Introduction
Converting natural language queries into code is one of the toughest challenges in NLP. The ability to change a simple English question into a complex code opens up a number of possibilities in developer productivity and a quick software development lifecycle. This is where Google Gemma, an Open Source Large Language Model comes into play. This guide will explore how to fine-tune Google’s Gemma with unsloth for generating code statements from natural language queries.

Learning Objectives
- Understand the importance of code generation from natural language for developer efficiency.
- Learn about Google Gemma and its role in transforming English queries into code.
- Explore Unsloth’s efficiency enhancements and memory management for Large Language Models.
- Set up the environment for fine-tuning Google Gemma with Unsloth efficiently.
- Prepare datasets compatible with Gemma and Unsloth for effective fine-tuning.
- Master fine-tuning Google Gemma with specific training arguments using SFTTrainer.
- Generate code from natural language prompts using fine-tuned Gemma.
- Evaluate the performance of fine-tuned Gemma in software development workflows.
This article was published as a part of the Data Science Blogathon.
Table of contents
Introduction to Gemma
Google developed a set of Open-Source Large Language Models called Google Gemma. It was trained with 6T text tokens based on Google’s Gemini models. These are regarded to be the Gemini models‘ lighter variants. There are two sizes in the Gemma family: a 2 billion parameter model for CPU and on-device applications, and a 7 billion parameter model for effective deployment on GPU and TPU.
Gemma has cutting-edge comprehension and reasoning ability at scale along with high talent in text domains. It outperforms other open models in a variety of categories, which include question answering, commonsense reasoning, mathematics, and science at matchable or bigger scales. Google releases fine-tuned checkpoints and an open-source codebase for inference and serving for both models. In this guide, we will work with the 7 Billion Parameter version of Gemma.
What is Unsloth?
Daniel and Michael Han crafted Unsloth, which quickly emerged as the optimized framework tailored to refine the fine-tuning process for large language models (LLMs). Renowned for its swiftness and memory efficiency, Unsloth can fasten up to 30x training speed and with a notable 60% reduction in memory usage. These impressive metrics have rendered it a goto framework for the developers seeking to fine-tune LLMs with precision and speed.
Notably, Unsloth accommodates different Hardware Setups, spanning from NVIDIA GPUs like Tesla T4 to H100, and extends its compatibility to AMD and Intel GPUs. The library’s adaptability shines through its incorporation of pioneering techniques which include intelligent weight upcasting, a feature that curtails the necessity for upscaling weights during QLoRA, thereby optimizing memory usage. Additionally, Unsloth leverages bfloat16 swiftly, improving the stability of 16-bit training and expediting QLoRA fine-tuning.
As an open-source tool licensed under Apache 2.0, Unsloth integrated seamlessly into fine-tuning prominent LLMs like Mistral 7B, Llama, and Google Gemma showing up to an aspect of 5x acceleration in fine-tuning speed while concurrently slashing memory consumption by 60%. Moreover, its compatibility extends to alternative fine-tuning methods like Flash-Attention 2, which not only accelerates inference but even fine-tuning processes.
Setting Up the Environment
The first thing is to prepare the Python environment by downloading and installing the necessary libraries. We will be working on Google Collab to Finetune the Gemma LLM. To do so, we will follow the following commands
!pip install "unsloth[colab] @ git+https://github.com/unslothai/unsloth.git"- This installs the unsloth library in the Colab environment. The [colab] beside the unsloth specifically tells the pip installer to install other libraries that support unsloth in the Google Colab environment.
- This even installs the datasets and the transformers library from HuggingFace.
# Import the FastLanguageModel class from the unsloth library.
from unsloth import FastLanguageModel
# Import the torch library.
import torch
# Set the maximum sequence length to 8192 tokens.
max_seq_length = 8192
# Set the data type to None for automatic detection.
dtype = None
# Set the load_in_4bit flag to True to load the model weights in 4-bit precision.
load_in_4bit = True- The FastLanguageModel class from the unsloth library provides an optimized implementation of large language models for Google Colab.
- max_seq_length tells the maximum number of tokens the model can process in a single sequence. The max sequence length for Gemma is 8192 and hence initializing the same.
- dtype tells the data type to use for the model’s weights and activations.
- load_in_4bit setting to true will load the model weights in 4-bit precision. This can save memory and improve performance on some GPUs, but may even reduce accuracy slightly.
