This article was published as a part of the Data Science Blogathon
Overview
Text analysis is one of the most interesting advancements in the domain of Natural Language Processing (NLP). Text analysis is used in virtual assistants like Alexa, Google Home, and others. It is also very helpful in chatbot-based systems where user queries are served. Naturally, as the first step of the analysis, the pre-processing or the data cleaning is important.
It is so critical process to perform that according to a recent survey[1], data scientists spend almost 60% of their time cleaning the data! Apart from the popular English Text analysis, much recently there has been more development in Hindi text analytics as well due to the increased need and interests of NLP enthusiasts around the world. In this article, I will walk you through the step-by-step process of cleaning Hindi text with code demonstrations. For your reference, I have also added code outputs that you can expect as well. We will perform the below cleaning:
- Drop unnecessary attributes or dataset columns
- Remove all emojis from text
- Generate Tokens from text
- Remove ‘\n’ from each token
- Remove Hindi and English Stopwords from the text
- Remove punctuations
- Remove most and least occurring tokens from the text
Once the above-mentioned steps are performed, we will also plot the distribution histogram for each label. At the end of the article, we will plot the word cloud to understand the majority of topics mentioned in the text corpus. So without further delay, let’s start cleaning up!

Dataset for Hindi Text Analysis
In this article, we are going to use a large dataset of Hindi tweets from Kaggle. The dataset has over 16000 tweets (including both sarcastic and non-sarcastic) in Hindi. Please note that we will not classify the tweets as sarcastic or non-sarcastic. We will simply use the tweet text to understand how Hindi text processing is performed. With the help of a word cloud for Hindi text, we will also understand what are the majority of the topics people have been tweeting about the most.
For each dataset the size is as below:
- Number of Sarcastic tweets: 6051
- Number of Non-Sarcastic Tweets: 10128
Let’s begin!
1. Load the libraries
import pandas as pd
import numpy as np
pd.set_option('display.max_colwidth',None) #this displays the dataframe in full width
import collections
from collections import Counter
2. Load the dataset:
df_sarcastic = pd.read_csv('Sarcasm_Hindi_Tweets-SARCASTIC.csv')
df_non_sarcastic = pd.read_csv('Sarcasm_Hindi_Tweets-NON-SARCASTIC.csv')
df_sarcastic['label'] = 'sarcastic'
df_non_sarcastic['label'] = 'non_sarcastic'
df = pd.concat([df_sarcastic, df_non_sarcastic], axis=0)
df = df.drop(['username','acctdesc','location','following','followers', 'totaltweets', 'usercreatedts', 'tweetcreatedts', 'retweetcount', 'hashtags'] ,axis=1)
df = df.reset_index()
df = df.drop('index',axis=1)
After loading both datasets, I have added a new column called ‘label‘. All the tweets in df_sarcastic are labeled as ‘sarcastic‘ and those in df_non_sarcastic are labeled as ‘non_sarcastic‘ respectively. Thereafter, the two dataframes are combined to form a single dataframe and few unnecessary columns are dropped as shown above
3. Since throughout the analysis, we are going to remove unnecessary words or tokens, let us create a function called count_length() which will count the number of words in the text.
def count_length():
df['word_count'] = df['text'].apply(lambda x: len(str(x).split(" ")))
4. Let us see our dataframe so far. But before that call the count_length() method first:
count_length() df.tail(10)
5. The output looks like this:

6. Take a moment to observe carefully the kind of data we have here. It is a mess! It contains emojis, unnecessary newline characters, punctuations, stopwords, and others which add no value to the analysis. Hence, in the upcoming sections, we will discuss these steps one by one. Also, keep observing how after each step the word count changes.
Remove All Emojis from Hindi Text Analysis Data
1. Removing emojis become very easy by using a regular expression for a range of emojis like the one shown below:
import re
emoji_pattern = re.compile("["
u"U0001F600-U0001F64F" # emoticons
u"U0001F300-U0001F5FF" # symbols & pictographs
u"U0001F680-U0001F6FF" # transport & map symbols
u"U0001F1E0-U0001F1FF" # flags (iOS)
u"U00002500-U00002BEF" # chinese char
u"U00002702-U000027B0"
u"U00002702-U000027B0"
u"U000024C2-U0001F251"
u"U0001f926-U0001f937"
u"U00010000-U0010ffff"
u"u2640-u2642"
u"u2600-u2B55"
u"u200d"
u"u23cf"
u"u23e9"
u"u231a"
u"ufe0f" # dingbats
u"u3030"
"]+", flags=re.UNICODE)
2. Let’s remove those emojis from the text and see the word count:
for i in range(len(df)):
df['text'][i] = emoji_pattern.sub(r'', df['text'][i])
count_length()
3. If you run df.tail(10), the output would be like this:

4. And with that, all the emojis have been removed from your dataframe! Good job so far. You have successfully done some cleaning.
5. In a very similar manner, we can use a regular expression to remove other unnecessary kinds of stuff like the website URLs or email ids using the code below:
import re
def processText(text):
text = text.lower()
text = re.sub('((www.[^s]+)|(https?://[^s]+))','',text)
text = re.sub('@[^s]+','',text)
text = re.sub('[s]+', ' ', text)
text = re.sub(r'#([^s]+)', r'1', text)
text = re.sub(r'[.!:?-'"\/]', r'', text)
text = text.strip(''"')
return text
for i in range(len(df)):
df['text'][i] = processText(df['text'][i])
6. Bravo! Another accomplishment so far. But do not stop here. Let us now create tokens!
Generating Tokens for Hindi Text Analysis
Simply put, a token is a single piece of text and tokens are the building blocks of Natural Language processing. Thankfully we have NLP libraries that can gracefully take care of tokenizing the text within seconds and very little code!
1. For generating tokens, I am using indic nlp library and the code looks something like this:
from indicnlp.tokenize import indic_tokenize
def tokenization(indic_string):
tokens = []
for t in indic_tokenize.trivial_tokenize(indic_string):
tokens.append(t)
return tokens
df['text'] = df['text'].apply(lambda x: tokenization(x))
2. Let us take a text like:
| तुम बारिश और चाय तीनों से मेरी ज़िंदगी मुकम्मल हो जाये बजम सुप्रभात happy good morning |
After tokenization, the text is segregated into individual tokens like:
| [तुम, बारिश, और, चाय, तीनों, से, मेरी, ज़िंदगी, मुकम्मल, हो, जाये, बजम, सुप्रभात, happy, good, morning] |
This happens for the entire dataset
3. Voila fellas! You have just tokenized your entire dataset. Pro, tip: keep watch of word_count.
Remove ‘\n’ from each token
Upon a quick glance at the dataset, I observed that many tokens contains ‘\n’ in the beginning. For instance: ‘\nक्योंकि’ or ‘pandey1\n’. Here our goal is to get rid of this extra ‘\n’ using the following code:
for i in range(len(df)):
df['text'][i] = [s.replace("\n", "") for s in df['text'][i]]
Remove Stopwords and Punctuations
Since the text contains majorly Hindi words, removing Hindi stop words is inevitable. But if you see carefully, there are some English words used in the tweets too sometimes. Therefore, to be on the safer side, I am going to remove both Hindi and English stopwords. Also, punctuation marks add no value to text analysis. Hence, we are going to remove punctuations as well from our text using the code below:
stopwords_hi = ['तुम','मेरी','मुझे','क्योंकि','हम','प्रति','अबकी','आगे','माननीय','शहर','बताएं','कौनसी','क्लिक','किसकी','बड़े','मैं','and','रही','आज','लें','आपके','मिलकर','सब','मेरे','जी','श्री','वैसा','आपका','अंदर', 'अत', 'अपना', 'अपनी', 'अपने', 'अभी', 'आदि', 'आप', 'इत्यादि', 'इन', 'इनका', 'इन्हीं', 'इन्हें', 'इन्हों', 'इस', 'इसका', 'इसकी', 'इसके', 'इसमें', 'इसी', 'इसे', 'उन', 'उनका', 'उनकी', 'उनके', 'उनको', 'उन्हीं', 'उन्हें', 'उन्हों', 'उस', 'उसके', 'उसी', 'उसे', 'एक', 'एवं', 'एस', 'ऐसे', 'और', 'कई', 'कर','करता', 'करते', 'करना', 'करने', 'करें', 'कहते', 'कहा', 'का', 'काफ़ी', 'कि', 'कितना', 'किन्हें', 'किन्हों', 'किया', 'किर', 'किस', 'किसी', 'किसे', 'की', 'कुछ', 'कुल', 'के', 'को', 'कोई', 'कौन', 'कौनसा', 'गया', 'घर', 'जब', 'जहाँ', 'जा', 'जितना', 'जिन', 'जिन्हें', 'जिन्हों', 'जिस', 'जिसे', 'जीधर', 'जैसा', 'जैसे', 'जो', 'तक', 'तब', 'तरह', 'तिन', 'तिन्हें', 'तिन्हों', 'तिस', 'तिसे', 'तो', 'था', 'थी', 'थे', 'दबारा', 'दिया', 'दुसरा', 'दूसरे', 'दो', 'द्वारा', 'न', 'नहीं', 'ना', 'निहायत', 'नीचे', 'ने', 'पर', 'पर', 'पहले', 'पूरा', 'पे', 'फिर', 'बनी', 'बही', 'बहुत', 'बाद', 'बाला', 'बिलकुल', 'भी', 'भीतर', 'मगर', 'मानो', 'मे', 'में', 'यदि', 'यह', 'यहाँ', 'यही', 'या', 'यिह', 'ये', 'रखें', 'रहा', 'रहे', 'ऱ्वासा', 'लिए', 'लिये', 'लेकिन', 'व', 'वर्ग', 'वह', 'वह', 'वहाँ', 'वहीं', 'वाले', 'वुह', 'वे', 'वग़ैरह', 'संग', 'सकता', 'सकते', 'सबसे', 'सभी', 'साथ', 'साबुत', 'साभ', 'सारा', 'से', 'सो', 'ही', 'हुआ', 'हुई', 'हुए', 'है', 'हैं', 'हो', 'होता', 'होती', 'होते', 'होना', 'होने', 'अपनि', 'जेसे', 'होति', 'सभि', 'तिंहों', 'इंहों', 'दवारा', 'इसि', 'किंहें', 'थि', 'उंहों', 'ओर', 'जिंहें', 'वहिं', 'अभि', 'बनि', 'हि', 'उंहिं', 'उंहें', 'हें', 'वगेरह', 'एसे', 'रवासा', 'कोन', 'निचे', 'काफि', 'उसि', 'पुरा', 'भितर', 'हे', 'बहि', 'वहां', 'कोइ', 'यहां', 'जिंहों', 'तिंहें', 'किसि', 'कइ', 'यहि', 'इंहिं', 'जिधर', 'इंहें', 'अदि', 'इतयादि', 'हुइ', 'कोनसा', 'इसकि', 'दुसरे', 'जहां', 'अप', 'किंहों', 'उनकि', 'भि', 'वरग', 'हुअ', 'जेसा', 'नहिं']
stopwords_en = ['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've", "you'll", "you'd", 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', "she's", 'her', 'hers', 'herself', 'it', "it's", 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', "that'll", 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', "don't", 'should', "should've", 'now', 'd', 'll', 'm', 'o', 're', 've', 'y', 'ain', 'aren', "aren't", 'couldn', "couldn't", 'didn', "didn't", 'doesn', "doesn't", 'hadn', "hadn't", 'hasn', "hasn't", 'haven', "haven't", 'isn', "isn't", 'ma', 'mightn', "mightn't", 'mustn', "mustn't", 'needn', "needn't", 'shan', "shan't", 'shouldn', "shouldn't", 'wasn', "wasn't", 'weren', "weren't", 'won', "won't", 'wouldn', "wouldn't"]
punctuations = ['nn','n', '।','/', '`', '+', '\', '"', '?', '▁(', '$', '@', '[', '_', "'", '!', ',', ':', '^', '|', ']', '=', '%', '&', '.', ')', '(', '#', '*', '', ';', '-', '}','|','"']
to_be_removed = stopwords_hi + punctuations + stopwords_en
Let us now remove the stopwords and punctuations altogether:
for i in range(len(df)):
df['text'][i]=[ele for ele in df['text'][i] if ele not in (to_be_removed)]
count_length()
df.tail(10)
The output looks like this:

