Overview
- Working on Data Science projects is a great way to stand out from the competition
- Check out these 7 data science projects on GitHub that will enhance your budding skillset
- These GitHub repositories include projects from a variety of data science fields – machine learning, computer vision, reinforcement learning, among others
Introduction
Are you ready to take that next big step in your data science journey? Working on small datasets and using popular data science libraries and frameworks is a good start. But if you truly want to stand out from the competition, you need to take a leap and differentiate yourself.
A brilliant way to do this is to do a project on the latest breakthroughs in data science. Want to become a Computer Vision expert? Learn how the latest object detection algorithm works. If Natural Language Processing (NLP) is your calling, then learn about the various aspects and off-shoots of the Transformer architecture.
My point is – always be ready and willing to work on new data science techniques. This is one of the fastest-growing fields in the industry and we as data scientists need to grow along with it.
So, let’s check out 7 data science GitHub projects that can help you upskill your knowledge. As always, I have kept the domain broad to include projects from machine learning to reinforcement learning.
And if you have come across any library that isn’t on this list, let the community know in the comments section below this article!
Table of contents
Top Data Science GitHub Projects

I have divided these data science projects into three broad categories:
- Machine Learning Projects
- Deep Learning Projects
- Programming Projects
Machine Learning Projects
pyforest – Importing all Python Data Science Libraries in One Line of Code
I really, really like this Python library. As the above heading suggests, your typical data science libraries are imported using just one library – pyforest. Check out this quick demo I’ve taken from the library’s GitHub repository:
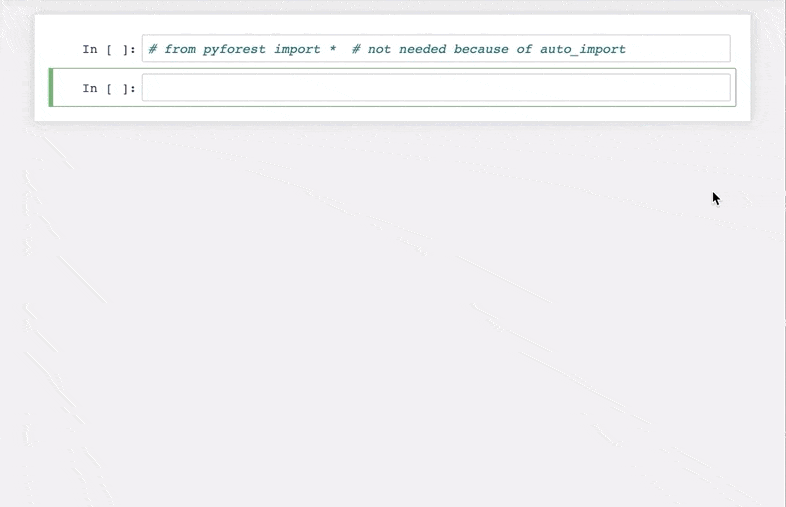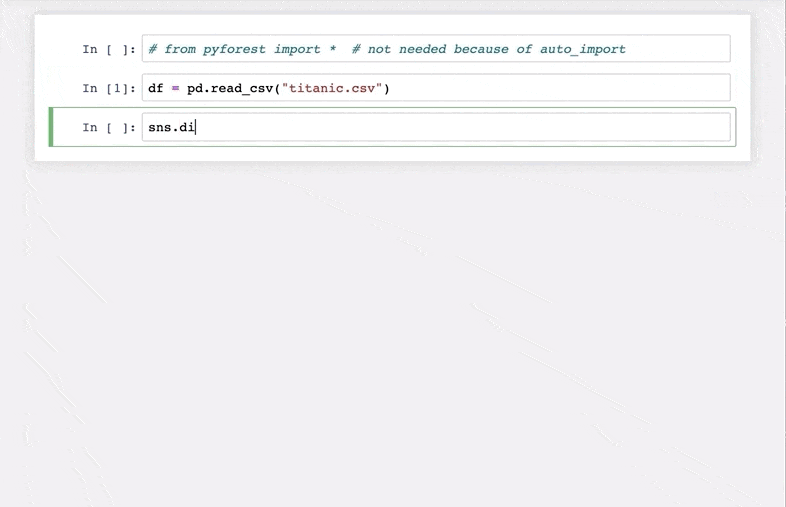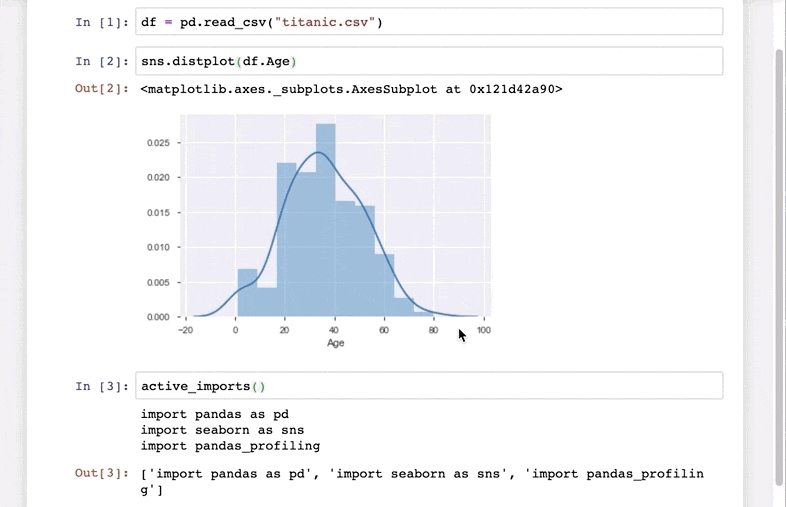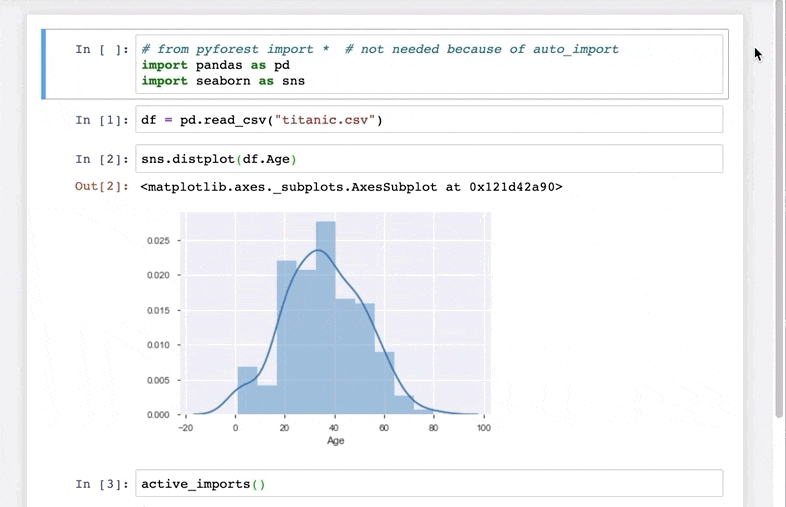
Excited yet? pyforest currently includes pandas, NumPy, matplotlib, and many more data science libraries.
Just use pip install pyforest to install the library on your machine and you’re good to go. And you can import all the popular Python libraries for data science in just one line of code:
from pyforest import *Awesome! I’m thoroughly enjoying using this and I’m certain you will as well. You should check out the below free course on Python if you’re new to the language:
Click here to explore this Github data science project.
HungaBunga – A Different Way of Building Machine Learning Models using sklearn
How do you pick the best machine learning model from the ones you’ve built? How do you ensure the right hyperparameter values are in play? These are critical questions a data scientist needs to answer.
And the HungaBunga project will help you reach that answer faster than most data science libraries. It runs through all the sklearn models (yes, all!) with all the possible hyperparameters and ranks them using cross-validation.

