Overview
- Check out our pick of the 30 most challenging open-source data science projects you should try in 2020
- We cover a broad range of data science projects, including Natural Language Processing (NLP), Computer Vision, and much more
- All of these data science projects are open source – so each comes with downloadable code and walkthroughs
Introduction
When was the last time you took up a data science project outside your work?
There are a plethora of ways to learn Data Science concepts. We can spend time reading exhaustive books, browse through tutorial articles, glue our ears to lengthy podcasts, spend hours on videos and dive deep into research papers.
I’ve found all of these mediums lacking one fundamental thing a data scientist needs – practice.
And that is the gap Analytics Vidhya aims to bridge with our monthly collection of open source data science projects! We strongly believe there is nothing quite like GitHub for practicing and staying up-to-date with Data Science. It is home to over 40 million developers who review codes and manage projects! Just think about it – you get to learn in such a highly collaborative environment!

There’s an even bigger incentive to work on these projects. Recruiters give a lot of weightage to data science projects. These projects not only portray your eagerness to learn and progress but also smartly showcase your passion to be a data scientist.
So why GitHub for Open Source Data Science Projects?
It’s a good question and one I wanted to answer in this comprehensive article.
Did you know that top tech behemoths open source a lot of their code on GitHub? The world’s leading companies like Google and Facebook open source their projects on GitHub by releasing the code behind their popular algorithms. It’s a brilliant way of applying and learning data science – pick up the open-source code, understand it, play around with it, and build your own model!
There is something for us all here, no matter which level you are at in your data science career (beginner, established or advanced). You will always find something fresh to learn on GitHub.
In this article – I have compiled a list of exciting open source Data Science projects for you. Trust me – you cannot afford to miss working on these projects! So pull up your socks and get set to achieve your data science stardom in 2020 with these amazing projects.
I have divided these open source data science projects into four broad categories:
- Tools, Frameworks, and Libraries for Data Science
- Computer Vision (CV) Projects
- Natural Language Processing (NLP) Projects
- Generative Adversarial Networks (GANs) Projects
Tools, Frameworks, and Libraries for Data Science
Let’s start with the top data science projects in terms of tools, frameworks, and libraries. The number of tools and frameworks available for a data scientist has increased tremendously in 2019 and we’ll cover the top ones here.
Plato – Tencent’s Graph Computing Framework
Graphs are now an important part of the machine learning lifecycle. They are super useful almost everywhere.
Plato is a state-of-the-art framework that comes with incredible computing power. While analyzing billions of nodes, Plato can reduce the computing time from days to minutes (that’s the power of graphs!). So, instead of relying on several hundred servers, Plato can finish its tasks on as little as ten servers.
Tencent is using Plato on the WeChat platform as well.
Here’s a comparison of Plato against Spark GraphX on the PageRank and LPA benchmarks:

You can read more Plato here. If you’re new to graphs and are wondering how they tie into data science, here’s an excellent article to help you out:
StringSifter – Automatically Rank Strings for Malware Analysis
StringSifter, pioneered by FireEye, “is a machine learning tool that automatically ranks strings based on their relevance for malware analysis”.
A malware program will often contain strings if it wants to perform operations like creating a registry key, copying a file to a specific location, etc.

