You can think of machine learning algorithms as an armoury packed with axes, swords, and blades. You have various tools, but you ought to learn to use them at the right time. As an analogy, think of ‘Linear Regression or Logistic Regression’ as a sword capable of slicing and dicing data efficiently but incapable of dealing with highly complex data. Similarly, a deep learning neural network is a lightsaber that can handle complex data. On the contrary, ‘Support Vector Machines’ or SVM, a machine learning algorithm, is like a sharp knife – it works on smaller datasets, but on them, it can be much more powerful in building models.
Table of Contents
About the Skill Test
This skill test was designed to test your knowledge of SVM, a supervised learning model, its techniques, and applications. These data science interview questions are useful for those of you wishing to grab a job as a data scientist. More than 550 people registered for the test. If you missed out on this skill test, here are the questions and solutions.
Here is the leaderboard for the participants who took the test.
Below is the distribution of the scores of the participants:
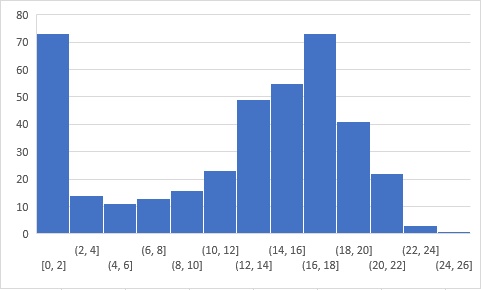
You can access the scores here. More than 350 people participated in the skill test; the highest score was 25.
Helpful Resources
There are plenty of courses and tutorials available online
Here are some resources to get in-depth knowledge of the subject.
- Essentials of Machine Learning Algorithms (with Python and R Codes)
- Understanding Support Vector Machine algorithm from examples (along with code)
- Free Course on Support Vector Machines (SVM) using Python and R
If you are just getting started with Machine Learning and Data Science, here is a course to assist you in your journey to Master Data Science and Machine Learning models. Check out the detailed course structure in the link below:
SVM Skill Test Questions & Answers
Let us now look at some SVM test questions and answers which will be helpful.
Question Context: 1 – 2
Suppose you are using a linear SVM classifier with a two-class classification problem. Now, you have been given the following data, in which some points are circled red and represent support vectors.
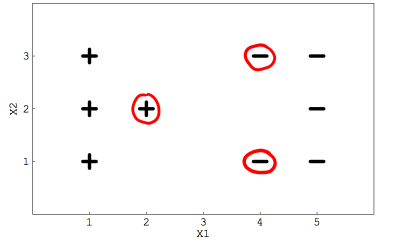
Q1. If you remove the following, anyone red points from the data. Will the decision boundary change?
A) Yes
B) No
Solution: A
Explanation: These three examples are positioned such that removing any one of them introduces slack in the constraints. So the decision boundary would completely change.
Q2. [True or False] If you remove the non-red circled points from the data, the decision boundary will change?
A) True
B) False
Solution: B
Explanation: The rest of the data points will, on the other hand, not significantly affect the decision boundary.
Q3. What do you mean by generalization error in terms of the SVM?
A) How far the hyperplane is from the support vectors
B) How accurately the SVM can predict outcomes for unseen data
C) The threshold amount of error in an SVM
Solution: B
Explanation: Generalisation error in statistics is generally the out-of-sample error, which measures how accurately a model can predict values for previously unseen data.
Q4. When the C parameter is set to infinite, which of the following holds true?
A) The optimal hyperplane, if exists, will be the one that completely separates the data
B) The soft-margin classifier will separate the data
C) None of the above
Solution: A
Explanation: At such a high level of misclassification penalty, a soft margin will not hold existence as there will be no room for error.
Q5. What do you mean by a hard margin?
A) The SVM allows a very low error in classification
B) The SVM allows a high amount of error in the classification
C) None of the above
Solution: A
Explanation: A hard margin means that an SVM is very rigid in classification and tries to work extremely well in the training set, causing overfitting.
Q6. The minimum time complexity for training an SVM is O(n2). According to this fact, what sizes of datasets are not best suited for SVMs?
A) Large datasets
B) Small datasets
C) Medium-sized datasets
D) Size does not matter
Solution: A
Explanation: Datasets with a clear classification boundary will function best with SVMs.
Q7. The effectiveness of an SVM depends upon _____________.
