Introduction
Necessity is the mother of innovation!
This is an old proverb, but it still holds damn good!
Last decade has pushed the boundaries of data generation, storage and analysis to an entirely new level. This push towards a digital data driven economy has created its own need. These problems and solutions are typically combined under the umbrella of Big Data.
Imagine this – Facebook and Google combined generate more data today, than the entire world would have generated a few years back. With this increase in data generation, comes the problem of data storage and scaling. All of us want our Facebook feeds to load instantaneously and hate the waiting time – but imagine the architecture you need to deliver that experience. Millions of users making simultaneous queries into your database in real time…phew! Add to this the unstructured nature of the data and need of a system, where you can add new features quickly – this would now be looking like an Herculean task.
Traditional databases find it hard to cope up with these requirements and the cost of scaling up becomes prohibitive! In this article, we’ll focus on one such innovation in data storage system popularly known as MongoDB. It provides schema-less design, high performance, high availability, and automatic scaling qualities which have now become a need and cannot be satisfactorily met by traditional RDBMS systems.
![]()
According to Wikipedia:
MongoDB (from humongous) is a cross-platform document-oriented database. Classified as a NoSQL database, MongoDB eschews the traditional table-based relational database structure in favor of JSON-like documents with dynamic schemas (MongoDB calls the format BSON), making the integration of data in certain types of applications easier and faster. Released under a combination of the GNU Affero General Public License and the Apache License, MongoDB is free and open-source software.
– Wikipedia
MongoDB is used across several companies in multiple domains (some of them shown below):

What can you learn from this guide?
In this guide, we’ll start by understanding the basic structural aspects powering MongoDB. The idea is to understand how MongoDB works. Specifically, we will look at these aspects:
- Data Model
- GridFS
- Sharding
- Aggregation
- Indexes
- Replication
We will also compare Traditional RDBMS vs NoSQL Databases to give you a better understanding of which works better, followed by the advantages and limitations of MongoDB.
Once we have a fair understanding of how MongoDB works, we will provide step by step guide to its installation. In the second part of this series, we will connect MongoDB to our analytics tools to provide a demo. For now, let’s start by understanding how MongoDB works.
Useful Read: NoSQL Databases explained in simple english!
Structural aspects of MongoDB
Let’s now understand the structural aspects of MongoDB in the order stated above:
1. Data Model
MongoDB stores data in the form of BSON -Binary encoded JSON documents which supports a rich collection of types. Fields in BSON documents may hold arrays of values or embedded documents. In MongoDB, the database construct is a group of related collections. Each database has a distinct set of data files and can contain a large number of collections. A single MongoDB deployment may have many databases.
What is a ‘document’ in Mongo DB?
A record in MongoDB is a document (shown below), which is a data structure composed of field and value pairs. MongoDB documents are similar to JSON objects. The values of fields may include other documents, arrays, and arrays of documents.This is an important differentiation from RDBMS systems where each field must contain only one value.
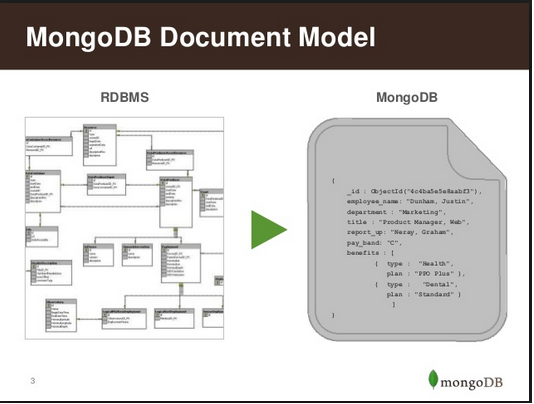
What are ‘collections’ in Mongo DB?
MongoDB stores documents in collections (shown below). Collections are analogous to tables in relational databases. In RDMS all tables in a database must have the same schema, but in MongoDB there is no such requirement. This schema-less design is an innovation which makes MongoDB the most used NoSQL Database. However, documents stored in a collection must have a unique _id field that acts as a primary key.

