Welcome to “A Guide to Monte Carlo Simulation!” Monte Carlo simulation is a fascinating and practical method for understanding complex systems influenced by randomness and uncertainty. This powerful tool uses random sampling to estimate potential outcomes, allowing us to make informed predictions and decisions across various fields—from finance and engineering to science and gaming. In this guide, we’ll break down the history, key concepts, and steps involved in performing Monte Carlo simulations, especially focusing on implementation in Python. By the end, you’ll have a solid grasp of using this technique to analyze various scenarios, tackle uncertainty, and gain valuable insights into your projects. Let’s start on this journey into the world of Monte Carlo simulation!
Overview:
- Learn about the history of Monte Carlo Simulation, pioneered by John Neumann and Stanislaw Ulam, and how it applies to analyzing uncertainty in complex systems.
- Gain an understanding of core concepts, including probability density functions, confidence levels, and confidence intervals, essential for interpreting Monte Carlo Simulation results.
- Discover how to perform Monte Carlo simulations in Python, using tools like NumPy and Python’s random library, to model and analyze random processes.
- Explore practical examples, such as simulating a roulette game, to see Monte Carlo Simulation in action and observe the Law of Large Numbers and Regression to the Mean.
- Analyze the steps involved, from defining the problem and generating random inputs to running simulations and interpreting results to make informed decisions.
- Understand both the advantages and limitations of Monte Carlo Simulation, particularly its ability to approximate solutions for complex scenarios and the computational demands it can entail.
This article was published as a part of the Data Science Blogathon
Table of contents
- A Brief History
- What is Monte Carlo Simulation in Python?
- Steps in Performing a Stimulation
- Stimulating a Roulette Game
- Law of Large Numbers
- Regression to Mean
- Sampling Space of Possible Outcomes
- Confidence levels and Confidence Intervals
- Probability Density Function (PDF)
- Advantages of Monte Carlo Simulation
- Disadvantages of Monte Carlo Simulation
- Conclusion
- Frequently Asked Questions
A Brief History
John Neumann and Ulam Stanislaw invented the Monte Carlo Method to improve decision-making under uncertain conditions. It was named after a well-known casino town, Monte Carlo, Monaco since the element of chance is core to the modelling approach, similar to a roulette game.
In easy words, Monte Carlo Simulation is a method of estimating the value of an unknown quantity with the help of inferential statistics. You need not dive deep into inferential statistics to have a strong grasp of how the Monte Carlo simulation works. However, this article will go only through those points of inferential statistics relevant to us in the Monte Carlo Simulation.
Inferential Statistics deals with the population, our set of examples, and the sample, a proper subset of the population. The key point is that a random sample tends to exhibit the same characteristics /properties as the population from which it is drawn.
What is Monte Carlo Simulation in Python?
Monte Carlo simulation is a computational technique that uses random sampling to model and analyze complex systems or processes. It is named after Monaco’s famous Monte Carlo casino, as the simulation relies on generating random numbers.
In Python, Monte Carlo simulation can be implemented using libraries such as NumPy and random.
Steps in Performing a Stimulation
The basic steps involved in performing a Monte Carlo simulation are as follows:
- Define the problem: Clearly state the problem you want to model or analyze using Monte Carlo simulation. This could involve anything from estimating probabilities to evaluating financial risks.
- Set up the model: Create a mathematical or computational model representing the system or process under consideration. This model should include all relevant variables, inputs, and assumptions.
- Generate random inputs: Identify the input variables in your model that exhibit uncertainty or randomness. Randomly sample values for these variables according to their probability distributions. This is often done using Python’s random or NumPy’s random functions.
- Run simulations: Execute the model multiple times using the randomly generated inputs. Each run of the model is called an iteration. Record the output or results of interest for each iteration.
- Analyze the results: With the recorded outputs from the simulations, analyze and summarize the data. This may involve calculating summary statistics, estimating probabilities, or constructing confidence intervals.
- Draw conclusions: Based on the analysis of the simulation results, conclude the behaviour, performance, or characteristics of the system or process being modelled. These conclusions can help make informed decisions or gain insights into the problem.
Monte Carlo simulation is a powerful tool for handling complex problems where analytical or deterministic solutions are difficult or impossible. It allows for exploring a wide range of scenarios and provides a probabilistic understanding of the system under study. Python provides a convenient environment for implementing Monte Carlo simulations due to its versatility and the availability of libraries that facilitate random number generation and numerical computations.
Example
We will go through an example to understand the workings of the Monte Carlo simulation.
We aim to estimate how likely it is to get ahead if we flip a coin an infinite number of times.
