This article was published as a part of the Data Science Blogathon

Objective
To get the bounding boxes around the scanned documents with paragraphs and tables.
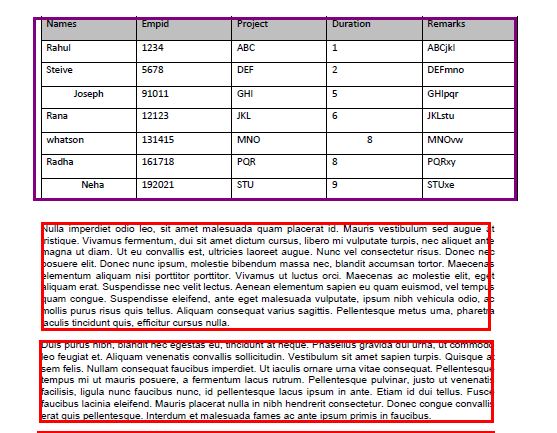
If we are having a scanned document or scanned images and we want to detect the paragraphs and tables in the image and like a layout and get bounding boxes around them as shown in the image below.
The problem is that we do not have to detect the words or headlines. We just have to detect the paragraphs and tables. This will be useful in many use cases in official documents.
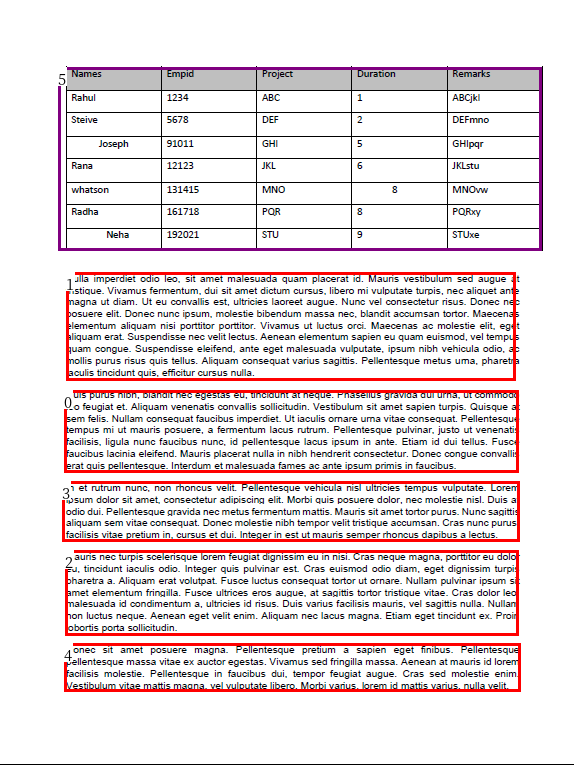
Solution Approach
To get the bounding boxes from the model in Deep learning and performing OCR with OpenCV and API. Here are some steps to make this work.
1. Install all required packages
You have to install layout parser and detectron2 for detection.
You can see more details on Detectron here:https://github.com/facebookresearch/detectron2/tree/master/projects
!pip install layoutparser !pip install detectron2 -f https://dl.fbaipublicfiles.com/detectron2/wheels/cu101/torch1.8/index.html
2. Convert the image from BGR (cv2 default loading style) to RGB
OpenCV uses the BGR image format. So, when we read an image using cv2.imread() it interprets in BGR format by default.
We can use cvtColor() or image[…, ::-1] method to convert a BGR image to RGB and vice-versa.
image = cv2.imread("/content/imagetemp.png")
image = image[..., ::-1]
3. Get the config files for the layout parser
In computing, config files are files used to configure the parameters and initial settings for some computer programs. They are used for user applications, server processes, and OS operating system settings.
#!wget https://www.dropbox.com/s/f3b12qc4hc0yh4m/config.yml?dl=1 #getting config file !wget https://www.dropbox.com/s/nau5ut6zgthunil/config.yaml?dl=1
4. Get the layout and bounding boxes perfectly
Here I have mapped the colour for each and every part that can be a part of the scanned image. After that, I have drawn the layout boxes around them.
color_map = {
'Text': 'red',
'Title': 'blue',
'List': 'green',
'Table': 'purple',
'Figure': 'pink',
}
lp.draw_box(image, layout, box_width=3, color_map=color_map )
5. Perform OCR on text
Optical character recognition or optical character reader (OCR) is the electronic conversion of images of typed, handwritten, or printed text into machine-encoded text, whether from a scanned document, a photo of a document, a scene photo.