Downloading 4-bit Quantized Model and Adding LoRA Adapters
In this section, we will start off by first downloading the Gemma Model:
# Load the pre-trained model from the 'unsloth/gemma-7b-bnb-4bit' repository.
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/gemma-7b-bnb-4bit",
# Set the maximum sequence length to the value defined earlier.
max_seq_length = max_seq_length,
# Set the data type to the value defined earlier.
dtype = dtype,
# Set the load_in_4bit flag to the value defined earlier.
load_in_4bit = load_in_4bit,
)
- This code works with the from_pretrained() method of the FastLanguageModel class to load a pre-trained model from the Hugging Face model hub.
- The model_name argument tells the name of the model that we need to load.
- The max_seq_length, dtype, and load_in_4bit arguments are passed to the constructor of the FastLanguageModel class. These are the parameters that we have already defined.
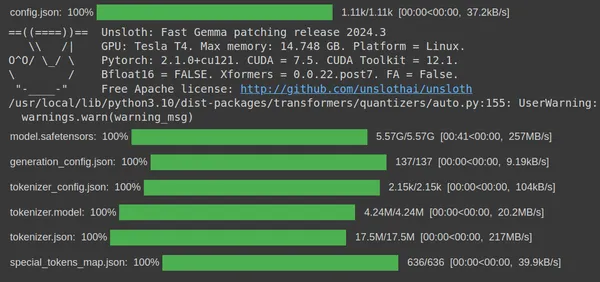
We can see that after running the code, the code will download the gemma-7b 4-bit quantized version from the unsloth huggingface hub present in HuggingFace. Finally, the download of the quantized model step is completed. Now we need to create a LoRA for this so that we can only train a subset of these parameters.
The code for this is as follows:
# Create a PEFT model with the given parameters
model = FastLanguageModel.get_peft_model(
model,
r=16, # LoRa Rank
target_modules=["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing=True
)
- The r parameter determines the rank of the LoRA projection matrix. It controls the number of parameters needed for fine-tuning. More parameters and maybe improved performance follow from a higher rank, but the model’s memory footprint may even grow
- The lora_alpha option sets the scale of the LoRA projection matrix. This parameter allows for adjusting the Learning Rate during the fine-tuning process.
- The LoRA projection matrix’s dropout rate is told by the lora_dropout option. This parameter is to reduce overfitting and improve the model’s capacity for generalization. However, for Unsloth optimization, it is set to 0.
- The bias parameter determines whether to include a Bias Component in the LoRA projection matrix. Setting it to ‘none’ means no bias term will be applied.
- The use_gradient_checkpointing variable is set to True to leverage Gradient Checkpointing. Doing this will speed up the training process
Finally running this code will create the LoRA adapters for the Gemma 7B model which we can work with to fine-tune the model on different types of dataset.
Preparing the Dataset for Fine-tuning
Now, we will download the dataset and prepare it for fine-tuning. For this guide, for generating codes, we will go with the Token Bender Code Instructions dataset. This dataset follows alpaca tyle chat formatting. The dataset looks like the one below:

We work with mainly 3 columns, the Input, Instruction, and the Output Column. With these 3 columns, we arrange it in an alpaca-style format and train the Gemma Large Language Model on this data. First, let’s define a helper function that takes in each row of this data and converts it to an alpaca-style format.
def formatted_train(x):
if x['input']:
formatted_text = f"""Below is an instruction that describes a task. \
Write a response that appropriately completes the request.
### Instruction:
{x['instruction']}
### Input:
{x['input']}
### Response:
{x['output']}<eos>"""
else:
formatted_text = f"""Below is an instruction that describes a task. \
Write a response that appropriately completes the request.
### Instruction:
{x['instruction']}
### Response:
{x['output']}<eos>"""
return formatted_textThe function takes in each row of the dataset and returns it in the corresponding Alpaca format:
- The function takes a single argument, x, which represents a row of a DataFrame.
- It checks whether the value in the ‘input’ column of the DataFrame row is true (if x[‘input’]:). If it is, it proceeds to create a formatted text block using f-strings.
- If the ‘input’ column is true, it constructs a formatted text block containing an instruction, input, and response, separated by markdown headings (###) for each section. It includes the instruction from the ‘instruction’ column, the input from the ‘input’ column, and the output from the ‘output’ column.
