This article was published as a part of the Data Science Blogathon
Imagine collecting all the required information from a website with just a few lines of Python codes! Yes, it’s possible by using Python libraries such as Beautiful Soup and Requests. This article will be the step by step guide which will be useful if you are new to the Web Scraping world, so keep on reading 🙂
What is Web Scraping?
Web scraping is a technique to automate the extraction process of a large amount of data from the website. The data present on the websites will be in unstructured format but with the help of Web scraping, you can scrape, access, and store the data in a much more structured and clean format for your further analysis.
How to perform Web scraping in Python?
Web scraping can be performed only on the websites which provide permissions before scraping, please check the policies of the website.
Steps to Scrape Flipkart Data using Python:
- Install the necessary libraries like Beautiful Soup and Requests
- Choose the data you need to extract
- Send HTTP request to the URL of the page you want to scrape
- Inspect the page and write codes for extraction
Step 1: Install/ Import the necessary libraries
import bs4 from bs4 import BeautifulSoup as bs import requests
If you have not already installed the above libraries use:
pip install bs4 pip install requests
Step 2: Choose the data you need to extract
For this example, we will be scraping Television Data from Flipkart Website. We will be storing the link of the product in the variable link.
link='https://www.flipkart.com/search?q=tv&as=on&as-show=on&otracker=AS_Query_TrendingAutoSuggest_8_0_na_na_na&otracker1=AS_Query_TrendingAutoSuggest_8_0_na_na_na&as-pos=8&as-type=TRENDING&suggestionId=tv&requestId=9c9fa553-b7e5-454b-a65b-bbb7a9c74a29'
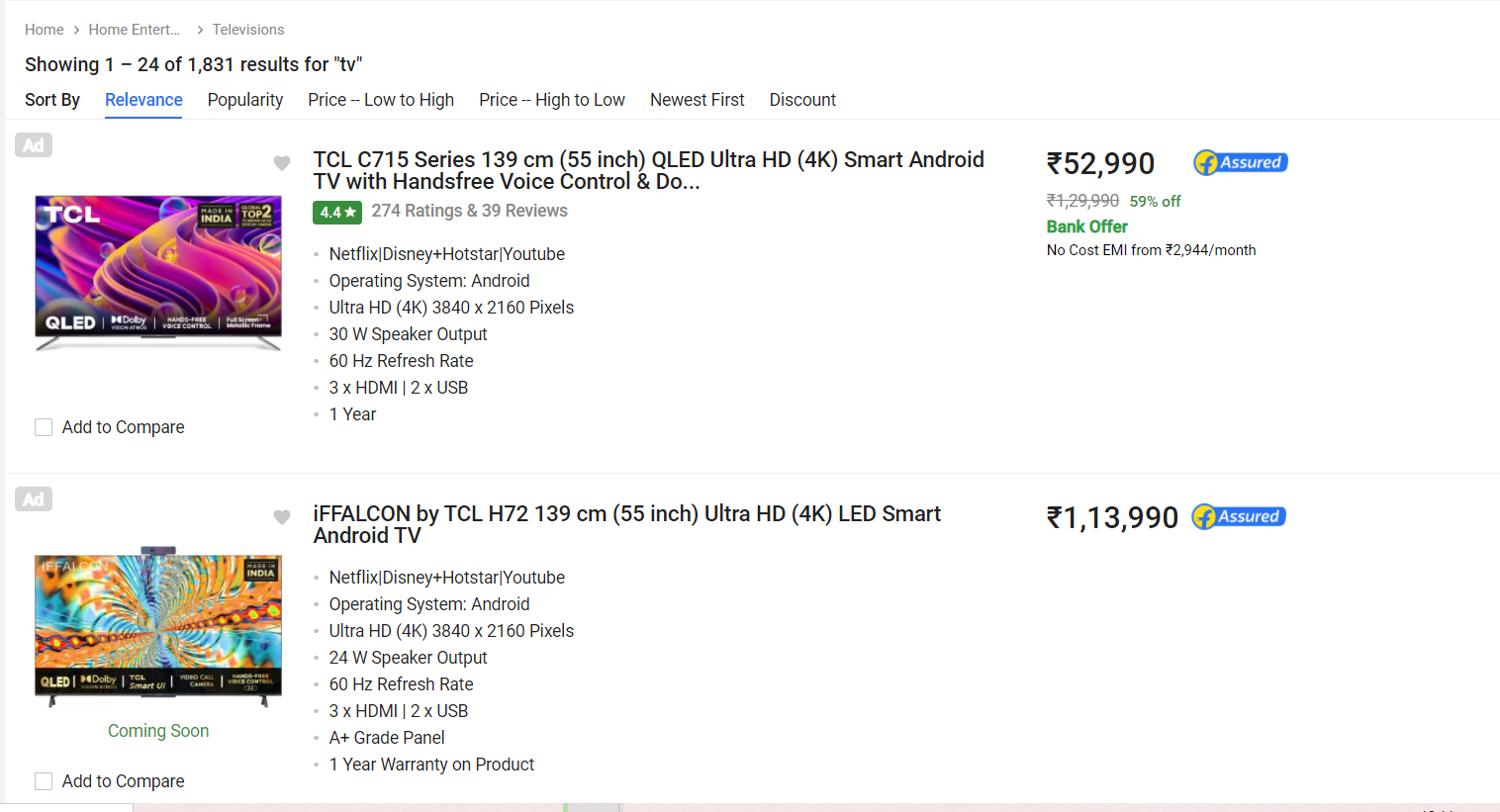
Step 3: Send HTTP request to the URL of the page you want to scrape
We will use the Request library to send the request HTTP request to the URL of the page mentioned in the above code and store the response in the page variable. It will give us the HTML content of the page which is used to scrape the required data from the page.
page = requests.get(link)
We can print the content of the page using the below code. It will give the HTML content of the page and it’s in string format.
page.content
import bs4
from bs4 import BeautifulSoup as bs
import requests
link='https://www.flipkart.com/search?q=tv&as=on&as-show=on&otracker=AS_Query_TrendingAutoSuggest_8_0_na_na_na&otracker1=AS_Query_TrendingAutoSuggest_8_0_na_na_na&as-pos=8&as-type=TRENDING&suggestionId=tv&requestId=9c9fa553-b7e5-454b-a65b-bbb7a9c74a29'
page = requests.get(link)
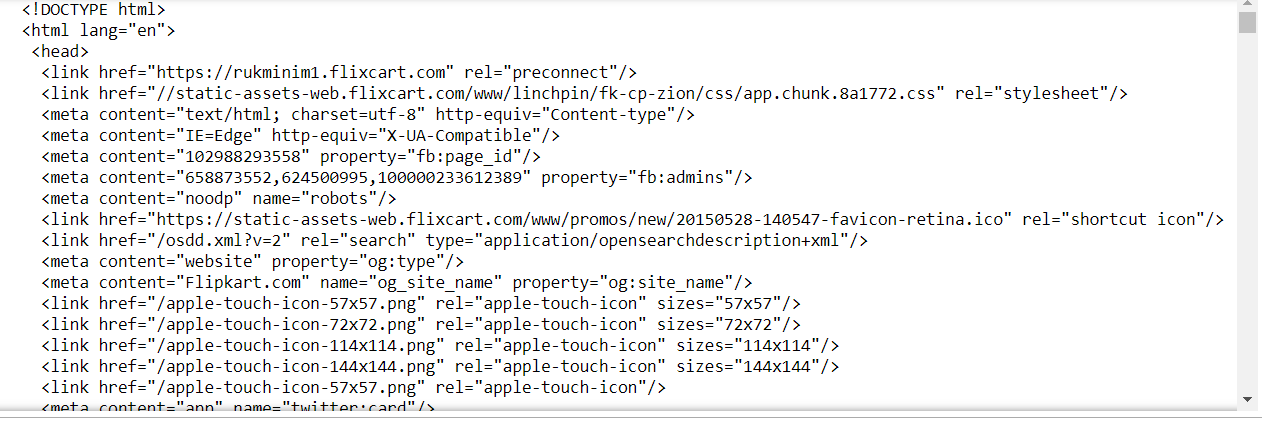
print(page.content)Now that we have got the HTML content of the page, we need to parse the data and store it in soup variable to structure it into a different format which will help in data extraction.
