By implementing cutting-edge technology like artificial intelligence (AI) and machine learning, businesses are attempting to increase the accessibility of information and services for consumers. These technologies are increasingly adopted in various business areas, including banking, finance, retail, manufacturing, and healthcare.
Some in-demand organizational roles embracing AI are data scientists, artificial intelligence engineers, machine learning engineers, and data analysts. Knowing the types of machine learning interview questions that hiring managers could pose if you intend to apply for positions in this field is essential because an ML interview would demand rigorous preparation in terms of in-depth knowledge of ML concepts and algorithms, technical and programming skills, etc.
To help you streamline your efforts as you embrace this learning journey, I decided to start a series of the essential ML questions that one is expected to face during the interviews. Each part will consist of 10 questions to provide brief and focussed coverage of each topic. For the first part, I decided to deal with the question pertinent and meaningful to Machine Learning and Statistics. This should provide you with sufficient background and revision material before your following interview. Over the remaining sections, I would deal with questions specific to Deep Learning, Computer Vision, NLP, Time Series Analysis, etc.
So if you are ready to start your dream career in ML, continue reading below to refresh your memory and add new knowledge to your existing know-how.
1. What are the Major Types of Machine Learning Algorithms?
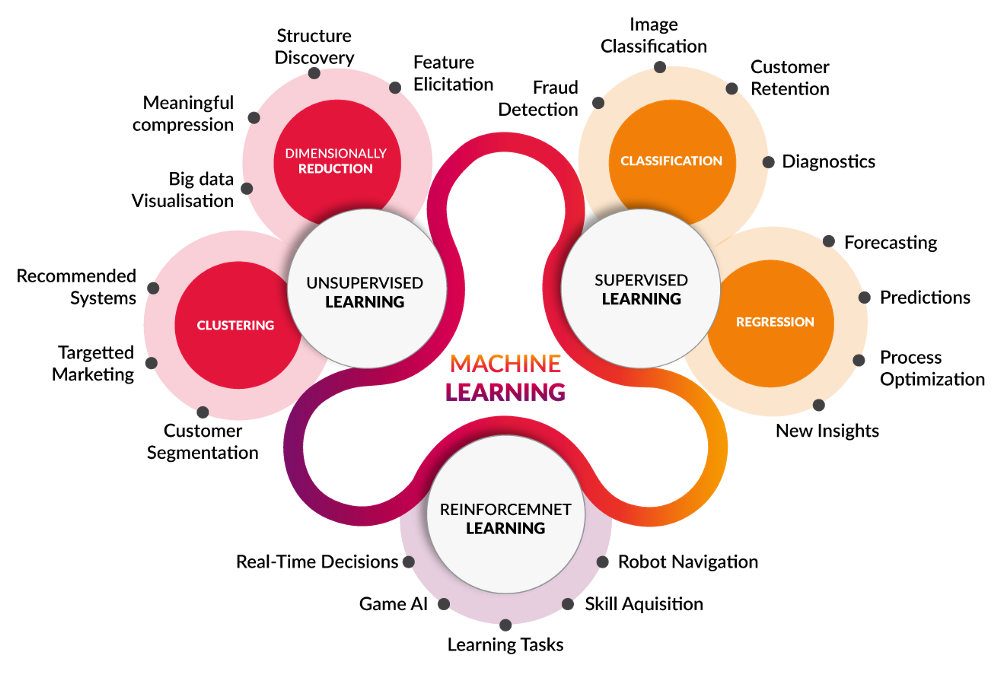
On a broad category, ML algorithms can be sub-divided into three main categories:
A. Supervised Learning: These algorithms give predictions based on inferring a function based on labeled training data, i.e., the target variables are present.
If the target variable is continuous, the usual choice of algorithms is the various regression models (linear, quadratic, polynomial)
If the target variable is categorical, preferred algorithms include Logistic Regression, Naive Bayes, KNN, SVM, Decision Tree, Boosting Algorithms, Random Forest, etc.
B. Unsupervised Learning: These algorithms predict the target variable based on some patterns on the set of given data. The data for this purpose does not have any dependent variable or label to predict. Algorithms that fall into this category include Clustering Algorithms, Anomaly Detection, Latent Space Models, Singular Value Decomposition, Principal Component Analysis, etc.
C. Reinforcement Learning: These algorithms use a trial-and-error-based approach, and learning occurs based on the rewards received from the previous action.
