News at a Glance
- Meta announces Chameleon, an advanced multimodal large language model (LLM).
- Chameleon uses an early-fusion token-based mixed-modal architecture.
- The model processes and generates text and images within a unified token space.
- It outperforms other models in tasks like image captioning and visual question answering (VQA).
- Meta aims to continue enhancing Chameleon and exploring additional modalities.

Meta is making strides in artificial intelligence (AI) with a new multimodal LLM named Chameleon. This model, based on early-fusion architecture, promises to integrate different types of information better than its predecessors. With this move, Meta is positioning itself as a strong contender in the AI world.
Also Read: Ray-Ban Meta Smart Glasses Get a Multimodal AI Upgrade
Understanding Chameleon’s Architecture
Chameleon employs an early-fusion token-based mixed-modal architecture, setting it apart from traditional models. Unlike the late-fusion approach, where separate models process different modalities before combining them, Chameleon integrates text, images, and other inputs from the start. This unified token space allows Chameleon to reason over and generate interleaved sequences of text and images seamlessly.
Meta’s researchers highlight the model’s innovative architecture. By encoding images into discrete tokens similar to words in a language model, Chameleon creates a mixed vocabulary that includes text, code, and image tokens. This design enables the model to apply the same transformer architecture to sequences containing both image and text tokens. It enhances the models’s ability to perform tasks that require a simultaneous understanding of multiple modalities.
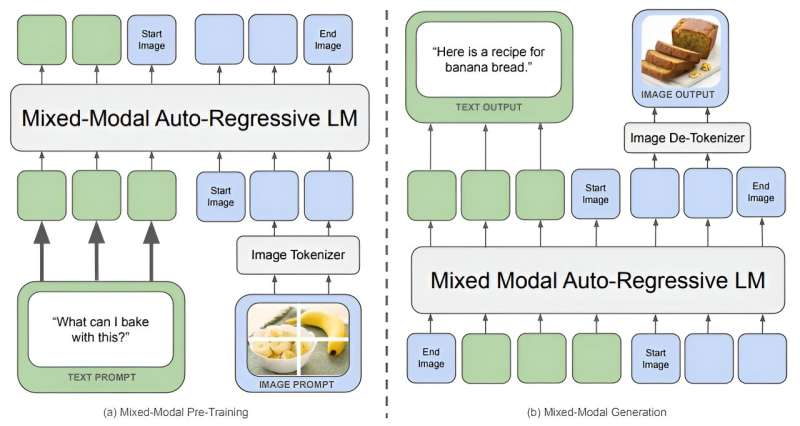
Training Innovations and Techniques
Training a model like Chameleon presents significant challenges. To address these, Meta’s team introduced several architectural enhancements and training techniques. They developed a novel image tokenizer and employed methods such as QK-Norm, dropout, and z-loss regularization to ensure stable and efficient training. The researchers also curated a high-quality dataset of 4.4 trillion tokens, including text, image-text pairs, and interleaved sequences.
Chameleon’s training occurred in two stages, with versions of the model boasting 7 billion and 34 billion parameters. The training process spanned over 5 million hours on Nvidia A100 80GB GPUs. These efforts have resulted in a model capable of performing various text-only and multimodal tasks with impressive efficiency and accuracy.
Also Read: Meta Llama 3: Redefining Large Language Model Standards
Performance Across Tasks
Chameleon’s performance in vision-language tasks is notable. It surpasses models like Flamingo-80B and IDEFICS-80B in image captioning and VQA benchmarks. Additionally, it competes well in pure text tasks, achieving performance levels comparable to state-of-the-art language models. The model’s ability to generate mixed-modal responses with interleaved text and images sets it apart from its competitors.
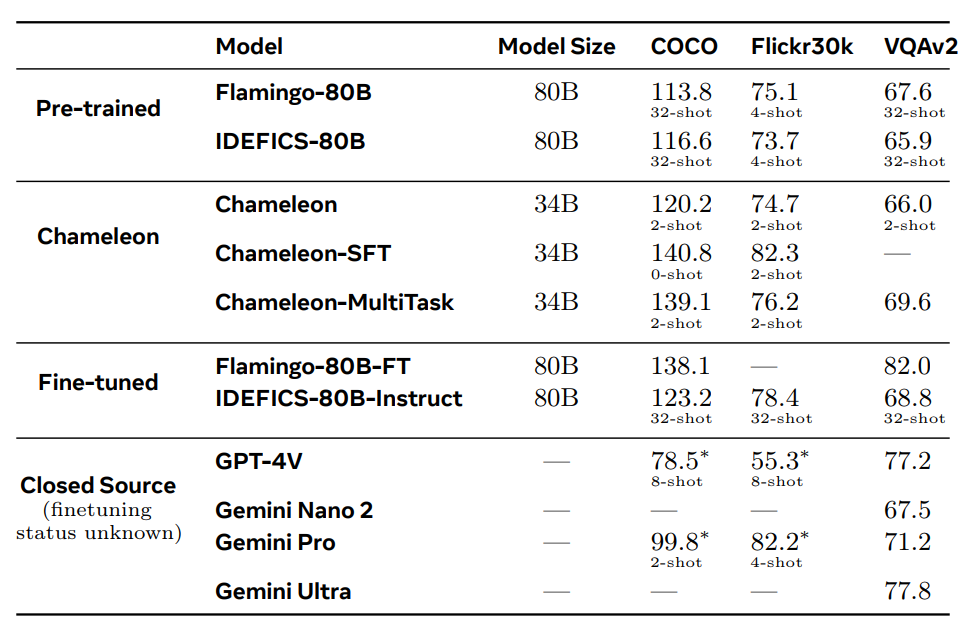
Meta’s researchers report that Chameleon achieves these results with fewer in-context training examples and smaller model sizes, highlighting its efficiency. The model’s versatility and capability to handle mixed-modal reasoning make it a valuable tool for various AI applications, from enhanced virtual assistants to sophisticated content-generation tools.
Future Prospects and Implications
Meta sees Chameleon as a significant step towards unified multimodal AI. Going forward, the company plans to explore the integration of additional modalities, such as audio, to further enhance its capabilities. This could open doors to a range of new applications that require comprehensive multimodal understanding.
Chameleon’s early-fusion architecture is also quite promising, especially in fields such as robotics. Researchers could potentially develop more advanced and responsive AI-driven robots by integrating this technology into their control systems. The model’s ability to handle multimodal inputs could also lead to more sophisticated interactions and applications.
Our Say
Meta’s introduction of Chameleon marks an exciting development in the multimodal LLM landscape. Its early-fusion architecture and impressive performance across various tasks highlight its potential to revolutionize multimodal AI applications. As Meta continues to enhance and expand Chameleon’s capabilities, it could set a new standard in AI models for integrating and processing diverse types of information. The future looks promising for Chameleon, and we anticipate seeing its impact on various industries and applications.
Follow us on Google News to stay updated with the latest innovations in the world of AI, Data Science, & GenAI.
Sabreena is a GenAI enthusiast and tech editor who's passionate about documenting the latest advancements that shape the world. She's currently exploring the world of AI and Data Science as the Manager of Content & Growth at Analytics Vidhya.