This can help provide crucial insights that can help build robust malware detection programs. This is one of the more fascinating data science projects on this list. I feel we as a community don’t spend enough time talking about cyber threats and how to use data science to build robust solutions, so this can just be a starting point for that!
If this is something you want to pursue, you should take a few minutes and go through this excellent article:
pyforest – Importing all Python Data Science Libraries in One Line of Code
I really, really like this Python library. As the above heading suggests, our regularly used data science libraries are imported into our notebook using just one library – pyforest.
Check out this quick demo I’ve taken from the library’s GitHub repository:
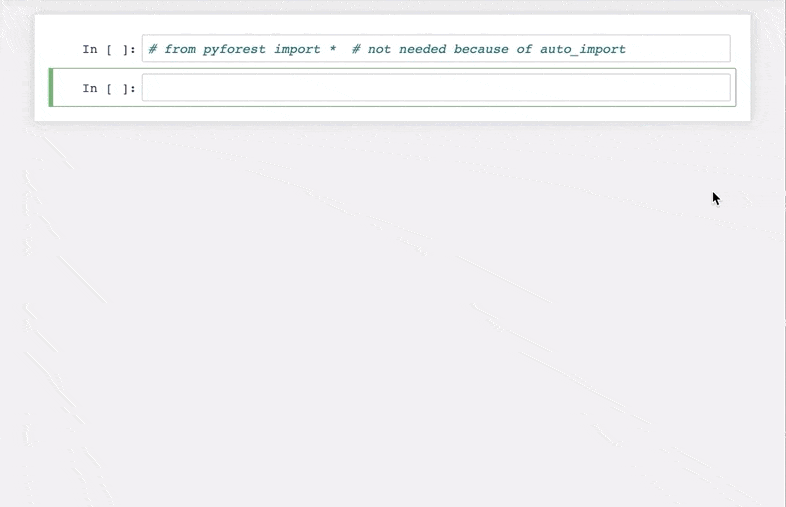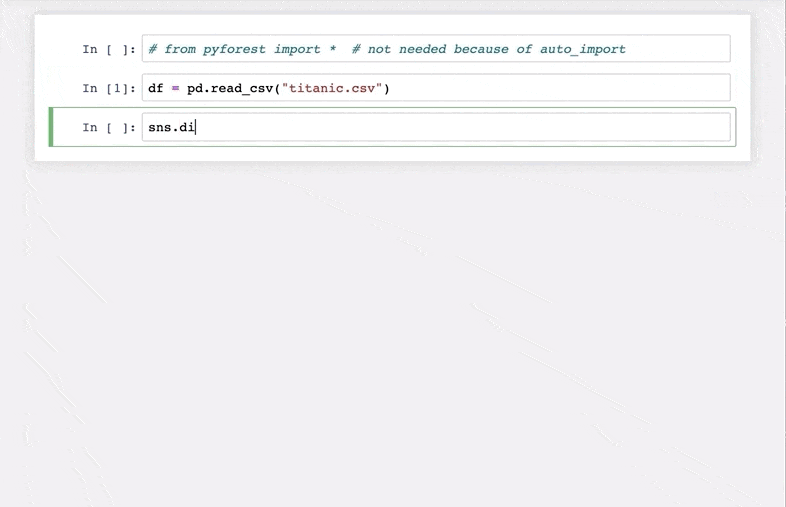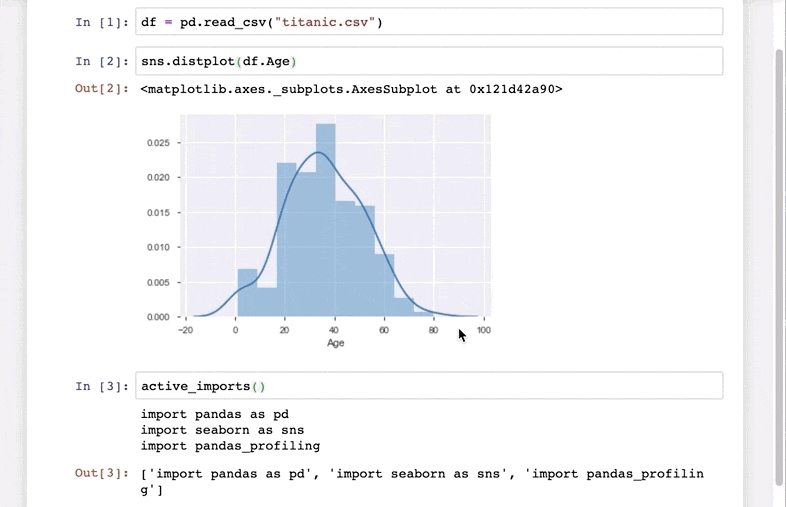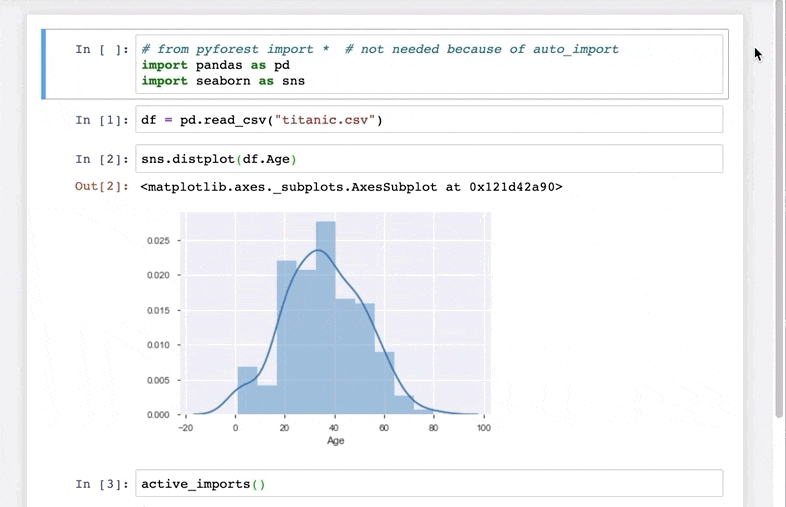
Excited yet? pyforest currently includes pandas, NumPy, matplotlib, and many more data science libraries.
Just use pip install pyforest to install the library on your machine and you’re good to go. And you can import all the popular Python libraries for data science in just one line of code:
from pyforest import *
Awesome! I’m thoroughly enjoying using this and I’m certain you will as well. You should check out the below free course on Python if you’re new to the language:
tfpyth – TensorFlow to PyTorch to TensorFlow
TensorFlow and PyTorch both have very strong user communities. But the incredible adoption rate of PyTorch is already ensuring it’s eating up the gap to TensorFlow (the next couple of years will be quite interesting). Note: This isn’t a knock on TensorFlow which is pretty solid.
So, if you have written any code in TensorFlow and a separate one in PyTorch, and want to combine the two to train a model – the tfpyth framework is for you. The best part about tfpyth is that we don’t need to rewrite the earlier code.

