Clustering is a fundamental technique in unsupervised learning, essential for grouping data points and uncovering hidden patterns. This article focuses on key clustering interview questions, covering concepts like K-Means, hierarchical clustering, and DBSCAN. Whether you’re preparing for an interview or enhancing your skills, these questions will help you master clustering and tackle real-world challenges effectively.
Clustering Techniques Skill Test Questions & Answers
Q1. Movie recommendation systems are an example of:
- Classification
- Clustering
- Reinforcement Learning
- Regression
Options:
A. 2 Only
B. 1 and 2
C. 1 and 3
D. 2 and 3
E. 1, 2, and 3
F. 1, 2, 3, and 4
Solution: (E)
Generally, movie recommendation systems cluster the users in a finite number of similar groups based on their previous activities and profiles. Then, people in the same cluster make similar recommendations at a fundamental level.
In some scenarios, this can also be approached as a classification problem for assigning the most appropriate movie class to the user of a specific group of users. Also, a movie recommendation system can be viewed as a reinforcement learning problem where it learns from its previous recommendations and improves future recommendations.
Q2. Sentiment Analysis is an example of:
- Regression
- Classification
- Clustering
- Reinforcement Learning
Options:
A. 1 Only
B. 1 and 2
C. 1 and 3
D. 1, 2 and 3
E. 1, 2 and 4
F. 1, 2, 3 and 4
Solution: (B)
Sentiment Analysis is primarily a classification task, as it categorizes text into sentiments like positive, negative, or neutral. However, it can also involve regression when predicting sentiment scores on a continuous scale. Clustering and reinforcement learning are not typically used in sentiment analysis.
Q3. Can decision trees be used to perform clustering?
A. True
B. False
Solution: (A)
Decision trees (and also random forests)can also be used for clusters in the data, but clustering often generates natural clusters and is not dependent on any objective function.
Q4. Which of the following is the most appropriate strategy for data cleaning before performing clustering analysis, given less than the desirable number of data points?
- Capping and flooring of variables
- Removal of outliers
Options:
A. 1 only
B. 2 only
C. 1 and 2
D. None of the above
Solution: (A)
If there are few data points, removing outliers is not recommended. The most appropriate strategy in this scenario is to cap and floor variables.
Q5. What is the minimum no. of variables/ features required to perform clustering?
Options:
A. 0
B. 1
C. 2
D. 3
Solution: (B)
To perform clustering analysis, at least a single variable is required. Clustering analysis with a single variable can be visualized using a histogram.
Q6. For two runs of K-Mean clustering, is it expected to get the same clustering results?
A. Yes
B. No
Solution: (B)
K-Means clustering algorithm instead converses on local minima, which might also correspond to the global minima in some cases but not always. Therefore, running the K-Means algorithm multiple times is advised before drawing inferences about the clusters.
However, receiving the same clustering results from K-means is possible by setting the same seed value for each run. This is done by simply making the algorithm choose the same random number set for each run.
Q7. Is it possible that the assignment of observations to clusters does not change between successive K-Means iteration?
Options:
A. Yes
B. No
C. Can’t say
D. None of these
Solution: (A)
In the above clustering question, when the K-Means machine learning model has reached the local or global minima, it will not alter the assignment of data points to clusters for two successive iterations.
Q8. Which of the following can act as possible termination conditions in K-Means?
- For a fixed number of iterations.
- The assignment of observations to clusters does not change between iterations, except for cases with a bad local minimum.
- Centroids do not change between successive iterations.
- Terminate when RSS falls below a threshold.
Options:
A. 1, 3 and 4
B. 1, 2 and 3
C. 1, 2 and 4
D. All of the above
Solution: (D)
All four conditions can be used as possible termination conditions in K-Means clustering:
- This condition limits the runtime of the clustering algorithm, but in some cases, the clustering quality will be poor because of an insufficient number of iterations.
- This produces good clustering except for cases with a bad local minimum, but runtimes may be unacceptably long.
- This also ensures that the algorithm has converged at the minimum.
- Terminate when RSS falls below a threshold. This criterion ensures that the clustering is of the desired quality after termination. Practically, combining it with a bound on the number of iterations to guarantee termination is a good practice.
Q9. Which of the following clustering algorithms suffers from the convergence problem at local optima?