Source: Experfy Insights
2. How can you Determine the Critical Variables from the Dataset you are Working with?
Various means can be implemented to select essential variables from a dataset:
1. Identify and discard the correlated values before finalizing the important variables
2. Chose the variables based on the p” values obtained from hypothesis testing
3. Forward, backward and stepwise selection
4. Lasso Regression
5. Use Random Forest and select variables based on the feature importance plots
6. The top features can be selected based on the information gained from the available set of features
3. Explain Covariance and Correlation.
Covariance indicates the extent to which two random variables depend on each other. A higher number would denote a higher dependency. Their value lies in the range of -∞ and +∞. The problem with covariance is that they are hard to compute without performing normalization over the entire dataset, and a change of scale of the data would affect the covariance.
Correlation is a statistical measure that determines how strongly two variables are related. Its value would range from -1 to +1, which is scale-independent.
Source: Experfy Insights
4. What is the “P” Value?
P – value is used to decide the hypothesis test. The P value denotes the minimum significant level at which we can reject the null hypothesis. A lower the P – value would mean that we are more likely to reject the null hypothesis.
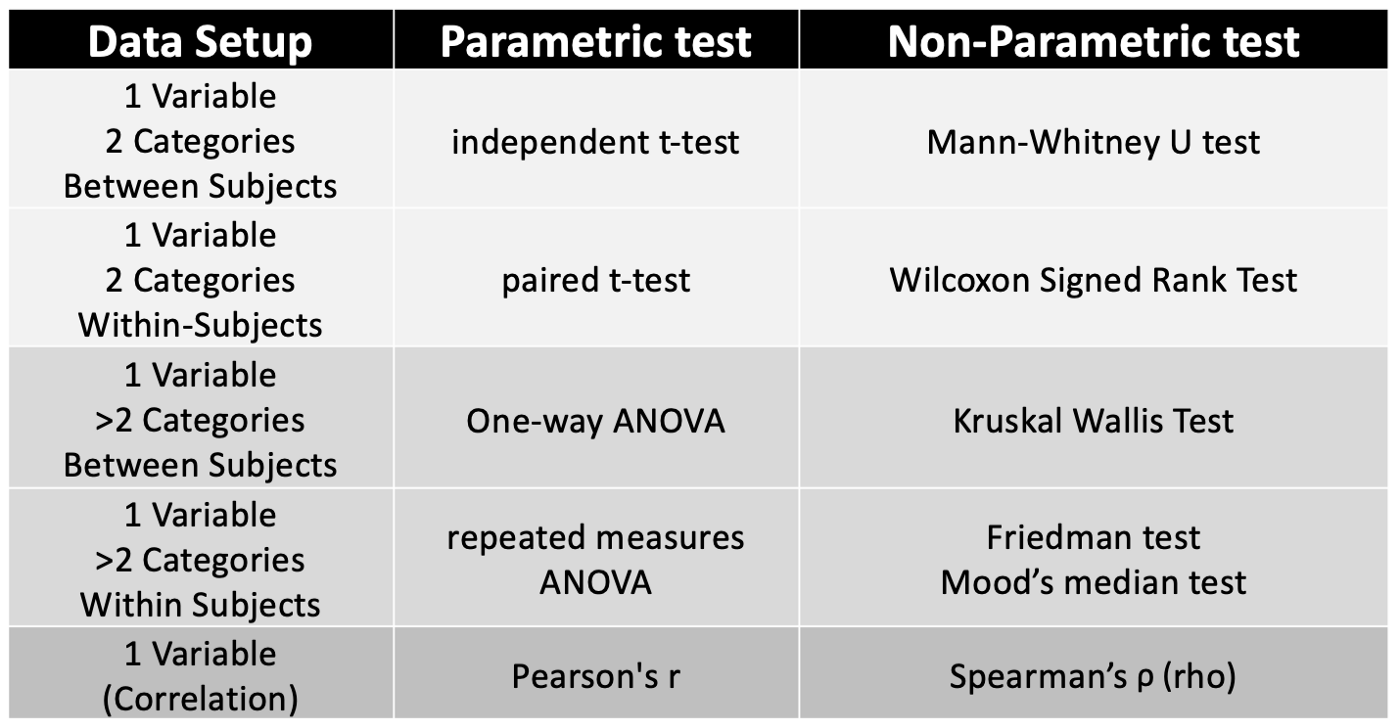
5. What are Parametric and Non-parametric Models?
Parametric models have limited parameters, and only knowledge about the model’s parameters is required to predict new data.
Non-parametric models possess no limits to the number of input parameters allowing for more flexibility in predicting newer data. All we need to know to provide the predictions is the state of the data and the model parameters.
