This article was published as a part of the Data Science Blogathon
Introduction
Text classification is a machine-learning approach that groups text into pre-defined categories. It is an integral tool in Natural Language Processing (NLP) used for varied tasks like spam and non-spam email classification, sentiment analysis of movie reviews, detection of hate speech in social media posts, etc. Although there are a lot of machine learning algorithms available for text classification like Naive Bayes, Support Vector Machines, Logistic Regression, etc., in this article we will be using a deep-learning-based convolutional neural network architecture to perform intent classification of text commands.
What are CNNs?
Though CNNs are associated more frequently with computer vision problems, recently they have been used in NLP with interesting results. CNNs are just several layers of convolutions with non-linear activation functions like ReLU or tanh or SoftMax applied to the results.
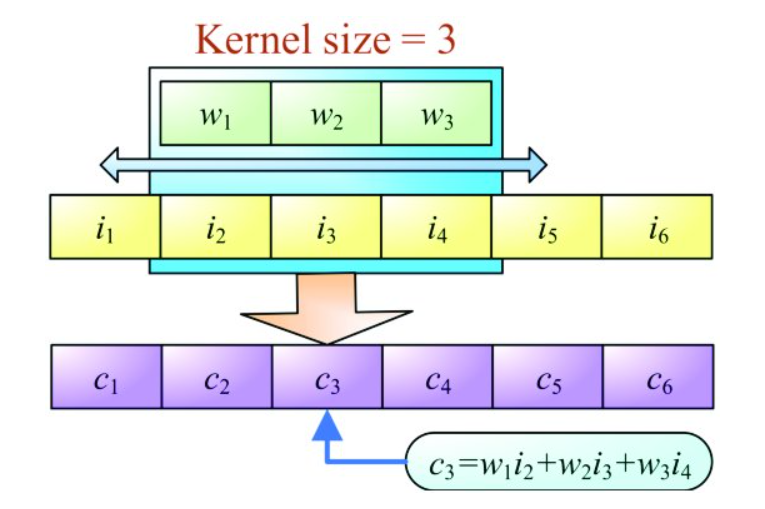
A 1-D convolution is shown in the above image. A filter/kernel of size 3 is passed over the input of size 6. Convolution is a mathematical operation where the elements in the filter are multiplied element-wise with the input over which the filter is currently present and the corresponding products are summed up to obtain the output element (as is shown by c3 = w1i2 + w2i3 + w3i4). The filter keeps going over the input, performing convolutions, and obtaining the output elements. We need 2-D convolutions in image processing tasks since images are 2-D vectors, but 1-D convolutions are enough for 1-D text manipulations. A convolutional neural network is simply a neural network where layers that perform convolutions are present. There can be multiple filters present in a single convolutional layer, which help to capture information about different input features.
Why CNNs in text classification?
The filters/kernels in CNNs can help identify relevant patterns in text data – bigrams, trigrams, or n-grams (contiguous sequence of n words) depending on kernel size. Since CNNs are translation invariant, they can detect these patterns irrespective of their position in the sentence. Local order of words is not that important in text classification, so CNNs can perform this task effectively. Each filter/kernel detects a specific feature, such as if the sentence contains positive (‘good’, ‘amazing’) or negative (‘bad’, ‘terrible’) terms in the case of sentiment analysis. Like sentiment analysis, most text classification tasks are determined by the presence or absence of some key phrases present anywhere in the sentence. This can be effectively modelled by CNNs which are good at extracting local and position-invariant features from data. Hence we have chosen CNNs for our intent classification task.
Loading the Dataset
Our task is to identify the intent behind a command like “Please bold the sentence” or “Emphasize the last word”. Our dataset consists of text commands like these with 26 different intents/ labels – undo, bold, remove bold, italicize, remove italics, underline, remove underline, superscript, remove superscript, subscript, remove subscript, strikethrough, remove strikethrough, centre align, insert a comment, left align, right align, remove formatting, insert a bullet, go to next bullet, end bullets, pause dictation, stop dictation, show all commands, show help and delete. As a first step, we load the dataset into a Pandas dataframe to make manipulation easier.
import pandas as pd
commands=pd.read_csv('TextCommands.csv’)
commands.columns = ['text','label','misc']
commands.head()
The dataset looks like this :
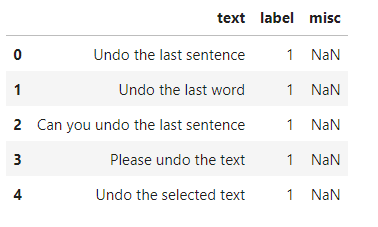
The different intents/labels are numbered from 1 to 26. The dataset is pretty balanced among the different labels. The dataset should ideally be balanced because a severely imbalanced dataset can be challenging to model and require specialized techniques.