- K- Means clustering algorithm
- Agglomerative clustering algorithm
- Expectation-Maximization clustering algorithm
- Diverse clustering algorithm
Options:
A. 1 only
B. 2 and 3
C. 2 and 4
D. 1 and 3
E. 1,2 and 4
F. All of the above
Solution: (D)
Only the K-Means and EM clustering algorithms have the drawback of converging at local minima.
Q10. Which of the following algorithms is most sensitive to outliers?
Options:
A. K-means clustering algorithm
B. K-medians clustering algorithm
C. K-modes clustering algorithm
D. K-medoids clustering algorithm
Solution: (A)
Out of all the options, the K-Means clustering algorithm is most sensitive to outliers as it uses the mean of cluster data points to find the cluster centre.
Q11. After performing K-Means Clustering analysis on a dataset, you observed the following dendrogram. Which of the following conclusion can be drawn from the dendrogram?

Options:
A. There were 28 data points in the clustering analysis
B. The best no. of clusters for the analyzed data points is 4
C. The proximity function used is Average-link clustering
D. The above dendrogram interpretation is not possible for K-Means clustering analysis
Solution: (D)
A dendrogram is not possible for K-Means clustering analysis. However, one can create a cluster gram based on it.
Q12. How can Clustering (Unsupervised Learning) be used to improve the accuracy of the Linear Regression model (Supervised Learning)?
- Creating different models for different cluster groups.
- Creating an input feature for cluster ids as an ordinal variable.
- Creating an input feature for cluster centroids as a continuous variable.
- Creating an input feature for cluster size as a continuous variable.
Options:
A. 1 only
B. 1 and 2
C. 1 and 4
D. 3 only
E. 2 and 4
F. All of the above
Solution: (F)
In the above clustering questions, creating an input feature for cluster IDs as ordinal variables or an input feature for cluster centroids as a continuous variable might not convey any relevant information to the regression model for multidimensional data. However, for clustering in a single dimension, all the given methods are expected to convey meaningful information to the regression model. For example, clustering people into two groups based on their hair length, and storing clustering IDs as ordinal variables and cluster centroids as continuous variables will convey meaningful information.
Q13. What could be the possible reason(s) for producing two different dendrograms using an agglomerative clustering algorithm for the same dataset?
A. Proximity function used
B. of data points used
C. of variables used
D. B and C only
E. All of the above
Solution: (E)
A change in either the proximity function, the number of data points, or the number of variables will lead to different clustering results and, hence, different dendrograms.
Q14. In the figure below, if you draw a horizontal line on the y-axis for y=2. What will be the number of clusters formed?

Options:
A. 1
B. 2
C. 3
D. 4
Solution: (B)
Since the number of vertical lines intersecting the red horizontal line at y=2 in the dendrogram is 2, two clusters will be formed.
Q15. What is the most appropriate no. of clusters for the data points represented by the following dendrogram?

Options:
A. 2
B. 4
C. 6
D. 8
Solution: (B)
The number of clusters that can best depict different groups can be chosen by observing the dendrogram. The best choice of clusters is the no. of vertical lines in the dendrogram cut by a horizontal line that can transverse the maximum distance vertically without intersecting a cluster.

In the above example, the best choice of no. of clusters will be 4 as the red horizontal line in the dendrogram below covers the maximum vertical distance AB.
Q16. In which of the following cases will K-Means clustering fail to give good results?
- Data points with outliers
- Data points with different densities
- Data points with round shapes
- Data points with non-convex shapes
Options:
A. 1 and 2
B. 2 and 3
C. 2 and 4
D. 1, 2 and 4
E. 1, 2, 3 and 4
Solution: (D)
The K-Means clustering algorithm fails to give good results when the data contains outliers, the density spread of data points across the data space differs, and the data points follow non-convex shapes.

Q17. Which metrics do we have for finding dissimilarity between two clusters in hierarchical clustering?
- Single-link
- Complete-link
- Average-link
Options:
A. 1 and 2
B. 1 and 3
C. 2 and 3
D. 1, 2 and 3
Solution: (D)
In the above clustering questions, all three methods, i.e., single link, complete link, and average link, can be used for finding dissimilarity between two clusters in hierarchical clustering( can be found in the Python library scikit-learn).
Q18. Which of the following is/are true?
- Clustering analysis is negatively affected by the multicollinearity of features
- Clustering analysis is negatively affected by heteroscedasticity
Options:
A. 1 only
B. 2 only
C. 1 and 2
D. None of them
Solution: (A)
In the above clustering questions, clustering analysis is not negatively affected by heteroscedasticity. Still, the results are negatively impacted by the multicollinearity of features/ variables used in clustering as the correlated feature/ variable will carry extra weight on the distance calculation than desired.
