This article was published as a part of the Data Science Blogathon
HISTORY & Background of Convolutional Neural Networks
Convolutional Neural Networks are a widely used neural network that is inspired by the mechanism of visual perception of the living bodies. Its history begins in mid ninety’s and quick developments in the ending years of 1900.
In 1990, some authors published the paper in which they developed an artificial neural network called LENET-5 which was multi-layered. It was built for classifying handwritten digits. It was able to recognize visual patterns directly from low pixels with little to no preprocessing.
Around 2010, researchers proposed a CNN architecture known as Alex Net which was similar to the LeNet-5 but with a deeper structure. After the success of Alex Net, many other architectures were proposed like ZF Net, VGG Net, Google Net, and Res Net.
Trends in the evolution of CNN architectures show that the networks are getting deeper and deeper. The network can learn the target variable more accurately and get better feature representations due to deeper architecture.
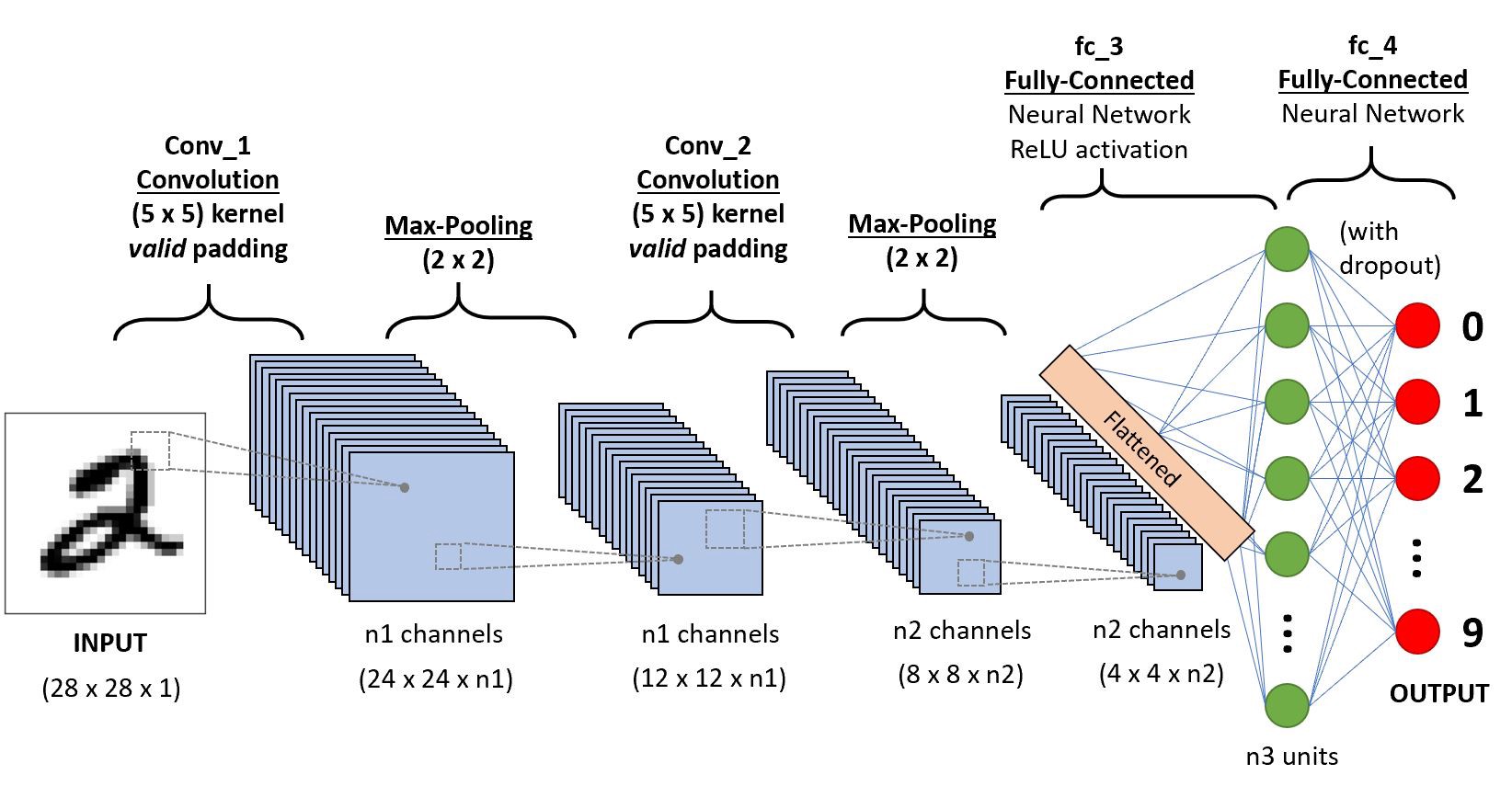
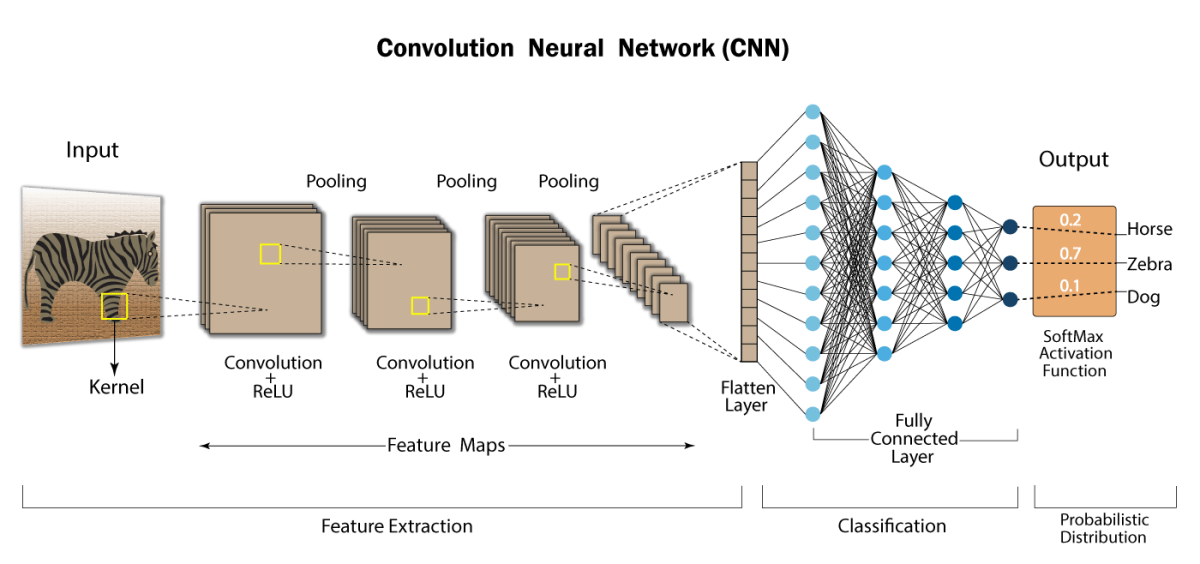
Components of Convolutional Neural Networks
Convolutional Layer