In the below output we can see the difference in the representation of the above data in different structures and formats.
soup = bs(page.content, 'html.parser') #it gives us the visual representation of data print(soup.prettify())
Step 4: Inspect the page and write codes for extraction
In this step, we will Inspect the Flipkart page from where we need to extract the data and read the HTML tags. To do the same, We can right-click on the page and click on “Inspect”.
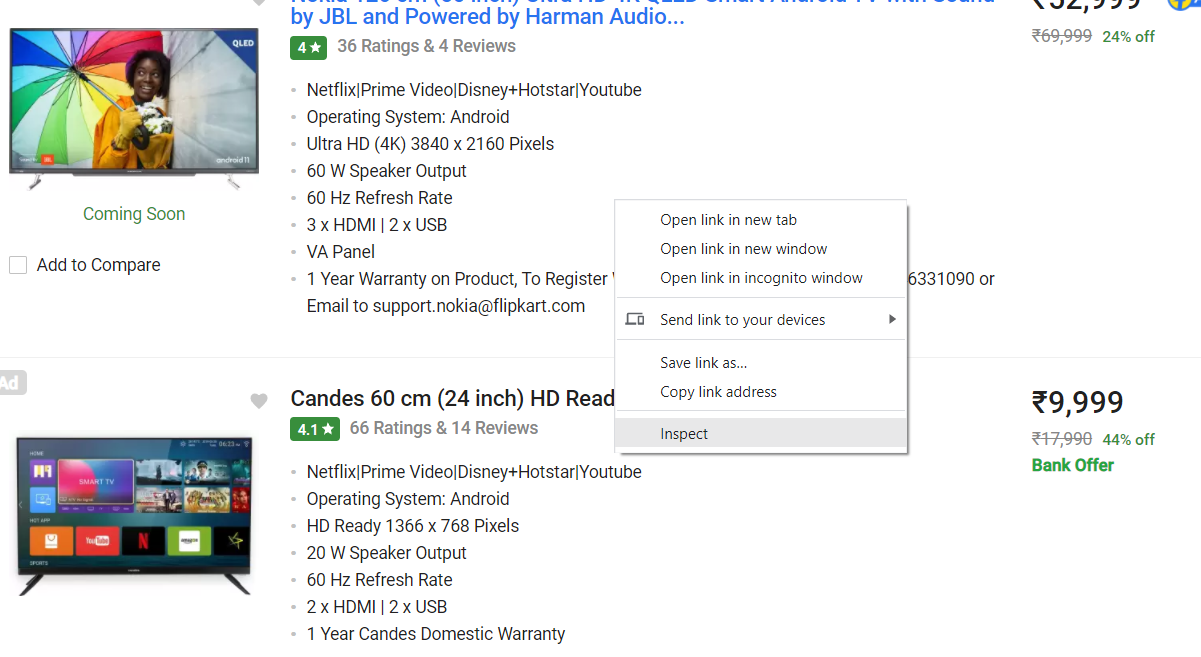
As we click on “Inspect” the following screen will appear where all the HTML tags used are present which will help us to extract the exact data we need.
