This article was published as a part of the Data Science Blogathon.
Introduction

We, as human beings, make multiple decisions throughout the day.
For example, when to wake-up, what to wear, whom to call, which route to take to travel, how to sit, and the list goes on and on. While several of these are repetitive and we do not usually take notice (and allow it to be done subconsciously), there are many others that are new and require conscious thought.
And we learn along the way.
Businesses, similarly, apply their past learning to decision-making related to operations and new initiatives e.g. related to classifying customers, products, etc. However, it gets a little more complex here as there are multiple stakeholders involved. Additionally, the decisions need to be accurate owing to their wider impact.
With the evolution in digital technology, humans have developed multiple assets; machines being one of them. We have learned (and continue) to use machines for analyzing data using statistics to generate useful insights that serve as an aid to making decisions and forecasts.
Machines do not perform magic with data, rather apply plain Statistics!
In this context, let’s review a couple of Machine Learning algorithms commonly used for classification, and try to understand how they work and compare with each other. But first, let’s understand some related concepts.
Table of contents
Basic Concepts
Supervised Learning is defined as the category of data analysis where the target outcome is known or labeled e.g. whether the customer(s) purchased a product, or did not. However, when the intention is to group them based on what all each purchased, then it becomes Unsupervised. This may be done to explore the relationship between customers and what they purchase.
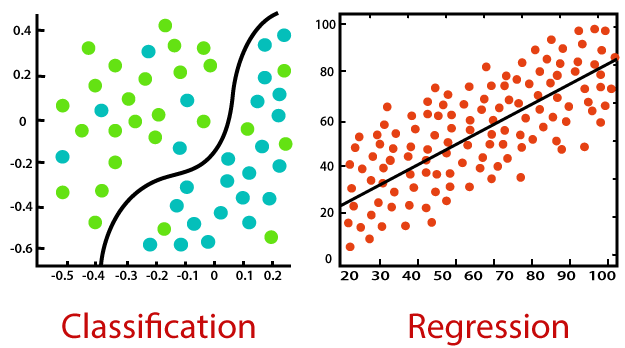
Classification and Regression both belong to Supervised Learning, but the former is applied where the outcome is finite while the latter is for infinite possible values of outcome (e.g. predict $ value of the purchase).
The normal distribution is the familiar bell-shaped distribution of a continuous variable. This is a natural spread of the values a parameter takes typically.
Given that predictors may carry different ranges of values e.g. human weight may be up to 150 (kgs), but the typical height is only till 6 (ft); the values need scaling (around the respective mean) to make them comparable.
Collinearity is when 2 or more predictors are related i.e. their values move together.
Outliers are exceptional values of a predictor, which may or may not be true.
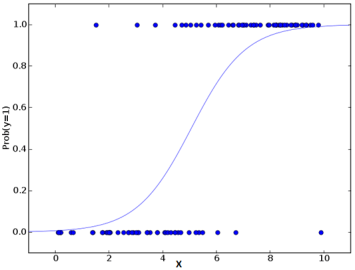
Logistic Regression
Logistic Regression utilizes the power of regression to do classification and has been doing so exceedingly well for several decades now, to remain amongst the most popular models. One of the main reasons for the model’s success is its power of explainability i.e. calling-out the contribution of individual predictors, quantitatively.
Unlike regression which uses Least Squares, the model uses Maximum Likelihood to fit a sigmoid-curve on the target variable distribution.
Given the model’s susceptibility to multi-collinearity, applying it step-wise turns out to be a better approach in finalizing the chosen predictors of the model.
The algorithm is a popular choice in many natural language processing tasks e.g. toxic speech detection, topic classification, etc.
Artificial Neural Networks
Artificial Neural Networks (ANN), so-called as they try to mimic the human brain, are suitable for large and complex datasets. Their structure comprises of layer(s) of intermediate nodes (similar to neurons) which are mapped together to the multiple inputs and the target output.
It is a self-learning algorithm, in that it starts out with an initial (random) mapping and thereafter, iteratively self-adjusts the related weights to fine-tune to the desired output for all the records. The multiple layers provide a deep learning capability to be able to extract higher-level features from the raw data.
The algorithm provides high prediction accuracy but needs to be scaled numeric features. It has wide applications in upcoming fields including Computer Vision, NLP, Speech Recognition, etc.