Here I have used Python-tesseract as the optical character recognition (OCR) tool for python. That is, it will recognize and “read” the text embedded in images.
Python-tesseract is a wrapper for Google’s Tesseract-OCR Engine. It is also useful as a stand-alone invocation script to tesseract, as it can read all image types supported by the Pillow and Leptonica imaging libraries, including jpeg, png, gif, BMP, tiff, and others.
Additionally, if used as a script, Python-tesseract will print the recognized text instead of writing it to a file.
for block in text_blocks:
segment_image = (block.pad(left=5, right=5, top=5, bottom=5).crop_image(image))
text = ocr_agent.detect(segment_image)
block.set(text=text, inplace=True)
6. For detecting the tables you have to process images in OpenCV
In digital image processing, thresholding is the simplest method of segmenting images. From a grayscale image, thresholding can be used to create binary images.
https://docs.opencv.org/master/d7/d4d/tutorial_py_thresholding.html
file=r'/content/imagetemp.png'
img = cv2.imread(file,0)
img.shape
#thresholding the image to a binary image
thresh,img_bin = cv2.threshold(img,128,255,cv2.THRESH_BINARY)
#inverting the image
img_bin = 255-img_bin
cv2.imwrite('cv_inverted.png',img_bin)
#Plotting the image to see the output
plotting = plt.imshow(img_bin,cmap='gray')
plt.show()
.png)
Use horizontal kernel to detect and save the horizontal lines in a jpg
image_2 = cv2.erode(img_bin, hor_kernel, iterations=3)
horizontal_lines = cv2.dilate(image_2, hor_kernel, iterations=3)
cv2.imwrite("horizontal.jpg",horizontal_lines)
#Plot the generated image
plotting = plt.imshow(image_2,cmap='gray')
plt.show()
.png)
Detect contours for following box detection
Contours can be explained simply as a curve joining all the continuous points (along the boundary), having the same colour or intensity. The contours are a useful tool for shape analysis and object detection and recognition.
https://docs.opencv.org/3.4/d4/d73/tutorial_py_contours_begin.html
contours, hierarchy = cv2.findContours(img_vh, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
def sort_contours(cnts, method="left-to-right"):
# initialize the reverse flag and sort index
reverse = False
i = 0
# handle if we need to sort in reverse
if method == "right-to-left" or method == "bottom-to-top":
reverse = True
# handle if we are sorting against the y-coordinate rather than
# the x-coordinate of the bounding box
if method == "top-to-bottom" or method == "bottom-to-top":
i = 1
# construct the list of bounding boxes and sort them from top to
# bottom
boundingBoxes = [cv2.boundingRect(c) for c in cnts]
(cnts, boundingBoxes) = zip(*sorted(zip(cnts, boundingBoxes),
key=lambda b:b[1][i], reverse=reverse))
# return the list of sorted contours and bounding boxes
return (cnts, boundingBoxes)
Sort all the contours by top to bottom
Creating a list of heights for all detected boxes and Get the mean of heights and Get the position (x,y), width and height for every contour and show the contour on the image.