Documents in a collection can be stored either in Normalized for or embedded into another document itself. Let’s understand the difference in detail:
a) Normalized Data Models
The relationships between data is stored by links (references) from one document to another (shown below). These references are resolved by the application to fetch the related data.
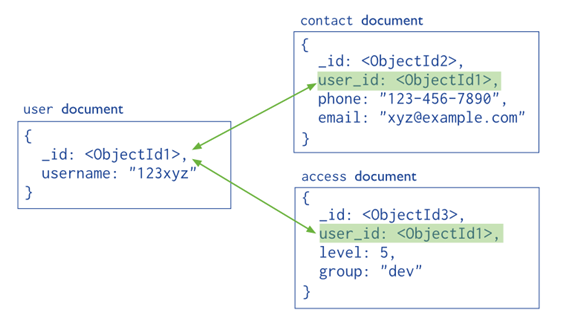
b) Embedded Data Models
Embedded documents store relationships between data by storing related data in a single document structure (shown below). These denormalized data models allow applications to retrieve and manipulate related data in a single database operation.

2. GridFS
GridFS is a specification for storing and retrieving files that exceed the BSON-document size limit of 16MB.
Instead of storing a file in a single document, GridFS divides a file into parts, and stores each part as a separate document. GridFS uses two collections to store files. One collection stores the file chunks, and the other stores file metadata (shown below).
When we query a GridFS store for a file, the client reassembles the chunks as needed. Information can also be accessed from any random section/s of files. This feature is what basically allows for “skipping” into the middle of a video or audio file.
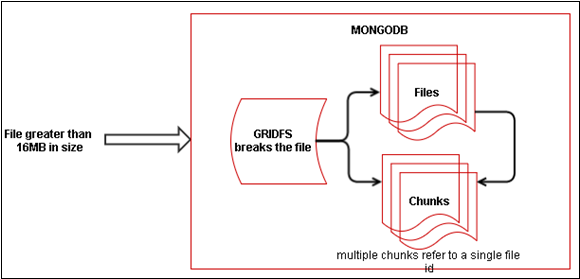
3. Sharding
Database systems with large data sets and high throughput applications can challenge the capacity of a single server in multiple ways such as:
- High query rates put stress on the CPU capacity of the server.
- Larger data sets exceed the storage capacity of a single machine.
- Dataset sizes larger than the system’s RAM stress the I/O capacity of disk drives.
To address these issues of scale, database systems have two basic approaches:
- Vertical Scaling
- Sharding or Horizontal Scaling
a) Vertical scaling: It adds more CPU and storage resources to increase capacity. But such arrangements are disproportionately expensive. As a result there is a practical maximum capability for vertical scaling.
b) Sharding or Horizontal Scaling: By contrast, it divides the data set and distributes the data over multiple servers-shards. Each shard is an independent database and collectively shards make up a single database.
MongoDB supports sharding through the configuration of sharded clusters. Process of sharing has been explained in the image below where:
- Shards are used to store the data.
- Query Routers, or mongos instances, interface with client applications and direct operations to the appropriate shard or shards and then returns results to the clients.
- Config servers stores the cluster’s metadata. This data contains a mapping of the cluster’s data set to the shards. The query router uses this metadata to target operations to specific shards.
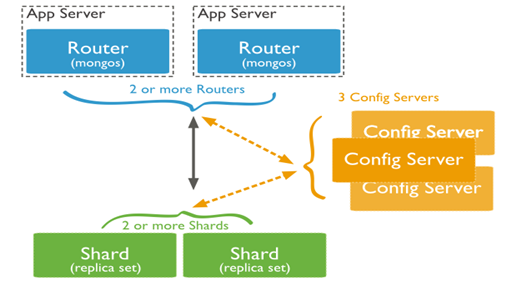
4. Data partitioning
MongoDB distributes data at the collection level. Sharding partitions a collection’s data by the shard key.
What is a shard key?
A shard key is either an indexed field or an indexed compound field that exists in every document in the collection. MongoDB divides the shard key values into chunks and distributes the chunks evenly across the shards. To divide the shard key values into chunks, MongoDB uses either range based partitioning or hash based partitioning.