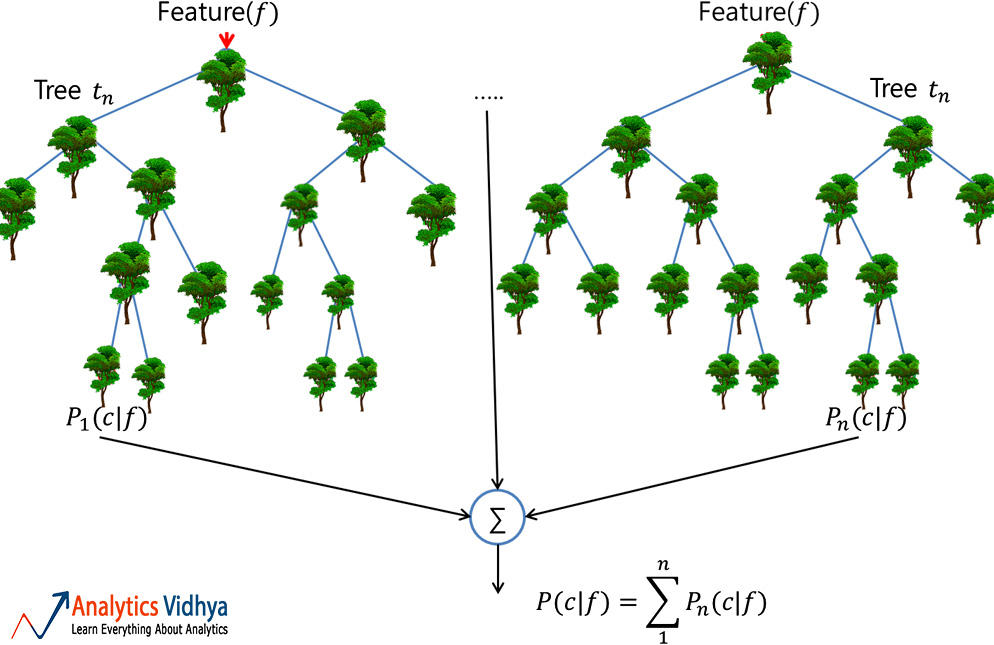
Random Forest
A Random Forest is a reliable ensemble of multiple Decision Trees (or CARTs); though more popular for classification, than regression applications. Here, the individual trees are built via bagging (i.e. aggregation of bootstraps which are nothing but multiple train datasets created via sampling of records with replacement) and split using fewer features. The resulting diverse forest of uncorrelated trees exhibits reduced variance; therefore, is more robust towards change in data and carries its prediction accuracy to new data.
However, the algorithm does not work well for datasets having a lot of outliers, something which needs addressing prior to the model building.
It has wide applications across Financial, Retail, Aeronautics, and many other domains.
Naïve Bayes
While we may not realize this, this is the algorithm that’s most commonly used to sift through spam emails!
It applies what is known as a posterior probability using Bayes Theorem to do the categorization on the unstructured data. And in doing so, it makes a naïve assumption that the predictors are independent, which may not be true.
The model works well with a small training dataset, provided all the classes of the categorical predictor are present.
KNN
K-Nearest Neighbor (KNN) algorithm predicts based on the specified number (k) of the nearest neighboring data points. Here, the pre-processing of the data is significant as it impacts the distance measurements directly. Unlike others, the model does not have a mathematical formula, neither any descriptive ability.
Here, the parameter ‘k’ needs to be chosen wisely; as a value lower than optimal leads to bias, whereas a higher value impacts prediction accuracy.
It is a simple, fairly accurate model preferable mostly for smaller datasets, owing to huge computations involved on the continuous predictors.
At a simple level, KNN may be used in a bivariate predictor setting e.g. height and weight, to determine the gender given a sample.

Putting it all together
The performance of a model is primarily dependent on the nature of the data. Given that business datasets carry multiple predictors and are complex, it is difficult to single out 1 algorithm that would always work out well. Therefore, the usual practice is to try multiple models and figure out the suitable one.
As a high-level comparison, the salient aspects usually found for each of the above algorithms are jotted-down below on a few common parameters; to serve as a quick reference snapshot.