- If the ‘input’ column is not truthy (empty or evaluates to False), it constructs a similar formatted text block but without including the input section.
- In both cases, the formatted text block has an appended (end of sentence) marker at the end.
- Finally, the function returns the constructed formatted text block.
Function to Download Dataset from HuggingFace
Next, we create a function to download the dataset from HuggingFace and transform the dataset with the following formatting.
from datasets import load_dataset, Dataset
def prepare_train_data(data_id):
data = load_dataset(data_id, split="train")
data_df = data.to_pandas()
data_df["formatted_text"] = data_df[["input", "output",
"instruction"]].apply(formatted_train, axis=1)
data = Dataset.from_pandas(data_df)
return data
data_id = "TokenBender/code_instructions_122k_alpaca_style"
data = prepare_train_data(data_id)- The load_dataset function loads the dataset from the specified dataset ID and splits.
- The to_pandas method converts the dataset to a pandas dataframe.
- The apply method applies the lambda function to each row in the dataframe.
- The lambda function takes the instruction, input, and output columns from each row and passes them to the formatted_train function.
- The formatted_train function returns the formatted chat template string in Alpaca format, which we then store in the new ‘formatted_text’ column.
- The Dataset.from_pandas method converts the dataframe back to a Dataset object.
And then we finally pass the data_id to the prepare_train_data function. We download the dataset from HuggingFace, apply the specified changes to each row, and then save the resulting Alpaca-format text in the ‘formatted_text’ column of the dataset.
With this, we have completed the preparation of the code dataset for fine-tuning.
Fine-tuning Google Gemma for Code Dataset
We now have access to the dataset for fine-tuning. In this section, we will start off by defining the training arguments and finally fine-tune the model. The below code defines the training arguments for fine-tuning Google Gemma Large Language Model:
from trl import SFTTrainer
from transformers import TrainingArguments
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = data,
dataset_text_field = "formatted_text",
max_seq_length = max_seq_length,
dataset_num_proc = 2,
packing = False,
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 5,
max_steps = 10,
learning_rate = 2e-4,
fp16 = not torch.cuda.is_bf16_supported(),
bf16 = torch.cuda.is_bf16_supported(),
logging_steps = 1,
optim = "paged_adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
),
)The provided code snippet configures training arguments for the Large Language Model using the TrainingArguments class from the Transformers library. These arguments Define different parameters that control the training process. Then passes them along with other Trainer parameters to the SFTTrainer class.
Breakdown of Key Arguments
Here’s a breakdown of the key arguments for the TrainingArguments:
- per_device_train_batch_size: This tells the number of training examples processed per device (e.g., GPU) during each training step. Here, it is set to 2, meaning 2 examples will be processed per device in each step.
- gradient_accumulation_steps: This defines the number of Grad Accumulation steps before performing a parameter update. It effectively increases the batch size by accumulating gradients over multiple steps. Here, it is set to 4, meaning gradients will be accumulated over 4 steps before updating the model parameters.
- warmup_steps: This sets the number of warm-up steps during training, gradually increasing the Learning Rate from 0 to the provided value. Here, it’s set to 5, so the Learning Rate will linearly increase over the first 5 steps.
- max_steps: This defines the total number of training steps to perform. Here, it is set to 50, meaning the training will stop after 50 steps.
- learning_rate: This tells the first Learning Rate used for training. Here, it is set to 2e-4 (2 multiplied by 10 to the power of -4).
- fp16 and bf16: These arguments control the precision used for training. fp16 is for half-precision (16-bit) training if the GPU supports it, while bf16 is for bfloat16 training if supported.
- logging_steps: This sets the interval at which training metrics and losses are logged. We set it to 1, so logs are printed after every training step.
- optim: This tells the optimizer to use for training. Here, we set it to ‘paged_adamw_8bit’, a specialized optimizer for memory-efficient training.
- weight_decay: This defines the weight Decay Rate that we need for regularization. Here, it is set to 0.01.
- lr_scheduler_type: This tells what Learning Rate Scheduler to use during training.
Passing Training Arguments
Finally, we are done creating our Training Arguments. We pass these Training Arguments to the SFTTrainer, to the args variable. Apart from the TrainingArguments, we even pass in the below parameters:
- model: This tells the model to be trained. In our code, it is the model variable defined earlier.
