Introduction
When given a bunch of movies to organize, you might sort them based on similarity measures such as genre, year of release, casting, revenue generated, and so on. While you categorize them based on a measure, it doesn’t mean that a measure used by others is of no good. Our perception of data is greatly influenced by the clustering measure being used. When you believe that two sci-fi movies belong to the same cluster, someone else might consider two movies released in the same year to be in the same cluster. Because you might have used the genre as a measure to cluster and the other person might have used the year of release as a measure.
Learning Objectives:
- Understand the concept of clustering and how it differs from classification
- Learn about the two major approaches to clustering: compactness and connectivity
- Grasp the key steps involved in the spectral clustering algorithm
- Familiarize with the advantages and limitations of spectral clustering
This article was published as a part of the Data Science Blogathon
Table of contents
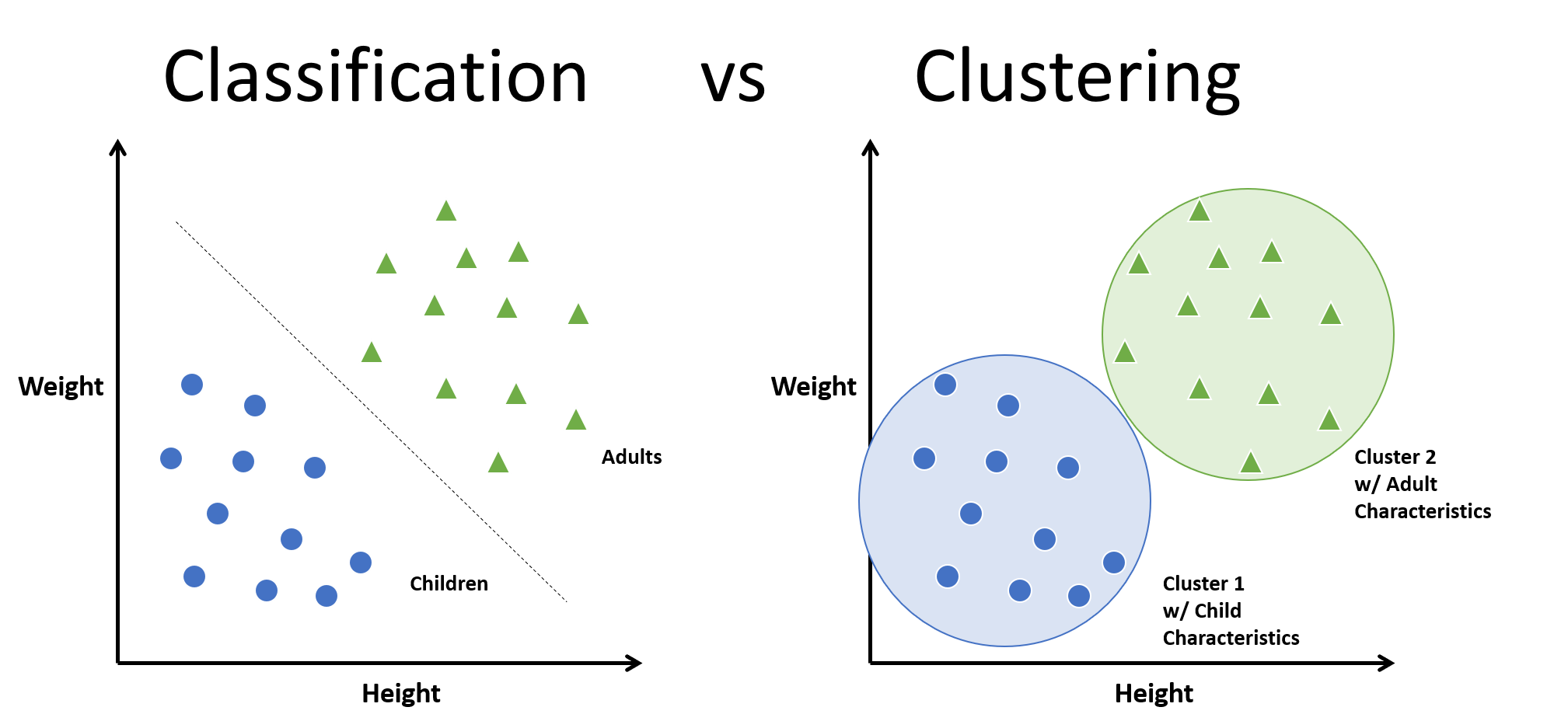
Classifications vs Clustering
In machine learning, humans widely use clustering, an unsupervised algorithm that groups unlabeled data points based on similarity and distance measures. If the data points are labeled, the grouping is known as classification. Many applications utilize clustering algorithms, such as anomaly detection, image segmentation, search result grouping, market segmentation, and social network analysis. Clustering is one of the primary steps in exploratory data analysis for visualizing similarity and identifying hidden patterns in data points. The goal of clustering is to uncover similarities within a cluster and differences between clusters.