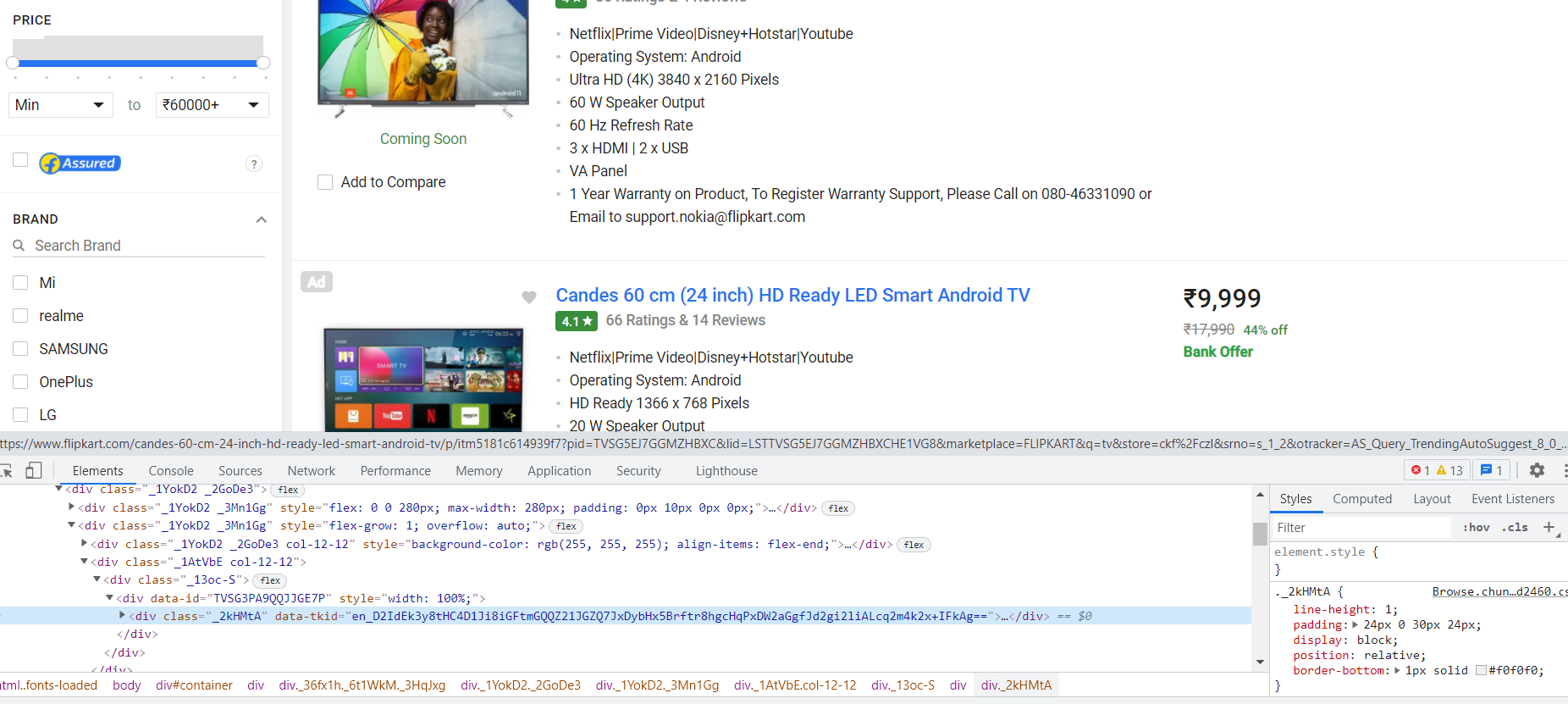
Extracting the Name of the Product
First, we need to figure out the HTML tag and class where the Name of the Product is available. In the below image, we can see that the Name of the Product (highlighted part on the right side) is nested in
tag with class _4rR01T (highlighted on the left side)
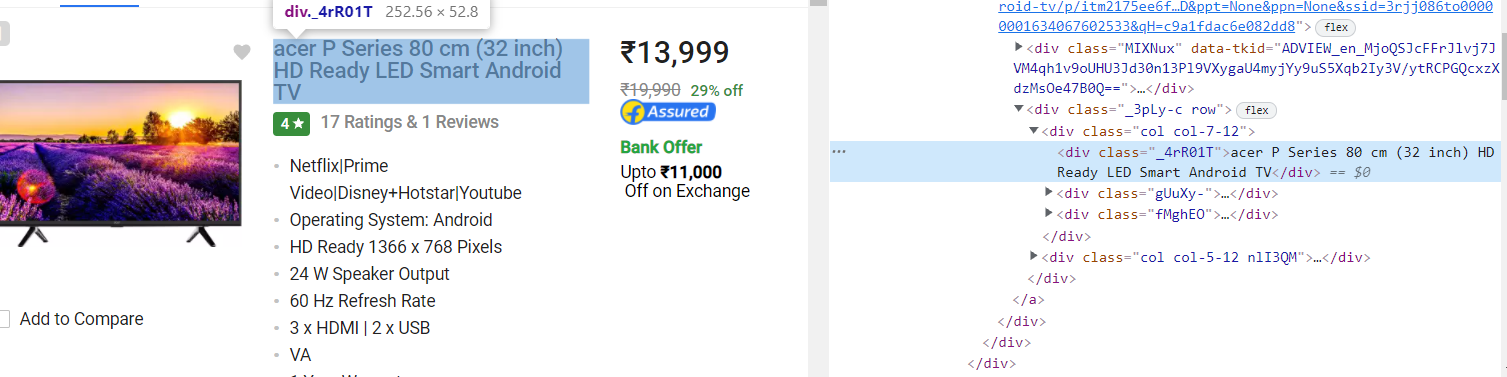
Extract the Name of Television using the ‘find’ function where we will specify the tag and the class and store it in the ‘name’ variable.
name=soup.find('div',class_="_4rR01T")
print(name)
Output:
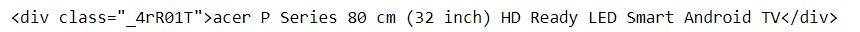
# to get just the name we will use the below code name.text
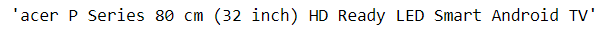
