Introduction
All the machine learning projects developed for the industrial business problem aim to develop and deploy them into production quickly. Thus, developing an automated ML pipeline becomes a challenge, which is why most ML projects fail to deliver on their expectations. However, the problem of automated ML pipelines can be addressed by bringing the Machine Learning Operations (MLOps) concept. Many industrial ML projects fail to progress from proof of concept to production. Even today, data scientists manually manage the ML pipelines, resulting in many issues during the operation. This article will address the traditional problems through MLOps architecture and workflow in detail.
Learning Objectives
In this article, you will learn:
- The architecture involved in MLOPs.
- The role of data engineers, data scientists, and ML engineers in each component of MLOps architecture.
- The workflow and importance of each unit in the architecture.
- Understanding the applications of MLOps in the industry.
This article was published as a part of the Data Science Blogathon.
Table of Contents
- Architecture for MLOPs
- Steps for initiating the MLOps project
- Pipeline for feature engineering
- The experimentation
- Automated ML workflow
- Application of MLOps in the industry
- Conclusion
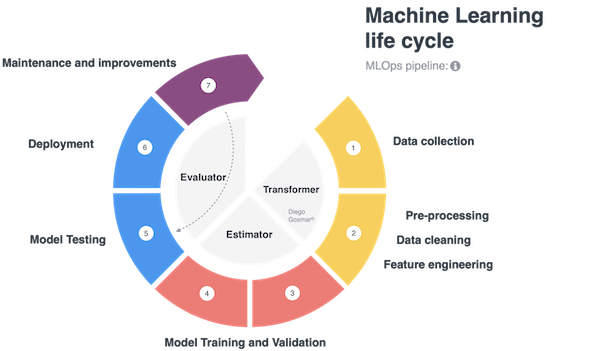
Architecture for MLOps
This section will discuss a generalized MLOps end-to-end architecture from initiating the project involving MLOps to the model serving. It includes the following:
- Steps for initiation of the MLOps project.
- Pipeline for feature engineering
- The experimentation
- Pipeline for automated model till model serving.
.png)
Source: Machine Learning Operations (MLOps)
Fig. 1 illustrates the MLOps architecture. Let’s discuss each one of them in detail.
Steps for Initiating the MLOps Project
The first step in MLOps architecture and workflow involves business stakeholders, solution architects, data scientists, and data engineers. Each one of them has a different role to play. The following points explain the role of each one of them:
- The stakeholders are responsible for analyzing the business and the problem that can be solved using machine learning.
- Then, the architecture of the machine learning solution will be designed by the solution architect.
- The data scientists with data engineers analyze the incoming data from the source. They perform validation checks that include the distribution and quality of data and potential data sources.
- Data scientists decide the type of algorithm for solving the business problem. The aim is to get the data into the proper format for model training, which would be continually refined depending on feedback.
In the next section, we will discuss designing the pipeline for feature engineering.