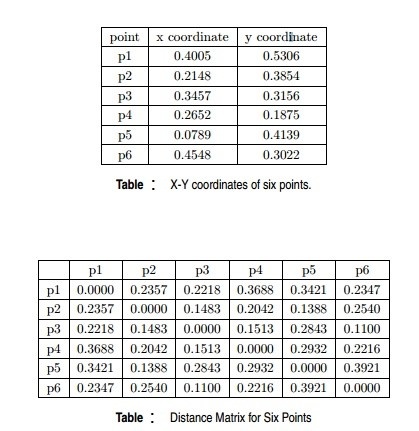
Context for Question 19: Given are six points with the following attributes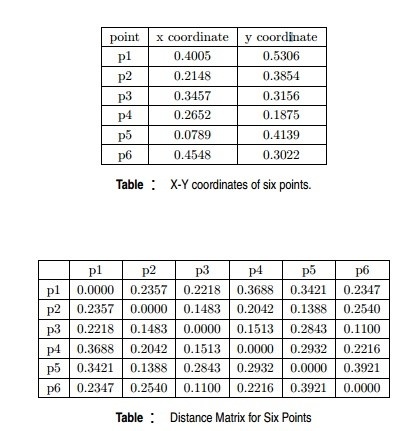
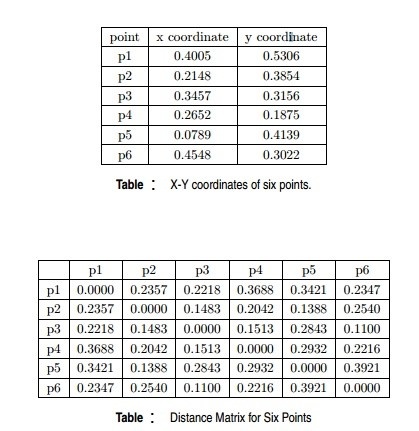
Q19. Which of the following clustering representations and dendrogram depicts the use of MIN or single link proximity function in hierarchical clustering?
A. 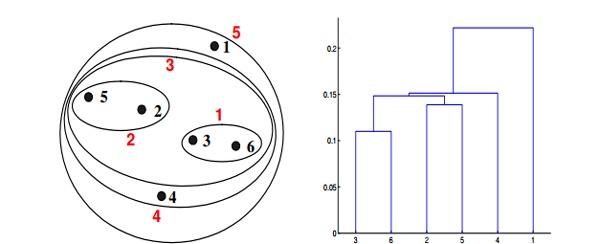
B. 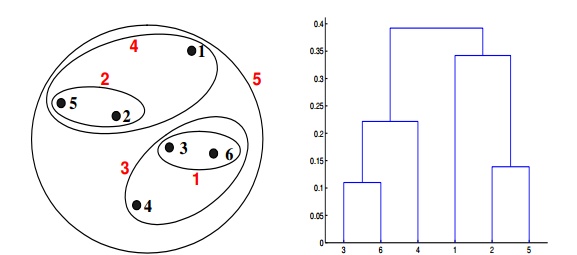
C. 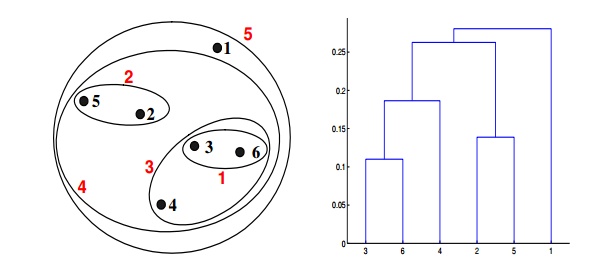
D. 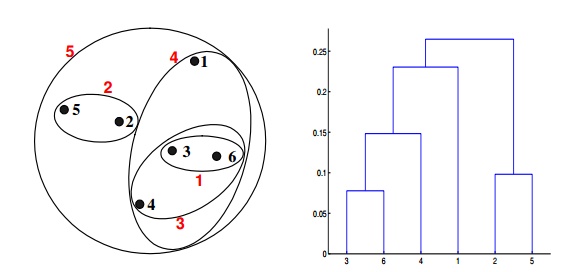
Solution: (A)
For the single link or MIN version of hierarchical clustering, the proximity of two clusters is the minimum distance between any two points in the different clusters. For instance, from the table, we see that the distance between points 3 and 6 is 0.11, the height at which they are joined into one cluster in the dendrogram. As another example, the distance between clusters {3, 6} and {2, 5} is given by dist({3, 6}, {2, 5}) = min(dist(3, 2), dist(6, 2), dist(3, 5), dist(6, 5)) = min(0.1483, 0.2540, 0.2843, 0.3921) = 0.1483.
