This article was published as a part of the Data Science Blogathon.
Introduction

NLTK is a string processing library that takes strings as input. The output is in the form of either a string or lists of strings. This library provides a lot of algorithms that helps majorly in the learning purpose. One can compare among different variants of outputs. There are other libraries as well like spaCy, CoreNLP, PyNLPI, Polyglot. NLTK and spaCy are most widely used. Spacy works well with large information and for advanced NLP.
To get an understanding of the basic text cleaning processes I’m using the NLTK library which is great for learning.
The data scraped from the website is mostly in the raw text form. This data needs to be cleaned before analyzing it or fitting a model to it. Cleaning up the text data is necessary to highlight the attributes that you’re going to want your machine learning system to pick up on. Cleaning (or pre-processing) the data typically consists of a number of steps. Let’s get started with the cleaning techniques!
Removing extra spaces
Most of the time the text data that you have may contain extra spaces in between the words, after or before a sentence. So to start with we will remove these extra spaces from each sentence by using regular expressions.
CODE:
import regex as re
doc = "NLP is an interesting field. "
new_doc = re.sub("\s+"," ",doc)
print(new_doc)
2. Removing punctuations
The punctuations present in the text do not add value to the data. The punctuation, when attached to any word, will create a problem in differentiating with other words.
CODE:
"I like NLP." == 'I like NLP'

Punctuations can be removed by using regular expressions.
CODE:
text = "Hello! How are you!! I'm very excited that you're going for a trip to Europe!! Yayy!"
re.sub("[^-9A-Za-z ]", "" , text)

Punctuations can also be removed by using a package from the string library.
CODE:
import string text = "Hello! How are you!! I'm very excited that you're going for a trip to Europe!! Yayy!" text_clean = "".join([i for i in text if i not in string.punctuation]) text_clean

3. Case Normalization
In this, we simply convert the case of all characters in the text to either upper or lower case. As python is a case sensitive language so it will treat NLP and nlp differently. One can easily convert the string to either lower or upper by using:
str.lower() or str.upper().
For example, you can convert the character to either lower case or upper case at the time of checking for the punctuations.
CODE:
import string text = "Hello! How are you!! I'm very excited that you're going for a trip to Europe!! Yayy!" text_clean = "".join([i.lower() for i in text if i not in string.punctuation]) text_clean

4. Tokenization: Splitting a sentence into words and creating a list, ie each sentence is a list of words. There are mainly 3 types of tokenizers.
a. word_tokenize: It is a generic tokenizer that separates words and punctuations. An apostrophe is not considered as punctuation here.
CODE:
text = "Hello! How are you!! I'm very excited that you're going for a trip to Europe!! Yayy!" nltk.tokenize.word_tokenize(text)
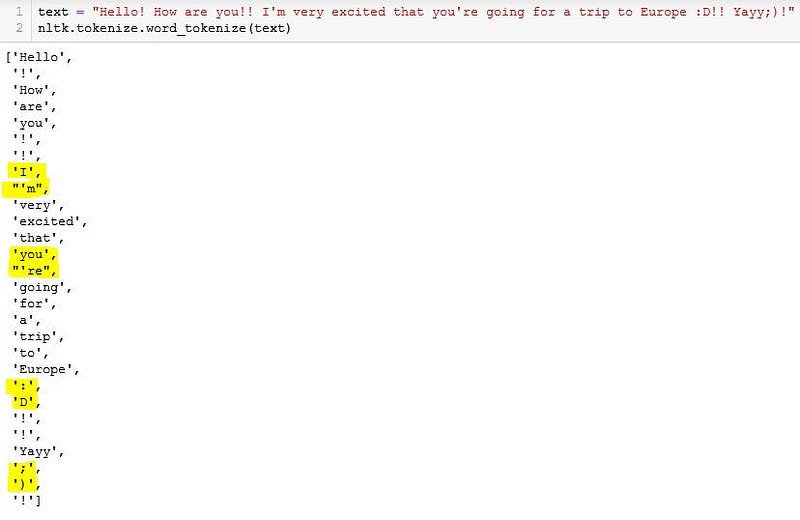
Notice that the highlighted words are split based on the punctuations.
b. TweetTokenizer: This is specifically used while dealing with text data from social media consisting of #,@, emoticons.
CODE:
text = "Hello! How are you!! I'm very excited that you're going for a trip to Europe!! Yayy!" from nltk.tokenize import TweetTokenizer tweet = TweetTokenizer() tweet.tokenize(text)
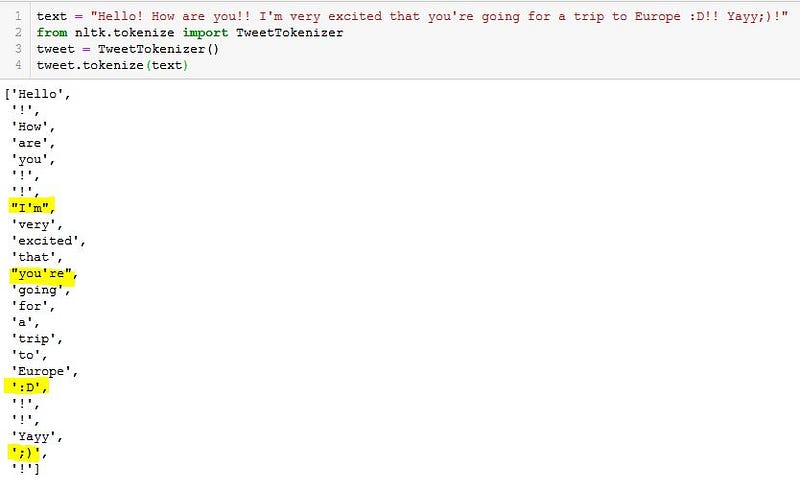
c. regexp_tokenize: It can be used when we want to separate words of our interests which follows a common pattern like extracting all hashtags from tweets, addresses from tweets, or hyperlinks from the text. In this, you can use the normal regular expression functions to separate the words.
CODE:
import re
a = 'What are your views related to US elections @nitin'
re.split('s@', a)