Pipeline for Feature Engineering
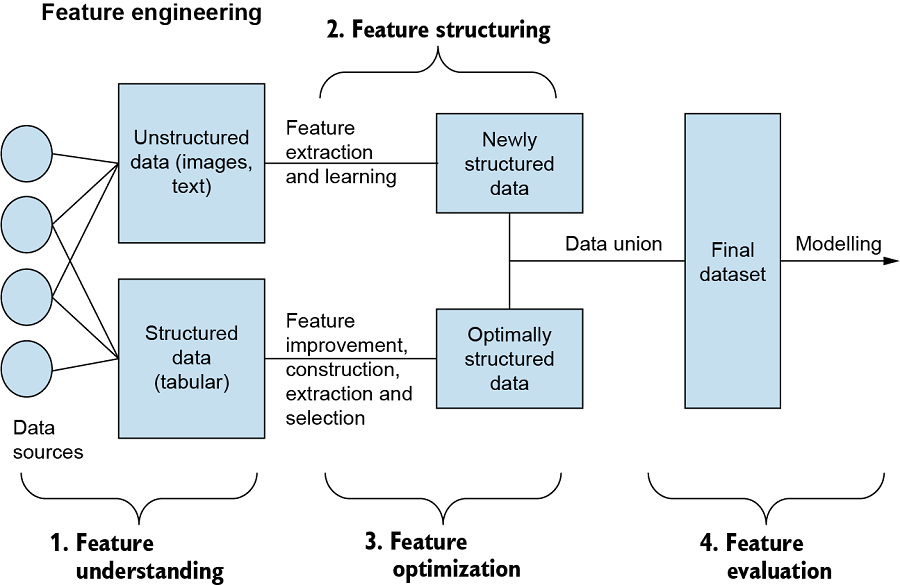
Source: LiveBook
Defining the requirements for feature engineering
The data scientists or ML engineers decide the features used in this stage of MLOps after analyzing the raw data through exploratory data analysis. Features are a critical part of model training. There are requirements for designing the pipeline for feature engineering. In this stage, data engineers are responsible for defining data transformation rules, such as aggregations, normalization, and data cleaning rules, to modify and alter the information into a useful form. The data engineers usually take help from data scientists in defining the data transformation rules. The rules must be framed upon the feedback from ML models trained for experimental purposes.
Feature engineering pipeline
In the previous step, data engineers and software developers use the defined features to create a pipeline for feature engineering. Feedback from model engineering experiments or production-level monitoring is used to adjust the initial rules and specifications. The data engineer’s responsibilities in this stage include writing code for continuous integration and delivery and managing the data received from multiple storage sources in an organized manner. The first step involves obtaining raw data from sources such as streaming data and cloud storage, which is then preprocessed to transform and clean the data as necessary.
Experimentation
During the MLOps stage, the tasks are mainly led by data scientists with support from software engineers. The first step is extracting and preprocessing raw data from various sources, then validating and splitting the data into training and testing sets. The data scientist then uses this data to determine the most effective machine learning algorithms and optimize hyperparameters. The software engineers assist in developing well-structured code for training the model. The hyperparameters are fine-tuned, and the best-performing model parameters are selected based on performance metrics. The training continues until optimal performance is achieved, known as “model engineering.” The final step is to save the model in a repository for future use.
Automated ML Workflow Pipeline
In this stage of MLOps, an ML engineer and a DevOps engineer are responsible for managing the automated ML workflow pipeline and ensuring the necessary infrastructure for model training and computation is in place. The tasks are performed in an isolated environment, such as containers, as part of the automated machine learning pipeline. The pipeline automates the following tasks:
- Data Extraction: the automatic pulling of the data from the store, either offline or online.
- Automated data preparation and validation: This includes splitting the dataset for training and testing purposes.
- Automated final model training on new unseen data: The model is chosen, and the hyperparameters are predefined according to the previous experimental stage.
- Automatic model evaluation along with the tuning of hyperparameters. The model’s training is stopped once a good performance of the model is achieved.
- Once the model is trained with best-performing parameters, it is then exported.
- Exported model is then saved in the registry.
Once the model has been created, it moves to the production phase, managed by a DevOps Engineer. The continuous deployment pipeline is initiated, including testing and training of the model. The final build is deployed on the cloud for real-time prediction of incoming data from the database. The deployment and monitoring of the model are done using REST APIs within containers. The monitoring component of the pipeline regularly evaluates the model’s performance, enabling ongoing retraining and optimization.
Application of MLOps in Industry
MLOps is widely applied across various industries to improve the management of machine learning models. Some applications of MLOps in the industry are mentioned below:
- In the healthcare industry, MLOps can streamline the drug discovery process and reduce the time and cost of clinical trials. For example, Microsoft’s Project InnerEye uses AI to analyze 3D radiological images and differentiate between tumors and healthy anatomy to aid medical professionals in treatment planning. The goal is to personalize medicine for each patient.
- In the financial sector, MLOps can automate and monitor fraud detection systems in real-time, helping reduce the risk of fraudulent activities. For example, TMNL, a collaboration of 5 Dutch banks, uses MLOps to monitor payment transactions for potential money laundering or terrorism financing using AI and ML.
