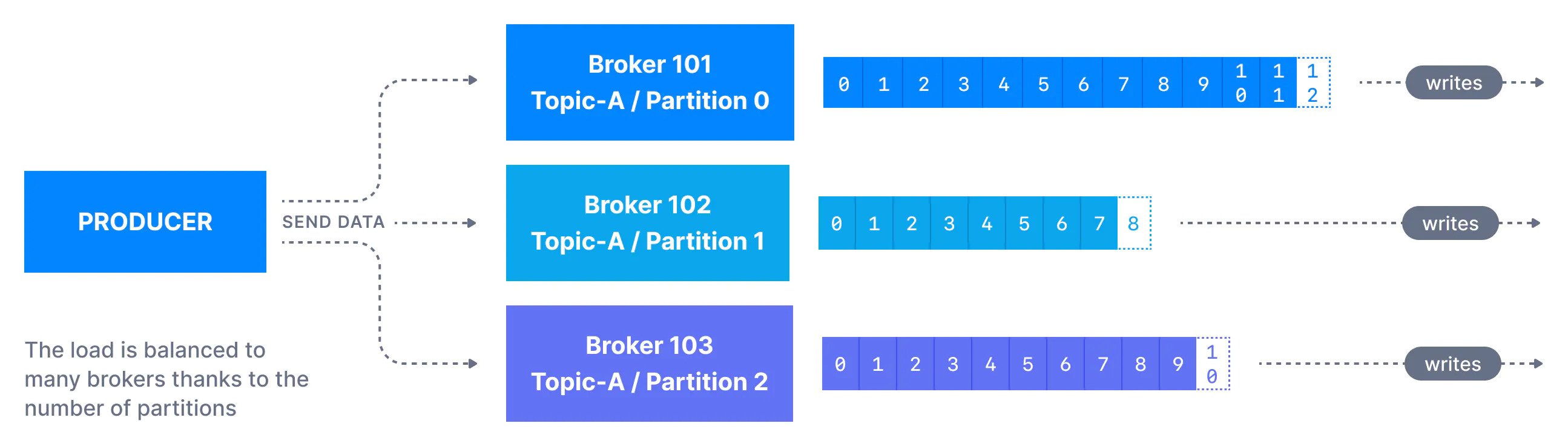
Producers are the applications that send data to Kafka topics. A producer can be any data source, such as Twitter, Reddit, Logs, GPS data etc. A producer client library can assist in ingesting the data from these sources to respective topics.
The records from Applications are written to the partitions. All the messages sharing the same event key are written to the same Kafka partition. If the events lack keys, the messages are written to topics in a round-robin fashion (p0->p1….->p0).
Apache Kafka Consumers
Kafka Consumers are the applications or systems that consume the data from the topics. Applications integrate a Kafka client library to read data from the topics.
To read data from Kafka, consumers first need to subscribe to a topic and then can read from single or multiple partitions. Consumer tracks its progress by using the offset of the last message processed.
The message order is guaranteed if the consumer consumes messages from a single partition. While reading from multiple partitions may not conserve ordering.
Unlike traditional messaging platforms, events in topics are not deleted after being read. The lifetime of these events can be configured.
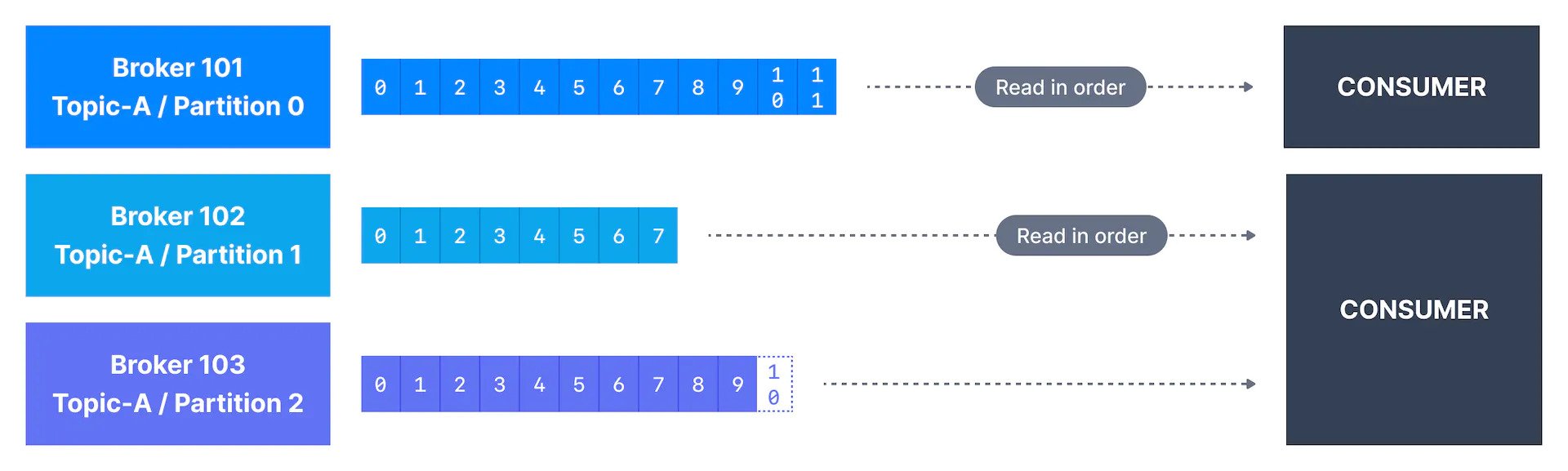
Consumers identify themselves with a consumer group name, and each message published on a topic is delivered to one consumer instance within each consumer group that is subscribed to it.