This GitHub repository includes a well structured example of how you can use tfpyth. It’s definitely a refreshing look at the TensorFlow vs. PyTorch debate, isn’t it?
Install tfpyth using the below command:
pip install tfpyth
Here are a couple of in-depth articles to learn how TensorFlow and PyTorch work:
- Deep Learning Guide: Introduction to Implementing Neural Networks using TensorFlow in Python
- An Introduction to PyTorch – A Simple yet Powerful Deep Learning Library
Tensor2Robot (T2R) by Google Research
Google has the most computational power in the business and they’re putting it to good use in machine learning.

Their open source released this year, called Tensor2Robot (T2R) was pretty awesome. T2R is a library for training, evaluation and inference of large-scale deep neural networks. It has been developed with a specific goal in mind. It is tailored for neural networks related to robotic perception and control.
No prizes for guessing the deep learning framework on which Tensor2Robot is built. That’s right – TensorFlow. Tensor2Robot is used within Alphabet, Google’s parent organization.
Here are a couple of projects implemented using Tensor2Robot:
Generative Models in TensorFlow 2
TensorFlow 2.0 is the most awaited TensorFlow (TF) version that was launched this year!

This repository contains TF implementations of multiple generative models, including:
- Generative Adversarial Networks (GANs)
- Autoencoder
- Variational Autoencoder (VAE)
- VAE-GAN, among others.
All these models are implemented on two datasets you’ll be pretty familiar with – Fashion MNIST and NSYNTH.
The best part? All of these implementations are available in a Jupyter Notebook! So you can download it and run it on your own machine or export it to Google Colab. The choice is yours and TensorFlow 2.0 is right here for you to understand and use.
We encourage you to listen to Paige Bailey, Product Manager for TensorFlow, as she elaborates on this topic during her DataHack Radio podcast appearance:
Google Research Football – A Unique Reinforcement Learning Environment
Football – I love this game, so this repository instantly caught my attention. It “contains a reinforcement learning environment based on the open-source game Gameplay Football”. This environment was created exclusively for research purposes by the Google Research team. Here are a few scenarios produced within the environment:

Agents are trained to play football in an advanced, physics-based 3D simulator. I’ve seen a few RL environments in the last couple of years but this one takes the cake.
The research paper makes for interesting reading, especially if you’re a football or reinforcement learning enthusiast (or both!). Check it out here.
Computer Vision
The beautiful use of deep learning and artificial neural network has made computer vision more capable of replicating human vision. One exceptional breakthrough that I read about recently stunned me – computer vision is aiding 3D-printing anatomy and functions in neurosurgical planning.
Check out this new printer and go wild on guessing the ways in which this can transform the healthcare sector in 2020:
Computer Vision techniques are evolving rapidly and you need to spring up with this evolution. What can be a better way than honing your skills by undertaking various exciting projects! So let’s jump in and practice the best open-source Computer Vision projects from 2019.
Gaussian YOLOv3: An Accurate and Fast Object Detector for Autonomous Driving
Autonomous vehicles are literally changing the face of travel. They are an incredible innovation and I am so excited to see this industry take shape and transform the world.
But progress in building a seamless autonomous car has been slow due to a variety of reasons (architecture, public policy, acceptance among the community, etc.). So it’s always heartening to see any framework or algorithm that promises a better future for these autonomous cars.

Object detection algorithms are at the heart of these autonomous vehicles. And detecting objects at high accuracy with fast inference speed is vital to ensure safety. All this has been around for a few years now, so what differentiates this project?
The Gaussian YOLOv3 architecture improves the system’s detection accuracy and supports real-time operation (a critical aspect). Compared to a conventional YOLOv3, Gaussian YOLOv3 improves the mean average precision (mAP) by 3.09 and 3.5 on the KITTI and Berkeley deep drive (BDD) datasets, respectively.
Here are three in-depth articles to get you started with object detection and the YOLO framework in computer vision:
- A Step-by-Step Introduction to the Basic Object Detection Algorithms
- A Practical Guide to Object Detection using the Popular YOLO Framework (with Python code)
- A Friendly Introduction to Real-Time Object Detection using the Powerful SlimYOLOv3 Framework
Few-Shot vid2vid by NVIDIA
I came across the concept of video-to-video (vid2vid) synthesis last year and was blown away by its effectiveness. vid2vid essentially converts a semantic input video to an ultra-realistic output video. This idea has come a long way since then.
But there are currently two primary limitations with these vid2vid models:
- They require humongous amounts of training data
- These models struggle to generalize beyond the training data

