This article was published as a part of the Data Science Blogathon
Introduction
In today’s world, the internet has become the world’s biggest library with a monumental amount of data accessible to us at the tip of our fingers. In order to make use of this library to its full potential, web scraping has become even an extremely useful skill for data enthusiasts. From scrapping top movie recommendations to getting the stock market data, the list of uses is endless.
In this blog, we shall learn how to make use of Requests and BeautifulSoup library in order to parse a website, make use of HTML tags to get the data we require, and store them in a dataframe for further use.
Don’t worry if you are a total beginner !!
We will be using these skills to scrap movie recommendations from Imdb so just follow along and you will get a hands-on experience of data scraping. Let’s go !!
Libraries: Requests and BeautifulSoup
The Requests library is used to make HTTP requests in Python. It is an easy-to-use library with a lot of features. We will be using it to get the content from the URL of the webpage that we wish to scrap
BeautifulSoup is a library that is used to parse HTML documents. We create a new BeautifulSoup object by passing the HTML content and the type of parser we want to use
Implementation
1.Installing the Libraries
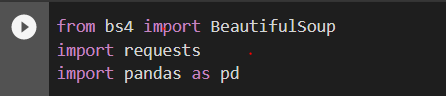
This will allow us to use requests and BeautifulSoup for scrapping the data and Pandas library for storing the data into a dataframe
2. Understanding the Webpage structure
We are going to scrap the most popular movies from IMDb. The most important step in data scraping is to understand the structure of the webpage and the structure of the data we want to scrap
In order to see the HTML code for a website, do a “Right-Click” and click on “Inspect Source”
.jpeg)
This shows us the HTML code for the web page. Now we wish to scrap the following:
1.The rank of the movie
2.Name of the movie
3.IMDb rating of the movie
Ongoing through the HTML code, we see that this information is stored in the form of a table using the <table> tag
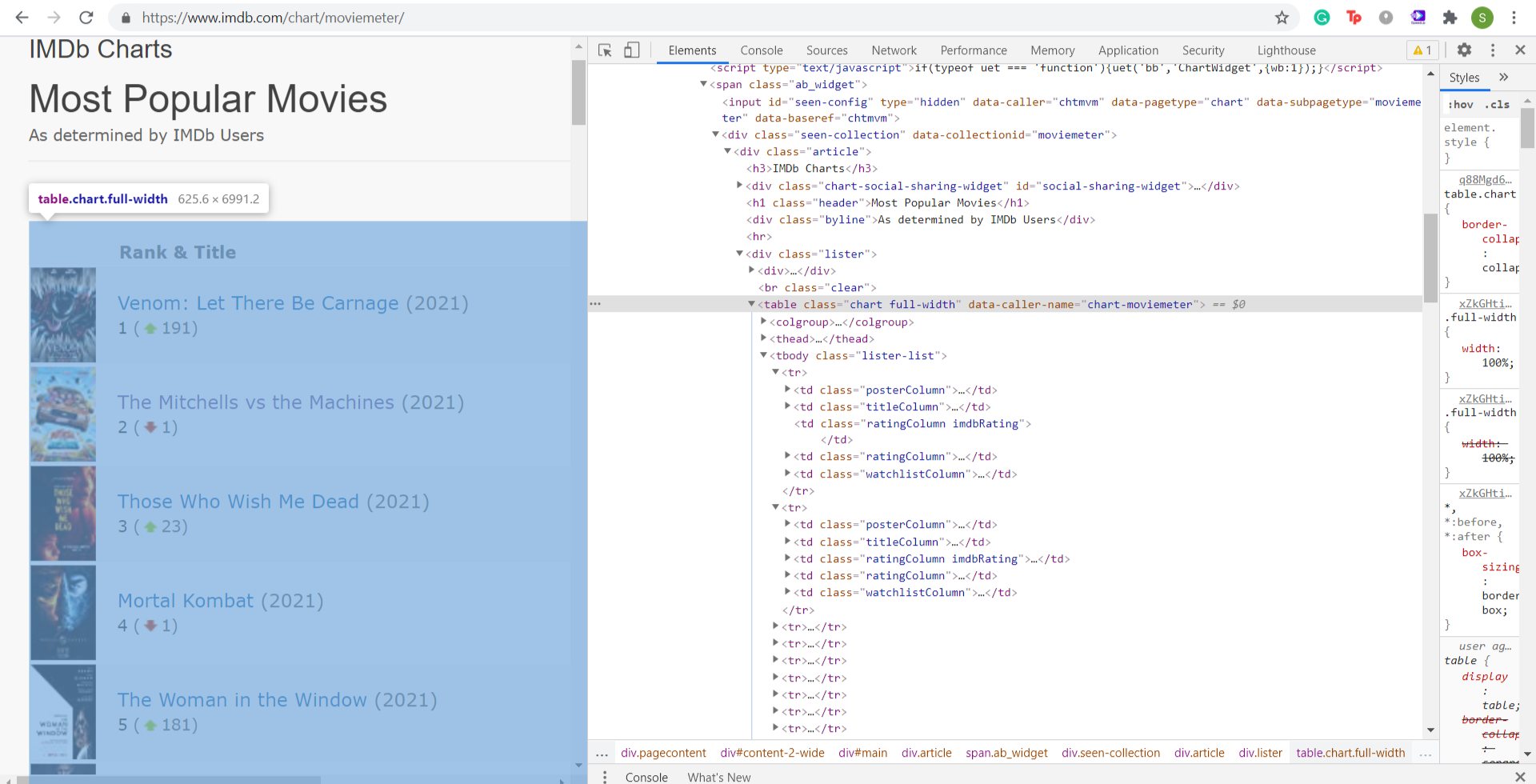
Wait !! Let us take a detour and understand the basic structure of the HTML page which will help us in scraping data easily
3. Understanding HTML structure and tags
All the data on a webpage is stored inside different tags based on the content and presentation. The various important tags are :
1. <div> tag: It is used to define a section of the webpage. For example, you can observe that the table which we want to scrap is present inside a <div> tag with class =” lister” and this is further inside a <div> tag with class = “article”
2. <a> tag: This is used to create a hyperlink to another webpage. It consists of the “href” attribute which specifies the URL of the webpage it links to. For example, when you click on a word and it directs you to another webpage on Wikipedia, it is because the word is present inside a tag along with the href attribute containing the URL of the web page you are directed to