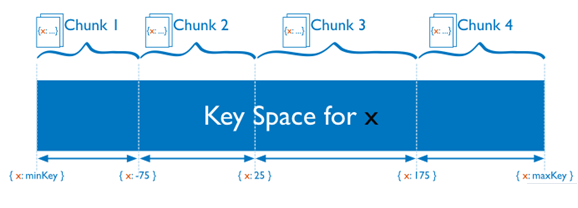
a) Range Based Sharding
Consider a numeric shard key: If you visualize a number line that goes from negative infinity to positive infinity, each value of the shard key falls at some point on that line. MongoDB partitions this line into smaller, non-overlapping ranges called chunks. It is a range of values from some minimum value to some maximum value (shown below).
In a range based partitioning system, documents with “close” shard key values are most probably in the same chunk, and thus on the same shard.
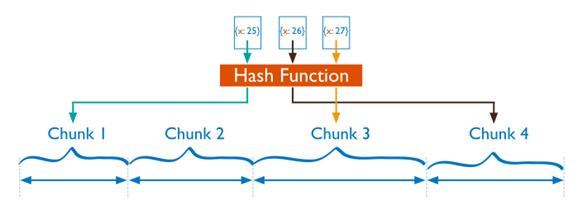
b) Hash Based Sharding:
For hash based partitioning, MongoDB computes a hash -A hash value is a numeric value of a fixed length that uniquely identifies data. These values represent large amounts of data as much smaller numeric values of a field’s value, and then uses these hashes to create chunks (shown below).
With hash based partitioning, two documents with “close” shard key values are unlikely to be part of the same chunk. This ensures a more random distribution of a collection in the cluster.
4. Aggregation
Aggregations are operations that process data records and return computed results. Unlike queries, aggregation operations in MongoDB use collections of documents as an input and return results in the form of one or more documents. MapReduce is a tool used for aggregating data.
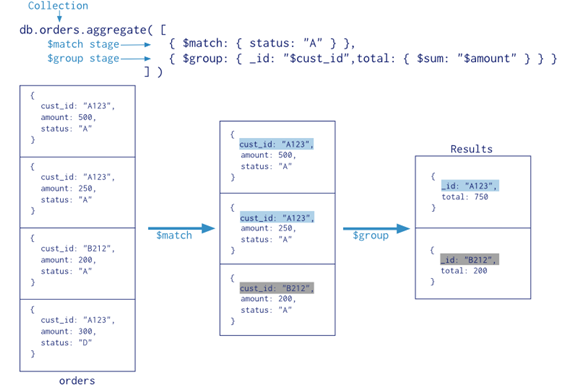
What is an Aggregation Pipeline?
An aggregation pipeline is a series of document transformations which are executed in stages. The original input is a collection whereas the output can be a document,cursor or a collection (shown below).
The most basic pipeline stages provide filters that operate like queries and document transformations that modify the form of the output document.
Other pipeline operations provide tools for grouping and sorting documents by specific field or fields as well as tools for aggregating the contents of arrays, including arrays of documents. In addition, pipeline stages can use operators for tasks such as calculating the average or concatenating a string.
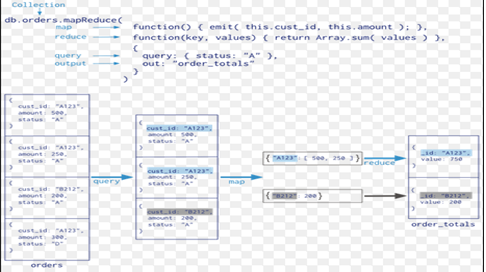
a) MapReduce
MapReduce is a powerful and flexible tool for aggregating data. It can solve problems which are complex in nature and express using the aggregation framework query language.
It splits up a problem, sends chunks of it to different machines, and lets each machine solve its part of the problem. When all the machines are finished, all the pieces of the solution are merged back into a full solution.
b) Single Purpose Aggregation Operations
For a number of common single purpose aggregation operations like returning a count of matching documents, returning the distinct values for a field, and grouping data based on the values of a field; MongoDB provides special purpose database commands.