- Let’s say we flip it once and get ahead. Can we confidently say that our answer is 1?
- Now we flipped the coin again, and it appeared again head-high. Are we sure that the next flip will also be ahead?
- We flipped it repeatedly, let’s say 100 times, and strangely, a head appeared every time. Do we need to accept that the next flip will result in another head?
- Let us just change the scenario and assume that out of 100 flips, 52 resulted in the head, and 48 came to be tails. Is the probability of the next flip resulting in the head 52/100? Given the observation, it’s our best estimate, but the confidence will still be low.
Why is there a Difference in Confidence Level?
It is important to know that our estimate depends upon two things
- Size: the size of the sample (e.g., 100 vs 2 in cases 2 and 4, respectively)
- Variance: variance of the sample (all the results as head versus 52 heads as in cases 3 and 4 respectively)
- As the Variance of the observation grows (case 3 and 4), there comes a need for larger observation (as in cases 2 and 4) to have the same degree of confidence.
Stimulating a Roulette Game
We will now be simulating a Roulette game (python):
Roulette is a game in which a disk with blocks (half red and half black) in which a ball can be contained is spun with a ball. We need to guess a number, and if the ball lands up in this number, then it’s a win, and we win an amount of (paid amount for one slot
) X (no. of total slots in the machine).
import random
class Roulette():
def __init__(self):
self.pockets = []
for i in range(1,37):
self.pockets.append(i)
self.ball = None
self.pocketOdds = len(self.pockets) - 1
def spin(self):
self.ball = random.choice(self.pockets)
def betPocket(self, pocket, amt):
if str(pocket) == str(self.ball):
return amt*self.pocketOdds
else: return -amt
def __str__(self):
return 'Fair Roulette'
def playRoulette(game, numSpins, pocket, bet):
totPocket = 0
for i in range(numSpins):
game.spin()
totPocket += game.betPocket(pocket, bet)
if totPocket:
print (numSpins, 'spins of', game)
print ('Expected return betting', pocket, '=',
str(100*totPocket/numSpins) + '%n')
return (totPocket/numSpins)
game = Roulette()
for numSpins in (100, 1000000):
for i in range(3):
playRoulette(game, numSpins, 5, 1)100 spins of Roulette
Expected return betting 5 = -100.0%
100 spins of Roulette
Expected return betting 5 = 42.0%
100 spins of Roulette
Expected return betting 5 = -26.0%
1000000 spins of Roulette
Expected return betting 5 = -0.0546%
1000000 spins of Roulette
Expected return betting 5 = 0.502%
1000000 spins of Roulette
Expected return betting 5 = 0.7764%
Law of Large Numbers
.jfif)
In repeated independent tests with the constant probability p of the population of a particular outcome in each test, the probability that the outcome occurs, i.e. obtained from the samples, differs from p and converges to zero as the number of trials goes to infinity.
This simply means that if deviations (Variance) occur from the expected behaviour (probability p), the opposite deviation will likely even them out.
Now let’s talk about an interesting incident on 18 August 1913, at a casino in Monte Carlo. In roulette, black came up a record twenty-six times in succession, and there arose a panic to bet red (so as to even out the deviation from expected behaviour)
Let’s analyze this situation mathematically
- Probability of 26 consecutive reds = 1/67,108,865
- Probability of 26 consecutive reds when previous 25 rolls were red =1/2
Regression to Mean
1. Following an extreme random event, the next random event is likely to be less extreme so that the mean is maintained.
2. E.g. if the roulette wheel is spun 10 times and reds come every time, then it is an extreme event =1/1024, and it is likely that in the next 10 spins, we will get less than 10 reds, But the average number is 5 only.
So, the mean of 20 spins will be closer to the expected mean of 50% reds than to the 100% as of the first 10 spins.
Now, it is time to face some reality.
Sampling Space of Possible Outcomes
1. It is not possible to guarantee perfect accuracy through sampling, and also cannot say that an estimate is not precisely correct
We face the question here: How many samples are required to examine before we can have significant confidence in our answer?
It depends upon the variability in underlying distribution.
Confidence levels and Confidence Intervals
.jfif)
In a real-life situation, we cannot be sure of any unknown parameter obtained from a sample for the whole population, so we use confidence levels and confidence intervals.
The confidence interval provides a range within which the unknown value is likely to be contained, with the confidence that it lies strictly within that range.
For example, the return for betting on a slot 1000 times in roulette is -3%, with a margin error of +/—4% and a 95% confidence level.
It can be further decoded as we conduct an infinite trial of 1000,
The expected average/mean return would be -3%
The return would roughly vary between +1% and -7% that also 95% of the time.