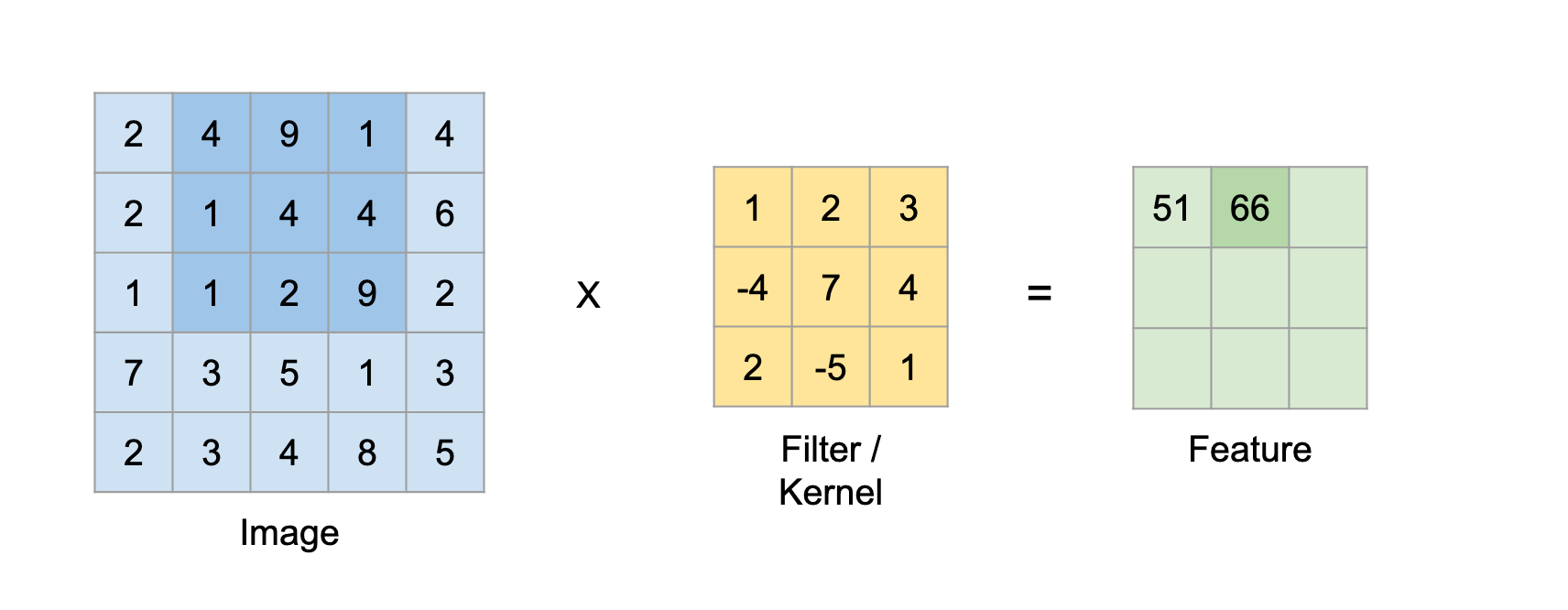
It tries to learn the feature representation of the inputs, whether it be the images of cats vs dogs or digits. For computing the different feature maps, it is composed of several kernels/matrix are used. So, a filter/kernel of (n*n) matrix depends on the type of problem we are solving, and then it is applied to the input data(or image) to get the convolutional feature. This convolution feature is then passed on to the next layer after adding bias and applying any suitable activation function.
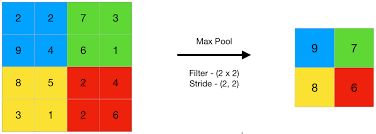
Pooling Layer
The pooling layer is placed between the convolutional layers. It is used for achieving shift invariance which is achieved by decreasing the resolution of the feature maps. The widely used pooling operations are average pooling and max pooling. Basically, reducing the number of connections between convolutional layers, lowers the computational burden on the processing units.
Some different types of pooling are listed below:
1.Lp Pooling
2.Max Pooling
3.Average Pooling
4.Mixed Pooling and so on
Fully-Connected Layer
There may be multiple fully connected layers, after a number of convolutional and pooling layers. Every single neuron of the current layer is connected with all the neurons in the previous layer.