5. Removing Stopwords
Stopwords include: I, he, she, and, but, was were, being, have, etc, which do not add meaning to the data. So these words must be removed which helps to reduce the features from our data. These are removed after tokenizing the text.
CODE:
stopwords = nltk.corpus.stopwords.words('english')
text = "Hello! How are you!! I'm very excited that you're going for a trip to Europe!! Yayy!"
text_new = "".join([i for i in text if i not in string.punctuation])
print(text_new)
words = nltk.tokenize.word_tokenize(text_new)
print(words)
words_new = [i for i in words if i not in stopwords]
print(words_new)
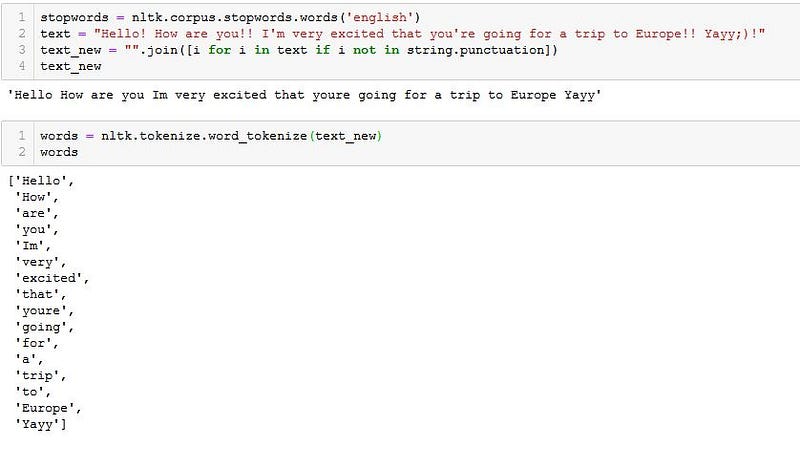

6. Lemmatization & Stemming
a. Stemming: A technique that takes the word to its root form. It just removes suffixes from the words. The stemmed word might not be part of the dictionary, i.e it will not necessarily give meaning. There are two main types of stemmer- Porter Stemmer and Snow Ball Stemmer(advanced version of Porter Stemmer).
CODE:
ps = nltk.PorterStemmer() w = [ps.stem(word) for word in words_new] print(w)
OR
ss = nltk.SnowballStemmer(language = 'english') w = [ss.stem(word) for word in words_new] print(w)

b. Lemmatization: Takes the word to its root form called Lemma. It helps to bring words to their dictionary form. It is applied to nouns by default. It is more accurate as it uses more informed analysis to create groups of words with similar meanings based on the context, so it is complex and takes more time. This is used where we need to retain the contextual information.
CODE:
wn = nltk.WordNetLemmatizer() w = [wn.lemmatize(word) for word in words_new] print(w)

Based on the problem we have to use either Stemming or Lemmatizing.
End Notes
These are the cleaning techniques that must be applied to make our text data ready for analysis and model building. It is not necessary that you have to perform all these steps for cleaning.
Sometimes, you want to create new features for analysis such as the percentage of punctuation in each text, length of each review of any product/movie in a large dataset or you can check that if there are more percentage of punctuations in a spam mail or ham mail or positive sentiment reviews are having more punctuations than negative sentiment reviews or vice-versa.
Once the text cleaning is done we will proceed with text analytics. Before model building, it is necessary to bring the text data to numeric form(called vectorization) so that it is understood by the machine.