Context for Question 20: Given are six points with the following attributes

Q20. Which of the following clustering representations and dendrogram depicts the use of MAX or complete link proximity function in hierarchical clustering?
A. 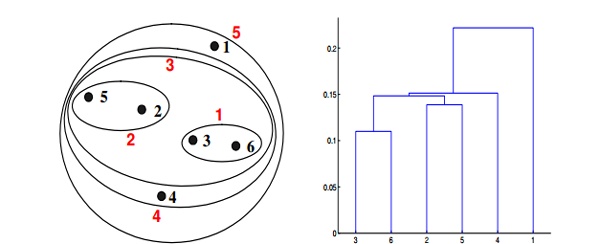
B. 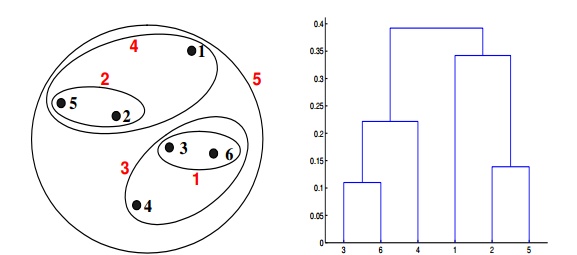
C. 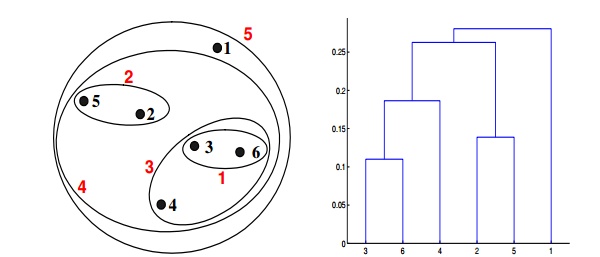
D. 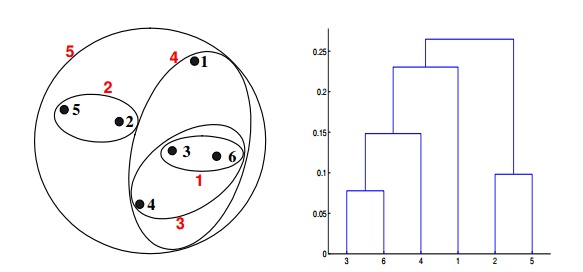
Solution: (B)
In the above clustering questions, for the single link or MAX version of hierarchical clustering, the proximity of two clusters is defined as the maximum distance between any two points in the different clusters. Similarly, here points 3 and 6 are merged first. However, {3, 6} is merged with {4}, instead of {2, 5}. This is because the dist({3, 6}, {4}) = max(dist(3, 4), dist(6, 4)) = max(0.1513, 0.2216) = 0.2216, which is smaller than dist({3, 6}, {2, 5}) = max(dist(3, 2), dist(6, 2), dist(3, 5), dist(6, 5)) = max(0.1483, 0.2540, 0.2843, 0.3921) = 0.3921 and dist({3, 6}, {1}) = max(dist(3, 1), dist(6, 1)) = max(0.2218, 0.2347) = 0.2347.
Context for Question 21: Given are six points with the following attributes
Q21. Which of the following clustering representations and dendrogram depicts the use of the group average proximity function in hierarchical clustering?
