Introduction
Knowledge is a treasure but practice is the key to it
Lao Tzu philosophy matches our thoughts behind AV hackathons. We believe knowledge can only be useful when it is applied and tested time and again. The motive behind AV hackathons is to challenge your self and realize your true potential.
Our recent hackathon, “The Smart Recruits” was a phenomenal success and we are deeply thankful to our community for their participation. More than 2500 data aspirants made close to 10,000 submissions over a weekend to take the coveted spot.
It was a 48 hour data science challenge and we challenged our community with a real life machine learning challenge. The competition was fierce and top data scientists competed against each other.
As you would know, the best part of our community is that people share their knowledge / approach with fellow community members. Read on to find the secret recipe from the winners, which would help you to improve yourself further.
The Competition
The competition launched on midnight of 23rd July with more than 2500 registration and 48 hours to go and as expected in no time our slack channel was buzzing with discussion. The individuals were pleasantly surprised with the data set and participants were convinced that it’s not a cake walk. Overnight, the heat rose and hackathon platform was bustling with ideas and execution strategies.

The participants were required to help Fintro – a financial distribution company to help assessing potential agents which will be profitable for the company. The evaluation metric used was AUC- ROC.
The Problem Set
Fintro is an offline financial distribution company operating across India from past 10 years. They sell financial products to consumers with the help of agents. The managers at Fintro identify the right talents and recruit these agents. Once the candidate has been hired by the company they undergo a training for next 7 days and have to clear an assessment to become an agent with Fintro. The agents work as freelancers and get paid in commission for each product they sell.
However, Fintro is facing a challenge of not being able to generate enough business from its agents.
The problem – Who are the best agents?
Fintro invests invaluable time and money in recruiting & training the agents. They expect the agent to have selling skills and generate as much business for the company as possible. But some agents don’t perform, as expected.
Fintro has shared the details of all the agents they have recruited from 2007 to 2009. The data contained demographics of the agents hired and the managers who hired them. They want the data scientists to provide insights from past recruitment data and help them identify / hire potential agents.
Winners
The winners used different approaches and rose up on the leaderboard. Below are the top 3 winners on the leaderboard:
Rank 1 – Rohan Rao
Rank 2 – Sudalai Rajkumar and Mark Landry
Rank 3 – Yaasna Dua and Kanishk Agarwal (Qwerty Team)
Here’s the final ranking of all the participants on leaderboard .
For learning of the rest of the community, all the three winners shared their approach and code which they used in The Smart Recruits.
Rank 3 : Yaasna Dua ( New Delhi, India) and Kanishk Agarwal ( Bengaluru, India) – Qwerty Team

Yaasna Dua

Kanishk Agarwal
Yaasna Dua is an Associate Data Scientist at Info Edge and Kanishk Agarwal is an Associate Data Scientist at Sapient Global Networks. They both participated together ( Qwerty Team ) and were the first ones to find the time based insight on a given day.
They said:
This was our first hackathon on Analytics Vidhya. We followed CRISP-DM and concentrated on feature engineering. We ended up creating the following features-
- Applicant’s age and manager’s age on the day the application was received
- Manager’s experience in Fintro when the application was received
- Whether manger was promoted
- Pin difference ,which was a proxy of how far the applicant’s city was from his office
But feature engineering did not give us a good gain. Then we struck gold. Kanishk discovered that the target variable when grouped by application date gave a constant percentage! We incorporated this feature in our model and our score shot up. We tried random forest, xgboost and extra trees. Extra trees gave us the best result. Unfortunately, we did not have enough time to tune the model. Nevertheless, it was a good learning experience and we want to thank Analytics Vidhya for the same.
Solution: Link to Code .
Rank 2 : Sudalai Rajkumar (Chennai, India) and Mark Landry (San Fransico, USA)

