Overview
What is a web scraping and how does it work with Python? Interestingly, Web scraping is a word that refers to the practice of extracting and processing vast amounts of data from the internet using a computer or algorithm. Scraping data from the web is a useful skill to have, whether you’re a data scientist, engineer, or anyone who analyses enormous volumes of data. Let’s get started.!
This article was published as a part of the Data Science Blogathon
Table of contents
Introduction to Web Scraping
Consider the following scenario: you need to pull an enormous volume of data from websites as rapidly as workable. How would you do it if you didn’t go to each website and manually collect the data? Well, the answer is “web scraping”. Scraping the web makes this process a lot easier and faster.

Image 1
Web scraping is a technique for extracting vast amounts of data from websites. But why is it necessary to gain such vast amounts of data from websites? Look at the following web scraping applications to learn more:
- Price comparison and competition monitoring – Web scraping tools can monitor this company’s catering products data at all times.
- Train and Test data for Machine Learning Projects – Web scraping aids in the collection of data for the testing and training of Machine Learning models.
- Academic Research.
- Gather hotel/restaurant reviews and ratings from sites such as TripAdvisor.
- Use websites like Booking.com and Hotels.com to scrape hotel room pricing and information.
- Scrape tweets from Twitter that are associated with a specific account or hashtag.
- We can scrape business contact information such as phone numbers and email addresses from yellow pages websites or Google Maps business listings to generate leads for marketing.
Implementing Web Scraping using Python
Web scraping is a way to extract vast volumes of data from websites that are automated. Sometimes, the information on the web pages is not structured. In that case, Web scraping aids in the collection of unstructured data and its subsequent storage in a structured format. We can do scraping websites in a variety of methods, including using internet services, APIs, or building your programs. In this article, we’ll look at how to use web scraping Python to implement web scraping.
Why is python used for web scraping?
1) Python includes many libraries, such as Numpy, Matplotlib, Pandas, and others, that provide methods and functions for a variety of uses. As a result, it’s suitable for web crawling and additional data manipulation.
2) Python is an easy language to program in. There are no semi-colons “;” or curly-braces “{}” required anywhere. So it is easier to use and less noisy.
3) Dynamically typed: You don’t have to define data types for variables in Python; you can just use them wherever they’re needed. This saves you time and speeds up your work.
4) Small code, long process: Web scraping is a technique for saving time. But what good is it if you waste more time writing code? You don’t have to, though. We can write small codes in Python to accomplish large tasks. As a result, even while writing the code, you save time.
5) Python syntax is simple to learn because reading Python code is quite understandable compared to reading a statement in English. Python’s indentation helps the user distinguish between distinct scopes/blocks in the code, making it expressive and easy to understand.
Step-by-Step process to Scrape Data From A Website:
Web scraping is gaining data from web pages using HTML parsing. Something data is available in CSV or JSON format from some websites, but this is not always the case, causing the use of web scraping.
When you run the web scraping Python code, it sends a request to the URL you specified. The server provides the data in response to your request, allowing you to see the HTML or XML page. The code then parses the HTML or XML page, locating and extracting the data.
How is Web Scraping using Python done?
We can do web scraping with Python using three different frameworks:
Scrapy
Scrapy is a high-level web crawling and scraping framework for crawling websites and extracting structured data from their pages. From data mining to monitoring and automated testing, we can use it for a variety of tasks. Scraping hub and a slew of other contributors built and maintain it.
Scrapy is the best of the bunch since it requires us to concentrate mostly on parsing the HTML structure of the webpage rather than sending queries and extracting HTML content from the response; in Scrapy, we simply need to specify the website URL.
The scraping hub can also host scrapy projects, and we can schedule when scrapers to run.
Beautiful Soup
Beautiful Soup is a Python package for parsing HTML and XML files and extracting data. It integrates with your preferred parser to offer fluent navigation, search, and modification of the parse tree. It is normal for programmers to save hours or even days of effort.
To scrape a website with Beautiful Soup, we must also use the requests library to send requests to the website and receive responses, as well as extract HTML content from those responses and deliver it to the Beautiful Soup object for parsing.
Selenium
The Selenium Python junctions provide a simple API for writing Selenium WebDriver functional/acceptance tests. You may use the Selenium Python API to access all of Selenium WebDriver’s features simply.