A. 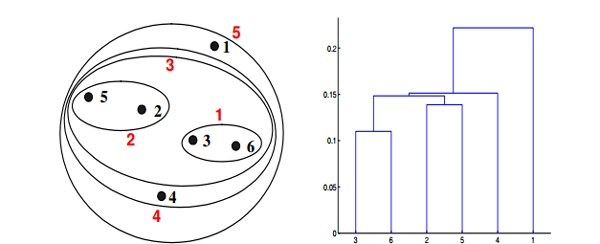
B. 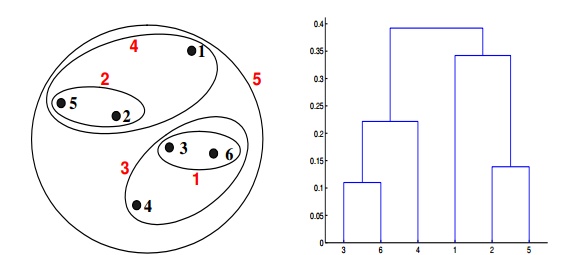
C. 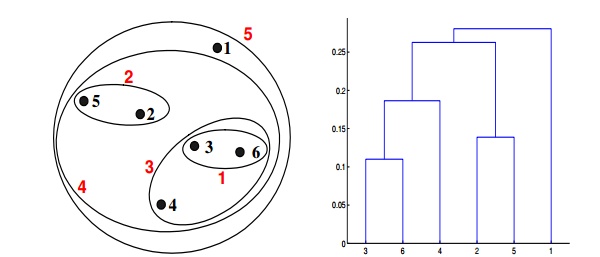
D. 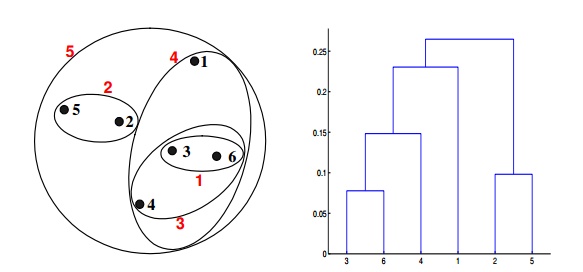
Solution: (C)
For the group average version of hierarchical clustering, the proximity of two clusters is the average of the pairwise proximities between all pairs of points in the different clusters. This is an intermediate approach between MIN and MAX. The following equation expresses this:

Here, the distance between some clusters. dist({3, 6, 4}, {1}) = (0.2218 + 0.3688 + 0.2347)/(3 ∗ 1) = 0.2751. dist({2, 5}, {1}) = (0.2357 + 0.3421)/(2 ∗ 1) = 0.2889. dist({3, 6, 4}, {2, 5}) = (0.1483 + 0.2843 + 0.2540 + 0.3921 + 0.2042 + 0.2932)/(6∗1) = 0.2637. Because dist({3, 6, 4}, {2, 5}) is smaller than dist({3, 6, 4}, {1}) and dist({2, 5}, {1}), these two clusters are merged at the fourth stage.
Context for Question 22: Given are six points with the following attributes
Q22. Which of the following clustering representations and dendrogram depicts the use of Ward’s method proximity function in hierarchical clustering?
A. 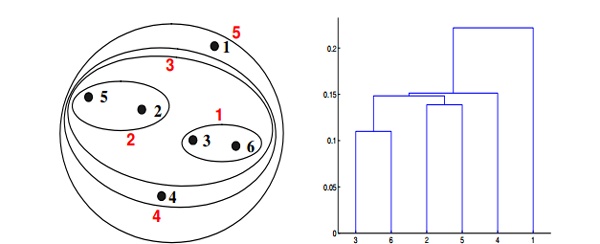
B. 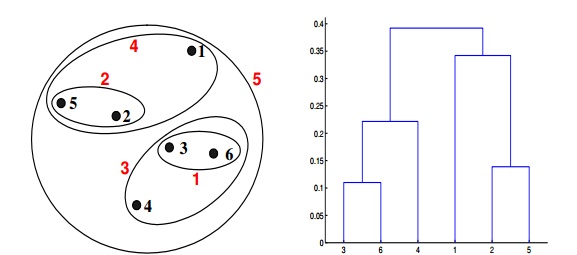
C. 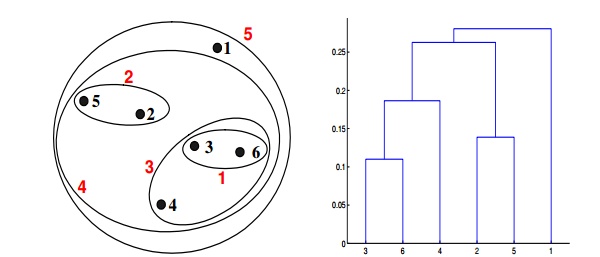
D. 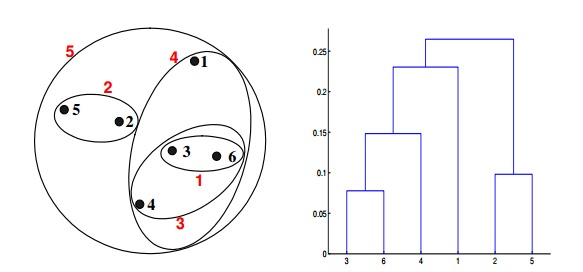
Solution: (D)
Ward method is a centroid method. The centroid method calculates the proximity between two clusters by calculating the distance between the centroids of clusters. For Ward’s method, the proximity between two clusters is defined as the increase in the squared error that results when two clusters are merged. The results of applying Ward’s method to the sample data set of six points. The resulting clustering is somewhat different from those produced by MIN, MAX, and group average.