That’s where NVIDIA’s Few-Shot viv2vid framework comes in. As the creator state, we can use it for “generating human motions from poses, synthesizing people talking from edge maps, or turning semantic label maps into photo-realistic videos”.
This GitHub repository is a PyTorch implementation of Few-Shot vid2vid. You can check out the full research paper here (it was also presented at NeurIPS 2019).
Here’s the perfect article to start learning about how you can design your own video classification model:
Kaolin – PyTorch Library for Accelerating 3D Deep Learning Research
Voila! Here it is – a practice project on 3D imaging, geospatial analysis, architecture, etc. I haven’t come across a lot of work on 3D deep learning that’s why I found this GitHub repository quite fascinating. 3D models can potentially aid much-needed breakthroughs in various sectors and the big one is healthcare.
So get your hands dirty here and learn Kaolin!
Kaolin is a PyTorch library that aims to accelerate research in 3D deep learning. The PyTorch library provides efficient implementations of 3D modules for use in deep learning systems – something I’m sure all you industry veterans will appreciate.

We get a ton of functionality with Kaolin, including loading and preprocessing popular 3D datasets, evaluating and visualizing 3D results, among other things.
What I especially like about Kaolin is that the developers have curated multiple state-of-the-art deep learning architectures to help anyone get started with these projects.
And if you’re new to deep learning and PyTorch, don’t worry! Here are a few tutorials (and a course) to get you on your way:
- A Beginner-Friendly Guide to PyTorch and How it Works from Scratch
- Get Started with PyTorch – Learn How to Build Quick & Accurate Neural Networks (with 4 Case Studies!)
- Computer Vision using Deep Learning 2.0 Course
Ultra-Light and Fast Face Detector
This is a phenomenal and powerful open-source release. Don’t be put off by the Chinese page (you can easily translate it into English). This is an ultra-light version of a face detection model – a really useful application of computer vision.

The size of this face detection model is just 1MB! I honestly had to read that a few times to believe it.
This model is a lightweight face detection model for edge computing devices based on the libfacedetection architecture. There are two versions of the model:
- Version-slim (slightly faster simplification)
- Version-RFB (with the modified RFB module, higher precision)
This is a great repository to get your hands on. We don’t typically get such a brilliant opportunity to build computer vision models on our local machine – let’s not miss this one.
Video Object Removal
Computer Vision techniques for manipulating and dealing with images are quite advanced. Object detection for images is considered a basic step to becoming a computer vision expert.
What about videos, though? The difficulty level goes up several notches when we’re asked to simply draw bounding boxes around objects in videos. The dynamic aspect of objects makes the entire concept more complex.
So, imagine my delight when I came across this GitHub repository. We just need to draw a bounding box around the object in the video to remove it. It really is that easy! Here are a couple of examples of how this project works:

If you’re new to the world of computer vision, here are a few resources to get you up and running:
- A Step-by-Step Introduction to the Basic Object Detection Algorithms
- Computer Vision using Deep Learning 2.0 Course
DeepPrivacy – An Impressive Anonymization Technique for Images
I really like DeepPrivacy – a fully automatic anonymization technique for images. The GAN model behind DeepPrivacy never sees any privacy-sensitive information. It generates the image(s) considering the original pose of the person and the image background.

DeepPrivacy uses Mask R-CNN to generate information about the face. You can read the full research paper behind DeepPrivacy here.
MedicalNet

This GitHub repository contains a PyTorch implementation of the ‘Med3D: Transfer Learning for 3D Medical Image Analysis‘ paper. This machine learning project aggregates the medical dataset with diverse modalities, target organs, and pathologies to build relatively large datasets.
And as we well know, our deep learning models do (usually) require a large amount of training data. So MedicalNet, released by TenCent, is a brilliant open source project I hope a lot of folks work on.
The developers behind MedicalNet have released four pretrained models based on 23 datasets. And here is an intuitive introduction to transfer learning if you needed one:
Implementation of the CRAFT Text Detector
CRAFT stands for Character Region Awareness for Text Detection. It’s a fascinating concept and it should be on your to-read list if you’re interested in computer vision. Just check out this GIF:

Can you figure out how the algorithm is working? CRAFT detects the text area by exploring each character region present in the image. And the bounding box of the text? That is obtained by simply finding minimum bounding rectangles on a binary map.
You’ll grasp CRAFT in a jiffy if you’re familiar with the concept of object detection. This repository includes a pretrained model so you don’t have to code this algorithm from scratch!
You can find more details and an in-depth explanation of CRAFT in this paper.
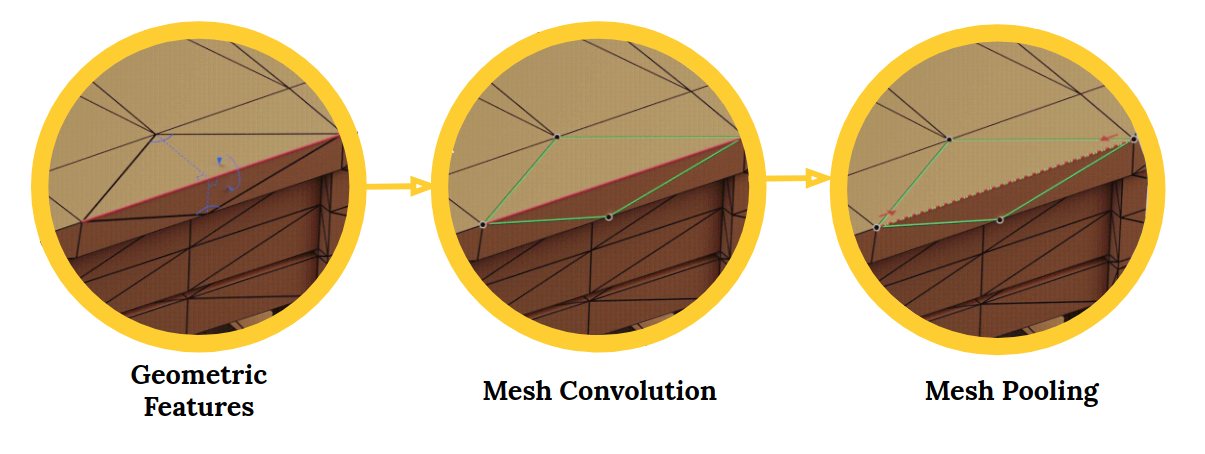
MeshCNN in PyTorch
MeshCNN is a general-purpose deep neural network for 3D triangular meshes. These meshes can be used for tasks such as 3D-shape classification or segmentation. A superb application of computer vision.
The MeshCNN framework includes convolution, pooling and unpooling layers which are applied directly on the mesh edges:
Convolutional Neural Networks (CNNs) are perfect for working with image and visual data. CNNs have become all the rage in recent times with a boom of image related tasks springing up from them. Object detection, image segmentation, image classification, etc. – these are all possible thanks to the advancement in CNNs.
3D deep learning is attracting interest in the industry, including fields like robotics and autonomous driving. The problem with 3D shapes is that they are inherently irregular. This makes operations like convolutions difficult an challenging.
This is where MeshCNN comes into play. From the repository:
Meshes are a list of vertices, edges and faces, which together define the shape of the 3D object. The problem is that every vertex has a different # of neighbors, and there is no order.
If you’re a fan of computer vision and are keen to learn or apply CNNs, this is the perfect project for you.
CenterNet – Computer Vision using Center Point Detection

I really like this approach to object detection. Generally, detection algorithms identify objects as axis-aligned boxes in the given image. These methods look at multiple object points and locations and classify each. This sounds fair – that’s how everyone does it, right?
Well, this approach, called CenterNet, models an object as a single point. Basically, it identifies the central point of any bounding box using keypoint estimation. CenterNet has proven to be much faster and more accurate than the bounding box techniques we are familiar with.
Try it out next time you’re working on an object detection problem – you’ll love it! You can read the paper explaining CenterNet here.
SiamMask – Fast Online Object Tracking and Segmentation
This repository is based on the ‘Fast Online Object Tracking and Segmentation: A Unifying Approach‘ paper. Here’s a sample result using this technique:

Awesome! The technique, called SiamMask, is fairly straightforward, versatile and extremely fast. Oh, did I mention the object tracking is done in real-time? That certainly got my attention. This repository also contains pretrained models to get you started.
face.evoLVe – High Performance Face Recognition Library
Face recognition algorithms for computer vision are ubiquitous in data science. face.evoLVe is a “High Performance Face Recognition Library” based on PyTorch.

It provides comprehensive functions for face related analytics and applications, including:
- Face alignment (detection, landmark localization, affine transformation)
- Data pre-processing (e.g., augmentation, data balancing, normalization)
- Various backbones (e.g., ResNet, DenseNet, LightCNN, MobileNet, etc.)
- Various losses (e.g., Softmax, Center, SphereFace, AmSoftmax, Triplet, etc.)
- A bag of tricks for improving performance (e.g., training refinements, model tweaks, knowledge distillation, etc.).
This library is a must-have for the practical use and deployment of high performance deep face recognition, especially for researchers and engineers.
Natural Language Processing (NLP)
I am truly astonished at the speed of research and development in NLP nowadays. Every new paper/framework/library just pushes the boundary of this incredibly powerful field. And due to the open culture of research around AI and large amounts of freely available text data, there is almost nothing that we can’t do today.
Here, we have amazing, State-of-the-Art approaches for Language Modeling, Transfer Learning and many other important and advanced NLP tasks. Seriously, what a time to be alive!

