BigQuery is a robust data warehousing and analytics solution that allows businesses to store and query large amounts of data in real time. Its importance lies in its ability to handle big data and provide insights that can inform business decisions.
Source: dataedo.com
It is designed to handle big data and is ideal for data warehousing, business intelligence, data science, and machine learning. It also allows easy integration with other data analytics tools and visualization platforms such as Tableau, Looker, and Data Studio. It can be integrated with other GCP services, such as Google Cloud Storage and Cloud Dataflow, to provide a complete data analytics solution. So, in this article, we will dive deep into the concepts of GCP BigQuery.
Learning Objective
This article will discuss the best practices that must be followed while loading and querying large data sets in Bigquery. The learning objective of this article is given as follows:
Understanding the BigQuery data loading process, including file format and data type considerations and ways to optimize data loading performance.
Knowledge of handling large datasets in BigQuery, including strategies for partitioning and clustering tables and managing resource utilization during data loading and querying.
Awareness of the different methods for querying large datasets in BigQuery, including using SQL, the BigQuery web UI and the BigQuery API.
Understanding best practices for optimizing query performance, such as using indexes, creating and using materialized views, and caching and query result deduplication.
GCP BigQuery is a fully-managed, cloud-based, analytical data warehouse offered by Google Cloud Platform (GCP). BigQuery’s SQL-like syntax makes it easy for SQL developers, analysts, and data scientists to quickly get started and perform complex data analysis and data mining. It allows users to run SQL-like queries on large datasets stored in GCP without setting up and managing a traditional data warehouse.
Source: whizlabs.com
Best Practices to Load Large Datasets in Bigquery
Here are a few best practices for loading large datasets into BigQuery:
Data Compressing: Compressing the data can significantly reduce the storage and network bandwidth required to load it into BigQuery. Gzip is the most common compression format for loading data into BigQuery.
Data Partitioning: Partitioning the data by date or other relevant fields can improve query performance and reduce costs.
Load jobs Monitoring: Keep an eye on the status of the load jobs and troubleshoot any issues that may arise. The BigQuery web UI provides detailed information about load job status, errors, and progress.
Optimizing the data format: Use the appropriate file format for data, such as Avro, Parquet, or ORC, which are more efficient for storing large datasets in BigQuery.
Optimizing the table schema: Make sure that the table schema is optimized for executing queries. This can improve query performance and reduce costs.
Using the Cloud Storage multi-part uploading feature: To upload large files to Cloud Storage, use the multi-part upload feature to upload parts of the file in parallel. This can significantly speed up the upload process.
Using a data pipeline tool: Use a data pipelines tool like Apache NiFi, Apache Beam, or Google Cloud Dataflow to automate loading large datasets into BigQuery.
Using the BigQuery streaming API: The BigQuery streaming API allows the stream of data into BigQuery in real-time, which helps load large datasets.
Using the Bigquery export function: The export functions can be used to move data out of BigQuery; it will create a job that will export the data to a GCS bucket from where it can be accessed or moved.
Consider using a Data lake architecture: A Data lake architecture enables you to store large datasets with different formats and structures and perform data processing and analysis on the stored data. Bigquery can be a data lake for storing and processing large datasets.
Here is an example of how to load a large dataset into BigQuery using the command-line tool
Suppose you have a dataset of Online_Retail_Sales with millions of rows containing information about each transaction, such as date, customer, product, and purchase amount. The sample table Sales_table within Online_Retail_Sales dataset is given below:
To load this dataset into BigQuery, you need to follow the given steps:
First, you must prepare your data by cleaning and transforming it into a format that BigQuery can understand, such as a CSV file.
You would then use the BigQuery web UI or the command-line tool to load the data into a BigQuery table. The command to load the data in the specified file from Cloud Storage into a BigQuery table:
You could then partition the data by date and use compression to reduce the storage size and cost.
Once the load job is complete, you can query the data using SQL.
Loading datasets into BigQuery may take some time and incur additional costs. To minimize costs, users should consider compressing and partitioning their data before loading it into BigQuery. It’s also essential to monitor the load job and troubleshoot any problems that may arise during loading.
Querying Large Datasets in BigQuery
Here are a few best practices for querying large datasets in BigQuery:
Using suitable data types: Choose the appropriate data types for columns to reduce the storage and network bandwidth required to scan the data.
Data Partitioning: Partition the data by date or other relevant fields to improve query performance and reduce costs.
Using the right query type: Use the appropriate query type. For example, use a SELECT DISTINCT query to find unique values from a column and a SELECT COUNT(*) query to count the number of rows in a table.
Using the right aggregate functions: Use aggregate functions like SUM(), COUNT(), AVG(), etc., to summarize data and reduce the amount of data that needs to be scanned.
Filtering and Ordering: Use filtering and order to limit the amount of data that needs to be scanned.
Using subqueries: Use subqueries to break down complex queries into smaller, more manageable pieces.
Making use of indexes: Create indexes on columns to improve query performance.
Using materialized views: Use materialized views to pre-aggregate and pre-join your data, which can improve query performance.
Using wildcard tables: To query multiple tables simultaneously can improve query performance and reduce costs.
Using Google Cloud Storage and Bigquery: Using Bigquery and Google Cloud Storage to store and process large datasets. This will allow using both services’ power to process large datasets efficiently.
Making use of the Explain plan and Query Caching feature: Explain Plan feature can be used to understand how a query is executed and to identify potential performance bottlenecks. The query caching feature can be used to cache the results of frequently run queries, improving query performance.
Example:
The following is a poorly optimized query that would require a full table scan to search for rows with dates between 2022-01-01 to 2022-01-03 and group the result by Customer. The large size of the table could impact the performance of the query.
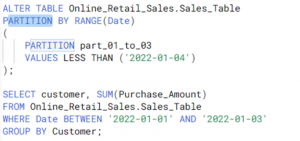
The example of a well-optimized query in BigQuery using data partitioning as a best practice is as follows:
By partitioning the data by Date, the database can now use the partition information to quickly locate the rows that match the condition in the WHERE clause. The partition allows the database to perform the search without scanning the entire table, which can help improve the query performance and reduce costs.
Conclusion
GCP BigQuery provides a cost-effective, scalable, and fast solution for data warehousing, analytics, and business intelligence. It automatically handles many of the complexities of data warehousing, such as provisioning, scaling, and backup.
The key takeaways of this article are as follows:
With GCP BigQuery, users can store and query petabytes of data using SQL.
It allows real-time streaming data, visualization, and integration with other GCP services such as Google Cloud Storage and Cloud Dataflow.
It also provides a web-based interface, command-line tools, data management, and analysis APIs.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
We use cookies on Analytics Vidhya websites to deliver our services, analyze web traffic, and improve your experience on the site. By using Analytics Vidhya, you agree to our Privacy Policy and Terms of Use.Accept
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.