Q23. What should be the best choice of no. of clusters based on the following results?

Options:
A. 1
B. 2
C. 3
D. 4
Solution: (C)
The silhouette coefficient measures how similar an object is to its own cluster compared to other clusters. The number of clusters for which the silhouette coefficient is highest represents the best choice of clusters.
Q24. Which of the following is/are valid iterative strategies for treating missing values before clustering analysis?
Options:
A. Imputation with mean
B. Nearest Neighbor assignment
C. Imputation with Expectation Maximization algorithm
D. All of the above
Solution: (D)
D. All of the above is correct because all three methods—mean imputation, nearest neighbor assignment, and Expectation Maximization (EM) algorithm—are valid iterative strategies for handling missing values. Mean imputation fills gaps with averages, nearest neighbor uses similar data points, and EM iteratively estimates missing values, making all suitable for preprocessing before clustering.
Q25. The K-Means algorithm has some limitations. For example, it makes hard assignments (A point either completely belongs to a cluster or not belongs at all) of points to clusters.
Note: Soft assignment can be considered as the probability of being assigned to each cluster: say K = 3 and for some point xn, p1 = 0.7, p2 = 0.2, p3 = 0.1)
Which of the following algorithm(s) allows soft assignments?
- Gaussian mixture models
- Fuzzy K-means
Options:
A. 1 only
B. 2 only
C. 1 and 2
D. None of these
Solution: (C)
Both, Gaussian mixture models and Fuzzy K-means allow soft assignments.
Q26. Assume you want to cluster 7 observations into 3 clusters using the K-Means clustering algorithm. After the first iteration, clusters C1, C2, C3 have following observations:
C1: {(2,2), (4,4), (6,6)}
C2: {(0,4), (4,0)}
C3: {(5,5), (9,9)}
What will be the cluster centroids if you want to proceed with the second iteration?
Options:
A. C1: (4,4), C2: (2,2), C3: (7,7)
B. C1: (6,6), C2: (4,4), C3: (9,9)
C. C1: (2,2), C2: (0,0), C3: (5,5)
D. None of these
Solution: (A)
Finding centroid for data points in cluster C1 = ((2+4+6)/3, (2+4+6)/3) = (4, 4)
Identifying centroid for data points in cluster C2 = ((0+4)/2, (4+0)/2) = (2, 2)
Finding centroid for data points in cluster C3 = ((5+9)/2, (5+9)/2) = (7, 7)
Hence, C1: (4,4), C2: (2,2), C3: (7,7)
Q27. Assume you want to cluster 7 observations into 3 clusters using the K-Means clustering algorithm. After first iteration, clusters C1, C2, C3 have following observations:
C1: {(2,2), (4,4), (6,6)}
C2: {(0,4), (4,0)}
C3: {(5,5), (9,9)}
What will be the Manhattan distance for observation (9, 9) from cluster centroid C1 in the second iteration?
Options:
A. 10
B. 5*sqrt(2)
C. 13*sqrt(2)
D. None of these
Solution: (A)
Manhattan distance between centroid C1, i.e., (4, 4) and (9, 9) = (9-4) + (9-4) = 10
Q28. If two variables, V1 and V2, are used for clustering. Which of the following are true for K means clustering with k =3?
- If V1 and V2 have a correlation of 1, the cluster centroids will be in a straight line
- If V1 and V2 have a correlation of 0, the cluster centroids will be in a straight line
Options:
A. 1 only
B. 2 only
C. 1 and 2
D. None of the above
Solution: (A)
If the correlation between the variables V1 and V2 is 1, then all the data points will be in a straight line. Hence, all three cluster centroids will form a straight line as well.
Q29. Feature scaling is an important step before applying the K-Mean algorithm. What is the reason behind this?
