SQL window functions are powerful tools that enable data analysts and developers to perform complex analytical calculations on data sets. They allow for the efficient manipulation and analysis of data by providing a way to compute values across a subset of rows, known as a “window.” These functions offer a more flexible and expressive approach to data aggregation compared to traditional GROUP BY statements. By understanding and leveraging window functions, users can gain deeper insights into their data, identify patterns and trends, and make more informed decisions.
Introducing the Dataset
Before exploring the intricacies of SQL window functions, it’s essential to introduce the dataset that will be used throughout this article. Imagine a company that maintains detailed records of its employees, including their names, job titles, and salaries. This sample dataset will serve as the foundation for understanding the various window function concepts and how they can be applied to real-world data. By working with a realistic dataset, you’ll be able to grasp the practical applications of these powerful SQL tools and translate the knowledge to your own data analysis tasks.
List of SQL Window Functions
Data scientists should consider using Streamlit for a multitude of reasons. Firstly, Streamlit offers an incredible advantage by enabling users to develop interactive web apps without delving into the complexities of traditional web development. With just a few lines of code, utilizing the import streamlit command, data scientists can effortlessly create captivating web apps. The “Sweet Streamlit Hello App” serves as a perfect introduction, showcasing the platform’s intuitive interface and functionalities.
These web apps not only make data analysis more accessible but also enable users to interact with complex data sets in a dynamic and engaging manner. For instance, users can explore interactive visualizations, adjust model parameters, and receive real-time feedback, fostering a deeper understanding of the underlying data and insights.
Moreover, Streamlit’s versatility extends to content delivery, allowing data scientists to share their findings with stakeholders across various platforms and devices. Whether it’s presenting research findings during a conference, collaborating with team members remotely, or showcasing insights to clients, Streamlit empowers data scientists to communicate their work effectively and engage their audience with interactive data experiences.
Key benefits of using Streamlit include:
- Simplicity: Streamlit simplifies the process of creating interactive web apps, requiring only basic Python knowledge.
- Versatility: From simple visualizations to complex machine learning models, Streamlit supports a wide range of data science applications.
- Efficiency: With Streamlit, data scientists can rapidly prototype and iterate on their ideas, accelerating the development cycle.
- Engagement: Interactive web apps created with Streamlit enhance user engagement by allowing users to explore data and insights in real-time.
By simplifying the process of creating and sharing interactive web apps, Streamlit enables data scientists to focus more on their data science expertise and less on the intricacies of software development, ultimately accelerating the pace of innovation in the field.
Exploring Aggregate Window Functions
Aggregate window functions in SQL provide powerful capabilities for analyzing data within specific windows or partitions. These functions offer similar functionalities to standard aggregate functions like AVG, SUM, and COUNT, but with added flexibility and control over how data is aggregated within distinct subsets of a dataset. By leveraging aggregate window functions, users can perform sophisticated analyses, gain deeper insights into their data, and derive actionable intelligence to drive informed decision-making.
One of the most popular aggregate window functions is AVG, which calculates the average value of a specified column within a window. However, aggregate window functions can encompass a variety of operations beyond simple averaging. They can also include additional functions to compute values across the entire dataset, such as calculating the overall mean using AVG().
Moreover, aggregate window functions can incorporate supplementary functions to define the grouping criteria for the window. This allows users to partition the dataset based on specific attributes or conditions, enabling more granular analysis and insight generation.
In practice, the syntax for using aggregate window functions closely resembles that of standard aggregate functions. The key distinction lies in the inclusion of a window specification, which delineates the partitioning and ordering of rows within the dataset. By specifying the window frame, users can define the scope of the aggregation and tailor it to their analytical requirements. Ultimately, aggregate window functions replace the need for traditional GROUP BY statements by offering a more streamlined and expressive approach to data aggregation. By leveraging the capabilities of aggregate window functions, SQL users can perform sophisticated analyses, gain deeper insights into their data, and derive actionable intelligence to drive informed decision-making.
Ranking and Value Window Functions
SQL also offers a range of ranking and value window functions, such as ROW_NUMBER(), RANK(), and DENSE_RANK(), which allow you to assign ranks or sequential numbers to rows within partitions based on specified criteria. Additionally, functions like LEAD() and LAG() enable the comparison of values between the current row and the previous or next row, providing valuable insights into data trends and patterns.