Support Vector Machines, Decision trees, Random forests, Linear classifiers and Neural networks are few classification algorithms whereas K means clustering, Fuzzy analysis clustering, Mean shift, DBSCAN and Spectral are clustering algorithms.
There are two major approaches in clustering. They are:
- Compactness
- Connectivity
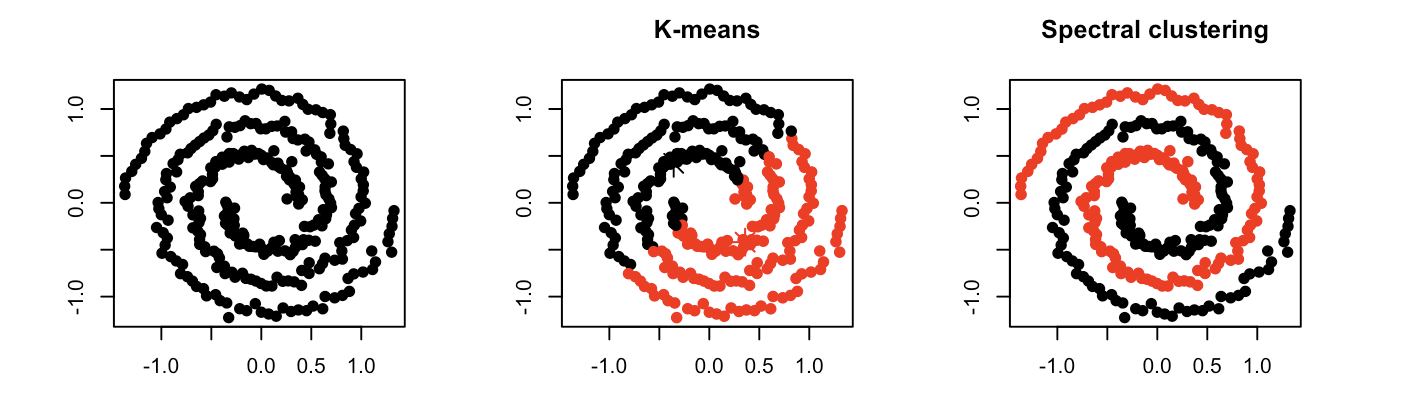
In compactness, the points are closer to each other and are compact towards the cluster center. Distance is used as a measure to compute closeness. There are different types of distance metrics that are in use. A few of them are Euclidean distance, Manhattan distance, Minkowski distance, and Hamming distance. K-means algorithm uses the compactness approach. In connectivity, the points in a cluster are either immediately next to each other (epsilon distance) or connected. Even if the distance is less, the algorithm does not place them in the same cluster. Spectral Clustering Algorithm is one of the techniques that follows this approach.
How to do Spectral Clustering?