contours, boundingBoxes = sort_contours(contours, method="top-to-bottom")
heights = [boundingBoxes[i][3] for i in range(len(boundingBoxes))]
#Get mean of heights
mean = np.mean(heights)
#Create list box to store all boxes in
box = []
# Get position (x,y), width and height for every contour and show the contour on image
for c in contours:
x, y, w, h = cv2.boundingRect(c)
if (w<1100 and h<600):
image = cv2.rectangle(img,(x,y),(x+w,y+h),(0,255,0),2)
box.append([x,y,w,h])
plotting = plt.imshow(image,cmap='gray')
plt.show()
#Creating two lists to define row and column in which cell is located
row=[]
column=[]
j=0
#Sorting the boxes to their respective row and column
for i in range(len(box)):
if(i==0):
column.append(box[i])
previous=box[i]
else:
if(box[i][1]<=previous[1]+mean/2):
column.append(box[i])
previous=box[i]
if(i==len(box)-1):
row.append(column)
else:
row.append(column)
column=[]
previous = box[i]
column.append(box[i])
print(column)
print(row)
#calculating maximum number of cells
countcol = 0
for i in range(len(row)):
countcol = len(row[i])
if countcol > countcol:
countcol = countcol
#Retrieving the center of each column
center = [int(row[i][j][0]+row[i][j][2]/2) for j in range(len(row[i])) if row[0]]
center=np.array(center)
center.sort()
print(center)
#Regarding the distance to the columns center, the boxes are arranged in respective order
finalboxes = []
for i in range(len(row)):
lis=[]
for k in range(countcol):
lis.append([])
for j in range(len(row[i])):
diff = abs(center-(row[i][j][0]+row[i][j][2]/4))
minimum = min(diff)
indexing = list(diff).index(minimum)
lis[indexing].append(row[i][j])
finalboxes.append(lis)
#from every single image-based cell/box the strings are extracted via pytesseract and stored in a list
outer=[]
for i in range(len(finalboxes)):
for j in range(len(finalboxes[i])):
inner=''
if(len(finalboxes[i][j])==0):
outer.append(' ')
else:
for k in range(len(finalboxes[i][j])):
y,x,w,h = finalboxes[i][j][k][0],finalboxes[i][j][k][1], finalboxes[i][j][k][2],finalboxes[i][j][k][3]
finalimg = bitnot[x:x+h, y:y+w]
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (2, 1))
border = cv2.copyMakeBorder(finalimg,2,2,2,2, cv2.BORDER_CONSTANT,value=[255,255])
resizing = cv2.resize(border, None, fx=2, fy=2, interpolation=cv2.INTER_CUBIC)
dilation = cv2.dilate(resizing, kernel,iterations=1)
erosion = cv2.erode(dilation, kernel,iterations=2)
out = pytesseract.image_to_string(erosion)
if(len(out)==0):
out = pytesseract.image_to_string(erosion, config='--psm 3')
inner = inner +" "+ out
outer.append(inner)
#Creating a dataframe of the generated OCR list
arr = np.array(outer)
dataframe = pd.DataFrame(arr.reshape(len(row), countcol))
Finally to Dataframe
Here I have just converted the array to a dataframe.
dataframe = pd.DataFrame(arr.reshape(len(row), countcol)) dataframe
Thanks for reading the article. Hope you will find it useful. If you want to have a look at the code please check here at colab.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.
I have 4+ years of working experience working with Big Data Analytics and the Cloud. Worked with different domains like Capital Markets, Insurance, FinTech, MedTech/Healthcare. Have designed scalable & optimized data pipelines for mostly Batch Processing Utilizing Cloud.
✔️ Building data warehouses /Data lakes using modern cloud platforms and technologies.
✔️ Implementing and automating data pipelines, ETL processes.
✔️ Data Cleaning, Processing, and Standardization (Machine Learning and NLP).
✔️ Data Migration (Heterogenous and Homogenous)
Some of the technologies I most frequently work with are:
👨💻 Programming: Python, PySpark, SQL, Pandas
☁️ Cloud: AWS
🔰 Databases: Redshift, RDS, PostgreSQL, MySQL, S3, Cloud Data Store
⚙️ Data Integration/ETL: AWS Glue & EMR, Airflow
📊 BI/Visualization: Tableau, Excel
🤖 Big Data - Hadoop, Hive, Spark, NLP, Jupyter Notebook, Data Structures
I love to adapt to new technologies to solve different business problems. I want to work with Petabytes of real-time/Streaming/Batch data and build good platforms. Looking forward to exploring.



Thank you but there are some missing parts in the code, so it is not possible to use the code.
Hi @Kuldeep Pal and thanks for this walkthrough. Unfortunately the Colab notebook link is broken. I was wondering if you would be able to share it please? Thanks :)