Here, I present to you amazing NLP projects that will sharpen your skills in the field. Check them out!
OpenAI’s GPT-2 in a Few Lines of Code
Ah yes. OpenAI’s GPT-2. I haven’t seen such hype around a data science library release before. They only released a very small sample of their original model (owing to fear of malicious misuse), but even that mini version of the algorithm has shown us how powerful GPT-2 is for NLP tasks.
There have been many attempts to replicate GPT-2’s approach but most of them are too complex or long-winded. That’s why this repository caught my eye. It’s a simple Python package that allows us to retrain GPT-2’s text-generating model on any unseen text. Check out the below-generated text using the gpt2.generate() command:

You can install gpt-2-simple directly via pip (you’ll also need TensorFlow installed):
pip3 install gpt_2_simple
Here’s the perfect article to get started with this framework:
Transformers v2.2 – with 4 New NLP Models!
HuggingFace is the most active research group I’ve seen in the NLP space. They seem to come up with new releases and frameworks mere hours after the official developers announce them – it’s incredible. I would highly recommend following HuggingFace on Twitter to stay up-to-date with their work.
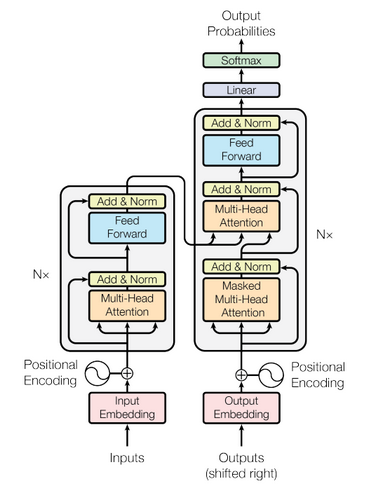
Their latest release is Transformers v2.2.0 that includes four new NLP models (among other new features):
- ALBERT (PyTorch and TensorFlow): A Lite version of BERT
- CamamBERT (PyTorch): A French Language Model
- GPT2-XL (PyTorch and TensorFlow): A GPT-2 iteration by OpenAI
- DistilRoberta (PyTorch and TensorFlow)
As always, we have the tutorials for the latest state-of-the-art NLP frameworks:
- How do Transformers Work in NLP?
- Demystifying BERT: A Comprehensive Guide to the Ground-Breaking NLP Framework
PLMpapers – Collection of Research Papers on Pretrained Language Models
This GitHub repository is a collection of over 60 pretrained language models. These include BERT, XLNet, ERNIE, ELMo, ULMFiT, among others. Here’s a diagrammatic illustration of the papers you’ll find in this repository:
Pretrained models are all the rage these days. Most of us don’t have a GPU sitting idle at home (let alone several of them) so it’s simply not possible to code deep neural network models from scratch.
This GitHub repository is a collection of over 60 pretrained language models. These include BERT, XLNet, ERNIE, ELMo, ULMFiT, among others. Here’s a diagrammatic illustration of the papers you’ll find in this repository:

This is a jackpot of a repository in my opinion and one you should readily bookmark (or star) if you’re an NLP enthusiast.
Text Mining on the 2019 Mexican Government Report – A Brilliant Application of NLP
The Mexican government released its annual report on September 1st and the creator of this project decided to use simple NLP text mining techniques to unearth patterns and insights.
The first challenge, as the author has highlighted in the above link, was to extract all the text from the PDF file where the report was housed. He used a library called PyPDF2 to do this. The entire process is well documented in this project along with a step-by-step explanation plus Python code.
Check out this visualization generated using seaborn:

It’s simple yet powerful – it shows the number of mentions of each state in the annual report.
DistilBERT – A Lighter and Cheaper Version of Google’s BERT
I am sure you are familiar with BERT by now. It is the most popular Natural Language Processing (NLP) framework. BERT is based on the Transformer architecture.
But it comes with one caveat – it can be quite resource-intensive. So how can data scientists work on BERT on their own machines? Step up – DistilBERT!
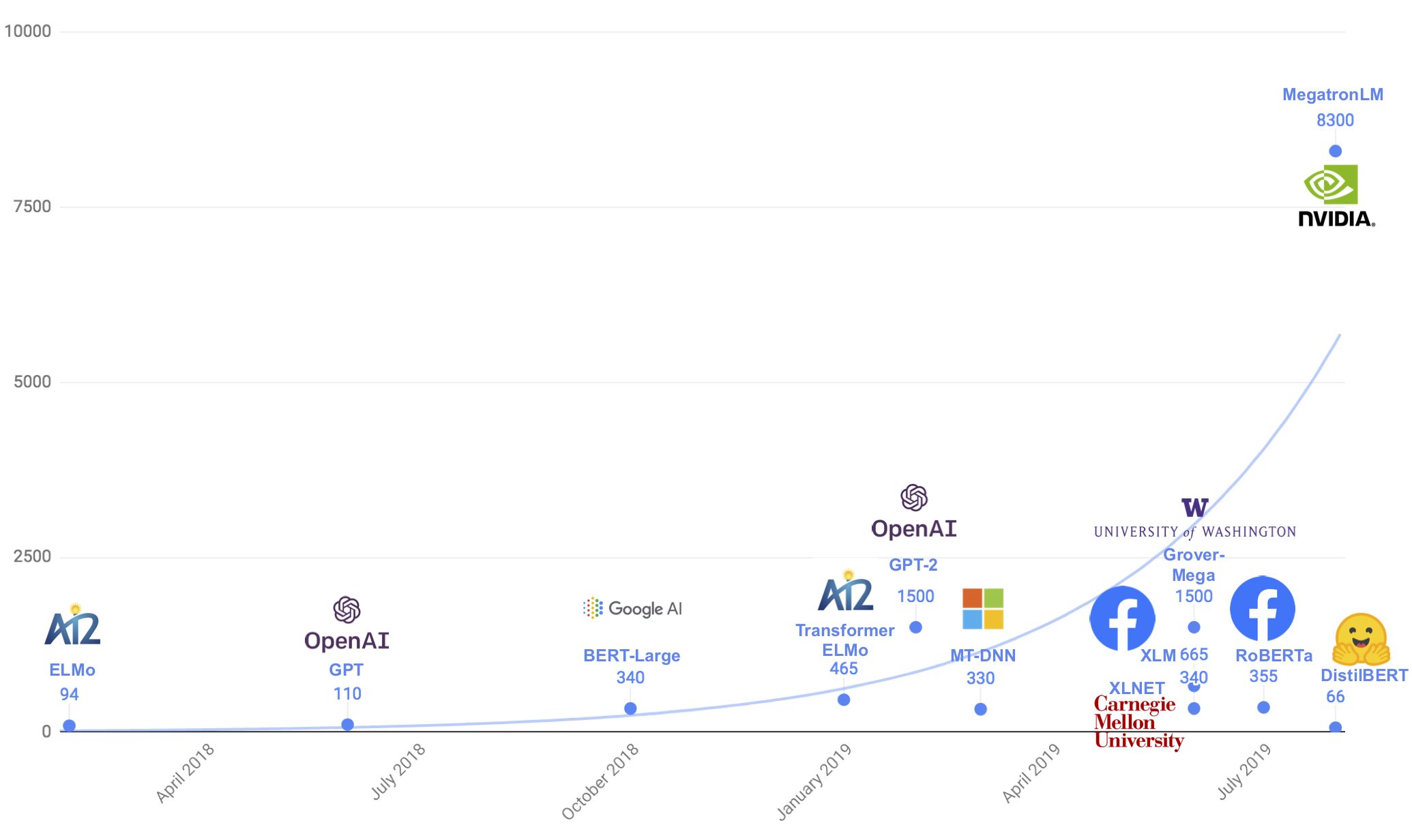
DistilBERT, short for Distillated-BERT, comes from the team behind the popular PyTorch-Transformers framework. It is a small and cheap Transformer model built on the BERT architecture. According to the team, DistilBERT runs 60% faster while preserving over 95% of BERT’s performances.
This GitHub repository explains how DistilBERT works along with the Python code. You will be amazed after trying your hands on this!
XLNet: The Next Big NLP Framework
The latest state-of-the-art NLP framework is XLNet. It has taken the NLP community by storm. XLNet uses Transformer-XL at its core. The developers have released a pretrained model as well to help you get started with XLNet.
XLNet has so far outperformed Google’s BERT on 20 NLP tasks and achieved state-of-the-art performance on 18 such tasks. Here are a few results on popular NLP benchmarks for reading comprehensions:
| Model | RACE accuracy | SQuAD1.1 EM | SQuAD2.0 EM |
|---|---|---|---|
| BERT | 72.0 | 84.1 | 78.98 |
| XLNet | 81.75 | 88.95 | 86.12 |
Want more? Here are the results for text classification:
| Model | IMDB | Yelp-2 | Yelp-5 | DBpedia | Amazon-2 | Amazon-5 |
|---|---|---|---|---|---|---|
| BERT | 4.51 | 1.89 | 29.32 | 0.64 | 2.63 | 34.17 |
| XLNet | 3.79 | 1.55 | 27.80 | 0.62 | 2.40 | 32.26 |
XLNet is, to put it mildly, very impressive. You can read the full research paper here.
NeuronBlocks – Impressive NLP Deep Learning Toolkit by Microsoft
Another NLP entry this year. It just goes to show the mind-boggling pace at which advancements in NLP are happening right now.
NeuronBlocks is an NLP toolkit developed by Microsoft that helps data science teams build end-to-end pipelines for neural networks. The idea behind NeuronBlocks is to reduce the cost it takes to build deep neural network models for NLP tasks.