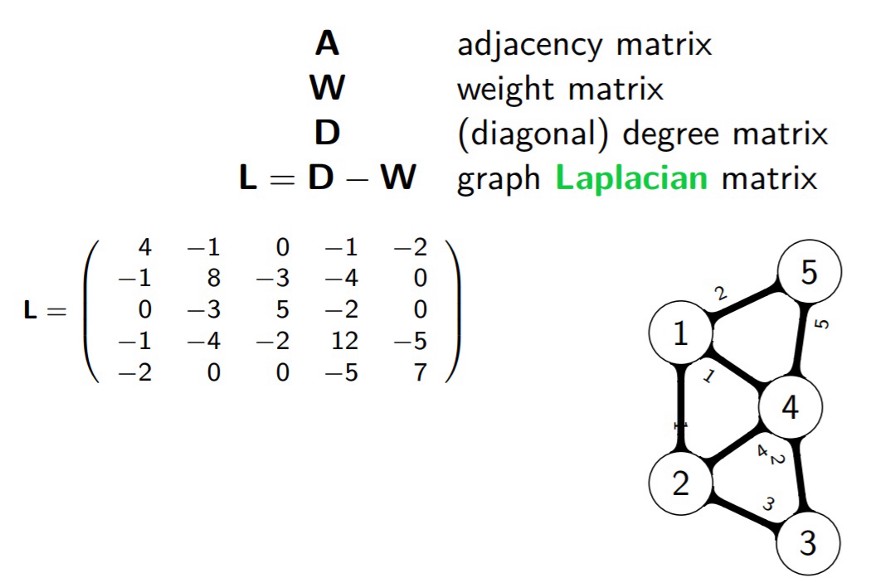
The three major steps involved in Spectral Clustering Algorithm are: constructing a similarity graph, projecting data onto a lower-dimensional space, and clustering the data. Given a set of points S in a higher-dimensional space, it can be elaborated as follows:
- Form a distance matrix
- Transform the distance matrix into an affinity matrix A
- Compute the degree matrix D and the Laplacian matrix L = D – A.
- Find the eigenvalues and eigenvectors of L.
- With the eigenvectors of k largest eigenvalues computed from the previous step form a matrix.
- Normalize the vectors.
- Cluster the data points in k-dimensional space.
Pros and Cons of Spectral Clustering
Spectral clustering helps us overcome two major problems in clustering: one being the shape of the cluster and the other is determining the cluster centroid. K-means algorithm generally assumes that the clusters are spherical or round i.e. within k-radius from the cluster centroid. In K-means, the algorithm requires many iterations to determine the cluster centroid. In spectral clustering, the clusters do not adhere to a fixed shape or pattern. The algorithm assigns points that are far apart but connected to the same cluster, while points that are close to each other could belong to different clusters if they are not connected. This suggests that the algorithm may be effective for data with varying shapes and sizes.
When compared with other algorithms, it is computationally fast for sparse datasets of several thousand data points. You don’t need the actual dataset to work with. Although computing eigenvalues and eigenvectors for large datasets and then performing clustering may be costly, the algorithms aim to reduce the cost. One must fix the number of clusters (k) before initiating the procedure.
Where can I use spectral clustering?
Spectral clustering has its application in many areas which includes: image segmentation, educational data mining, entity resolution, speech separation, Spectral Clustering Algorithm of protein sequences, text image segmentation. Although spectral clustering is a technique based on graph theory, it is used to identify communities of vertices in a graph based on the edges connecting them. This method is flexible and allows us to cluster non-graph data as well either with or without the original data.
Python packages for spectral clustering: spectralcluster. SpectralCluster is a python library that has inbuilt code for spectral clustering. There are other packages with which we can implement the spectral clustering algorithm.
Let us try an example with spectral clustering algorithm available from sklearn package.
Python Code:
from spectralcluster import SpectralClusterer
from sklearn.cluster import SpectralClustering
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
from numpy import random
clusterer = SpectralClusterer(
min_clusters=2,
max_clusters=100)
X = random.randint(1,10,(3,4))
labels = clusterer.predict(X)
print(labels)
random.seed(1)
x, _ = make_blobs(n_samples=400, centers=4, cluster_std=1.5)
plt.scatter(x[:,0], x[:,1])
plt.show()where X is a NumPy array of shape (n_samples, n_features) and the returned labels is a NumPy array of shape (n_samples, ).