- tokenizer: This tells the tokenizer used to process the text data. Here, it is the tokenizer variable defined earlier.
- train_dataset: This tells the training dataset, which is the data variable containing formatted text data.
- dataset_text_field: This tells the name of the field in the dataset that contains the formatted text. Here, it is “formatted_text”.
- max_seq_length: This defines the maximum sequence length for the input and output sequences. Here, it is set to max_seq_length, which is a variable defined earlier.
- dataset_num_proc: This tells the number of workers to work with to tokenize the data. Here are giving it a value of 2.
- packing: This is a boolean flag that tells if we should use sequence packing during training. It is set to false because we are dealing with larger sequences of data.
- args: This tells the training arguments object created earlier, which contains different training parameters.
We are finally done with defining our Trainer for training our quantized Gemma 7B Large Language Model. Now we will run the trainer to start the training process. To do this, we write the below command:
trainer_stats = trainer.train()Running the above will start the training process. It can take up to 30 minutes in the Google Colab to train this model. Finally, after 30 minutes, the model will be fine-tuned on the Code Dataset:
Generating Code with Gemma
Now, we will test the fine-tuned Gemma 7B that is trained on the Code Dataset. Before that, let’s define some helper functions that will let us create the Prompt in Alpaca Format.
def format_test(x):
if x['input']:
formatted_text = f"""Below is an instruction that describes a task. \
Write a response that appropriately completes the request.
### Instruction:
{x['instruction']}
### Input:
{x['input']}
### Response:
"""
else:
formatted_text = f"""Below is an instruction that describes a task. \
Write a response that appropriately completes the request.
### Instruction:
{x['instruction']}
### Response:
"""
return formatted_textThis function format_test() is very much similar to the function that we have defined during our Dataset processing stage. The only difference here is that we only take in the input and instruct., from the data this time and leave the output so that the model will generate it.
Let’s try to visualize an example Prompt with this function:
Prompt = format_test(data[155])
print(Prompt)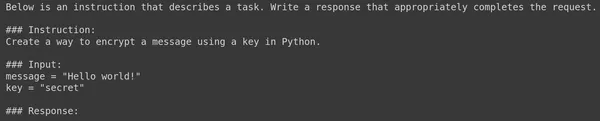
Now let’s take in the fine-tuned model, give this input, and see what output it generates.
Python Code Implementation
from transformers import TextStreamer
FastLanguageModel.for_inference(model) # Enable native 2x faster inference
inputs = tokenizer(
[
Prompt
], return_tensors = "pt").to("cuda")
text_streamer = TextStreamer(tokenizer)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 512)
- Imports the TextStreamer class from the transformers library. TextStreamer is used to generate text incrementally, one token at a time.
- Enables faster inference for the language model using FastLanguageModel.for_inference(model).
- Then we tokenize the provided Prompt with the pre-trained tokenizer. The Tokenized Prompt is then converted into a PyTorch tensor and moved to the GPU.
- Then we initialize a TextStreamer object with the same tokenizer.
- We generate new text by providing the text_streamer, input, and the maximum new tokens to the model.generate() function.
- Running this code will Stream the output generated by the Large Language Model. It has given the following result.
Running this code will stream the output generated by the Large Language Model. It has given the following result:
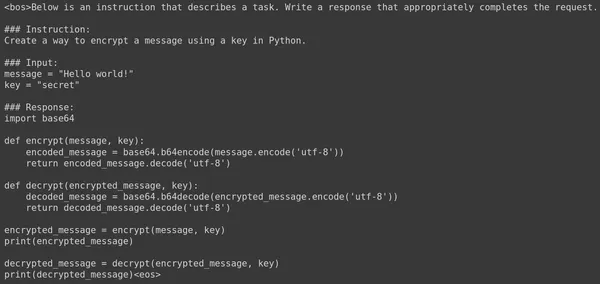
We see that the model has generated the following code:
import base64
def encrypt(message, key):
encoded_message = base64.b64encode(message.encode('utf-8'))
return encoded_message.decode('utf-8')
def decrypt(encrypted_message, key):
decoded_message = base64.b64decode(encrypted_message.encode('utf-8'))
return decoded_message.decode('utf-8')
message = "Hello World!"
key = "secret"
encrypted_message = encrypt(message, key)
print(encrypted_message)
decrypted_message = decrypt(encrypted_message, key)
print(decrypted_message)This code generated by the Gemma 7B LLM works perfectly fine. Let’s try asking another question and see the response generated. Below is another Prompt and its respective answer generated by the fine-tuned Gemma 7B Large Langage Model.