Tabular representation of the differences between Parametric and Non-parametric models
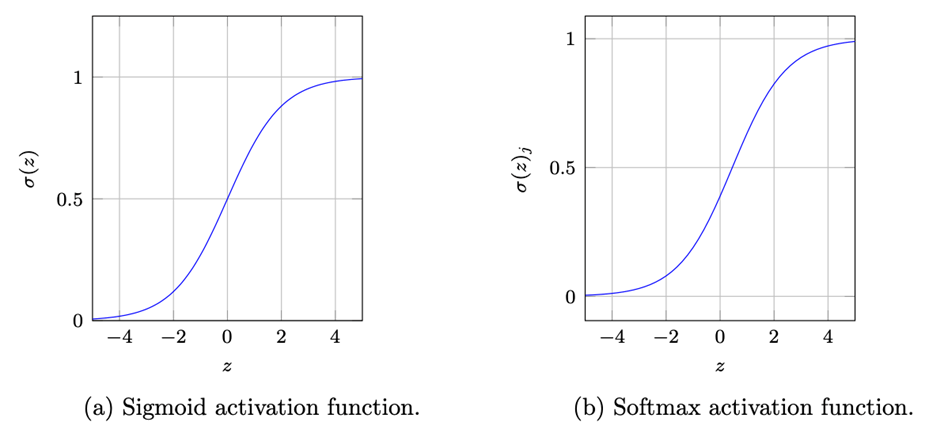
6. What is the Difference between Sigmoid and Softmax functions?
The Sigmoid function is used for Binary Classification methods, where we have only two output classes, whereas the Softmax function is applied to Multiclass methods. Thus it is evident that the input and output of both parts would be slightly different.
The sigmoid function receives just one input and outputs a single number representing the probability of belonging to class 1 or 2.
Whereas the softmax function is vectorized, i.e., it receives a vector with the same number of entries as the number of classes we have. The output vector contains the probabilities of belonging to that class.
Schematic Representation of the Activation Functions, Source: Nomidl
7. How can the Normality of a Dataset be Determined?
The easiest way to determine the normality is to plot the given data. However, a few of the normality tests also exist as below:
Shapiro-Wilk Test
Anderson-Darling Test
Kolmogorov-Smirnov Test
Martinez-Iglewicz Test
D’Agostino Skewness Test
8. How can the K-value be Selected for the K-means Clustering Algorithm?
The K value can be selected in two different ways: Direct Method and Statistical Testing Method.
1. Direct Method: It contains the elbow and silhouette methods
2. Statistical Testing Method: It includes gap statistics
The silhouette method remains the most frequently used for determining the optimal K value.
9. How can you Handle Outliers in a Dataset?
Outliers are data points significantly different from the rest of the dataset. Approaches that can be used to discover the outliers include – Box Plot, Z-Score, Scatter Plot, etc.
The following strategies can typically handle outliers:
1. The easiest way is to drop the outlier values
2. They can be separately marked as outliers and used as a different feature vector
3. The feature can alternatively be transformed to reduce the effect of the outlier
10. Explain the Differences between Loss and Cost Function.
The term loss function can be used when dealing with a single data point, whereas when the sum of the error for multiple data is calculated, the term cost function can be used. As such, intuitively, both terms would mean the same, and no significant difference exists between them. Thus the loss function captures the difference between the actual and predicted values for a single data point, whereas the cost function sums the difference over the entire training data.
Conclusion on Machine Learning
Thus in this first part of the series, we brushed up on the fundamental question of Machine Learning that one is expected to face. Having these thorough who be a boost to your preparation. to summarize, the key takeaways from this article would:
The different categories of machine learning – how and on what basis they can be classified into supervised, unsupervised, and reinforcement learning.
Then we dealt with methods of determining the various essential features of the data, how to find correlation and covariance and how to extract critical, meaningful inferences from such data; we discussed p-value and lasso regression,
Then we discussed parametric and non-parametric models
Key differences between the sigmoid and softmax activation functions were dealt with next
Then an essential step of data normalization was discussed, and the various methods of carrying out the same.
Another critical factor affecting model performance – outliers was discussed next, and the various ways you can handle them were elaborated.
And finally, we finished with the differences between cost and loss function – two of the most common terms you might have used while developing your ML models;
These fundamental questions should be an excellent primer to build upon over the next few blogs to be followed. Stay tuned for the upcoming parts.
In part 2 of this series, I dealt with Deep Learning and the essential aspects of DL. Hope this read could add something valuable to your existing technical know-how of Machine Learning!
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Advancing language model research by day and writing about my work online by night. I explore AI breakthroughs and transform complex studies into clear, engaging insights that empower professionals and enthusiasts alike.