The Power of SQL Window Functions in Data Analysis
SQL window functions are a versatile and powerful tool for data analysis and manipulation. They enable users to perform a wide range of analytical tasks, from ranking and partitioning data to calculating moving averages, cumulative sums, and differences between consecutive rows. By mastering the use of window functions, data professionals can streamline their workflows, enhance their data exploration capabilities, and uncover valuable insights that might otherwise be hidden within large or complex data sets. As the demand for data-driven decision-making continues to grow, the ability to effectively utilize window functions will become an increasingly valuable skill in the data science and business intelligence domains.
What exactly is a window in SQL?
Sure, here’s a structured explanation of what a window is in SQL:
In SQL, a window refers to a subset of rows within a result set that are used for calculations or operations. Windows are defined using a combination of the OVER clause and window functions, allowing users to perform calculations on specific subsets of data without affecting the overall query results.
Key components of a window include:
- Partitioning: Partitioning divides the result set into distinct groups or partitions based on specified criteria. This is achieved using the PARTITION BY clause within the OVER clause. Common partitioning criteria include grouping by columns or expressions, such as dates, categories, or customer IDs.
- Ordering: Ordering determines the sequence of rows within each partition. It specifies how the rows should be arranged before applying window functions. Ordering is accomplished using the ORDER BY clause within the OVER clause, typically based on one or more columns or expressions.
- Frame: The frame defines the window of rows within each partition that are included in the calculation. It specifies the range of rows relative to the current row that should be considered for the computation. The frame is defined using the ROWS or RANGE clause within the OVER clause and can be based on row positions or values.
By leveraging windows, SQL users can perform various analytical tasks, including:
– Aggregation: Computing aggregate functions such as SUM, AVG, MIN, MAX, and COUNT over specific subsets of data within partitions.
– Ranking: Assigning ranks, percentiles, or row numbers to rows within partitions based on specified criteria.
– Windowing: Calculating moving averages, cumulative totals, or other window-specific operations over consecutive or overlapping rows.
Overall, windows provide a flexible and efficient mechanism for performing complex analytical operations in SQL, enabling users to gain deeper insights into their data and derive actionable intelligence for decision-making.
Understanding SQL Window Functions – Over Clause
For example, if I were to display the total salary of employees along with every row value, it would look something like this:
The OVER clause signifies a window of rows over which a window function is applied. It can be used with aggregate functions, like we have used with the SUM function here, thereby turning it into a window function. Or, it can also be used with non-aggregate functions that are only used as window functions (we will learn more about them in the later sections).
So the syntax for defining a simple window function that outputs the same value for all rows is as follows:
window_function_name(<expression>) OVER ( )
But, how about applying the window function to specific rows instead of on the entire table?
Windowing with PARTITION BY
The PARTITION BY clause is used in conjunction with the OVER clause. It breaks up the rows into different partitions. These partitions are then acted upon by the window function.
For example, to display the total salary per job category for all the rows we would have to modify our original SQL query as follows:
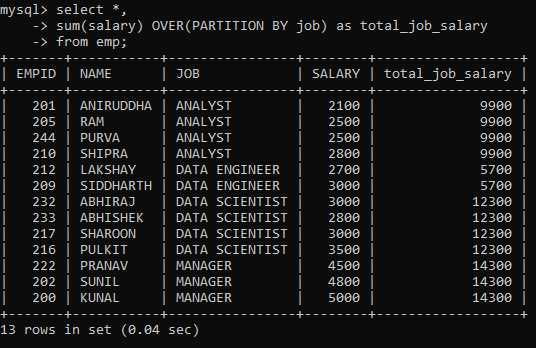
As you can see, the total_job_salary column depicts the sum of sales for that specific job category and not for the entire table.
So, the syntax for defining window function for the partition of rows is as follows:
window_function_name(<expression>) OVER (<partition_by_clause>)
Now, how about arranging the rows within each partition?
Arranging Rows within Partitions
We know that to arrange rows in a table, we can use the ORDER BY clause. So, to arrange rows within each partition, we have to modify the OVER clause with the ORDER BY clause.