Sudalai Rajkumar

Mark Landry
Sudalai Rajkumar is Lead Data Scientist at FreshDesk and Mark Landry is a Competitive Data Scientist and Product Manager at H2O.ai. They both worked together in a team to win The Smart Recruits competition. Their deep knowledge about machine learning and analytics have earned them the high rankings on Kaggle.
They shared :
The solution progression comes in two stages: before the application structure was identified, and after it.
SRK and I both used GBM to model the problem–H2O for me, XGBoost for SRK. We were modeling separately and blending our models together for increased gain on the leaderboard until the second stage.
Both of us immediately paid attention to the time-based competition structure. SRK replicated the competition setup with his internal validation, and I used time as a cross-validation mechanism by using 10 contiguous folds. Doing this showed me early on that the baseline AUC was highly variable: within 10 folds, I would see scores ranging by 0.1, which is an uncomfortably large margin. Finding the application structure helped us avoid the leaderboard shuffle. Understanding the drivers of the variable AUC over time would have been what we spent our final few hours doing to make a careful final submission choice.
Once we saw the big gap emerge in the leaderboard, we started looking at the problem differently. Soon we both found a time relationship emerging at the same time. I further noticed a high correlation between the order in which the applications were received throughout the day. I tested the hypothesis by creating an “order within received date” feature and noticing its correlation with the target was very high. Adding this to my model I was able to jump into second. I later added a “percentage within received date” to help the model deal with varying volume per day, and the total count of applications for each day. Those three features were the highest in my model, and that enabled us to be in first for a short while.
SRK had much cleaner code, so we used his, and that bumped us up even further.
The feature importance chart shows that calculated features were the most heavily used, dominated by those uncovering the application order structure.
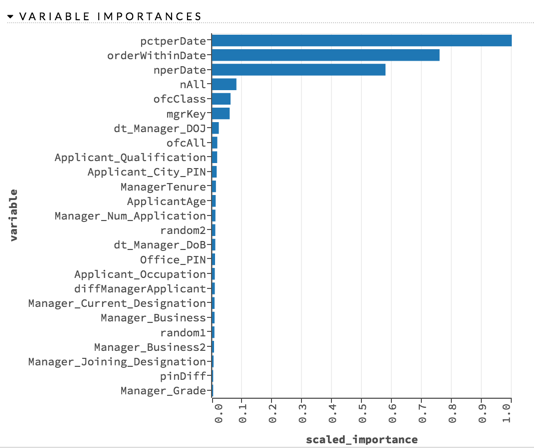
The insight is an interesting one. There could be a real business reason why the applications processed first are more likely to be successful. We cannot tell from the data, but a potential hypothesis is that there is an uncaptured pre-ranking of candidates, such as a test score or the opinion of a human reviewer. In practice, the modeler should then ask to understand the mechanism that is generating the application ID so we can take advantage of it more directly in the model. Presuming the human reviewer hypothesis, it would mean that a human reviewer is more effective than models using the stated features, so we should seek to understand what qualities they are taking into account and allow our model to use those qualities as well. In cases where a machine learning model is sought to automate prediction work already being done manually, those projects are most successful when collaborating with those performing the current process.
Solution : Link to Code
![]()
Rank 1: Rohan Rao ( Bengaluru, India )

Rohan Rao
Rohan Rao is a Lead Data Scientist at AdWyze. Rohan is an adept in machine learing and also won our last hackathon.(Rank 1 in Seer’s Accuracy ).
He says:
I started off with exploring the data after understanding the problem statement, evaluation metric and data dictionary. Tried various forms of summaries and visuals, after which I began the modelling.
Being a binary classification problem with the standard AUC-metric, the usual suspects like logistic regression and XGBoost came into play. Initial results proved XGB far better than LR, and I stuck with that. Once the baseline and pipeline was set, most scores in CV and LB were hovering ~ 0.63 – 0.67. Optimizing parameters didn’t help much either.
The CV-LB movement wasn’t in sync. This turned tricky and a public-private LB shakeup was expected with scores being close. I dug back into the data trying to find a feature/pattern which can boost my model. And this proved to be a great decision.
While plotting the target variable for a sample set of days, I found a glaring pattern. Within a day, a large proportion of positive samples appeared in the first half, and vice-versa. At first, it seemed too good to be true. I quickly created a feature based on ordering and saw a big jump in CV score, crossing the 0.8 mark. On exploring this pattern in detail, I was unsure whether it is leakage or whether it is just a pattern that applications received initially in the day are more likely to be accepted than ones later. Either ways, the data showed this and I used it in my model.
I polished this ordering feature using the variable ‘Order_Percentile’ which normalized the order of applications within a day to [0,1] and this was the winning feature which led me to my final score of 0.885 on the public LB and 0.766 on the private LB, ranked 1st.
My final model consisted of 14 features, with the other 13 being cleaned up features from the raw variables. I achieved a CV of 0.882 which was in the same range as the LB. I’d have liked to try out some more parameter tuning and ensembling, but with the limited duration of a hackathon, there wasn’t any time left.
Exploring the data and finding patterns/features will always give better returns than blindly modelling data. This is another good example of how feature engineering is one of the most powerful and crucial elements of building successful machine-learning solutions.
Solution: Link to Code
End Notes
It was great interacting with these winners and know their approach during the competition. Hopefully you will be able to evaluate where you missed out. Check out all the upcoming competitions here.
What are your opinions and suggestion about these approaches? Tell us in the comments below.
You can test your skills and knowledge. Check out Live Competitions and compete with best Data Scientists from all over the world.
Kunal Jain is the Founder and CEO of Analytics Vidhya, one of the world's leading communities of Al professionals. With over 17 years of experience in the field, Kunal has been instrumental in shaping the global Al landscape. His expertise spans diverse markets, from developed economies like the UK to emerging ones like India, where he has successfully led and delivered complex data-driven solutions. As a recognized thought leader, Kunal has empowered countless individuals to realize their Al ambitions through his visionary approach to Al education and community building. Before founding Analytics Vidhya, Kunal earned both his undergraduate and postgraduate degrees from IIT Bombay and held key roles at Capital One and Aviva Life Insurance across multiple geographies. His passion lies at the intersection of analytics, Al, and fostering a thriving community of data science professionals.






Please provide Dataset as well, So beginners can practice and learn well.
Hi Gokul, We will soon be launching it in form of practice problem.
Also provide code for "Rank 2 : Sudalai Rajkumar and Mark Landry".
Tanks to the winners for posting the solution, this really helps. The patterns that were discovered in the data was impressive.