3.<ul> tag: This is used to create unordered lists on the webpage. Each entry of the list is marked with a <li> tag
4.<ol> tag: This is used to create ordered lists on the webpage. Similar to the <ul> tag, each entry is marked with a <li> tag
5.<table> tag: This is used to create a table on the webpage. For example, we can see on the IMDb page, the information we require is present in a tabular form.
6.<tr> tag: This is used to specify the different rows under the table. For example, the different movies on the IMDb page are present in different rows and hence, in different <tr> tags
7.<td> tag: This is used to specify the content for each column for a given row in a table. For example, the content for the different columns (“Rank and Title”, “IMDb Rating”, “My Rating”) for each row is specified under the <td> tag
Now, you would be having a basic idea about the structure of HTML code and are ready to get on with the next step of data scraping
4. Creating a BeautifulSoup object
.png)
This creates an object named “soup” which has the HTML code for the URL given and can be used to select certain sections of the data
.png)
So, we can see that the data needed is present in the soup object
5. Extracting the data using BeautifulSoup
.png)
The information regarding the movies is stored inside a <table> tag with the class attribute as “chart full-width”
So we will use the “find_all” function to find all such tables in the soup object
.png)
Within the table, the data for each movie is stored in a <tr> tag so we will loop through these movies and store their data in a dataframe
The <td> tag containing the name and rank of the title has the class = “titleColumn”. The name of the movie is stored in a tag since it connects it to the webpage of that particular movie while the rank is stored inside a <div> tag with the class attribute as “velocity”
Also, the <td> tag containing the IMDb rating of the movie has the class attribute as “ratingColumn IMDb rating”
.png)
We can extract the text within a tag using the following way:
.png)
So using the “text” attribute, we can find the text present inside a tag
6. Storing the data in a DataFrame
Now, we will extract the rank and IMDb rating also and store all the data in the form of a dataframe.
.png)
The final dataframe we get will be :
.png)
And there, you have understood how to scrap a website using Python !!
Conclusion
So, in this blog, we learned about the webpage structure, HTML tags, and finally, scraping data from a website. The uses of web scraping are limitless and BeautifulSoup is one of the libraries built to make the task of data scraping easy. There are many other powerful libraries used for data scraping like Scrapy. Try to use the skills learned in this blog on different websites and build web scrapers. Thank you !!
The media shown in this article on Data Scraping using BeautifulSoup are not owned by Analytics Vidhya and is used at the Author’s discretion.







very informational and easy to understand.