Data Preprocessing
Data preprocessing is a particularly important task in NLP. We apply three main pre-processing methods here :
- Tokenizing: Keras’ inbuilt tokenizer API has fit the dataset which splits the sentences into words and creates a dictionary of all unique words found and their uniquely assigned integers. Each sentence is converted into an array of integers representing all the unique words present in it.
- Sequence Padding: The array representing each sentence in the dataset is filled with zeroes to the left to make the size of the array 10 and bring all arrays to the same length.
- Finally, the labels are converted into one-hot vectors using the to_categorical function from Keras.utils library.
The corresponding code :
import numpy as np
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.utils import to_categorical
MAX_SEQUENCE_LENGTH = 10
MAX_NUM_WORDS = 5000
tokenizer = Tokenizer(num_words=MAX_NUM_WORDS)
tokenizer.fit_on_texts(commands['text'])
sequences = tokenizer.texts_to_sequences(commands['text'])
word_index = tokenizer.word_index
print('Found %s unique tokens.' % len(word_index))
data = pad_sequences(sequences, maxlen=MAX_SEQUENCE_LENGTH)
labels = to_categorical(np.asarray(commands['label']))
print('Shape of data tensor:', data.shape)
print('Shape of label tensor:', labels.shape)
142 unique tokens are found in our dataset. Next, we need to split the data into train and test sets. The random shuffling of indices is used to split the dataset into roughly 90% training data and the rest test data.
VALIDATION_SPLIT = 0.1 indices = np.arange(data.shape[0]) np.random.shuffle(indices) data = data[indices] labels = labels[indices] num_validation_samples = int(VALIDATION_SPLIT * data.shape[0]) x_train = data[:-num_validation_samples] y_train = labels[:-num_validation_samples] x_val = data[-num_validation_samples:] y_val = labels[-num_validation_samples:]
Model Building
We start by importing the necessary packages to build the model and creating an embedding layer.
from keras.layers import Dense, Input, GlobalMaxPooling1D from keras.layers import Conv1D, MaxPooling1D, Embedding, Flatten from keras.models import Model from keras.models import Sequential from keras.initializers import Constant EMBEDDING_DIM = 60 num_words = min(MAX_NUM_WORDS, len(word_index) + 1) embedding_layer = Embedding(num_words,EMBEDDING_DIM,input_length=MAX_SEQUENCE_LENGTH,trainable=True)
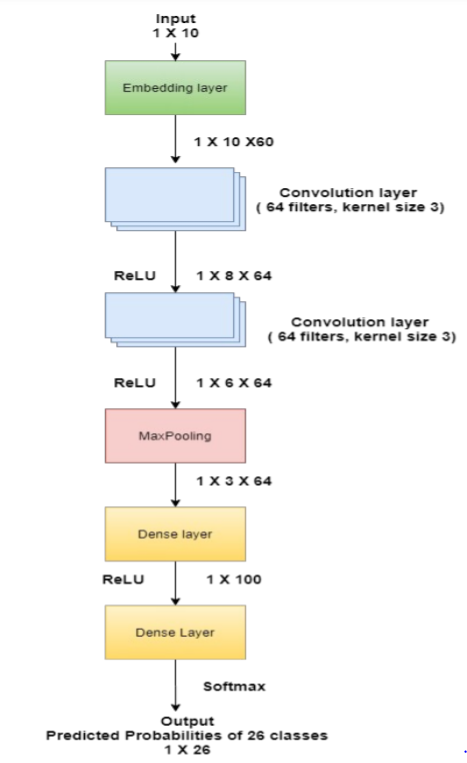
A keras functional model is implemented. It has the following layers :
- An input layer that takes the array of length 10 representing a sentence.
- An embedding layer of dimension 60 whose weights can be updated during training. It helps to convert each word into a fixed-length dense vector of size 60. The input dimension is set as the size of the vocabulary and the output dimension is 60. Each word in the input will hence get represented by a vector of size 60.
- Two convolutional layers (Conv1D) with 64 filters each, kernel size of 3, and relu activation.
- A max-pooling layer(MaxPooling1D) with pool size 2. Max Pooling in CNN is an operation that selects the maximum element from the region of the input which is covered by the filter/kernel. Pooling reduces the dimensions of the output, but it retains the most important information.
- A flatten layer to flatten the input without affecting batch size. If the input to the flatten layer is a tensor of shape 1 X 3 X 64, the output will be a tensor of shape 1 X 192.
- A dense (fully connected) layer of 100 units and relu activation.
- A dense layer of 26 units and softmax activation that outputs the final probabilities of belonging to each of the 26 classes. Softmax activation is used here since it goes best with categorical cross-entropy loss, which is the loss we are going to be using to train the model.