Clustering with the spectral clustering and visualizing the data
sc=SpectralClustering(n_clusters=4).fit(x)
SpectralClustering(affinity='rbf', assign_labels='kmeans', coef0=1, degree=3,
eigen_solver=None, eigen_tol=0.0, gamma=1.0,
kernel_params=None, n_clusters=4, n_components=None,
n_init=10, n_jobs=None, n_neighbors=10, random_state=None)
labels = sc.labels_
plt.scatter(x[:,0], x[:,1], c=labels)
plt.show()
print(sc)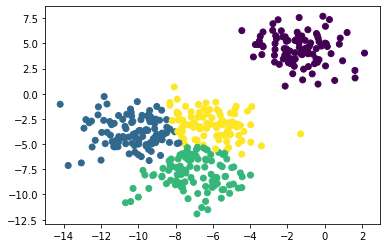
Let’s try changing the number of clusters.
f = plt.figure()
f.add_subplot(2, 2, 1)
for i in range(2, 6):
sc = SpectralClustering(n_clusters=i).fit(x)
f.add_subplot(2, 2, i-1)
plt.scatter(x[:,0], x[:,1], s=5, c=sc.labels_, label="n_cluster-"+str(i))
plt.legend()
plt.show()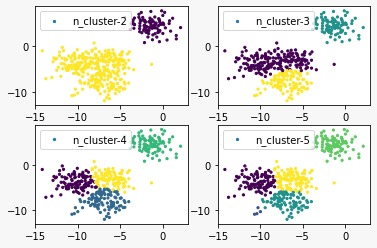
Conclusion
Spectral clustering is a powerful technique that uses eigenvectors to partition data into clusters, overcoming the limitations of traditional methods like K-means. It can effectively handle non-linearly separable data and clusters of arbitrary shapes. While computationally expensive for large datasets, Spectral Clustering Algorithm finds applications in diverse areas such as image segmentation, speech separation, and network analysis. By leveraging graph theory and linear algebra concepts, this method identifies natural groupings in data based on connectivity and affinity measures. As demonstrated, spectral clustering offers an excellent option when dealing with complex, non-convex cluster structures, providing valuable insights into the inherent patterns within datasets.
Key Takeaways:
- Spectral clustering is an effective technique for partitioning non-linearly separable data into clusters of arbitrary shapes
- It overcomes the limitations of centroid-based methods like K-means by using eigenvectors and connectivity measures
- Spectral clustering is useful for applications like image segmentation, speech separation, and social network analysis
- While computationally expensive for large datasets, it offers a powerful solution for complex, non-convex cluster structures
Frequently Asked Questions
Q1. What is meant by spectral clustering?
A. Spectral clustering partitions data based on affinity, using eigenvalues and eigenvectors of similarity matrices to group data points into clusters, often effective for non-linearly separable data.
Q2. What is the difference between K-means and spectral clustering?
A. K-means partitions data based on centroids and distances, suitable for convex clusters, while spectral clustering uses eigenvectors to find more complex clusters in non-linear datasets.
Q3. What is the objective function of spectral clustering?
A. The objective function of spectral clustering aims to minimize the normalized cut or ratio cut, quantifying the dissimilarity between clusters while maximizing similarity within clusters using eigenvectors.
Q4. What are spectral methods for graph clustering?
A. Spectral methods for graph clustering use eigenvalues and eigenvectors of matrices derived from graph structures to partition nodes into clusters based on similarities, offering effective solutions for complex network structures.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.






This guide is fantastic for beginners! I love how clearly you explained the concepts behind spectral clustering. The visuals really helped me understand the process better. Can't wait to try it out on my own datasets!