Overview
- MongoDB is a popular unstructured database that data scientists should be aware of
- We will discuss how you can work with a MongoDB database using Python (and the PyMongo library)
- We will cover all the basic operations in MongoDB using Python
The Challenge with Structured Databases
We are generating data at an unprecedented pace right now. The scale and size of this data – it’s mind-boggling! Just check out these numbers:
- Facebook generates four petabytes of data in just one day
- Google generates twenty petabytes of data every day
- Furthermore, Large Hadron Collider (27 kilometers long most powerful particle accelerator of the world) generates one petabyte of data per second. Most importantly this data is unstructured
Can you imagine using SQL to work with this volume of data? It’s setting yourself up for a nightmare!
SQL is a wonderful language to learn as a data scientist and it does work well when we’re dealing with structured data. But if your organization works with unstructured data, SQL databases can not fulfill the requirements.
Structured databases have two major disadvantages:
- Scalability: It is very difficult to scale as the database grows larger
- Elasticity: Structured databases need data in a predefined format. It the data is not following the predefined format, relational databases do not store it
So how do we solve this issue? If not SQL then what?

This is where we go for unstructured databases. Among a wide range of such databases, MongoDB is widely used because of its rich query language and quick access with concepts like indexing. In short, MongoDB is best suited for managing big data. Let’s see the difference between structured and unstructured databases:
| Structured Databases | Unstructured Databases | |
| Structure: | Every element has the same number of attributes | Different elements can have different number of attributes. |
| Latency: | Comparatively slower storage | Faster storage |
| Ease of learning: | Easy to learn | Comparatively tougher to learn |
| Storage Volume: | Not appropriate for storing Big Data | Can handle Big Data as well |
| Type of Data Stored: | Generally textual data is stored | Any type of data can be stored (Audio, Video, Clickstraem etc) |
| Examples: | MySQL, PostgreSQL | MongoDB, RavenDB |
This article is the ultimate guide to get started with MongoDB using Python. We will demonstrate various operations on MongoDB with the help of examples and the PyMongo library.
Table of Contents
- What is MongoDB?
- The Architecture of a MongoDB database
- Understanding the Problem Statement
- What is PyMongo?
- Installation Guide for MongoDB
- Basic Operations on the MongoDB database
- Connecting to the database
- Retrieval / Fetching the data
- Insertion
- Filter conditions
- Deletion
- Create a database and collection
- Converting Fetched Data to a Structured Form
- Storing into a Dataframe
- Writing to a file.
- Other Useful functions
1. What is MongoDB?

MongoDB is an unstructured database. It stores data in the form of documents. MongoDB is able to handle huge volumes of data very efficiently and is the most widely used NoSQL database as it offers rich query language and flexible and fast access to data.
Let’s take a moment to understand the architecture of a MongoDB database before we jump into the crux of this tutorial.
The Architecture of a MongoDB Database
The information in MongoDB is stored in documents. Here, a document is analogous to rows in structured databases.
- Each document is a collection of key-value pairs
- Each key-value pair is called a field
- Every document has an _id field, which uniquely identifies the documents
- A document may also contain nested documents
- Documents may have a varying number of fields (they can be blank as well)
These documents are stored in a collection. A collection is literally a collection of documents in MongoDB. This is analogous to tables in traditional databases.

Unlike traditional databases, the data is generally stored in a single collection in MongoDB, so there is no concept of joins (except $lookup operator, which performs left-outer-join like operation). MongoDB has the nested document instead.
2. Understanding the Problem Statement
Let’s understand the problem we’ll be solving in this tutorial. This will give you a good idea of the kind of projects you can pick up to further hone your MongoDB in Python skills.
Suppose you are working for a banking system that provides an application to the customers. This app sends data to your MongoDB database. This data is stored in three collections:
- The accounts collection contains information about all the accounts
- The customers collection contains information about a customer
- Finally, the transactions collection contains the customer transactions data
I have taken the sample database for this tutorial from MongoDB Atlas, a global cloud database service. We will use the ‘sample_analytics’ database to work on this problem statement. This database contains data related to financial services.
3. What is PyMongo?
PyMongo is a Python library that enables us to connect with MongoDB. It allows us to perform basic operations on the MongoDB database.
So, why Python? It’s a valid question.
We have chosen Python to interact with MongoDB because it is one of the most commonly used and considerably powerful languages for data science. PyMongo allows us to retrieve the data with dictionary-like syntax.
We can also use the dot notation to access MongoDB data. Its easy syntax makes our job a lot easier. Additionally, PyMongo’s rich documentation is always standing there with a helping hand. We will use this library for accessing MongoDB.
4. Installation Guide for MongoDB
MongoDB is available for Linux, Windows and Mac OS X operating systems.
If you are a Linux user, follow the instructions in this video:
Mac users can watch this video to install MongoDB:
If you want to install MongoDB on a Windows operating system, refer to this video:
Once you have installed the database, you need to start the mongod service. If you have any problem during the installation, feel free to connect with me in the comments section below this article.
5. Basic Operations on the MongoDB Database
It’s time to fire up your Python notebook and get coding! We have a solid idea of MongoDB – let’s put that knowledge into action.
We will be performing a few key basic operations on a MongoDB database in Python using the PyMongo library.
5.1 Connecting to the Database
To retrieve the data from a MongoDB database, we will first connect to it. Write and execute the below code in your Jupyter cell in order to connect to MongoDB:
Let’s see the available databases:
 We will use the sample_analytics database for our purpose. Let’s set the cursor to the same database:
We will use the sample_analytics database for our purpose. Let’s set the cursor to the same database:
The list_collection_names command shows the names of all the available collections:

Let’s see the number of customers we have. We will connect to the customers collection and then print the number of documents available in that collection:
Output: 500
Here, we can see that we have the data for 500 customers. Next, we will fetch a MongoDB document from this table and see what information is present there.
5.2 Retrieving / Fetching the Data
We can query MongoDB using a dictionary-like notation or the dot operator in PyMongo. In the previous section, we used the dot operator to access the MongoDB database. Here, we will also see a demonstration of a dictionary-like syntax.
First, let’s fetch a single document from the MongoDB collection. We’ll use the find_one function for this purpose:
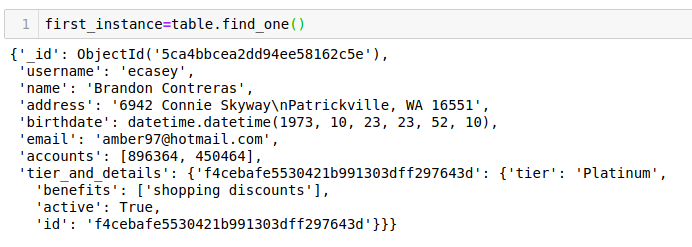
We can see that the function has returned a dictionary. Let’s see the keys of this dictionary and then I will explain the purpose of each key.

We can see some of the keys are self-explanatory. Let me explain what each of these keys is storing:
- _id: MongoDB assigns a unique Id to each document
- username: It contains the username of the user
- name: The name of the user
- address: Address of the user is stored in this field
- birthdate: This argument stores the Date of Birth of the user
- email: This is the email id of a given user
- active: This field tells whether the user is active or not
- accounts: It stores the list of all the accounts held by a given user. A user can have multiple accounts
- teir_and_details: The category (silver, gold, etc.) is stored in this argument. This field also stores the benefits they are entitled to
Now, let’s see an example of dictionary-like access for MongoDB. Let’s fetch the name of the customer from the MongoDB document:

We can also use the find function to fetch the documents. find_one fetches only one document at a time. On the other hand, find can fetch multiple documents from the MongoDB collection:
Here, the sort function sorts the documents in the descending order of _id.
5.3 Insertion Function
insert_one function can be used to insert one document at a time in MongoDB. We will first create a dictionary and then insert it into the MongoDB database:
Output: qwertyui123456
MongoDB is an unstructured database so it is not necessary that all the documents in a collection will follow the same structure.
For example, the dictionary we inserted in the above case does not contain a few of the fields we have seen in the MongoDB document we fetched earlier.
.inserted_id provides the _id field assigned by default if it has not been provided in the dictionary. In our case, we have explicitly provided this field. Finally, the operation returns the _id of the inserted MongoDB document. It is stored in the post_id variable in the above case.
So far, we had to insert only one document in the MongoDB collection. What should we do if we have to insert thousands of documents at once? Will you run insert_one in a loop? Not at all!
We have the insert_many function for this:

We have imported the datetime library because there is no built-in datatype for date and time in Python. This library will help us to assign the values of datetime type. In the above case, we have inserted a list of dictionaries in the MongoDB database. Each element is inserted as an independent document in the MongoDB collection.
5.4 Filter Conditions
We have seen how to fetch data from MongoDB using find and find_one functions. But, we don’t need to fetch all the documents all the time. This is where we apply some filter conditions.
Previously we have inserted a document to the MongoDB collection with the name field as Gyan. Let’s see how to fetch that MongoDB document using the filter condition:

Here, we have fetched the document using the name which is a string argument. On the other hand, we have seen in the previous example that final. inserted_ids contains the Ids of the inserted documents.
If we apply the filter condition on the _id field, it will return nothing because their datatype is ObjectId. This is not the built-in datatype. We need to convert the string value to ObjectId type to apply the filter condition on _id . So first, we will define a function to convert the string value then we will fetch the MongoDB document:

5.5 Deletion
The delete_one function deletes a single document from the MongoDB collection. Previously we had inserted the document for a user named Mike. Let’s have a look at the MongoDB document inserted:

We will now delete this MongoDB document:

Let’s try to fetch this document after deletion. If this document is not available in our MongoDB collection, the find_one function will return nothing.
Output: Nothing is returned.
Since we get nothing in return, it means that the MongoDB document doesn’t exist anymore.
As we saw that the insert_many function is used to insert multiple documents in MongoDB collection, delete_many is used to delete multiple documents at once. Let’s try to delete two MongoDB documents by the name field:
Here, the deleted count stores the number of deleted MongoDB documents during the operation. The ‘$in’ is an operator in MongoDB.
5.6 Creating Database and Collection
The creation of any database and collection is a very simple process in MongoDB. You can use the syntax of retrieval to do this. If you try to access a database which doesn’t exist, MongoDB will create it for you.
Let’s create a database and a collection:
The MongoDB database has been created here but if we run list_database_names, this database will not be listed. MongoDB doesn’t show empty databases. So, we will have to insert something there. Let’s insert a document in the MongoDB collection:
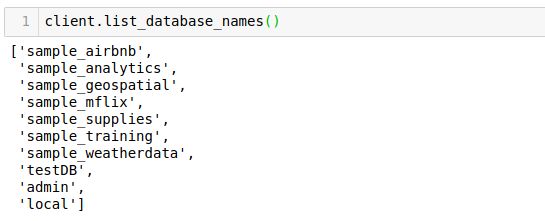
Now we can see that our database is available in the list of MongoDB databases.
6. Converting Unstructured Data to Structured Form
As a data scientist, you not only need to fetch the data but also analyze it. Storing the data in a structured form simplifies this task. In this section, we will learn how to convert the data fetched from MongoDB into a structured format.
6.1 Storing into a Dataframe
The find function returns a dictionary from a MongoDB collection. You can directly insert it into a dataframe. First, let’s fetch 100 MongoDB documents and then we will store these documents into a dataframe:

The readability of this dataframe is far better than that of the default format returned by the function.
6.2 Writing to a File
Pandas dataframes can directly be exported into CSV, Excel or SQL. Let us try to store this data to a CSV file:
Similarly, you can use the to_sql function to export the data into a SQL database.
7. Some Other Useful MongoDB Functions
You have accumulated enough knowledge to start working with MongoDB! We have discussed all the basic operations with examples so far. We also understood several theoretical concepts of MongoDB.
Before I finish this article, let me share a couple of useful functions of PyMongo:
- sort: We have already seen an example of this function. The purpose of this function is to sort the documents
- limit: This function limits the number of MongoDB documents fetched by the find function
There are more MongoDB functions you can check out here.
8. What’s Next?
Once you have mastered the concepts we’ve covered in this tutorial, you should go for more advanced topics related to MongoDB. Let me define a few of these advanced topics:
- Indexing: Indexing is the process of creating an index on some attribute (field) of a collection in MongoDB. It makes the retrieval process faster. In a collection with no index, when you try to filter out a specific document based upon the given condition on a field, it will scan the whole database. This process takes time if there are hundreds of millions of documents. After indexing, MongoDB uses an amount of memory to store the index information. This index lets you jump to a specific document based upon the filter condition without scanning the whole database
- Sharding: The process of storing the data across multiple machines is called sharding. Sharding facilitates horizontal scaling of the database
- Operators: We have already seen the $in operator in MongoDB. There are several other useful operators which perform some specific functions
End Notes
In this article, we learned all the basic concepts of MongoDB. This is good enough to give you a solid start with unstructured databases.
I encourage you to try things on your own and share your experiences in the comments section. Additionally, if you face any problem with any of the above concepts, feel free to ask me in the comments below.
Thanks for reading and keep learning!
Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged. It was popularised in the 1960s with the release of Letraset sheets containing Lorem Ipsum passages, and more recently with desktop publishing software like Aldus PageMaker including versions of Lorem Ipsum.







Look forward to trying this db. I cannot, however, find the sample databases mentioned in the beginning. Is there a specific Jupyter notebook that I cannot find? Kind regards, Poul
Hi Poul, You can find the dataset on this page (along with a few others if you want to practice!): https://docs.atlas.mongodb.com/sample-data/available-sample-datasets/
A wonderful article and learnt a new stuff. Can you share the code for connecting the python with MongoDB.Its not there in section 5.1
My Apologies. Its now showing in the older version of the Chrome but showing in the Newer Version.
I actually wanted to how to store model data into MongoDB and using it in tableau? i mean I have an output from a model. I need to show that in tableau. So for that the output data first needs to be stored in MongoDB and then with the help of a connector in tableau. I know how to save the model using pickle. But how to save the model output?