All of these operations aggregate documents from a single collection. Though these operations provide simple access to common aggregation processes, they lack the flexibility and capabilities of the aggregation pipeline and MapReduce.
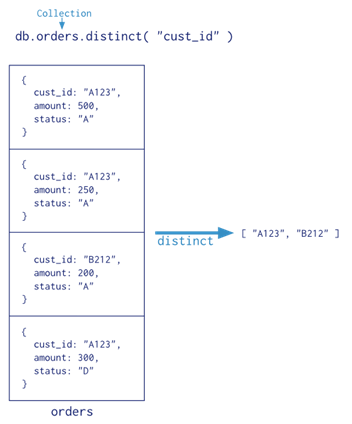
5. Indexes
Indexes are special data structures that store a small portion of the collection’s data set in an easy to traverse form. The index stores the value of a specific field or set of fields, ordered by the value of the field.
The ordering of the index entries supports efficient equality matches and range-based query operations. In addition, MongoDB can return sorted results by using the ordering in the index. The following diagram illustrates a query that selects and orders the matching documents using an index:
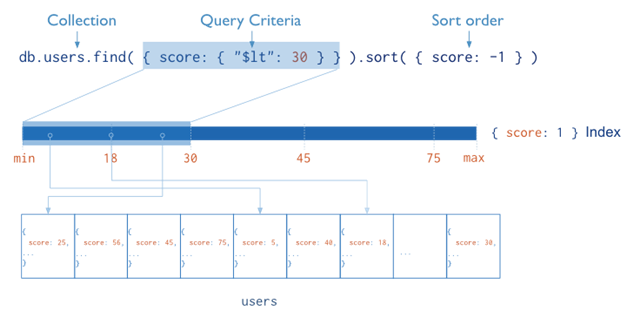
Indexes are used for better query performance. They are created on fields which appear often in queries(_id) and for operations that return sorted results. MongoDB automatically creates a unique index on the _id field. Indexes have the following properties in MongoDB:
- Each index requires at least 8KB of data space.
- Adding an index has some negative performance impact for write operations. For collections with high write-to-read ratio, indexes are expensive since each insert must also update any indexes.
- Collections with high read-to-write ratio often benefit from additional indexes.
- When active, each index consumes disk space and memory. This usage grows over time can becomes significant. Perhaps, for better server space and performance management, it is good practice to track the growth of indexes.
Indexes support the efficient execution of queries. If an appropriate index exists for a query, MongoDB can use the index to limit the number of documents it must inspect.
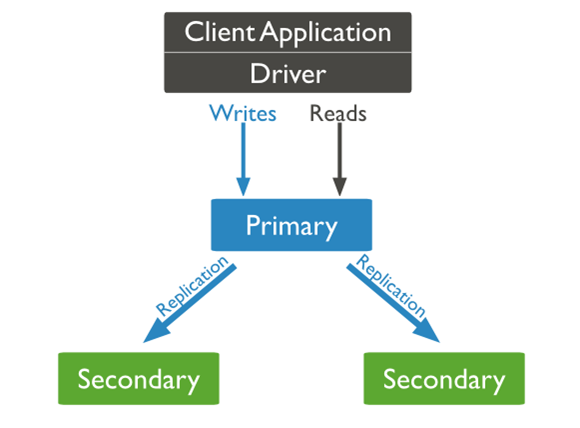
6. Replication
Replication provides redundancy and increases data availability. With multiple copies of data on different database servers, replication protects a database from the loss of a single server allows for recovery from hardware failure and service interruptions.
What is a replica?
A replica set is a group of mongodb instances that host the same data set. One mongodb, the primary, receives all write operations. All other instances, secondaries, apply operations from the primary so that they have the same data set (shown below).
The primary accepts all write operations from clients. A replica set can have only one primary. To support replication, the primary records all changes to its data sets in its oplog (operations log).