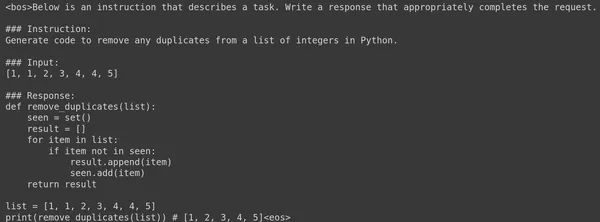
Below is the code generated by the Large Language Model for the provided Prompt:
def remove_duplicates(list):
seen = set()
result = []
for item in list:
if item not in seen:
result.append(item)
seen.add(item)
return result
list = [1, 1, 2, 3, 4, 4, 5]
print(remove_duplicates(list)) # [1, 2, 3, 4, 5]
Even the above code works perfectly fine. We see that fine-tuning Google Gemma 7B Large Language Model in just 60 steps has resulted in a good code-generating model. The LLM is even able to understand the formatting correctly and generate the response in the same Alpaca format.
Conclusion
The integration of Google’s Gemma with Unsloth for code generation from natural language queries has shown potential in enhancing developer productivity. Gemma, a robust Large Language Model, can convert English queries into complex code statements, while Unsloth improves training efficiency and memory usage. This synergy enhances code generation capabilities in Natural Language Processing (NLP) applications, fostering new techniques and improving software development efficiency.
Key Takeaways
- Google Gemma, provides great Language Comprehension and Reasoning Abilities, making it a great choice for code-generation tasks.
- Unsloth, an optimized library for fine-tuning Large Language Models, greatly boosts training speed reduces memory, and increases overall efficiency.
- Creating the environment involves installing necessary libraries and configuring parameters like the sequence length and data type.
- Fine-tuning Google Gemma with provided training arguments and working with the SFTTrainer class facilitates efficient model training on code datasets.
- Generating code with fine-tuned Gemma involves providing Prompts in Alpaca format and working with the TextStreamer class for incremental text generation.
- Practical examples show the efficacy of the fine-tuned Gemma 7B model in accurately generating code responses from Natural Language Prompts, showing its potential in improving software development workflows.
Frequently Asked Questions
Q1. What is Google Gemma and what are its capabilities?
A. Google Gemma is a family of open-source large language models (LLMs). These models are lighter variants of Google’s Gemini models and exhibit good Comprehension and Reasoning Abilities. Gemma’s capabilities span various tasks like question answering, code generation, and more.
Q2. What is Unsloth and how does it benefit fine-tuning LLMs?
A. Unsloth, an optimized library, accelerates and improves the efficiency of LLM fine-tuning. It provides great speed and memory improvements, making it the go-to choice for fine-tuning models like Gemma.
Q3. What dataset is used for fine-tuning Gemma in this guide?
A. The Token Bender Code Instructions dataset contains instructions and corresponding code outputs in an Alpaca-style chat format.
Q4. How is the Dataset Prepared for fine-tuning?
A. The dataset is first converted into an Alpaca-style format, where each row includes an Instruct., an Input, and the desired code output. This format helps the model learn the relationship between natural language instructions and code.
Q5. What are the key training arguments used for fine-tuning?
A. Define several training arguments: Batch Size, Gradient Accumulation Steps, Learning Rate, and the number of training steps. These parameters control how the model learns from the data.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I work as a Developer in the field of Data Science. I constantly spend time learning new things be it related to AI, DataSceine, and CyberSecurity. Deep learning and machine learning are two topics that I find particularly fascinating, and Python is my preferred language for programming. Cyber Security is another field that I'm touching upon recently. I have experience with large-scale data analysis, and I have a solid grasp of a variety of deep learning and machine learning approaches, including neural networks, regression models, and natural language processing. I'm eager to take on new challenges and make a meaningful contribution to the industry, so I'm constantly seeking for ways to enlarge and deepen my knowledge and skills in the subject.






