This article was published as a part of the Data Science Blogathon.
Introduction
Support vector machine is one of the most famous and decorated machine learning algorithms in classification problems. The heart and soul of this algorithm is the concept of Hyperplanes where these planes help to categorize the high dimensional data which are either linearly separable or not, and that is the USB of this algorithm that it can deal with real-world complex situations where most of the time data is non-linear and there comes the role of SVM kernels.
By far, you have got the importance of its algorithm, though, in most of the interviews, candidates do focus on the tree-based algorithm, but it has some serious use cases in the real world, which make it one of the hot topics for interviewers to ask for. Hence, in this article, we are gonna discuss the 10 most asked interview questions on SVM.
Interview Questions on SVM
1. In what conditions will you choose SVM over any other algorithm?
There are many reasons why ML engineers will prefer SVM over other algorithms. Some are mentioned below:
- SVM outperforms any other competitor when it comes to dealing with high-dimensional data along with PCA (helps in reducing the less important feature from the sample space). SVM, on the other side, tends to increase the dimensions to categorize the related features.
- When it comes to dealing with Non-linear datasets, then, it should be the first choice as linear separable data is easy to handle, but in the real world, we will always encounter non-linear datasets, so, in that case, SVM’s quality of converting the data into higher dimensions works.
- As the supervised machine learning algorithm, SVM has put its foot forward for unstructured data and semi-structured like images, text, and videos.
- The SVM kernels are the real strength of SVM, sometimes to deal with complex problems we need to go for higher dimensionality, which tends to have complex mathematical calculations so to perform smooth calculations, SVM kernels play a vital role as it provides certain coefficients values like gamma and Cost-C.
2. What are the drawbacks of using SVM for classification tasks?
- One of the most encountered drawbacks of this algorithm is that it takes a lot of training time as soon as we start feeding the larger dataset during the model development phase.
- It is always difficult to choose a good kernel function because we are looking for that optimal coefficient value that will perform with better accuracy, at the same time it will be a bad idea to choose the hit and trial method as most of them take soo much time in model training.
- Hyperparameter tuning in SVM is pretty complex to deal with because of the two main parameters i.e. Cost-C and Gamma as it is not a cup of tea to fine-tune these hyperparameters.
3. Is feature scaling a required step while working with SVM?
Yes, feature scaling is a very much important step to be followed while we are solving our problems using SVM as feature scaling (Standardization or Normalization) is required in every algorithm where distances are considered between the observations.
In SVM as well we are aiming to maximize the margin so that we will have a better accuracy directly or indirectly distances are involved hence, feature scaling is also required.
4. How SVM is impacted when the dataset has missing values?
SVMs are usually considered to be the ideal choice in terms of constructing the model for classification, but at the same time, they cannot deal with missing data in fact it is quite sensitive to missing data which leads to bad model accuracy on testing data. That’s why it is recommended that we should deal with all the missing values either during data cleaning or the feature engineering phase.
5. What are the possible outcomes if outliers are present in the dataset?
Being quite popular in the classification genre, SVM has one major drawback, i.e., it is very much sensitive to outliers it is because of the penalty that each misclassification returns, which we know as a hinge or convex loss, but this loss don’t make it sensitive to outliers it’s the outbounds of convex loss that makes SVM sensitive to outliers. Read this for in-depth knowledge.
6. How can one avoid the condition of overfitting in SVM?
Before moving forward with this answer, we need to understand 2 terminologies in SVM:
- Soft margin: In this case, SVM is not that rigid on the classification i.e. it is not that strict on training data to classify each data point correctly.
- Hard margin: Just opposite of soft margin (obviously!), here it is extreme towards making every classification to be right in terms of the training data sample and very rigid too.
So, now let’s come to our question; we all are well aware of the fact that if we become very much dependent on the training data sample’s accuracy, then it will lead to overfitting conditions while to make a generalized model we need something elastic to both training and testing data hence, the soft margin should be ideal choice to avoid overfitting condition.
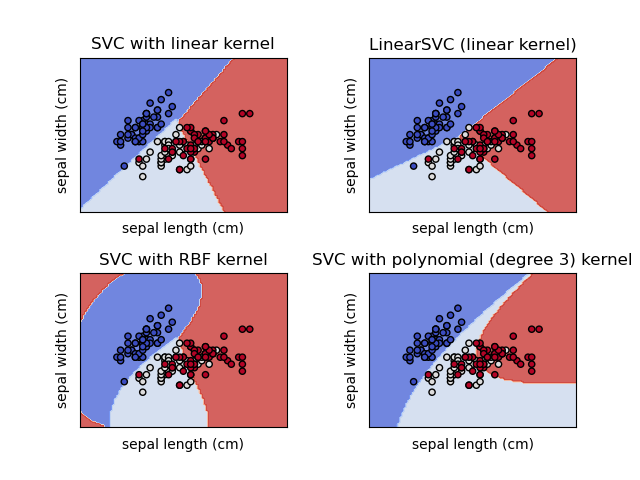
7. How is kernel trick helpful in SVM?
When we are choosing SVM for solving classification problems, our main goal is to attain the maximum margin i.e., the decision boundary between the classes that are to be separated. Still, this activity in real-world setup is quite complex because there we are dealing with non-linear data most of the time, so to save us from this situation SVM kernel can rescue us which using some functions like polynomial and Sigmoid to convert the dataset from lower dimension to higher dimension which later makes it easy to separate the complex dataset.
There are many kernel functions available for usage. I’m listing down some popular ones here:
- Linear
- Non-Linear
- Polynomial
- RBF – Radial basis function
- Sigmoid
8. How is SVM different from K-Nearest Neighbors (KNN)?
- The very first difference between both is, that Linear SVM is parametric because of its nature of producing linear boundaries while KNN is non-parameterized as it ignores the prior assumptions about the structure of class boundary that in turn, makes it flexible enough to deal with non-collinear boundaries.
- SVM has the upper hand in variance as KNN has a higher variance than linear SVM. Still, KNN can adapt to any classification boundary even when the class boundary is unknown. As the training data increases, KNN reaches the capability where it reaches the optimal classification boundary.
- KNN does not have any structure for the class boundaries, so the classes created by KNN are less interpretable if we compare them with linear SVM.
9. Which among SVM and Logistic regression is the better algorithm for handling outliers?
When it comes to logistic regression then, outliers could have a bigger impact on the model as the estimation factors that are involved in logistic regression coefficients are more likely to be sensitive to outliers.
On the other hand, outliers, when introduced in the SVM model then it can shift the position of the hyperplane but not as much as they can do in the case of logistic regression also, in SVM, we can deal with outliers by introducing slack variables.
Conclusively, SVM handles outliers more efficiently than Logistic Regression though both of them are affected by outliers.
Conclusion
So, we have discussed the top 9 most asked interview questions on SVM in depth. I kept the discussion as in-depth as possible so the one who is reading this article could also answer any related cross-questions from the interviewer as well. In this section of the article, we are gonna discuss everything we learned in a nutshell.
- First, we started with some basic questions like the advantages and drawbacks of the SVM algorithm but kept the questions twisted so that one could be comfortable with twisted yet basic questions asked by the interviewer. Then we move to feature engineering-related stuff, where we discovered that SVM is very sensitive to outliers and missing values.
- Then we leveled up where we saw how SVM could avoid headache situations like overfitting. Later we went through the importance of SVM kernels in complex non-linear datasets.
- At the last, we jumped to comparison-based interview questions where first we saw How SVM differs from the KNN algorithm related to what is happening in the background. At last, We saw that when compared with logistic regression, SVM seems better at handling outlier
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.