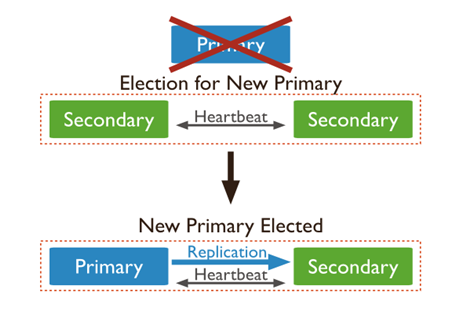
The secondaries replicate the primary’s oplog and apply the operations to their data sets such that the secondaries data sets reflect the primary’s data set. If the primary is unavailable, the replica set will elect a secondary to be primary. When a primary does not communicate with the other members of the set for more than 10 seconds, the replica set will attempt to select another member to become the new primary. The first secondary that receives a majority of votes becomes a primary(shown below).
COMPARISON: Traditional RDBMS vs NoSQL Databases
Comparing NoSQL and MongoDB is like comparing a Lion with a Tiger. Yet, both are predators, one hunts alone and the other in packs.
SQL (tiger) has a rigid data model which needs data to conform to the design of the schema. It is useful for organizing structured data like sales statistics. On the other hand, MongoDB (lion) is a document oriented database, which stores data in the form of documents. Though their approaches are different, both are required for data storage and the selection of the database type depends rather on the organizational need.
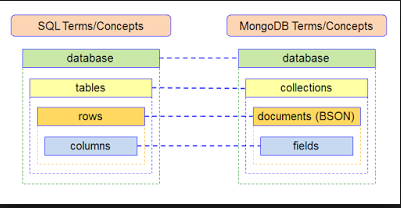
Useful Read: Basics of SQL and RDBMS – A must have skills for data science professional
What are the advantages of using MongoDB ?
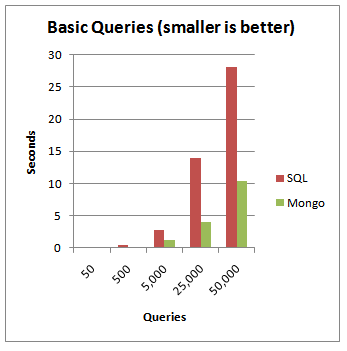
As you can see from the above representation, when the number of queries hitting the server increases, MongoDB is a clear winner. MongoDB is typically used for real-time analytics where latency is low and availability requirements very high.
MongoDB has come to the forefront because of the need of organizations to analyze semi-structured, unstructured and geo-spatial data and because the structure of data is rapidly changing in today’s world. Traditional RDBMS systems are unable to cope with these demands fully as their inherent structure does not allow them do so.
Though changes are being made in RDBMS systems too, to cope with the explosion of data, databases like MongoDB with their document structure are best suited for dealing with today’s data.
What are the limitations of MongoDB?
MongoDB has some limitations which are listed below.
- Max document size is 16 MB.
- Max document nesting level: 100 (documents inside documents inside documents).
- Indexed field can’t contain more than 1024 bytes.
- Max 64 indexes per collection.
- Max 31 fields can be used to create a compound index.
- Full-text search and geo indexes are mutually exclusive.
- Limit of documents in a capped collection can’t be more than 2**32. Otherwise, number of documents is unlimited.
- On windows, mongodb can’t store more than 4 TB of data (8 TB without journal)
- Max 12 nodes in a replica set.
- Max 7 voting nodes in a replica set.
- To rollback more than 300 MB of data manual intervention is needed.
- Group command doesn’t work in sharded cluster.
- $isolated, $snapshot, geoSearch don’t work in a sharded cluster.
- You can’t refer to db object in $where
- For sharding a collection it must be less than 256 GB.
- Individual (not multi) updates/removes in a sharded cluster must include shard key. Multi versions of these commands may not include shard key.
- Max 512 bytes for shard key values.
- Shard key values of a collection cannot be changed once sharding is done.