Here’s how to import all the models (both classification and regression):
from hunga_bunga import HungaBungaClassifier, HungaBungaRegressorYou should check out the below comprehensive article on supervised machine learning algorithms Commonly used Machine Learning Algorithms (with Python and R Codes)
Click here to explore this Github data science project.
Deep Learning Projects
Behavior Suite for Reinforcement Learning (bsuite) by DeepMind

Deepmind has been in the news recently for the huge losses they have posted year-on-year. But let’s face it, the company is still clearly ahead in terms of its research in reinforcement learning. They have bet big on this field as the future of artificial intelligence.
So here comes their latest open source release – the bsuite. This project is a collection of experiments that aims to understand the core capabilities of a reinforcement learning agent.
I like this area of research because it is essentially trying to fulfill two objectives (as per their GitHub repository):
- Collect informative and scalable issues that capture key problems in the design of efficient and general learning algorithms
- Study the behavior of agents via their performance on these shared benchmarks
The GitHub repository contains a detailed explanation of how to use bsuite in your projects. You can install it using the below code:
pip install git+git://github.com/deepmind/bsuite.gitIf you’re new to reinforcement learning, here are a couple of articles to get you started:
- Simple Beginner’s Guide to Reinforcement Learning & its Implementation
- A Hands-On Introduction to Deep Q-Learning using OpenAI Gym in Python
Click here to explore this Github data science project.
DistilBERT – A Lighter and Cheaper Version of Google’s BERT
You must have heard of BERT at this point. It is one of the most popular and quickly becoming a widely-adopted Natural Language Processing (NLP) framework. BERT is based on the Transformer architecture.
But it comes with one caveat – it can be quite resource-intensive. So how can data scientists work on BERT on their own machines? Step up – DistilBERT!
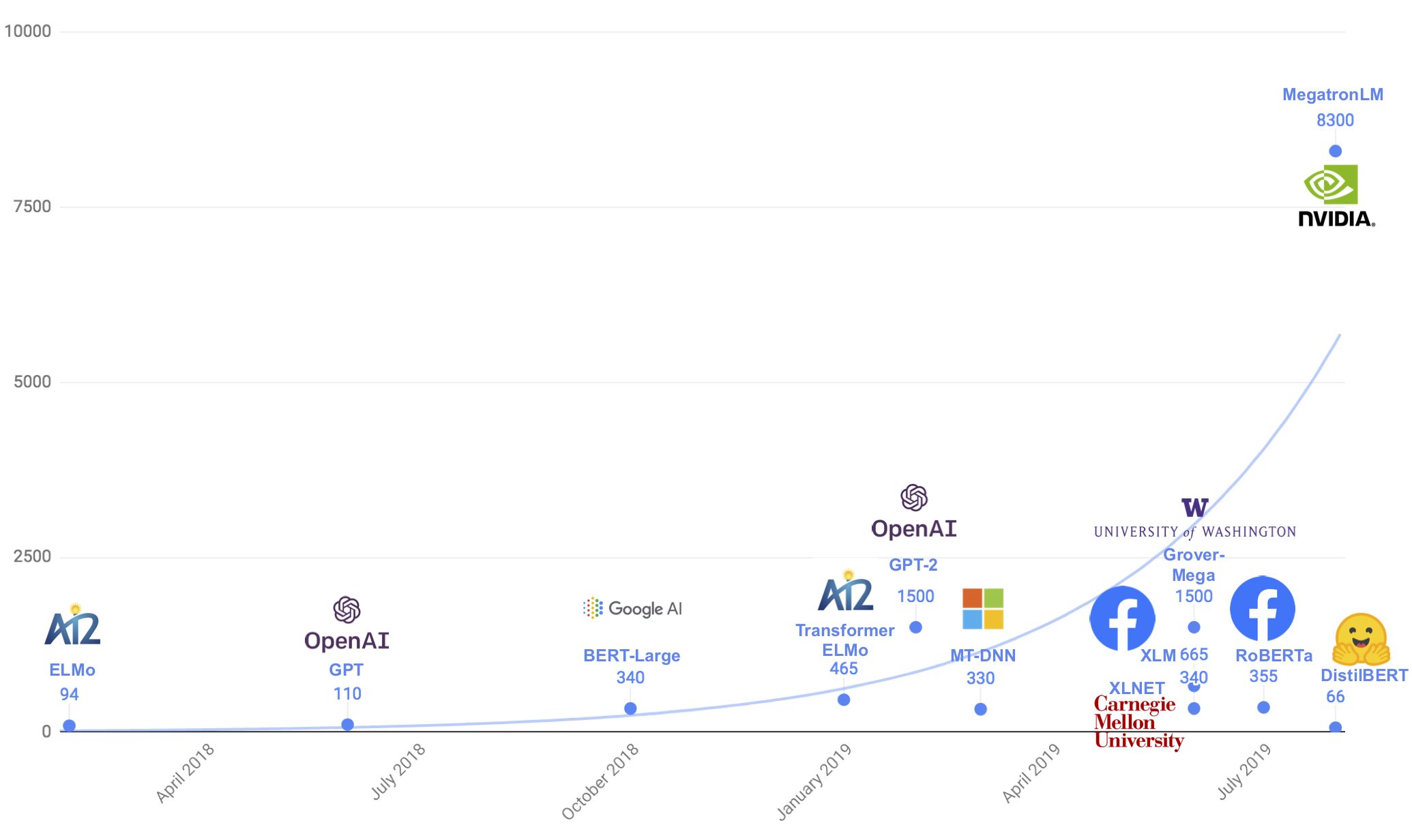
DistilBERT, short for Distillated-BERT, comes from the team behind the popular PyTorch-Transformers framework. It is a small and cheap Transformer model built on the BERT architecture. According to the team, DistilBERT runs 60% faster while preserving over 95% of BERT’s performances.
This GitHub repository explains how DistilBERT works along with the Python code. You can learn more about PyTorch-Transformers and how to use it in Python here:
Click here to explore this Github data science project.
ShuffleNet Series – An Extremely Efficient Convolutional Neural Network for Mobile Devices
A computer vision project for you! ShuffleNet is an extremely computation-efficient convolutional neural network (CNN) architecture. It has been designed for mobile devices with very limited computing power.