The model architecture is shown below :
The code for building the model :
sequence_input = Input(shape=(MAX_SEQUENCE_LENGTH,), dtype='int32') embedded_sequences = embedding_layer(sequence_input) x = Conv1D(64, 3, activation='relu')(embedded_sequences) x = Conv1D(64, 3, activation='relu')(x) x = MaxPooling1D(2)(x) x=Flatten()(x) x = Dense(100, activation='relu')(x) preds = Dense(27, activation='softmax')(x) model = Model(sequence_input, preds) model.compile(loss='categorical_crossentropy',optimizer='rmsprop',metrics=['acc']) model.summary()
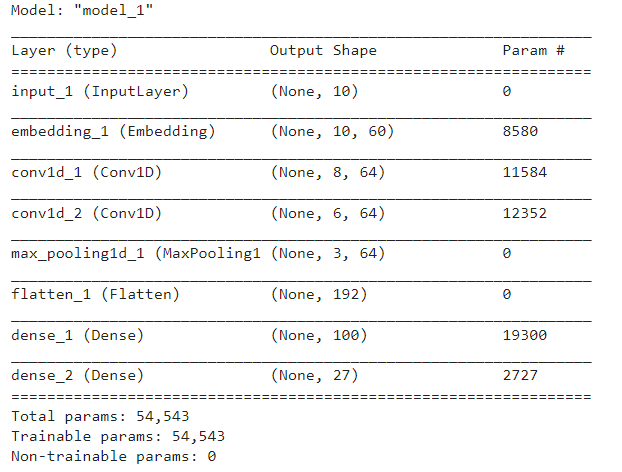
The model is compiled with categorical cross-entropy loss and rmsprop optimizer. Categorical cross-entropy is a loss function commonly used for multi-class classification tasks. The rmsprop optimizer is a gradient-based optimization technique that uses a moving average of squared gradients to normalize the gradient. This helps to overcome the vanishing gradients problem. Accuracy is used as the main performance metric. The model summary can be seen below :
Model Training and Evaluation
The model is trained for 30 epochs with batch size 50.
s=0.0
for i in range (1,50):
model.fit(x_train, y_train,batch_size=50, epochs=30, validation_data=(x_val, y_val))
# evaluate the model
scores = model.evaluate(x_val, y_val, verbose=0)
s=s+(scores[1]*100)
The model is evaluated by calculating its accuracy. Accuracy of classification is calculated by dividing the number of correct predictions by the total number of predictions.
# evaluate the model
scores = model.evaluate(x_val, y_val, verbose=0)
print("%s: %.2f%%" % (model.metrics_names[1], scores[1]*100))
The accuracy of our model comes out to be 94.87%! You can try improving the accuracy further by playing around with the model hyperparameters, further tuning the model architecture or changing the train-test split ratio.
Using the model to classify a new unseen text command
We can use our trained model to classify new text commands not present in the dataset into one of the 26 different labels. Each new text has to be tokenized and padded before being fed as input to the model. The model.predict() function returns the probabilities of the data belonging to each of the 26 classes. The class with the greatest probability is the predicted class.
# new instance where we do not know the answer
Xnew=["kindly undo the changes","Can you please undo the last paragraph","Make bold this","Would you be kind enough to bold the last word?","Please remove bold from the last paragraph","Kindly unbold the selected text","Kindly insert comment here","Can you please put a comment here","Can you please centre align this text","Can you please position this text in the middle"]
sequences_new = tokenizer.texts_to_sequences(Xnew)
data = pad_sequences(sequences_new, maxlen=MAX_SEQUENCE_LENGTH)
# make a prediction
yprob = model.predict(data)
yclasses=yprob.argmax(axis=-1)
# show the inputs and predicted outputs
print("X=%s, Predicted=%snX=%s, Predicted=%snX=%s, Predicted=%snX=%s, Predicted=%snX=%s, Predicted=%snX=%s, Predicted=%snX=%s, Predicted=%snX=%s, Predicted=%snX=%s, Predicted=%snX=%s, Predicted=%s" % (Xnew[0], yclasses[0],Xnew[1],yclasses[1],Xnew[2],yclasses[2],Xnew[3],yclasses[3],Xnew[4],yclasses[4],Xnew[5],yclasses[5],Xnew[6],yclasses[6],Xnew[7],yclasses[7],Xnew[8],yclasses[8],Xnew[9],yclasses[9]))
The output from the above code is :

The output looks very promising, it fails to classify only one sentence correctly.
Conclusion
To conclude, Natural Language Processing is a continuously expanding field filled with emerging technologies and applications. It has a massive impact in areas like chatbots, social media monitoring, recommendation systems, machine translation, etc. Now, you have learned how to use CNNs for text classification, go ahead and try to apply them in other areas of Natural Language Processing. The results might end up surprising you!
Thank you for reading.
Read here about NPL using CNNs for Sentence Classification!
Connect at: [email protected]
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.





Great post, I have read this post here I got very useful information. This is a very useful article.
Great post, I have read this post here I got very useful information. This is a very useful article. such a nice posting like this.