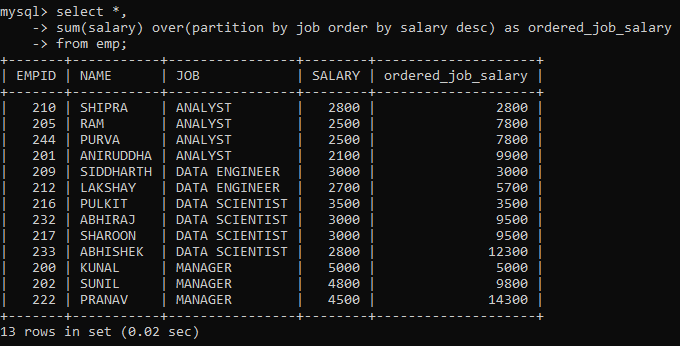
Here, the rows have been partitioned as per their job category as indicated by the JOB column. As you scroll down, you will notice the SALARY column has been ordered in descending order and the ordered_job_salary column depicts the running total of the job category (starting over after every partition).
So, the syntax for defining window function for the partition of rows and arranging them in order is as follows:
window_function_name(<expression>) OVER (<partition_by_clause> <order_clause>)
Window Functions
Now that we know how to define window functions using the OVER clause and some of its modified versions, we can finally move on to working with the window functions!
1. Row_Number
Sometimes your dataset might not have a column depicting the sequential order of the rows, as is the case with our dataset. In that case, we can make use of the ROW_NUMBER() window function. It assigns a unique sequential number to each row of the table.
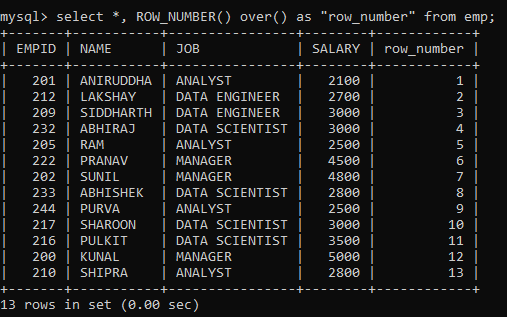
Notice that the numbering starts from 1. Also, to prevent any clash with the MySQL keyword for the function, I have put the column name within quotes.
But, since it is a window function, we can also limit it to partitions and then order those partitions.
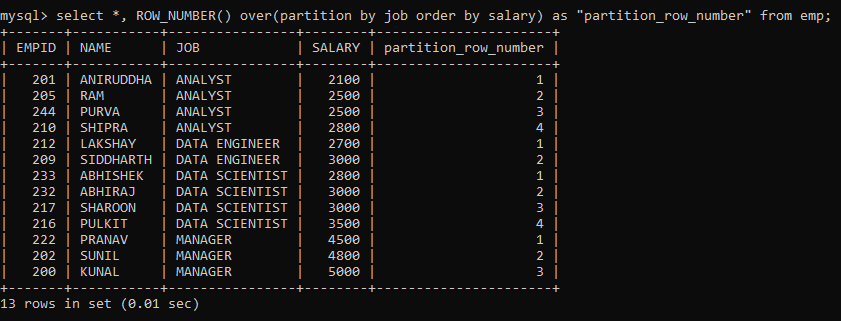
Here, we have partitioned the rows on the JOB column and ordered them based on the SALARY of the employee. Notice how the numbering restarts each time a new partition begins.
But suppose we want to rank the employees based on their salaries?
2. Rank vs Dense_Rank
The RANK() window function, as the name suggests, ranks the rows within their partition based on the given condition.
Notice the highlighted portion. In the case of ROW_NUMBER(), we have a sequential number. On the other hand, in the case of RANK(), we have the same rank for rows with the same value.
But there is a problem here. Although rows with the same value are assigned the same rank, the subsequent rank skips the missing rank. This wouldn’t give us the desired results if we had to return “top N distinct” values from a table. Therefore we have a different function to resolve this issue.
The DENSE_RANK() function is similar to the RANK() except for one difference, it doesn’t skip any ranks when ranking rows.
Here, all the ranks are distinct and sequentially increasing within each partition. As compared to the RANK() function, it has not skipped any rank within a partition.
3. Nth_Value
If you want to retrieve the nth value from a window frame for an expression, then you can use the NTH_VALUE(expression, N) window function.