This GitHub repository includes the below ShuffleNet models (yes, there are multiple):
- ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
- ShuffleNetV2: Practical Guidelines for Efficient CNN Architecture Design
- ShuffleNetV2+: A strengthened version of ShuffleNetV2.
- ShuffleNetV2.Large: A deeper version based on ShuffleNetV2.
- OneShot: Single Path One-Shot Neural Architecture Search with Uniform Sampling
- DetNAS: DetNAS: Backbone Search for Object Detection
So are you looking to understand CNNs? You know I have you covered:
Click here to explore this data science project.
RAdam – Improving the Variance of Learning Rates
RAdam was released less than two weeks ago and it has already accumulated 1200+ stars. That tells you a lot about how well this repository is doing!
The developers behind RAdam show in their paper that the convergence issue we face in deep learning techniques is due to the undesirably big variance of the adaptive learning rate in the early stages of model training.
RAdam is a new variant of Adam, that rectifies the variance of the adaptive learning rate. This release brings a solid improvement over the vanilla Adam optimizer which does suffer from the issue of variance.
Here is the performance of RAdam compared to Adam and SGD with different learning rates (X-axis is the number of epochs):

You should definitely check out the below guide on optimization in machine learning (including Adam):
Checkout this data science project here.
Programming Projects
ggtext – Improved Text Rendering for ggplot2
This one is for all the R users in our community. And especially all of you who work regularly with the awesome ggplot2 package (which is basically everyone).

The ggtext package enables us to produce rich-text rendering for the plots we generate. Here are a few things you can try out using ggtext:
- A new theme element called element_markdown() renders the text as markdown or HTML
- You can include images on the axis (as shown in the above picture)
- Use geom_richtext() to produce markdown/HTML labels (as shown below)
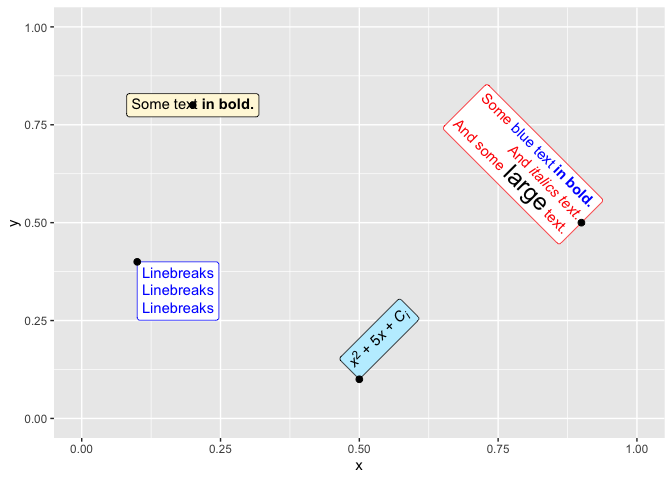
The GitHub repository contains a few intuitive examples which you can replicate on your own machine.
ggtext is not yet available through CRAN so you can download and install it from GitHub using this command:
devtools::install_github("clauswilke/ggtext")Want to learn more about ggplot2 and how to work with interactive plots in R? Here you go:
- 10 Questions R Users always ask while using ggplot2 package
- How I Built Animated Plots in R to Analyze my Fitness Data (and you can too!)
Click here to explore this data science project.
End Notes
I love working on these monthly articles. The amount of research and hence breakthroughs happening in data science are extraordinary. No matter which era or standard you compare it with, the rapid advancement is staggering.
Which data science project did you find the most interesting? Will you be trying anything out soon? Let me know in the comments section below and we’ll discuss ideas!
Senior Editor at Analytics Vidhya.Data visualization practitioner who loves reading and delving deeper into the data science and machine learning arts. Always looking for new ways to improve processes using ML and AI.




Great article. I am not in data science but fascinated by these techniques, In particular, RAdam optimization. Can you show an example where waveform fitting (e.g. seismic waves) is optimized with a similar technique? Thanks!
Thanks Pranav. These projects are fabulous. One question on Hunga Bunga. For some of the classifiers like LR and Naive Bayes, we need to do scaling or normalization of features. So does this library handle them as well without we doing it at our end.
This article is written with a brilliance and enthusiasm about a topic I enjoy reading about and trying to understand but I'm no data scientist. I'm a but reluctant to download on my phone but I may look into the links on my laptop. Thanks for sharing.