This is perhaps my favorite part so far! See the word_count values for each row. It has been drastically reduced since we removed Hindi stopwords, English stopwords, and punctuations from our dataset.
Plotting distribution of every tweet’s length for each Label [before text cleaning]
Let’s make more use of word_count to understand something more. To plot a histogram for both labels use the following code:
df.hist(column = 'word_count', by ='label',figsize=(12,4), bins = 5)
The output histogram looks like this:
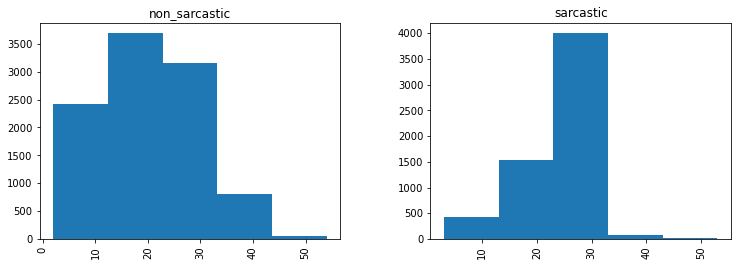
See here that the length of non_sarcastic tweets is way more than sarcastic tweets. Our efforts today will probably result in a more equal graph for both labels (hint: we’ll successfully do that!).
Now, let’s get back to cleaning our dataset.
Remove most frequent unnecessary words from Hindi Text Analysis Data
Removing just the stopwords and punctuations is not enough at all! We will now look at the frequency of all the words or tokens and remove the absurd or the most unnecessary words.
1. To generate the occurrence frequency of each unique token we will use the code as shown below:
corpus_list =[]
for i in range(len(df)):
corpus_list +=df['text'][i]
counter=collections.Counter(corpus_list)
print(counter)
2. The output will be very large since our dataset has almost 16000 entries. For your reference, I am showing some parts of the output which you can expect as well:

3. In the output you see there are so many tokens that are occurring so many times yet they add no value to the analysis. Examples of such tokens are: ‘हमारे’, ‘वो’, and many others.
to_remove = ['नेहरू', 'लेते', 'कटाक्ष', 'जय', 'शी', 'अगर', 'मास्टर', 'वो', 'सिगरेट', 'बीवी', 'इश्क़', 'किताब', 'वश', 'पटाकर', 'पिलाकर']
for i in range(len(df)):
df['text'][i]=[ele for ele in df['text'][i] if ele not in (to_remove)]
count_length()
4. You can add more tokens to be removed from the list. This is a bit manual process, but it is totally necessary.
5. You could have removed the top 100 or 120 tokens with two lines of code, but I felt some tokens were important.
Remove least common words/tokens
Now is the time to remove the least common tokens from the text corpus. The least occurring tokens or words also add no value to the overall analysis.
For this purpose, we will use this code below:
least_common= [word for word, word_count in Counter(corpus_list).most_common()[:-50:-1]]
for i in range(len(df)):
df['text'][i]=[ele for ele in df['text'][i] if ele not in (least_common)]
You will see the dataframe like this with reduced word_count:

Plotting distribution of tweet-length per Label [After text cleaning and processing]
Now let us plot the tweet lengths for both labels and see if our analysis made any difference.
df.hist(column = 'word_count', by ='label',figsize=(12,4), bins = 5)
The plot would look like this:
![Plotting distribution of tweet-length per Label [After text cleaning and processing]](https://editor.analyticsvidhya.com/uploads/46201download.png)
Figure 7: Distribution of each tweet-length per Label after cleaning data
Voilà! The distribution looks good.
Word Cloud for Hindi Text Analysis
from wordcloud import WordCloud
import matplotlib.pyplot as plt
df_list = []
for i in range(len(df)):
df_list +=df['text'][i]
dictionary=Counter(df_list)
wordcloud = WordCloud(width = 1000, height = 700,
background_color ='white',
min_font_size = 10).generate_from_frequencies(dictionary)
# plot the WordCloud image
plt.figure(figsize = (18, 8), facecolor = None)
plt.imshow(wordcloud,interpolation="bilinear")
plt.axis("off")
plt.tight_layout(pad = 0)
plt.show()
The Word cloud will show you the most frequently occurring words and give you an idea of what people have been talking about. Removal of unnecessary tokens in the previous steps has put important topics in the limelight. But running the above code will generate a word cloud like this:
.png)
All right, what is this? You must be wondering. Well if you look closely only English tokens are plotted precisely and others are not. Those other tokens are Hindi words. Plotting a word cloud for English texts is very easy and straightforward. But for Hindi text, we have to use a Unicode font for Hindi that can be downloaded from here. This will allow us to see the words cloud as below:
In the above code you need to make few changes:
1. Download the above-mentioned fonts.
2. Extract it and copy the “gargi.ttf” in the project directory.
3. In the above code, make changes as below:
font = "gargi.ttf"
dictionary=Counter(df_list)
wordcloud = WordCloud(width = 1000, height = 700,
background_color ='white',
min_font_size = 10, font_path= font).generate_from_frequencies(dictionary)
4. If you see, I have added the font path and added that path to the word cloud function, and the result would look like the one below:
.png)
5. This world cloud says a lot! You can dig deeper but on the surface level, the tweets have been mostly talking about the above-plotted topics.
Conclusion
In this article, we have covered the step-by-step process to clean Hindi text data. As you can see the process is different from English text cleaning but nevertheless, having sound knowledge of English text processing will be useful any day. I hope this article was helpful to you. As a next step, you can try to design and build a model that would identify sarcastic and non-sarcastic tweets. If you have any questions about this article, do not hesitate to write a comment below and I will try to answer.
Adiós until next time!
References
[1] Dodds, L. (2020, September 29). Do data scientists spend 80% of their time cleaning data? turns out, no? Lost Boy. Retrieved October 14, 2021, from https://blog.ldodds.com/2020/01/31/do-data-scientists-spend-80-of-their-time-cleaning-data-turns-out-no/
[2] Anoopkunchukuttan. (n.d.). Anoopkunchukuttan/indic_nlp_library: Resources and tools for Indian Language Natural Language Processing. GitHub. Retrieved October 14, 2021, from https://github.com/anoopkunchukuttan/indic_nlp_library.





Hey , It was a great article and I got to learn a lot from it. But a small help which I needed was how do I further convert the tokens into Lemma in order to pass to my model.