A) Selection of Kernel trick
B) Kernel Parameters
C) Soft Margin Parameter C
D) All of the above
Solution: D
Explanation: The effectiveness of the SVM depends upon how you choose the basic 3 requirements mentioned above to maximize efficiency and reduce error and overfitting.
Q8. Support vectors are the data points that lie closest to the decision surface.
A) TRUE
B) FALSE
Solution: A
Explanation: They are the points closest to the hyperplane and the hardest to classify. They also directly affect the location of the decision surface.
Q9. The SVM’s are less effective when:
A) The data is linearly separable
B) The data is clean and ready to use
C) The data is noisy and contains overlapping points
Solution: C
Explanation: When the data has noise and overlapping points, drawing a clear hyperplane without misclassifying is difficult.
Q10. Suppose you are using RBF (radial basis factor) kernel in SVM with a high Gamma value. What does this signify?
A) The model would consider even far away points from the hyperplane for modeling
B) The model would consider only the points close to the hyperplane for modeling
C) The model would not be affected by the distance of points from the hyperplane for modeling
D) None of the above
Solution: B
Explanation: The gamma parameter in SVM tuning signifies the influence of points near or far away from the hyperplane.
For a low gamma, the model will be too constrained and include all points of the training dataset without capturing the shape.
For a higher gamma, the model will capture the shape of the dataset well.
Q11. The cost parameter in the SVM means:
A) The number of cross-validations to be made
B) The kernel to be used
C) The tradeoff between misclassification and simplicity of the model
D) None of the above
Solution: C
Explanation: The cost parameter decides how much an SVM should be allowed to “bend” with the data. For a low cost, you aim for a smooth decision surface; for a higher cost, you aim to classify more points correctly. It is also simply referred to as the cost of misclassification.
Question Context: 12 – 13
Suppose you are building an SVM model on data X. The data X can be error-prone, meaning you should not trust any specific data point too much. Now, think that you want to build an SVM model with a quadratic kernel function of polynomial degree 2 that uses Slack variable C as one of its hyperparameters. Based upon that, answer the following question.
Q12. What would happen when you use a very large value of C(C->infinity)?
Note: For small C was also classifying all data points correctly
A) We can still classify data correctly for a given setting of hyperparameter C
B) We can not classify data correctly for a given setting of hyperparameter C
C) Can’t Say
D) None of these
Solution: A
Explanation: The penalty for misclassifying points is very high for large values of C, so the decision boundary will perfectly separate the data if possible.
Q13. What would happen when you use a very small C (C~0)?
A) Misclassification would happen
B) Data will be correctly classified
C) Can’t say
D) None of these
Solution: A
Explanation: Because the penalty is so low, the classifier can maximize the margin between most of the points while misclassifying a few points.
Q14. If I am using all features of my dataset and I achieve 100% accuracy on my training data set but ~70% on the validation set of data, what should I look out for?
A) Underfitting
B) Nothing; the model is perfect
C) Overfitting
Solution: C
Explanation: If we easily achieve 100% training accuracy, we need to check to verify whether we’re overfitting our data.
Q15. Which of the following are real-world applications of the SVM?
A) Text and Hypertext Categorization (NLP)
B) Image Classification
C) Clustering of News Articles
D) All of the above
Solution: D
Explanation: SVMs are highly versatile models that can be used for practically all real-world problems ranging from regression by svm regression model to clustering and handwriting recognition.
Question Context: 16 – 18
Suppose you have trained an SVM with a linear decision boundary. After training SVM, you correctly infer that your SVM model is underfitting.
Q16. Which of the following option would you be more likely to consider iterating SVM next time?
A) You want to increase your data points
B) You want to decrease your data points
C) You will try to calculate more variables
D) You will try to reduce the features
Solution: C
Explanation: The best option here is to create more model features.
Q17. Suppose you gave the correct answer to the previous question. What do you think that is actually happening?
1. We are lowering the bias
2. We are lowering the variance
3. We are increasing the bias
4. We are increasing the variance
A) 1 and 2
B) 2 and 3
C) 1 and 4
D) 2 and 4
Solution: C
Explanation: Better model will lower the bias and increase the variance
Q18. In the above question, which of the (SVM) hyperparameters would you have to change so that the model will not underfit?