Options:
A. In distance calculation, it will give the same weights for all features
B. You always get the same clusters. If you use or don’t use feature scaling
C. In Manhattan distance, it is an important step, but in Euclidean distance, it is not
D. None of these
Solution: (A)
In the above clustering questions, feature scaling ensures that all the features get the same weight in the clustering analysis. Consider a scenario of clustering people based on their weights (in KG), which range from 55 to 110, and height (in inches), which ranges from 5.6 to 6.4. In this case, the clusters produced without scaling can be very misleading, as the weight range is much higher than that of height. Therefore, bringing them to the same scale is necessary to have equal weightage on the clustering result.
Q30. Which of the following methods is used for finding the optimal of a cluster in the K-Mean algorithm?
Options:
A. Elbow method
B. Manhattan method
C. Ecludian method
D. All of the above
E. None of these
Solution: (A)
Out of the given options, only the elbow method is used to find the optimal number of clusters. The elbow method looks at the percentage of variance explained as a function of the number of clusters: One should choose several clusters so that adding another cluster doesn’t give much better modelling of the data.
Q31. What is true about K-Mean Clustering?
- K-means is extremely sensitive to cluster center initializations
- Bad initialization can lead to Poor convergence speed
- Bad initialization can lead to bad overall clustering
Options:
A. 1 and 3
B. 1 and 2
C. 2 and 3
D. 1, 2 and 3
Solution: (D)
All three of the given statements are true. K-means is extremely sensitive to cluster center initialization. Also, bad initialization can lead to Poor convergence speed as well as bad overall clustering.
Q32. Which of the following can be applied to get good results for the K-means algorithm corresponding to global minima?
- Try to run the algorithm for different centroid initialization
- Adjust the number of iterations
- Find out the optimal number of clusters
Options:
A. 2 and 3
B. 1 and 3
C. 1 and 2
D. All of above
Solution: (D)
All of these are standard practices that are used in order to obtain good clustering results.
Q33. What should be the best choice for the number of clusters based on the following results?

Options:
A. 5
B. 6
C. 14
D. Greater than 14
Solution: (B)
In the above clustering questions, based on the above results, 6 is the best number of clusters to use the elbow method.
Q34. Based on the following results, what should be the best choice for the number of clusters?

Options:
A. 2
B. 4
C. 6
D. 8
Solution: (C)
Generally, a higher average silhouette coefficient indicates better clustering quality. In this plot, the optimal clustering number of grid cells in the study area should be 2, at which the value of the average silhouette coefficient is the highest. However, the SSE of this clustering solution (k = 2) is too large. At k = 6, the SSE is much lower. In addition, the value of the average silhouette coefficient at k = 6 is also very high, which is just lower than k = 2. Thus, the best choice is k = 6.
Q35. Which of the following sequences is correct for a K-Means algorithm using the Forgy method of initialization?
- Specify the number of clusters
- Assign cluster centroids randomly
- Assign each data point to the nearest cluster centroid
- Re-assign each point to the nearest cluster centroid
- Re-compute cluster centroids
Options:
A. 1, 2, 3, 5, 4
B. 1, 3, 2, 4, 5
C. 2, 1, 3, 4, 5
D. None of these
Solution: (A)
The methods used for initialization in K means are Forgy and Random Partition. The Forgy method randomly chooses k observations from the data set and uses these as the initial means. The Random Partition method randomly assigns a cluster to each observation. Then it proceeds to the update step, thus computing the initial mean as the centroid of the cluster’s randomly assigned points.
Q36. If you use Multinomial mixture models with the expectation-maximization algorithm for clustering data points into two clusters, which of the assumptions are important?
Options:
A. All the data points follow two Gaussian distribution
B. All the data points follow n Gaussian distribution (n >2)
C. All the data points follow two multinomial distribution
D. All the data points follow n multinomial distribution (n >2)
Solution: (C)
In the EM algorithm for clustering, it’s essential to choose the same number of clusters to classify the data points into the number of different distributions they are expected to be generated from, and the distributions must be of the same type.
Q37. Which of the following is/are not true about the centroid-based K-means clustering algorithm and Distribution-based expectation-maximization clustering algorithm?
- Both start with random initializations
- Both are iterative algorithms
- Both have strong assumptions that the data points must fulfil
- Both are sensitive to outliers
- The expectation-maximization algorithm is a special case of K-Means
- Both require prior knowledge of the no. of desired clusters
- The results produced by both are non-reproducible
Options:
A. 1 only
B. 5 only
C. 1 and 3
D. 6 and 7
E. 4, 6 and 7
F. None of the above
Solution: (B)
In the above to this clustering question, all of the above statements are true except the 5th as K-Means is a special case of EM algorithm in which only the centroids of the cluster distributions are calculated at each iteration.