Selenium framework is used to scrape websites that load content dynamically, such as Facebook and Twitter, or if we need to log in or sign up using a click or scroll page action to get to the page that is to be scrapped.
After the site has loaded the dynamically created material, we can use Selenium to gain access to the HTML of that site and feed it to Scrapy or Beautiful Soup to execute the same activities.
Pandas
Pandas is a data manipulation and analysis library. It’s used to extract data and save it in the format that you want.
Scraping E-commerce Website
Pr-requisites:
- Python 2. x or Python 3. x with Beautiful Soup, pandas, Selenium libraries installed.
- Ubuntu Operating System.
- Google-chrome browser.
Now let’s extract data from the website,
Web scraping using beautiful soup and selenium:
Step 1: Locate the URL you wish to scrape.
We’ll scrape the amazon website to get the price, name, and rating of mobile phones for this example. This page’s address is:
Step 2: Inspect the page and view the page source:
They usually nest the data on tags. So we examine the website to discover where the data we want to scrape is nested beneath which tag. Simply right-click on an element and select “Inspect” from the drop-down menu.
Right-click anywhere on the page and select “Inspect” / “View Page Source” to inspect it. To see where a particular element on a webpage, such as text or an image, right-click it and select ‘Inspect’ / “View Page Source“.
When we navigate on the “Inspect” tab, “Browser Inspector Box” will open in the same tab.
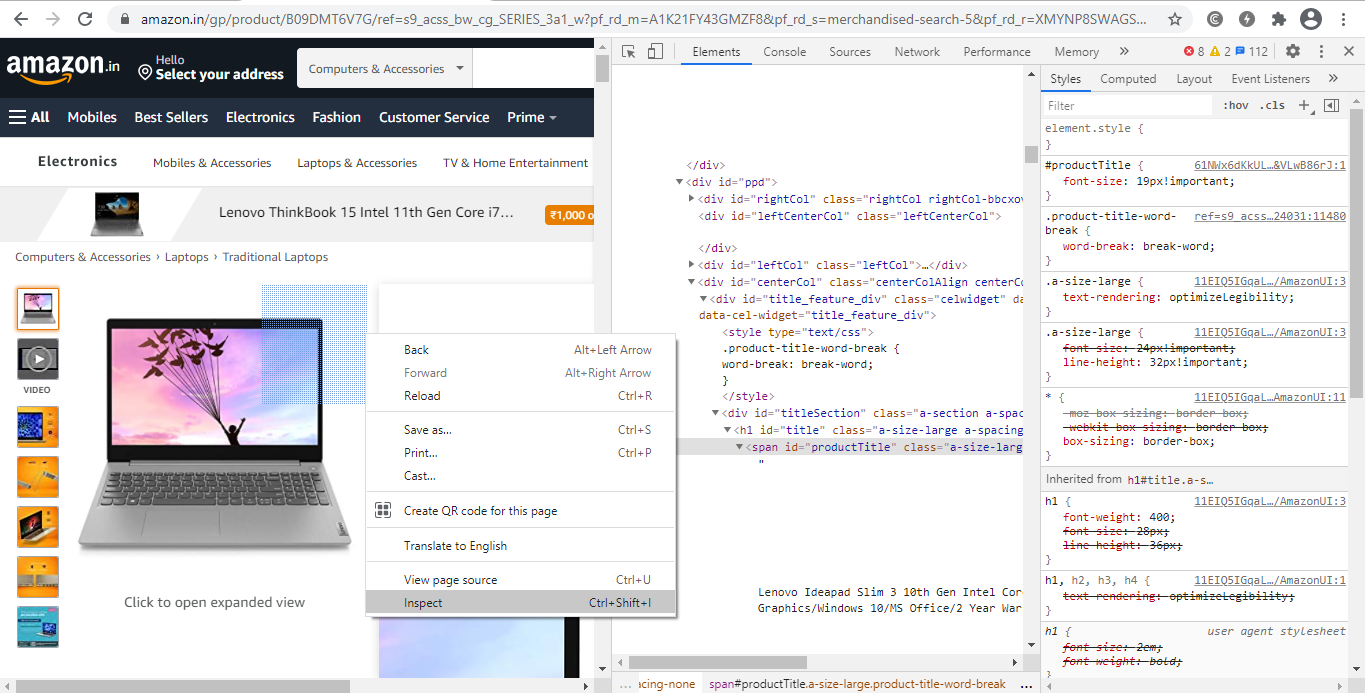
Step 3: Locate the information you wish to retrieve.