Extracting the Rating of the Product
In the below image, we can see that the Rating (highlighted part on the right side) is nested in
tag with class _3LWZlK (highlighted on the left side)

#get rating of a product
rating=soup.find('div',class_="_3LWZlK")
print(rating)
rating.text

Extracting Other specifications of the product
It is nested in tag with class fMghEO(highlighted on the left side)
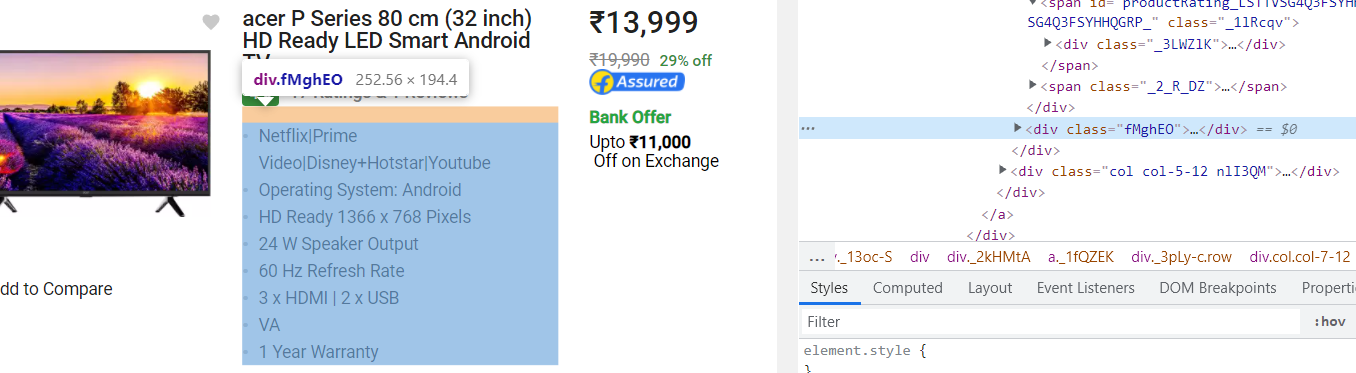
#get other details and specifications of the product
specification=soup.find('div',class_="fMghEO")
print(specification)
specification.text

If we want to get each specification separately then we will run the below code.