(Source: www.mongodb.com)
Apart from these, prevention of accidental deletion of records due to constraints in RDBMS systems cannot be implemented in MongoDB or other NoSQL systems. Also there might be other problems like the one shown below, for storing multi-layered data without normalization:
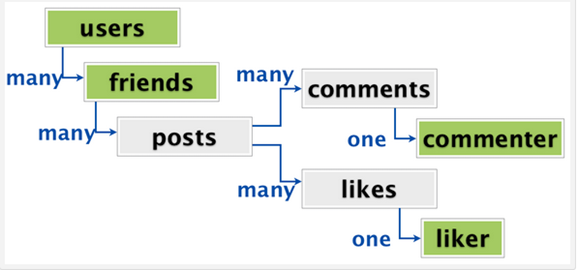
A user has friends who might be a user himself.People who have liked or commented or both can again be users themselves. This type of duplication makes it way harder to de-normalize an activity stream into a single document.
MongoDB also has it’s fair share of limitations and disadvantages and just like any other technology, with improvements they will be hopefully removed.
Installation of Mongo & its admin GUI:
Follow the 7 steps below and complete the installation process of MongoDB:
Step 1: Download MongoDB from MongoDBDownload. Click Download and save it on your machine. You can also select the version according to the OS you use.
Step 2: In case of Windows, locate the downloaded MongoDB .msi file, which typically is located in the default Downloads folder. Double-click the .msi file. A set of screens will appear to guide you through the installation process.
Setup the MongoDB environment:
Step 3: MongoDB requires a data directory to store all data. Its default data directory path is\data\db. Create this folder using the following commands from a Command Prompt:
md \data\db.
By default, this folder gets created in the C: drive.
Start MongoDB:
Step 4: Navigate to the bin folder where the mongod.exe file is located and run the following command in the cmd “C:\Program Files\MongoDB\Server\3.0\bin\mongod.exe”. This should give an output as shown below:

The waiting for connections message indicates MongoDB is running successfully.
Notice the part highlighted in white color; if you do not get this message, it means you haven’t downloaded and installed hotfix prior to running MongoDB.
Connect to MongoDB:
Start 5: To connect to MongoDB, open another command prompt window and type:
“C:\Program Files\MongoDB\Server\3.0\bin\mongo.exe”.
Note: The path is the location of mongo.exe file.
This should give the following message in the cmd window(mongo shell):
Step 6: Download NoSQL Manager for MongoDB from MongoDBManager. This is much like SQL server management studio and I will use this for the purpose of illustration in the article.
Step 7: Click on localhost. This should establish a connection with the instance of MongoDB and the interface will look like as shown below:
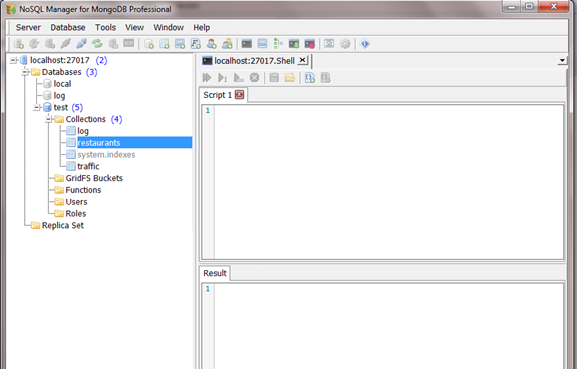
More Admin GUI can be found at: mongoDB admin GUI
With this we complete the installation of MongoDB and its admin GUI.
End Notes
The structural components of MongoDB like data storage in the form of documents and collections, sharding, replication etc. makes it the most widely used No SQL database today. MongoDB also has API’s for connecting with programming languages like Perl,Ruby,Python and R which further makes it attractive to developers and analysts alike. We will be sharing some of these details in one of the future posts.
Did you find this guide useful ? Do let us know your thoughts about this guide in the comments section below.
If you want to learn more about MongoDB you can consider Data Wrangling With MongoDB from Udacity. This will require knowledge of Python.
References : MongoDB manual.







Awesome intro for a layman/funtional guy like me. Thanks Shuvayan for this amazing article. Most of my products are using MongoDB, but I didnot know the uses and limitations of MongoDb
Hi Sudhi, Glad that you liked and found the article useful!!
How many banks and insurance companies did you see in the list of mongoDB users you provided? Do you know why that is? Do you know anything about the tradeoffs made to get that sort of scalability, or do you think it comes for free?
Nice intro about Mongo Db, thanks for writing