A) We will increase the parameter C
B) We will decrease the parameter C
C) Changing in C doesn’t affect underfitting
D) None of these
Solution: A
Explanation: Increasing the C parameter would be the right thing to do here, as it will ensure regularize the model
Q19. We usually use feature normalization before using the Gaussian kernel in SVM. What is true about feature normalization?
1. We do feature normalization so that new features will dominate others.
2. Sometimes, feature normalization is not feasible for categorical variables.
3. Feature normalization always helps when we use the Gaussian kernel in SVM.
A) 1
B) 1 and 2
C) 1 and 3
D) 2 and 3
Solution: B
Explanation: Statements one and two are correct.
Question Context: 20-22
Suppose you are dealing with a 4-class classification problem and want to train an SVM model on the data. For that, you are using the One-vs-all method. Now answer the below questions.
Q20. How many times do we need to train our SVM model in such a case?
A) 1
B) 2
C) 3
D) 4
Solution: D
Explanation: If you are using a one-vs-all method for a four-class problem, you would have to train the SVM at least four times.
Q21. Suppose you have the same distribution of classes in the data. Now, say for training 1 time in a one vs. all set, the SVM is taking 10 seconds. How many seconds would it require to train the one-vs-all method end to end?
A) 20
B) 40
C) 60
D) 80
Solution: B
Explanation: It would take 10×4 = 40 seconds
Q22. Suppose your problem has changed now. Now, data has only 2 classes. What would you think about how many times we need to train SVM in such a case?
A) 1
B) 2
C) 3
D) 4
Solution: A
Explanation: Training the SVM only one time would give you appropriate results
Question context: 23 – 24
Suppose you are using SVM with a linear kernel of polynomial degree 2. Now think that you have applied this on data and found that it perfectly fits the data, which means the training and testing accuracy is 100%.
Q23. Now, think that you increase the complexity (or degree of the polynomial of this kernel). What would you think will happen?
A) Increasing the complexity will overfit the data
B) Increasing the complexity will underfit the data
C) Nothing will happen since your model was already 100% accurate
D) None of these
Solution: A
Explanation: Increasing the complexity of the data would cause the algorithm to overfit it by having a highly non-linear boundary.
Q24. In the previous question, you found that training accuracy was still 100% after increasing the complexity. According to you, what is the reason behind that?
1. Since data is fixed and we are fitting more polynomial terms or parameters, so the algorithm starts memorizing everything in the data.
2. Since data is fixed and SVM doesn’t need to search in big hypothesis space.
A) 1
B) 2
C) 1 and 2
D) None of these
Solution: C
Explanation: Both the given statements are correct.
Q25. What is/are true about kernel in SVM?
1. Kernel function map low dimensional input data to high dimensional space
2. It’s a similarity function
A) 1
B) 2
C) 1 and 2
D) None of these
Solution: C
Explanation: Both the given statements are correct.
Conclusion
You have now covered 25 important Support Vector Machines (SVM) interview questions that I hope have helped increase your knowledge in the subject. While preparing for your next data science interview, do check out our other skill tests, which comprise interview questions and answers on topics ranging from SQL and random forest to data analysis and k-nearest neighbour.
Here are a few articles that might be useful for your interview:
- How to Prepare for an AI Job Interview?
- 5 Strategies for Acing Your AI Technical Interview
- Top 10 Telephonic Interview Tips
- How to Introduce Yourself in a Job Interview?
- Tips and Tricks to Crack Campus Placement in Data Science
Ankit is currently working as a data scientist at UBS who has solved complex data mining problems in many domains. He is eager to learn more about data science and machine learning algorithms.






Answer to Q17 seems wrong may be because of Typo. Also could you please have some explanation on the answers?
Initially, it is known that there is a underfitting situation. And solution of 16th question suggest that underfitting can be reduced by introducing more variables in the model. That means model will become more complex if we introduce variables and in such case we can say that we are reducing the bias and increasing the variance.
4) When the C parameter is set to infinite, which of the following holds true? A) The optimal hyperplane if exists, will be the one that completely separates the data B) The soft-margin classifier will separate the data C) None of the above Solution: A At such a high level of misclassification penalty, soft margin will not hold existence as there will be no room for error. Please help to understand
Since the the parameter C tends to infinity, misclassification error would be zero.
For question 20, how is the answer 3? Shouldn't it be 4?
Thanks for noticing, Answer marked is incorrect though solution is right.