Probability Density Function (PDF)
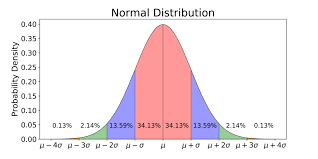
The distribution is usually defined by the probability density function (PDF). It is the probability that the random variable lies between an interval.
The area under the curve between the two points of PDF is the probability of the random variable falling within that range.
Example
Let’s conclude our learning with an example
Let’s say there is a deck of shuffled cards, and we need to find the probability of getting 2 consecutive kings if the cards are laid down in the order they are placed.
Analytical method:
P (at least 2 consecutive kings) = 1-P (no consecutive kings)
=1-(49! X 48!)/((49-4)! X52!) = 0.217376
By Monte Carlo Simulation:
Steps
1. Repeatedly select the random data points: Here we assume the shuffling of the cards is random
2. Performing deterministic computation. A number of such shuffling and finding the results.
3. Combine the results: Exploring the result and ending with our conclusion.
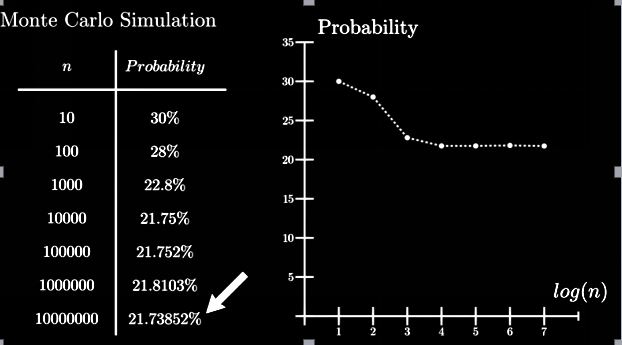
By using the Monte Carlo method, we achieve a nearly exact solution as with the analytical method.
Advantages of Monte Carlo Simulation
- Easy to implement and it gives statistical sampling for numerical experiments using the computer.
- Provides us with satisfactory approximate solutions to computationally expensive mathematical problems.
- It can be used for deterministic as well as stochastic problems.
Disadvantages of Monte Carlo Simulation
- It can sometimes be time-consuming, as we have to generate a large number of samples to get the desired satisfactory output.
- The results obtained from this method are only the approximation of the true solution and not the exact solution.
Conclusion
In conclusion, the Monte Carlo simulation serves as a robust and versatile tool for tackling complex systems and making predictions when deterministic solutions are challenging or unattainable. Leveraging random sampling and statistical analysis enables us to model uncertainty and gain insights into the likelihood of various outcomes, whether in finance, engineering, or scientific research. From estimating probabilities to optimizing decisions, Monte Carlo simulation’s applications are vast and impactful. While it has limitations, particularly in computational intensity, its ability to approximate solutions reasonably accurately makes it invaluable in fields where precision and predictive insights are crucial. As we’ve seen through examples and practical implementation, the Monte Carlo method empowers data scientists and decision-makers to navigate uncertainties more confidently.
Frequently Asked Questions
Q1. What is Monte Carlo simulation used for?
A. Monte Carlo simulation models and analyses complex systems or processes through random sampling. It helps estimate probabilities, evaluate risks, optimize decisions, simulate financial scenarios, analyze performance, and understand behaviour in finance, engineering, physics, and computer science.
Q2. Can we do Monte Carlo simulation in Excel?
A. Yes, Monte Carlo simulation can be performed in Microsoft Excel, although it may require some programming and formula implementation. Excel provides a range of functions and tools that can be leveraged for Monte Carlo simulation. Here’s a general approach to implementing it in Excel:
1. Define the problem and set up the model in Excel, including input variables, parameters, and assumptions.
2. Use Excel’s random number functions (such as RAND or RANDBETWEEN) to generate random values for the uncertain variables based on their probability distributions.
3. Implement the model calculations and formulas based on the inputs and desired outcomes.
4. Create a loop or a series of iterations in Excel using functions like IF, WHILE, or iterative calculations to simulate a specific number of iterations.
5. Record the results of each iteration in Excel’s cells or tables.
6. Analyze and summarize the simulation results using Excel’s statistical functions, charts, and visualizations.
While Excel can handle simple Monte Carlo simulations, more complex simulations may require additional programming or the use of specialized software.
Q3. Can you implement Monte Carlo simulation algorithms in Python?
This Python code estimates the value of pi using the Monte Carlo method. It randomly generates points inside a square, counts the points that fall inside the inscribed circle, and uses this ratio to estimate pi.
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.