- In the retail industry, MLOps can be used to personalize the customer experience and optimize supply chain operations. Retailers can quickly respond to changing customer preferences and market conditions by automating the deployment and maintenance of ML models. This can help retailers to remain competitive and improve their bottom line. For example, Market basket analysis is a technique retailers use to find connections between frequently purchased items and uncover customer buying habits using association rules.
- Another important application of MLOps is in the telecommunications industry, where MLOps can be used to improve network operations and reduce downtime. By automating the deployment and maintenance of ML models, telecom companies can quickly detect and resolve network issues, reducing the risk of service disruptions. Examples of telecom companies that are using MLOps include AT&T, Verizon, and Ericsson. They use MLOps to automate these processes, ensure consistent model performance, and increase the speed of model deployment. The goal is to improve the accuracy and efficiency of machine learning in the telecom industry while reducing manual efforts.
In conclusion, MLOps is becoming increasingly important for companies that want to leverage the power of machine learning in their operations. By automating and streamlining the entire ML development and deployment lifecycle, MLOps can help companies to optimize their operations, reduce the risk of errors, and improve their bottom line.
Frequently Asked Questions
Q1. What is an MLOps pipeline?
A. MLOps (Machine Learning Operations) pipeline refers to the end-to-end process of managing, deploying, and monitoring machine learning models in production. It encompasses data preparation, model training, testing, deployment, and ongoing maintenance. MLOps pipelines ensure reproducibility, scalability, and continuous improvement of ML models, enabling organizations to effectively operationalize and optimize their machine learning workflows for real-world applications.
Q2. What is the difference between ML pipeline and MLOps?
A. An ML pipeline refers to the sequence of steps involved in training and deploying a machine learning model, including data preprocessing, feature engineering, model training, and evaluation. On the other hand, MLOps (Machine Learning Operations) encompasses the broader set of practices and tools used to manage and operationalize ML pipelines, including version control, automated testing, continuous integration, deployment orchestration, and monitoring, ensuring reliable and efficient management of ML models throughout their lifecycle. MLOps focuses on the operational aspects of ML, while an ML pipeline focuses on the specific steps of model development.
Q3. What is MLOps architecture?
A. MLOps architecture refers to the overall design and structure of the systems and components used to implement Machine Learning Operations (MLOps). It typically involves integrating various tools and technologies for data ingestion, preprocessing, model training, deployment, monitoring, and feedback loops. MLOps architecture aims to enable seamless collaboration, automation, scalability, and reproducibility of machine learning workflows, ensuring efficient management and operationalization of ML models in production environments.
Conclusion
This article discussed the benefits of using an MLOps architecture to automate the pipeline for machine learning models. The steps outlined in the paper show how MLOps provides a straightforward approach to implementing proof of concepts. To maximize efficiency throughout the process, data engineers, data scientists, and ML engineers play crucial roles in each aspect of the architecture. This article highlighted how MLOps architecture could address the challenge of creating an automated pipeline for machine learning models and how it provides a simple solution to implement ideas. The participation of data engineers, data scientists, and ML engineers in each stage of the architecture is essential to enhance overall efficiency.
The MLOps architecture comprises several parts. Here are some of the key takeaways:
- The first stage, initiating MLOps projects, involves collating data from sources and analyzing them, including the quality check. It mainly focuses on understanding what data is available and what data should be used for model development.
- The second stage is a feature engineering pipeline, which is associated with defining feature engineering rules like transformation methods and then developing a complete feature engineering pipeline where all the preprocessing takes place automatically.
- The third stage includes experimentation, where the data is split into the training set and test set, then training of the model and fine-tuning of hyper-parameters. Further, the model is saved and exported.
- The last stage is the development of an automated pipeline to automate all the processes discussed above through a single pipeline.
Thus, MLOps provides a complete pipeline to develop a production-ready ML model.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Sarvagya Agrawal
25 May, 2023