There are two major components that makeup NeuronBlocks (use the above image as a reference):
- BlockZoo: This contains popular neural network components
- ModelZoo: This is a suite of NLP models for performing various tasks
You know how costly applying deep learning solutions can get. So make sure you check out NeuronBlocks and see if it works for you or your organization. The full paper describing NeuronBlocks can be read here.
LazyNLP for Creating Massive Text Datasets
The premise behind LazyNLP is simple – it enables you to crawl, clean up and deduplicate websites to create massive monolingual datasets.

What do I mean by massive? According to the developer, LazyNLP will allow you to create datasets larger than the one used by OpenAI for training the GPT-2 model. The full scale one. That certainly had my full attention.
This GitHub repository lists down the 5 steps you’ll need to follow to create your own custom NLP dataset. If you’re in any way interested in NLP, you should definitely check out this release.
Subsync – Automating Subtitles Synchronization with the Video
How often have you found yourself frustrated at subtitles being out of sync with the video? This repository happens to be your savior in such situations.

Subsync is about “language-agnostic automatic synchronization of subtitles to video so that subtitles are aligned to the correct starting point within the video”. The algorithm was built using the Fast Fourier Transform technique in Python.
Subsync works inside the VLC Media Player as well! The model takes about 20-30 seconds to train (depending on the video length).
Generative Adversarial Networks (GANs)
GANs have been a huge success since the time they were introduced in 2014 by Ian Goodfellow. They are a powerful class of neural networks that are used for unsupervised learning. Here are some popular projects on GANs from 2019 that you should check out!
Visualizing and Understanding GANs

GAN Dissection, pioneered by researchers at MIT’s Computer Science & Artificial Intelligence Laboratory, is a unique way of visualizing and understanding the neurons of Generative Adversarial Networks (GANs). But it isn’t just limited to that – the researchers have also created GANPaint to showcase how GAN Dissection works.
This helps you explore what a particular GAN model has learned by inspecting and manipulating its internal neurons. Check out the research paper here and the below video demo, and then head straight to the GitHub repository to dive straight into the code!
PyTorch Implementation of DeepMind’s BigGAN
If I had to pick one reason for my fascination with computer vision, it would be GANs (Generative Adversarial Networks). They were invented by Ian Goodfellow only a few years back and have blossomed into a whole body of research. The recent AI art you’ve been seeing on the news? It’s all powered by GANs.

DeepMind came up with the concept of BigGAN last year but we have waited a while for a PyTorch implementation. This repository includes pretrained models (128×128, 256×256, and 512×512) as well. You can install this in just one line of code:
pip install pytorch-pretrained-biggan
And if you’re interested in reading the full BigGAN research paper, head over here.
StyleGAN – Generating Life-Like Human Faces

The above image seems like a typical collage – nothing to see here. What if I told you none of the people in this collection are real? That’s right – these folks do not exist.
All these faces were produced by an algorithm called StyleGAN. While GANs have been getting steadily better since their invention a few years back, StyleGAN has taken the game up by several notches. The developers have proposed two new, automated methods to quantify the quality of these images and also open sourced a massive high-quality dataset of faces.
This repository contains the official TensorFlow implementation of the algorithm. Below are a few key resources to learn more about StyleGAN:
| Link | Description |
|---|---|
| http://stylegan.xyz/paper | Paper PDF. |
| http://stylegan.xyz/video | Result video. |
| http://stylegan.xyz/code | Source code. |
| http://stylegan.xyz/ffhq | Flickr-Faces-HQ dataset. |
| http://stylegan.xyz/drive | Google Drive folder. |
End Notes
What a magnificent year it’s been! Such incredible open-source data science projects to work on and explore! I had a brilliant learning experience along the way and putting this together was an exhilarating experience. I hope it was helpful to you as well.
Do share your thoughts on the projects that you have used and let me know if I missed out on any. And also share if there are any other repositories in the year 2019 that you absolutely loved.
The heart of every marketing campaign is great content and I love churning just that! I am a Data Science content marketing enthusiast. Exploring the field of applied Artificial Intelligence and Machine Learning and consistently being involved in editing the content at Analytics Vidhya is how I spend my day. I have always been fueled by the passion to do something different. The core of me is always eager to explore and learn more and more each day not only in the field of Data Science but also in the field of Psychology.







Very usefull overview of NLP developments!