The last layer of CNNs is an output layer that makes final predictions. For classification tasks, the Softmax function is commonly used where multiple classes are targeted for prediction(Ex. MNIST Dataset) and the Sigmoid function is used for binary classification(Ex-Cats vs Dogs).
Improvements on Convolutional Neural Networks
1.Dilated Convolution
2.Transposed Convolution
3.Tiled Convolution
4.Network in Network
5.Inception Module
Activation Function
Any selected activation function hugely impacts the performance of a convolutional neural network for a given problem. For CNN’s hidden layers, Re Lu is the preferred activation function because of its simple differentiability and fastness compared to other activation functions like tanh and sigmoid. Re Lu is typically followed after convolution operation. Other names in a list of activation functions include Sigmoid, softmax, Leaky Re Lu, ELU, etc.
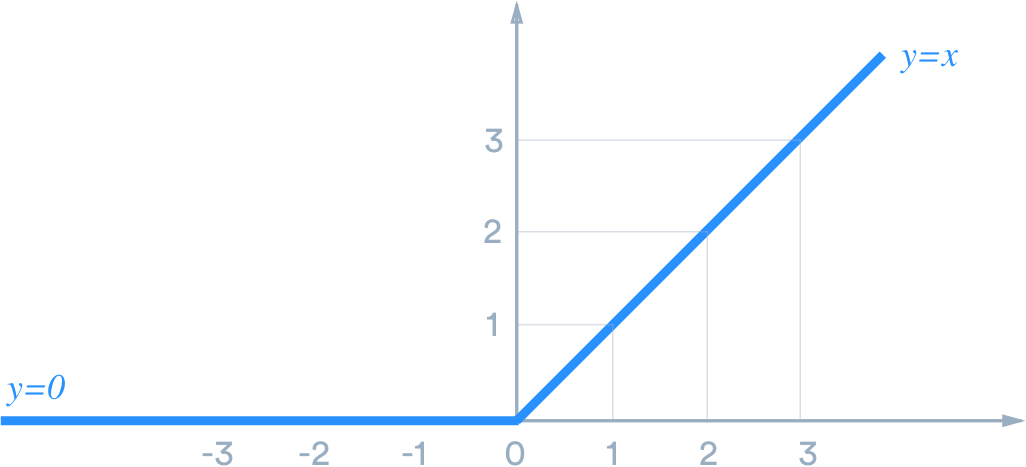
Source:medium.com
Applications of Convolutional Neural Networks
For achieving state-of-the-art performance, which includes image classification, natural language processing, pose estimation, text detection, and many more, here, I introduced some recent works and challenges.