for each in specification:
spec=each.find_all('li',class_='rgWa7D')
print(spec[0].text)
print(spec[1].text)
print(spec[2].text)
print(spec[4].text)
print(spec[5].text)
print(spec[7].text)

Extracting Price of the Product
Price is nested in
tag with class _30jeq3 _1_WHN1 (highlighted on the left side)

#get price of the product
price=soup.find('div',class_='_30jeq3 _1_WHN1')
print(price)
price.text

We have successfully got the Name, Rating, Other Specifications, and Price of a Television.
Till now we have just extracted the data of one Television but now we need the data of all the Televisions available on the page so we will be run a loop and store the data in the defined lists.
First, defining the lists to store the value of each feature
products=[] #List to store the name of the product prices=[] #List to store price of the product ratings=[] #List to store rating of the product apps = [] #List to store supported apps os = [] #List to store operating system hd = [] #List to store resolution sound = [] #List to store sound output
Next, inspecting the tag where all the information is present and using it to extract all the features together (As shown in the below figure). Here, all the television information is present in
tag with class _3pLy-c row.
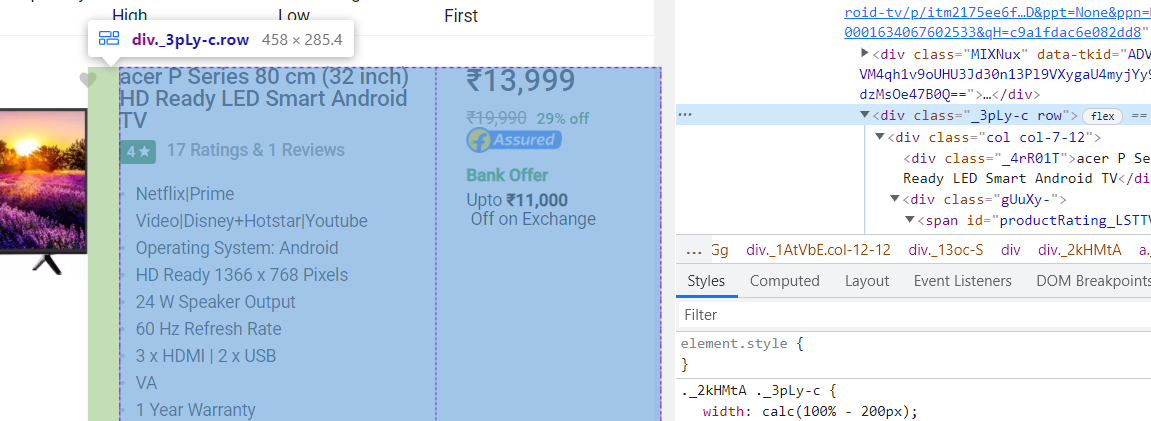
for data in soup.findAll('div',class_='_3pLy-c row'):
names=data.find('div', attrs={'class':'_4rR01T'})
price=data.find('div', attrs={'class':'_30jeq3 _1_WHN1'})
rating=data.find('div', attrs={'class':'_3LWZlK'})
specification = data.find('div', attrs={'class':'fMghEO'})
for each in specification:
col=each.find_all('li', attrs={'class':'rgWa7D'})
app =col[0].text
os_ = col[1].text
hd_ = col[2].text
sound_ = col[3].text
products.append(names.text) # Add product name to list
prices.append(price.text) # Add price to list
apps.append(app)# Add supported apps specifications to list
os.append(os_) # Add operating system specifications to list
hd.append(hd_) # Add resolution specifications to list
sound.append(sound_) # Add sound specifications to list
ratings.append(rating.text) #Add rating specifications to list
After executing the above code, all the features are extracted and stored in the respective lists.