Let’s extract the Price, name, and rating from the “div” tag, which are all in the “div” tag.
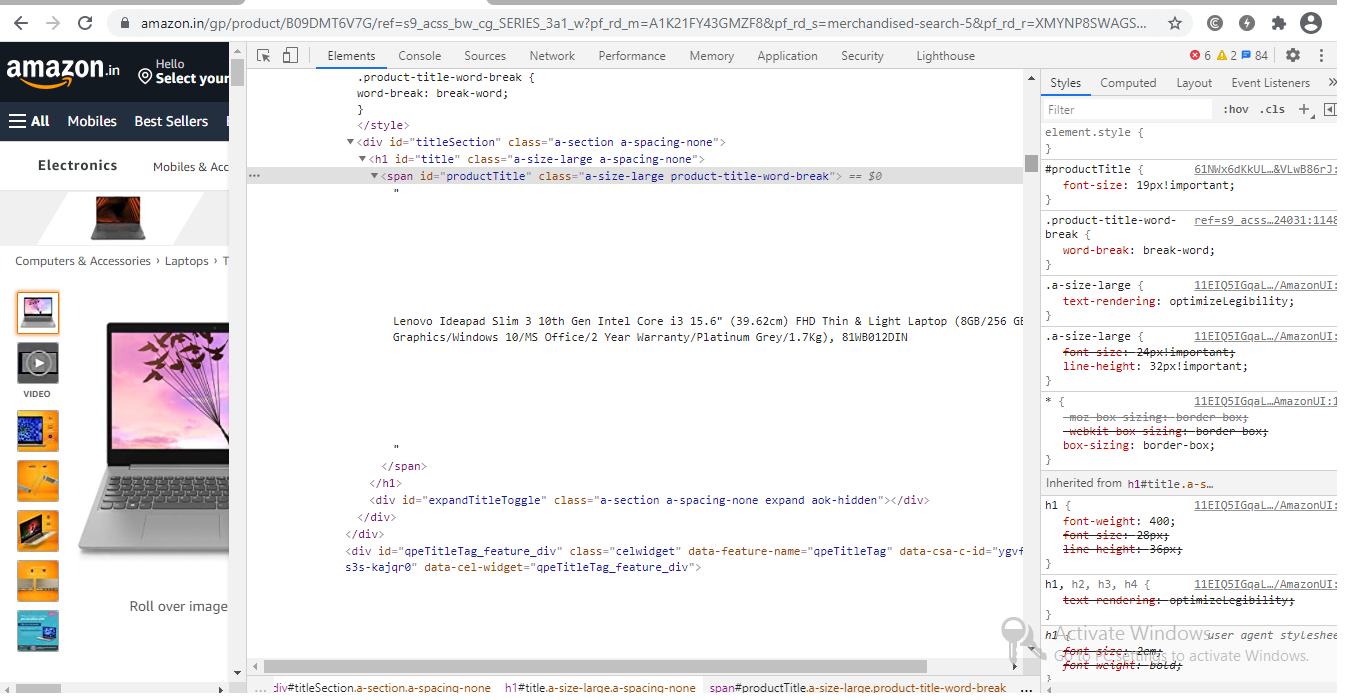
Step 4: Construct the code.
Let’s start by making a Python file. To do so, open Ubuntu’s terminal and type gedit your file name> with the.py extension.
gedit web-scrap.py
First, let us import all the libraries:
from selenium import webdriver from BeautifulSoup import BeautifulSoup import pandas as pd
Make sure you have Python (version 3+) and BeautifulSoup installed on your machine before you scrape. If you don’t have BeautifulSoup, enter the following command in your Terminal/Command Prompt:
pip install beautifulsoup4
Because our goal is to extract the whole body of the article, it’s crucial to note the

element, which contains the entire text of the article. Let’s take a deeper look at the page and see if we can find the tag.