For example, to retrieve the third-highest salary in each JOB category, we can partition the rows according to the JOB column, then order the rows within the partitions according to decreasing salary, and finally, use the NTH_VALUE function to retrieve the value. The command will be as follows:
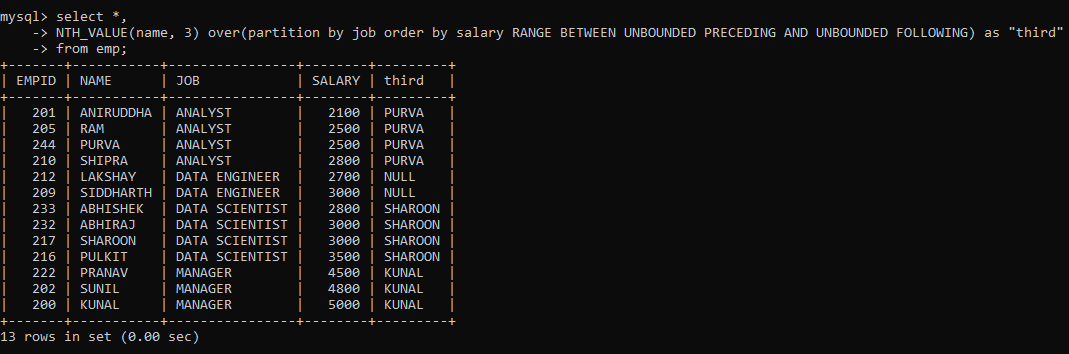
You must have noticed something different after the Order By clause. That is the Frame clause. It determines the subset of the partition (or frame) that will be used by the window function to calculate the value for the current row.
Here, I mentioned that all preceding and following rows for a current row be considered as within the frame when applying the window function. But why did I use the frame clause here and not with other functions? This is because the other window functions work on the entire partition even if a frame clause is provided. But only NTH_VALUE() can work on frames within a partition.
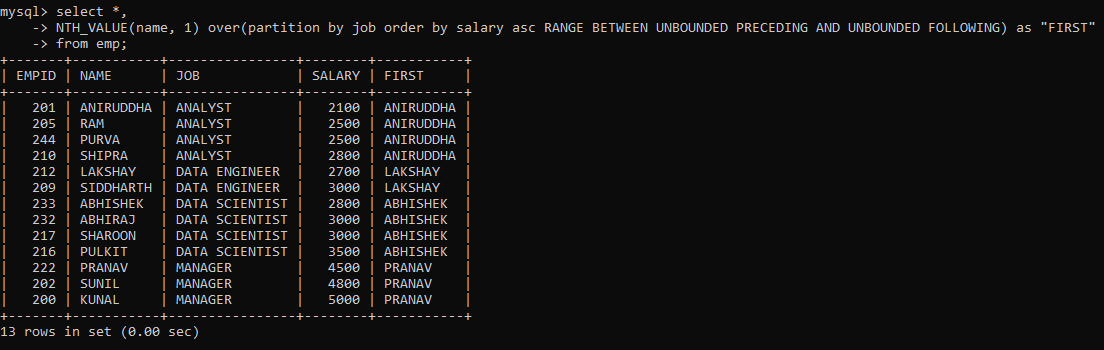
Now suppose you wanted to output the first value from each partition? Although there is a FIRST_VALUE() function as well, I am going to use the NTH_VALUE for the same.
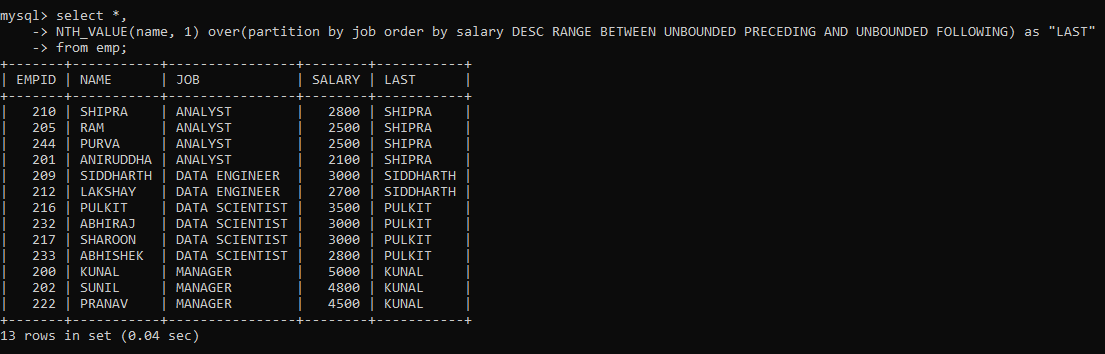
Similarly, just we also have a LAST_VALUE() function. But I am going to determine the last value within each partition just as above, albeit using the decreasing order of rows.