#printing the length of list print(len(products)) print(len(ratings)) print(len(prices)) print(len(apps)) print(len(sound)) print(len(os)) print(len(had))

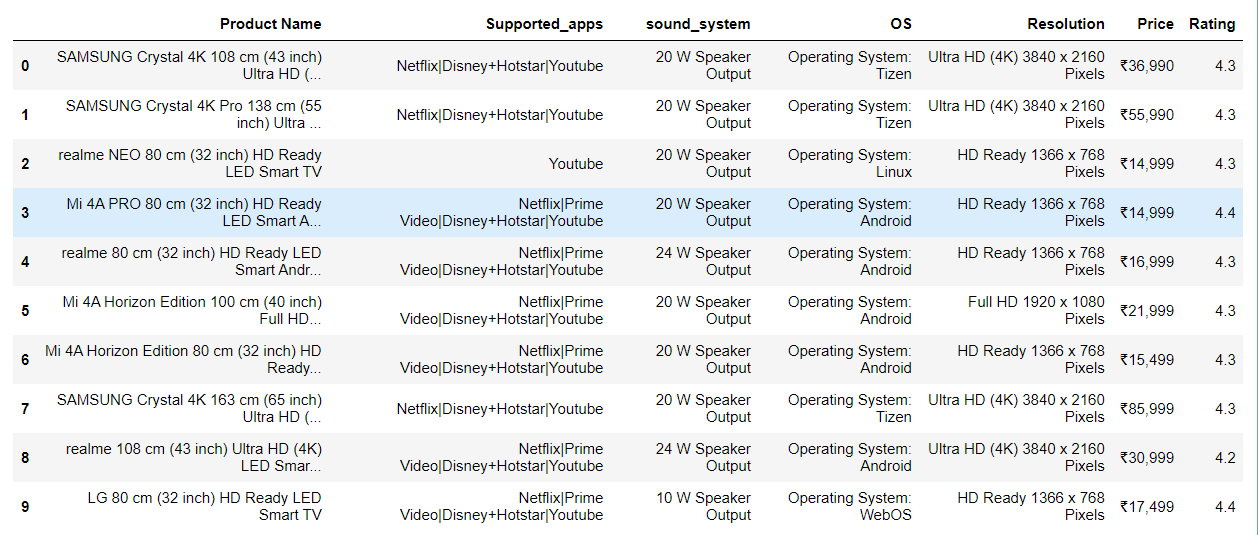
Storing the data into the structured format in the Data Frame.
import pandas as pd
df=pd.DataFrame({'Product Name':products,'Supported_apps':apps,'sound_system':sound,'OS':os,"Resolution":hd,'Price':prices,'Rating':ratings})
df.head(10)
Endnotes
That’s how we can scrape and store the data from the website. Here we have learned to scrape just one page, we can also perform the same on various pages and extract more data for comparison or analysis. The next step from here is to clean the data and perform analysis.
Beautiful Soup Library is one of the easiest libraries that can be used for web scraping and is beginner-friendly but it comes with its own cons. Some of them are:
- it is not the best for scraping dynamic content i.e for the content which keeps on changing.
- it is dependent on other libraries for sending requests to a webpage.
- it does not perform the best with big web scraping projects and is a little slow compared to another library such as scrapy.
About the Author:
I am Deepanshi Dhingra currently working as a Data Science Researcher, and possess knowledge of Analytics, Exploratory Data Analysis, Machine Learning, and Deep Learning. Feel free to share your thoughts and suggestions here or on LinkedIn.







i want total code of scraping the data from flipkart and display in the website with the interactive interface