We must set the path to chrome driver to configure web driver to use Chrome browser.
driver = webdriver.Chrome(“/usr/lib/chromium-browser/chromedriver”)
Next, we have to write code to open the URL and store the extracted details in a list,
products=[] #store name of the product
prices=[] #store price of the product
ratings=[] #store rating of the product
driver.get("https://www.amazon.in/gp/product/B09DMT6V7G/ref=s9_acss_bw_cg_SERIES_3a1_w?pf_rd_m=A1K21FY43GMZF8&pf_rd_s=merchandised-search-5&pf_rd_r=XMYNP8SWAGSCKFMMAJT6&pf_rd_t=101&pf_rd_p=2a1ca9d4-ed84-4a24-8db3-0c378b495799&pf_rd_i=1375424031")
It’s time to extract the data from the website now that we’ve built the code to open the URL. The data we wish to extract is nested in
tags, as previously stated. As a result, I’ll look for div tags with those class names, extract the data, and save it in a variable. Please see the code below:
content = driver.page_source
soup = BeautifulSoup(content)
for a in soup.findAll('a',href=True, attrs={'class':'_31qSD5'}):
name=a.find('div', attrs={'class':'_3wU53n'})
price=a.find('div', attrs={'class':'_1vC4OE _2rQ-NK'})
rating=a.find('div', attrs={'class':'hGSR34 _2beYZw'})
products.append(name.text)
prices.append(price.text)
ratings.append(rating.text)
Step 5: Run the code and extract the data.
Run the code by using the below command:
python web-scrap.py
Step 6: Save the information in an appropriate format.
Save the data in a format after you’ve extracted it. Depending on your needs, this format may differ. We’ll save the extracted data in CSV (Comma Separated Value) format in this example. To accomplish this, I’ll include the following lines in my code:
df = pd.DataFrame({'Product Name':products,'Price':prices,'Rating':ratings})
df.to_csv('products.csv', index=False, encoding='utf-8')
Now run the entire program again,
A file called “products.csv” is created, which contains the extracted data.
the output will be:
Selenium is frequently used to extract data from websites that contain a large amount of Javascript. Running a large number of Selenium/Headless Chrome instances at scale is difficult.
Web scraping/crawling using scrapy
We can install scrapy via pip command. However, the Scrapy literature strongly advises that it be installed in a specialized virtual environment to minimize problems with your system programs.
Virtualenv and Virtualenvwrapper are what I’m using:
mkvirtualenv scrapy_env
pip install Scrapy
With this command, you may now create a new Scrapy project:
scrapy startproject web_scrap
All the project’s boilerplate files will be created because of this.
├── web_scrap
│ ├── __init__.py
│ ├── __pycache__
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ ├── __init__.py
│ └── __pycache__
└── scrap.cfg
I tried to explain all the folders and files below.
items.py is a model for the data that has been extracted. You can create your model (for example, a product) that inherits the scrapy item class.
pipelines.py: we use pipelines in scrapy to process the extracted data, clean the HTML, validate the data, and save it to a database or export it to a custom format.
middlewares.py: The request/response life-cycle was changed using middleware. For example, instead of executing the requests yourself, you might construct a middleware to rotate user-agents or use an API.
scrapy.cfg is a configuration file that allows you to adjust some settings.
We can find spider class in the /spiders folder. Spiders are scrapy classes that define how to scrape a website, including which links to follow and how to collect data from those links.
The product name, image, price, and description will be extracted.
Shell Scrapy
Scrapy includes a built-in shell that may debug scraping code in real-time. It quickly tests your XPath expressions and CSS selectors. It’s a fantastic tool for writing web scrapers, and I use it all the time!
We can configure scrapy Shell to use a different console than the usual Python console, such as IPython. You’ll receive auto-completion and other useful features like colorized output.
You must add the following line to your scrapy.cfg file to use it in your scrapy Shell:
shell = ipython
Once we configured ipython, we can start using scrapy shell:
$ scrapy shell --nolog
Start fetching the URL simply by using the command below:
fetch('https://mamaearth.in/product/mamaearth-onion-shampoo-for-hair-growth-hair-fall-control-with-onion-oil-plant-keratin-250-ml')The /robot.txt file will be fetched first.
[scrapy.core.engine] DEBUG: Crawled (404) <GET https://mamaearth.in/product/robots.txt> (referer: None)Because there is no robot.txt in this scenario, we get a 404 HTTP code. Scrapy will default to following the rule if there is a robot.txt file.