4. Ntile
Sometimes, you might want to sort the rows within the partition into a certain number of groups. This is useful when you want to determine the percentile, quartile, etc. a particular row falls into. The NTILE() function is used for such purposes. It returns the group number for each of the rows in the partition.
For example, let’s find the quartile for each row based on the SALARY of the employee:
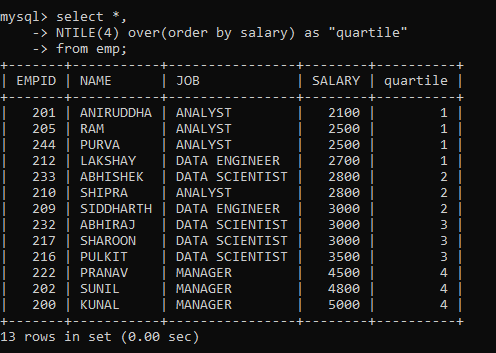
Similarly, you can divide the rows into different numbers of groups and calculate the NTILE for different partitions.
5. Lead and Lag
Often, you might want to compare the value of the current row to that of the preceding or succeeding row. It helps in the easy analysis of the data. The LEAD() and LAG() window functions are there just for this purpose.
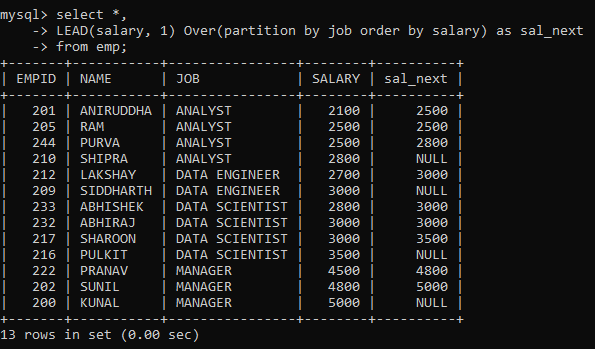
Here, we created a new column containing SALARY from the next row within each partition ordered by salary using the LEAD function. Notice that the last row from each partition contains a null value because there is no succeeding row for it to pull data from.
Now, let’s do the same with the LAG function.
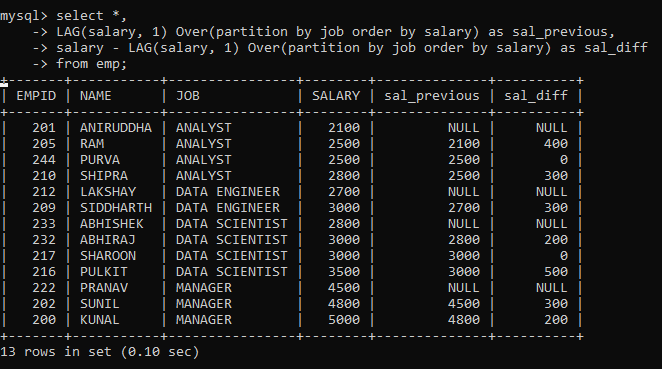
Here, we created two new columns. The first column contains SALARY from the previous row within each partition ordered by salary. While the second column contains the difference between SALARY from the previous row and the current row. As you can see, this is very helpful for a quick analysis of the difference between salaries within the same partition.
Window Function vs. Aggregate Function vs. GROUP BY
When working with SQL, it’s essential to understand the distinctions between window functions, aggregate functions, and the GROUP BY clause, as each serves a unique purpose in data analysis and manipulation.
- Aggregate Functions: Aggregate functions in SQL are used to perform calculations across multiple rows and return a single result. These functions typically operate on entire columns and produce a summary statistic, such as the sum, average, count, minimum, or maximum value within a dataset. Examples of aggregate functions include SUM(), AVG(), COUNT(), MIN(), and MAX().Keywords: Aggregate, Calculation, Summary, Result, Columns, Data Set, SUM, AVG, COUNT, MIN, MAX.