Q38. Which of the following is/are not true about the DBSCAN clustering algorithm?
- For data points to be in a cluster, they must be in a distance threshold to a core point
- It has strong assumptions for the distribution of data points in the dataspace
- It has a substantially high time complexity of order O(n3)
- It does not require prior knowledge of the no. of desired clusters
- It is robust to outliers
Options:
A. 1 only
B. 2 only
C. 4 only
D. 2 and 3
E. 1 and 5
F. 1, 3 and 5
Solution: (D)
DBSCAN can form a cluster of any arbitrary shape and does not have strong assumptions for the distribution of data points in the data space. DBSCAN has a low time complexity of order O(n log n) only.
Q39. Which of the following are the high and low bounds for F-Score?
Options:
A. [0,1]
B. (0,1)
C. [-1,1]
D. None of the above
Solution: (A)
In the above clustering questions, the lowest and highest possible values of the F score are 0 and 1, where 1 means that every data point is assigned to the correct cluster, and 0 means that the clustering analysis’s precession and/or recall are both 0. In clustering analysis, a high value of F score is desired.
Q40. Following are the results observed for clustering 6000 data points into 3 clusters: A, B, and C:

Options:
A. 3
B. 4
C. 5
D. 6
Solution: (D)
Here,
True Positive, TP = 1200
True Negative, TN = 600 + 1600 = 2200
False Positive, FP = 1000 + 200 = 1200
False Negative, FN = 400 + 400 = 800
Therefore,
Precision = TP / (TP + FP) = 0.5
Recall = TP / (TP + FN) = 0.6
Hence,
F1 = 2 (Precision Recall)/ (Precision + recall) = 0.54 ~ 0.5
Helpful Resources
Many people wish to be data scientists and data analysts these days and wonder if they can achieve it without a background in computer science. Be rest assured that is possible! Plenty of resources, courses, and tutorials are available online that cover various data science topics, such as data analysis, data mining, big data, data analytics, data modelling, data visualization, and more. Here are some of our best recommended online resources on clustering techniques.
- An Introduction to Clustering and different methods of clustering
- Getting your clustering right (Part I)
- Getting your clustering right (Part II)
If you are just getting started with Unsupervised Learning, here are some comprehensive resources to assist you in your journey:
- Machine Learning Certification Course for Beginners
- The Most Comprehensive Guide to K-Means Clustering You’ll Ever Need
- Certified AI & ML Blackbelt+ Program
Here are a few blogs that will help you crack your interview:
- Top 10 Telephonic Interview Tips
- How to Introduce Yourself in a Job Interview?
- How to Build a Portfolio for an AI Career
- How to Make an Impressive Data Science Portfolio
- Data Scientist Resume: Best Practices and Tips
- 60+ Generative AI Terms You Must Know By Heart
- 5 Strategies for Acing Your AI Technical Interview
Conclusion
Clustering is a powerful tool in unsupervised learning, enabling us to uncover hidden patterns and insights from unlabeled data. By mastering clustering techniques and understanding their practical applications, you can tackle real-world challenges effectively. All the best for your interview—may your knowledge and preparation lead you to success!
Saurav is a Data Science enthusiast, currently in the final year of his graduation at MAIT, New Delhi. He loves to use machine learning and analytics to solve complex data problems.






I am confused with question 40. It says the correct answer in D(6) and solution shows C(5). Anyway, rounding of 5.4 to 5 is not very clean.
Hi Eudie, Well, 5.4 is rounded off to 5 not 6 and 5.5 is rounded off to 6 not 5. This is standard convention. I'll make sure to explicitly mention it next time to avoid any confusion that you might have had. Best, Saurav.
Thanks for the test. Appreciate it. One feedback : Please classify what is good /bad score according to difficulty level of test.
Hi Arihant, Well, the average score is 15. You can simply use the score statistics to find your percentile and know where you stand compared to all. Personally speaking, 12 or more is a decent enough score. Best, Saurav.
This blog giving the details of technology. This gives the details about working with the business processes and change the way. Here explains think different and work different then provide the better output. Thanks for this blog.
Hi Lithika, Thank you for your kind words. We at Analytics Vidhya really appreciate your gratitude. Best, Saurav.