This behavior can be disabled by altering the following setting in settings.py:
ROBOTSTXT_OBEY = True
Data extraction:
Scrapy doesn’t run Javascript by default, so if the website you’re scraping has a frontend framework like Angular or React.js, you might have difficulties getting the data you need.
Let’s use an XPath expression to get the product title and price:
We’ll use an XPath expression to extract the price, and we’ll choose the first span after the div with the class Flex-sc-1lsr9yp-0 fiXUrs PriceRevamp-sc-13vrskg-1 jjWoWj.
response.xpath(“//div[@class=’Flex-sc-1lsr9yp-0 fiXUrs PriceRevamp-sc-13vrskg-1 jjWoWj’]/span/text()”).get()

Creating a Scrapy Spider class
Spiders are scrapy classes that determine your crawling (what links / URLs should be scraped) and scraping behavior.
Here are the several processes a spider class uses to scrape a website:
start_urls and start requests() are used as the method to call these URLs. If you need to alter the HTTP verb or add any parameters to the request, you can override this method.
For each URL, it will create a Request object and send the response to the callback function parse(). The data (in our example, the product price, image, description, and title) will then be extracted by the parse() method, which will return a dictionary, an Item object, a Request, or an iterable.
You can return scraped data as a basic Python dictionary with Scrapy, but it’s better to use the Scrapy Item class.
Item class: It’s just a simple container for our scraped data, and Scrapy will use the fields of this item for a variety of purposes, like exporting the data to multiple formats (JSON / CSV…), the item pipeline, and so on.
let’s write the python code for the product class:
import scrapy
class Product(scrapy.Item):
price = scrapy.Field()
product_url = scrapy.Field()
title = scrapy.Field()
img_url = scrapy.Field()We can now create a spider using the command-line helper:
scrapy genspider myspider mydomain.com
In Scrapy, there are several sorts of Spiders that can tackle the most frequent web scraping problems:
We’re going to use a spider class. It takes a list of start URLs and uses a parse function to scrape each one.
CrawlSpider follows links that are determined by rules.
The URLs defined in a sitemap are extracted by the Sitemap spider.
There are two needed attributes in the EcomSpider class:
Name, which is the name of our Spider (which you can run with scrapy runspider spider_name)
The beginning URL is start_urls.When using a CrawlSpider that can track links on other domains, the allowed domains parameter is critical.
import scrapy
from product_scraper.items import Product
class EcomSpider(scrapy.Spider):
name = 'ecom_spider'
allowed_domains = ['mamaearth.in']
start_urls = ['https://mamaearth.in/product/mamaearth-onion-shampoo-for-hair-growth-hair-fall-control-with-onion-oil-plant-keratin-250-ml/']
def parse(self, response):
item = Product()
item['product_url'] = response.url
item['price'] = response.xpath("//div[@class='Flex-sc-1lsr9yp-0 fiXUrs PriceRevamp-sc-13vrskg-1 jjWoWj']/span/text()").get()
item['title'] = response.xpath('//section[1]//h1/text()').get()
item['img_url'] = response.xpath("//div[@class='product-slider']//img/@src").get(0)
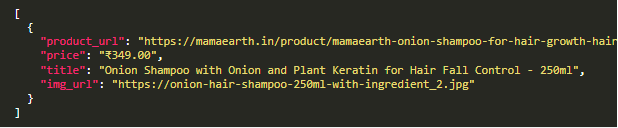
return itemTo export the output into JSON, run the code as follows (you could also export to CSV)
scrapy runspider ecom_spider.py -o product.json
Extracted JSON file will look like the below,
Scraping many pages
It’s time to learn how to scrape many pages, such as the full product catalog, now that we know how to scrape a single page. Spiders come in a variety of shapes and sizes, as we saw before.
A sitemap should be the first thing you look at if you want to scrape a full product catalog. I created specific sitemaps for this purpose, to show web crawlers how the website is organized.