Kafka guarantees ordering across multiple consumer instances by assigning partitions to consumers of the group., such that a single consumer in the group reads a single partition. This also ensures load balancing as there are multiple consumers.
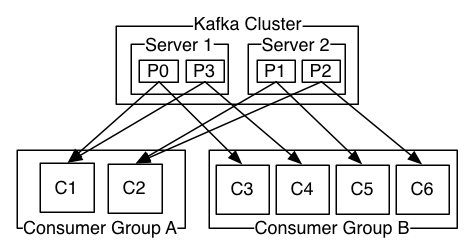
Kafka Brokers, Topic Replication, and Controller
Kafka brokers are servers that store data. Kafka usually operates in clusters, which are made up of one or more brokers. Topics are partitioned and stored on multiple brokers. To ensure that Kafka is fault-tolerant, multiple copies of topic partitions are kept on different brokers. The default number of copies is 3, but this can be changed programmatically. So, in case one broker dies, data will persist on other brokers having the replicas.
To achieve high throughput, partitions are evenly distributed across brokers. Here’s a diagram to understand the architecture.
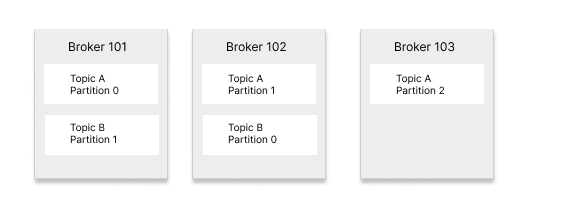
Topic Replication and Controller
Each active Kafka cluster has special brokers called controller nodes. The Zookeeper/Raft Protocol is responsible for controller selection. We know that each partition has multiple replicas determined by the replication factor. This controller node elects a leader for each of these partitions.
A leader partition is a partition responsible for writing operations. Producers publish records only to the leader partition, and follower partitions replicate data from the leader. This reduces the overhead of writing to multiple partitions.
Whenever a new topic is created or deleted, Kafka runs an algorithm to select a leader from the partition. The first replica always gets the preference. The distribution of partition leaders is even across brokers. So if you have 3 partitions and 3 brokers, each broker hosts a leader partition. This will spread the read/write load. When the leader fails, follower brokers take their place.
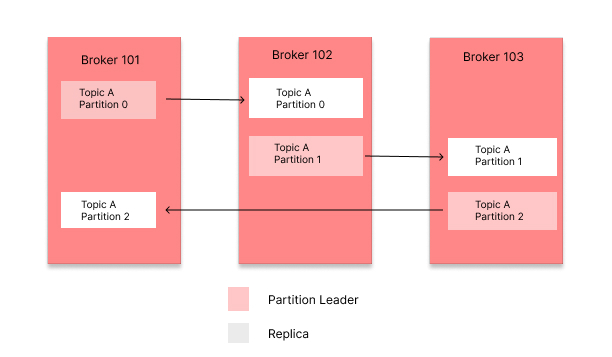
Topics with leaders and followers are distributed evenly across brokers.
Now you have an idea of how Kafka works. Let’s see how to set up a Kafka server from the terminal.
Apache Kafka With Zookeeper
Kafka uses Zookeeper to keep track of all the brokers in a cluster. The Zookeeper is responsible for following actions.
- Notify Kafka when a broker dies, a new broker joins, a topic is deleted or created, etc.
- Responsible for identifying and Electing the leader broker of a partition.
- Metadata management, Permission, and configuration management of topics.
Setup Kafka with the Zookeeper
To set up a Kafka cluster from the shell, you will need to perform the following steps:
- Download and install the Apache Kafka binary files from the Apache website.
- Extract the downloaded files and move them to the Kafka installation directory.