- GROUP BY Clause: The GROUP BY clause is used to group rows that have the same values into summary rows, typically to perform aggregate functions on these groups. When used with aggregate functions, the GROUP BY clause partitions the dataset into groups based on specified columns or expressions. Each group represents a distinct subset of data, and aggregate functions are applied independently to each group.Keywords: Grouping, Summary Rows, Aggregate Functions, Partitions, Dataset, Distinct, Subsets, Columns, Expressions.
- Window Functions: Window functions in SQL allow calculations to be performed across a set of rows related to the current row, known as a window. Unlike aggregate functions, window functions operate on a “window” of rows defined by the OVER clause. This window can be partitioned, ordered, and framed, providing flexibility in how calculations are applied within the dataset.Keywords: Window, Rows, Calculation, Current Row, Partitioned, Ordered, Framed, OVER Clause.
Comparison:
- Aggregate functions compute a single result across all rows or within each group defined by the GROUP BY clause.
- The GROUP BY clause partitions the dataset into groups, and aggregate functions are applied independently to each group.
- Window functions operate on a set of rows within a defined window, providing more flexibility in calculations and allowing access to multiple rows related to the current row.
- While aggregate functions and GROUP BY are used for summarizing data, window functions are often used for analytical tasks such as ranking, moving averages, and cumulative sums.
Understanding the differences between window functions, aggregate functions, and the GROUP BY clause is crucial for efficiently analyzing and manipulating data in SQL, enabling users to perform a wide range of analytical tasks and derive meaningful insights from their datasets.
Conclusion
In conclusion, SQL window functions are a versatile and powerful tool for data analysis and manipulation. They enable users to perform a wide range of analytical tasks, from ranking and partitioning data to calculating moving averages and cumulative sums. By mastering the use of window functions, data professionals can streamline their workflows, enhance their data exploration capabilities, and uncover valuable insights that might otherwise be hidden within large or complex data sets. As the demand for data-driven decision-making continues to grow, the ability to effectively utilize window functions will become an increasingly valuable skill in the data science and business intelligence domains.
Frequently Asked Questions?
Q1. Which are window function in SQL?
A. The window function gives you the opportunity to view the records directly before and afterwards. The windows function defines frames or windows with given lengths in the current table and performs calculation across data sets in the window.
Q2. What is a window function in SQL for dummies?
A. Windows functions are specialized functions in SQL which perform computations across rows. This function operates on a subset of rows, called a window defined through over() clauses. Let me describe how syntax can be broken.
Q3. What are window functions in SQL w3schools?
A. Introduction to SQL Window Functions Similar to the aggregate functions, the window functions calculate rows from rows. In addition, windows can only group rows together into one output row. The over() clause indicates the SUM function is being used to operate the windows in the above example.
Q4. How to use multiple window functions in SQL?
A. If using windows in a query, define the windows with an Over() clause. This section distinguishes windows functions from other analytical or reporting functions. A query may be used in several windows using the same window definition.
Q5. What does a window function do in SQL?
A. Windows functionality allows for access to data within records immediately before or after current records. A window function creates a frame and window of columns that has a length that is arranged around the current row, and performs computation across all of the data within that window.
I am on a journey to becoming a data scientist. I love to unravel trends in data, visualize it and predict the future with ML algorithms! But the most satisfying part of this journey is sharing my learnings, from the challenges that I face, with the community to make the world a better place!







I'm interested job IT field and data analysit course
You could also add UNBOUNDED PRECEDING and CURRENT ROW windowing as well. Good blog, BTW
Hi, Thanks for suggesting!
Hi Aniruddha, thanks for this great post. Window Functions are a powerful tool and come in very handy for many everyday problems. Can it be, that the rolling sum for the ANALYST Job is not correctly calculated (Section "Arranging Rows within Partitions"). The rolling sum for the second and third record are identical. Do you know how to overcome this issue? Besides that, adding a paragraph about the window frame clause would make this post perfect to me. Best Markus
Hi, You can try the following command: select *, sum(salary) over(partition by job order by salary desc rows between unbounded preceding and current row) as ordered_job_salary from emp; Thanks for recommending the paragraph on the frame clause. I'll add it pretty soon. Thank you.