A sitemap.xml file can usually be found at base URL/sitemap.xml. Scrapy assists you to parse a sitemap, which might be challenging.
https://mamaearth.in/product/
2019-10-17T11:22:16+06:00
https://mamaearth.in/product/mamaearth-onion-shampoo-for-hair-growth-hair-fall-control-with-onion-oil-plant-keratin-250-ml/
2019-10-17T11:22:16+06:00
Fortunately, we can limit URLs to read only those that fit a pattern; it’s very simple; Here, we only want URLs with /products/ in them:
class SitemapSpider(SitemapSpider):
name = "sitemap_spider"
sitemap_urls = ['https://mamaearth.in/product/sitemap.xml']
sitemap_rules = [
('/products/', 'parse_product')
]
def parse_product(self, response):
# ... scrap product ...To scrape all the products and export the results to a CSV file, run this spider:
scrapy runspider sitemap_spider.py -o output.csv
What if there was no sitemap on the website? Scrapy has a solution!
Starting with a start URLs list, the Crawl spider will crawl the target website. Then, based on a set of rules, it will extract all the links for each URL. It’s simple in our instance because all goods have the same URL pattern of /products/product title, therefore all we have to do is filter these URLs.
import scrapy
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
from product_scraper.productloader import ProductLoader
from product_scraper.items import Product
class MySpider(CrawlSpider):
name = 'crawl_spider'
allowed_domains = ['mamaearth.in']
start_urls = ['https://mamaearth.in/product/']
rules = (
Rule(LinkExtractor(allow=('products', )), callback='parse_product'),
)
def parse_product(self, response):
# .. parse productThese built-in Spiders, as you can see, are simple to operate. It would have been far more difficult to build it from the ground up.
Scrapy takes care of the crawling logic for you, such as adding new URLs to a queue, keeping track of already parsed URLs, multi-threading, and so on.
Conclusion
I hope you found this blog post interesting! You should now be familiar with the Selenium API in Python and beautiful soup, as well as web crawling and scraping with scrapy. In this article, we looked at how to scrape the web with Scrapy and how it may help you address some of your most typical web scraping problems.
Endnotes
1) If you have to execute repetitive operations like filling out forms or reviewing information behind a login form on a website that doesn’t have an API, Selenium may be a pleasant choice.
2) It’s easy to see how Scrapy can help you save time and construct better maintainable scrapers if you’ve been conducting web scraping more “manually” with tools like BeautifulSoup / Requests.
3) If you want to add any opinions about scraping the web with Python, add them in the comment section. To know more about web scraping, Kindly read the upcoming article! Thank you.
About Myself
Hello, my name is Lavanya, and I’m from Chennai. I am a passionate writer and enthusiastic content maker. The most intractable problems always thrill me. I am currently pursuing my B. Tech in Chemical Engineering and have a strong interest in the fields of data engineering, machine learning, data science, and artificial intelligence, and I am constantly looking for ways to integrate these fields with other disciplines such as science and chemistry to further my research goals.
Linkedin URL: https://www.linkedin.com/in/lavanya-srinivas-949b5a16a/
Image Source:
- Image 1: https://cdn.mindbowser.com/wp-content/uploads/2020/10/05200951/how-does-this-work-web-scrapping.svg
- Image 2: https://mamaearth.in/product/mamaearth-onion-shampoo-for-hair-growth-hair-fall-control-with-onion-oil-plant-keratin-250-ml?utm_source=google&utm_medium=cpc&utm_term=103265401422&gclid=CjwKCAjw7–KBhAMEiwAxfpkWGodzkCf2NB2jHc3wFbQhcWzSmjACKe178qdv0EB7Ce8Lw6iflGeHxoCeZYQAvD_BwE
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.
Hello, my name is Lavanya, and I’m from Chennai. I am a passionate writer and enthusiastic content maker. The most intractable problems always thrill me. I am currently pursuing my B. Tech in Computer Engineering and have a strong interest in the fields of data engineering, machine learning, data science, and artificial intelligence, and I am constantly looking for ways to integrate these fields with other disciplines such as science and computer to take further my research goals.







Hi, Very nice article with detailed inputs on the entire process! Would like to understand how to webscrape from pages that do not allow right click to reach the inspect page. Thanks!
Hi pratik, thank you for your appreciation! Let me clear your doubt, incase if the right click or inspect tab is not available Use Ctrl + Shift + C (or Cmd + Shift + C on Mac) to open the DevTools in Inspect Element mode, or toggle Inspect Element mode if the DevTools are already open. Try this out pratik and if you have further queries, Mention it in the comments session.
If you are using Firefox, goto Open Application Menu (three horizontal bars) -> More Tools -> Web Developers Tools.