- Start the Zookeeper server by running the
bin/zookeeper-server-start.sh config/zookeeper.propertiesscript. - Start the Kafka server by running the
bin/kafka-server-start.sh config/server.properties. - Create a new Kafka topic by running
bin/kafka-topics.sh --topic test-events --bootstrap-server localhost:9092. - Start a Kafka producer by running
bin/kafka-console-producer.sh --topic test-events --bootstrap-server. localhost:9092. Now write anything to the Kafka topic you just created. - Start a Kafka consumer by running the
bin/kafka-console-consumer.sh --topic test-events --bootstrap-server localhost:9092. This will show you everything you have published to the test-events topic.
After performing these steps, you will have a single-node Kafka cluster running on your machine. You can test the consumer and producer by running their respective scripts. The best thing about Kafka is both the producer and consumer are independent of each other, failure of one will not impact the other in any way.
Apache Kafka With KRaft
Some flaws in Zookeeper’s implementation kept developers always wanting more.
- With Zookeeper, Kafka clusters can only have 200,000 partitions.
- A high-level leader election, while a broker joins or leaves, overloads the Zookeeper server slowing down the entire process.
- Zookeeper security lags behind Kafka’s security.
Due to these reasons, an alternate solution for metadata management and leader elections was created. As Kafka’s metadata are logs only, these logs can be consumed by Kafka brokers as internal metadata topics. In short, Kafka used itself to store metadata. A protocol called Raft was used for controller election, hence the name KRaft.
Set-up Kafka with KRaft
To use Kafka with Kraft, create a cluster UUID.
KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"Format Log directories
bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.propertiesStart Kafka server
bin/kafka-server-start.sh config/kraft/server.propertiesThen, you can create topics and publish and consume events as usual.
Working with Kafka Using Python
First of all, install Apache Kafka using pip.
pip install kafka-python
Sending messages to a Kafka topic
The following example shows how to use the KafkaProducer class to send messages to a Kafka topic:
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers=['localhost:9092'])
# Send a message to the 'test' topic
producer.send('test', b'Hello, Kafka!')
# Flush the producer to ensure all messages are sent
producer.flush()
Receiving messages from a Kafka topic
The following example shows how to use the KafkaConsumer to receive messages from a Kafka topic:
from kafka import KafkaConsumer
consumer = KafkaConsumer(
'test', # consume messages from the 'test' topic
group_id='my-group', # consumer group to join
bootstrap_servers=['localhost:9092'], # Kafka broker address
)
# Consume messages from the 'test' topic
for message in consumer:
print(message.value)
Processing messages in real-time with Kafka Streams
Kafka also provides a stream processing library called Kafka Streams, which allows for creating real-time streaming applications that can process data from Kafka topics.
Here is an example of using Kafka Streams to count the number of messages in a Kafka topic in real-time:
from kafka import KafkaConsumer
from kafka.streams import KafkaStreams
# Create a Kafka consumer to read from the 'test' topic
consumer = KafkaConsumer(
'test',
group_id='my-group',
bootstrap_servers=['localhost:9092'],
)
# Create a KafkaStreams instance to process the 'test' topic
streams = KafkaStreams(consumer)
# Define a function to process each message in the stream
def process_message(message):
# Increment a counter for each message received
counter += 1
# Consume messages from the 'test' topic and process them with the function defined above
streams.foreach(process_message)
Where to use Apache Kafka?
Kafka can stream and process website events, e-commerce data, IoT sensor data, and Micro-services generated logs.
Some use cases of Kafka are
- Real-time data pipeline: Kafka can help build a real-time data pipeline to ingest a large amount of data and make it available for real-time processing.
- Streaming Data Analytics: Data from various sources can be ingested and analyzed to drive business and product decisions.
- Event-Driven Architectures: Kafka can be used to create event-driven architectures that allow for immediate processing and action on data as it is generated.
- Microservices: Kafka can be used as a communication channel between microservices. It can also retrieve and process large amounts of logs generated by various microservices.
Conclusion
Kafka’s ability to handle large amounts of data and support real-time processing makes Kafka an essential tool for those who need to process large quantities of data quickly and reliably.
Key takeaways from the article
- Kafka is a publish-subscribe event streaming tool for real-time data processing.
- Its distributed nature makes it a low-latency, Highly available, fault-tolerant, robust tool for processing large amounts of real-time data.
- Kafka has three core components Topics, Producers, and Consumers.
- In future stable releases, Apache Kafka will no longer need Zookeeper but instead will leverage its capacity to store metadata logs in an internal topic and use the Raft protocol for controller election.
So, this was all about the basics of Apache Kafka.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Meet your author Sunil kumar Dash, a developer and a writer. Has diverse interests in tech, pop culture, wellness, philosophy and Anime. Exploring underrated music is his hobby. And loves to doom scroll Twitter when bored.