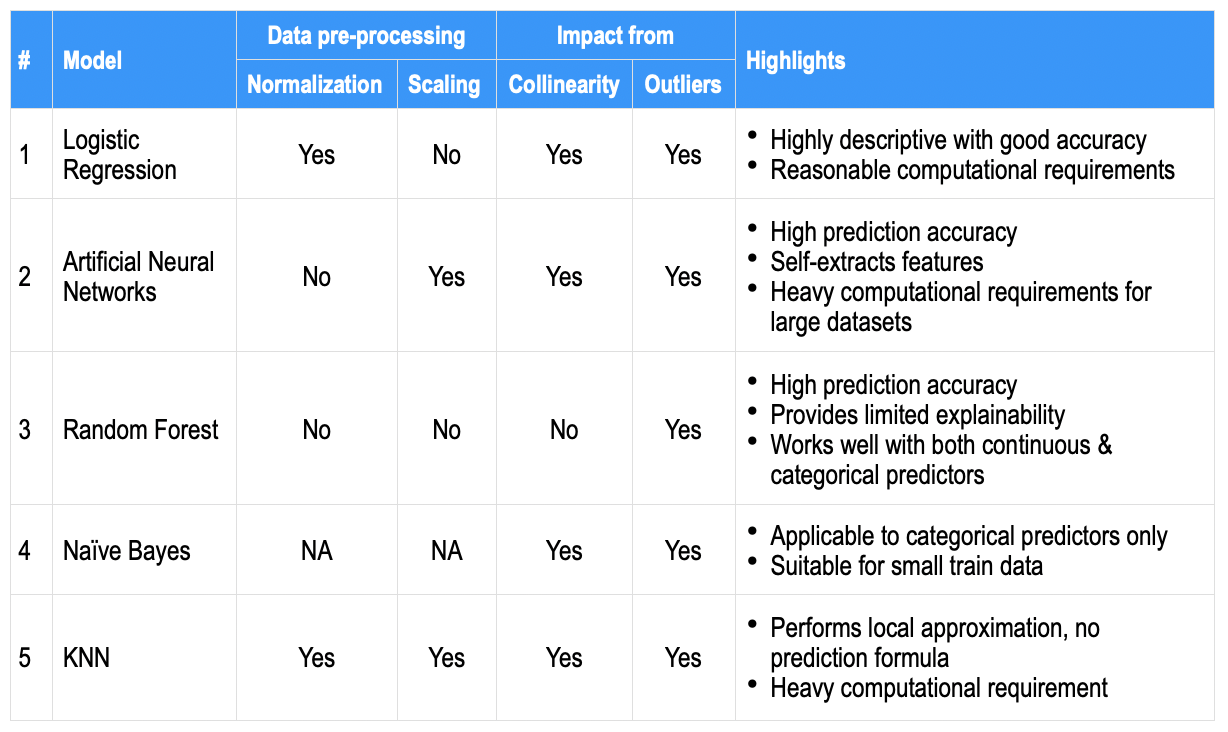
Further, there are multiple levers e.g. data balancing, imputation, cross-validation, ensemble across algorithms, larger train dataset, etc. in addition to model hyper-parameter tuning, that may be utilized to gain accuracy. While prediction accuracy may be most desirable, the Businesses do seek out the prominent contributing predictors (i.e. a descriptive model or its resulting explainability) as well.
Finally, machine learning does enable humans to quantitatively decide, predict, and look beyond the obvious, while sometimes into previously unknown aspects as well.
Conclusion
In summary, we’ve covered different classification models, like Logistic Regression and Neural Networks, making it easier to solve various problems in machine learning. By understanding these models, we now have a toolkit to handle different classification tasks confidently.
Frequently Asked Questions
Q1.What is the role of education in transfer of learning?
Education helps us learn and ensures we can use what we know in different situations. Teachers use methods and examples to make it easier for us to apply what we learn in real life.
Q2.What are the characteristics of transfer of learning?
Applicability: Using what we learn in one place in another similar situation.
Generalization: Using what we know in different, broader ideas or problems.
Retention: Remembering what we’ve learned for a long time.
Adaptability: Using what we learn in different and flexible ways
Q3.What are the stages of transfer learning?
Prior Knowledge Activation: Remembering what we already know before learning something new.
Transfer Initiation: Finding similarities between what we know and what we’re learning.
Application and Practice: Trying out what we’ve learned in real situations.
Reflection and Generalization: Thinking about how we learned can be used differently.
Integration: Making what we learned a natural part of what we already know and do
Saurabh Gupta
07 Dec, 2023