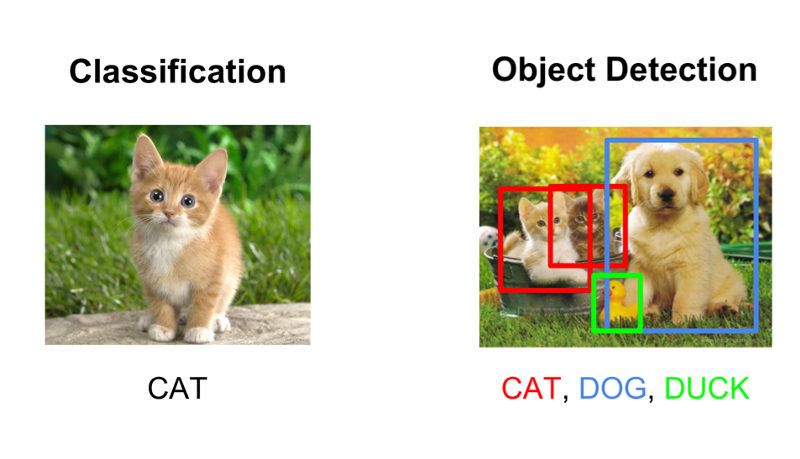
Image Classification
Image Classification is a fundamental task that attempts to comprehend an entire image as a whole. The goal is to classify the image by assigning it to a specific label. As compared with other methods, CNNs can achieve better classification accuracy on large-scale datasets.
In 2012, researchers developed the Alex Net architecture and achieve the best performance in ILSVRC 2012. After the success of Alex Net, several other works have made significant improvements in classification accuracy by either reducing filter size or expanding the network depth.
Object Detection
The difficulties here lie in how to accurately and efficiently localize objects in images or video frames. In some early works, researchers used the sliding window based approaches to densely evaluate the CNN classifier on windows sampled at each location and scale. Due to hundreds of thousands of candidate windows in an image, these methods suffer from high computational cost, which makes them unsuitable to be applied on the large-scale dataset, e.g., Pascal VOC, ImageNet, and MS COCO.
Object Tracking
There are several attempts to employ CNNs for visual tracking. In one study, researchers used CNN as a base learner. It learns a separate class-specific network to track objects.
In one more study authors design a CNN tracker with a shift-variant architecture. Such an architecture plays a key role so that it turns the CNN model from a detector into a tracker. The features are learned during offline training. Different from traditional trackers which only extract local spatial structures.
This CNN-based tracking method extracts both spatial and temporal structures by considering the images of two consecutive frames. Because the large signals in the temporal information tend to occur near objects that are moving, the temporal structures provide a crude velocity signal to track.
Some other methods include R-CNN, Faster R-CNN, and so on. More recently, YOLO and SSD allow single pipeline detection that directly predicts class labels.
Other applications are listed below:
Pose Estimation
Object Tracking
Text Detection and Recognition
Speech Processing and so on
Wrapping Up
Deep CNNs have made breakthroughs in processing image, video, speech, and text. In this article, we saw different components of CNNs and their applications like image classification, object detection, object tracking, pose estimation, text detection, visual saliency detection, action recognition, scene labeling, speech, and natural language processing.
As CNN’s have achieved huge success in experimental evaluations, there are lots of issues that require further research and investigation. Some of the challenges are listed below:
1.They require a large-scale dataset and massive computing power for training
2.Manually collecting labeled dataset requires huge amounts of human efforts
3.Need to develop effective and scalable parallel training algorithms
4.At testing time, these deep models are highly memory demanding and time-consuming, which makes them not suitable to be deployed
4.It requires considerable skill and experience to select suitable hyperparameters such as the learning rate, kernel sizes of convolutional filters, the number of layers, etc.
End Notes
The current CNN model works very well for various applications and our deep understanding of them can make their application more diverse. Recent developments in deep learning like Data Augmentation, Optimization Techniques, and others have made deep learning to be accepted widely.
Thanks and Keep Learning!!
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.





